Python 科學數據分析初步

進行科學數據分析,並不一定要用那些昂貴的工具,你也可以試試這些「能幹」的開源工具。
你或許是一個科學數據分析領域的新手,你可能有一些數學或者計算機基礎,你也可能來自完全不相關的領域,但是別擔心,數據科學能提供一切你所需要的。並且你不需要那些昂貴、特殊的企業版軟體——在這篇文章中介紹的這些開源工具都將成為你的選擇。
Python,它的機器學習和數據科學庫(pandas,Keras,TensorFlow,scikit-learn,SciPy,NumPy 等等),和它的擴展的可視化列表庫(Matplotlib,pyplot,Plotly 等等)對於初學者和專家等來說都是出色的開源工具。簡單易學、普及率高、有社區提供支持,並且內置了最新的庫和數據科學所用到的演算法,這些工具都能給剛開始工作的你帶來很大的幫助。
很多Python庫都繼承自某一個基礎庫(就是我們所熟知的依賴關係),而在科學數據分析領域,最基礎的便是 NumPy 這個庫。它專為數據科學分析設計,NumPy 庫經常用於儲存數據集中的關係型數據部分,這部分數據儲存在它的 ndarray 類型中。這種數據類型便於存儲來自關係型數據表(如 csv 或其他格式的文件)中的數據,反之亦然。當 scikit 庫中的函數應用於多維數組的時候,其便利性就體現得更加明顯。如果只是進行數據查詢,那麼SQL語言是很好的工具,但是對於複雜和資源密集型科學數據操作就顯得蹩腳了,而把數據存儲在 ndarray 中則可以提高效率和速度(但這種優勢只在處理大量數據時才能顯現出來)。當你開始用 pandas 來進行知識抽取和分析的時候,pandas 中的 DataFrame 數據類型與 NumPy 中的 ndarray 之間的強強聯合會形成用於知識抽取和計算密集型操作的有力工具。
為了快速說明問題,讓我們打開 Python 的 shell ,然後載入一個關於犯罪分析的數據集,這個數據集使用 pandas 的 DateFrame 類型存儲,讓我們來初探這個被載入的數據集。
>>> import pandas as pd
>>> crime_stats = pd.read_csv('BPD_Arrests.csv')
>>> crime_stats.head()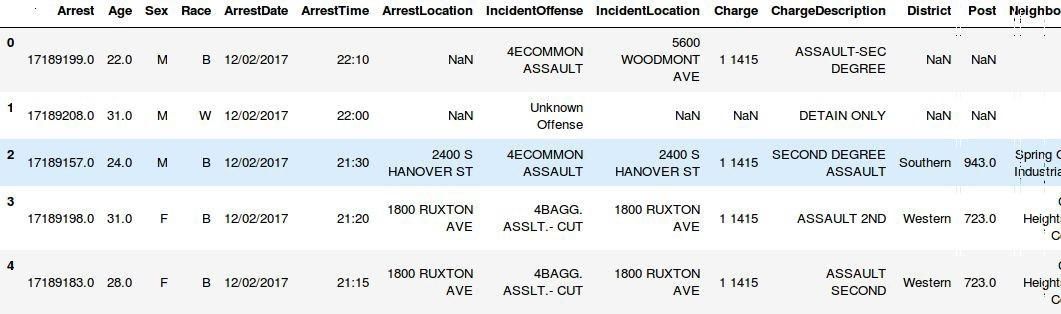
現在,在這個 pandas 的 DataFrame 類型數據集中,我們可以運用 SQL 查詢語句進行大多數查詢。例如,得到所有「Description」屬性的唯一值,SQL 查詢是這樣的:
$ SELECT unique(「Description」) from crime_stats;在 pandas 的 DataFrame 裡面實現相應功能的語句是這樣的:
>>> crime_stats['Description'].unique()
['COMMON ASSAULT' 'LARCENY' 'ROBBERY - STREET' 'AGG. ASSAULT'
'LARCENY FROM AUTO' 'HOMICIDE' 'BURGLARY' 'AUTO THEFT'
'ROBBERY - RESIDENCE' 'ROBBERY - COMMERCIAL' 'ROBBERY - CARJACKING'
'ASSAULT BY THREAT' 'SHOOTING' 'RAPE' 'ARSON']這樣的話就會返回一個 NumPy 數組(ndarray):
>>> type(crime_stats['Description'].unique())
之後,我們來把數據傳遞給一個神經元網路模型,來看看它的預測到底有多準確。給它一個類似的數據如犯罪時間,犯罪類型,和它發生的相關種種:,讓它預測其用了哪種類型的武器,代碼如下:
>>> from sklearn.neural_network import MLPClassifier
>>> import numpy as np
>>>
>>> prediction = crime_stats[[『Weapon』]]
>>> predictors = crime_stats['CrimeTime', 『CrimeCode』, 『Neighborhood』]
>>>
>>> nn_model = MLPClassifier(solver='lbfgs', alpha=1e-5, hidden_layer_sizes=(5,
2), random_state=1)
>>>
>>>predict_weapon = nn_model.fit(prediction, predictors)現在,學習模型已經準備完畢,我們可以進行一些測試來估計它的預測質量和穩定性。讓我們先從一些訓練用的測試數據開始(這部分的原始數據是用來訓練模型的,而不是用於創建模型的):
>>> predict_weapon.predict(training_set_weapons)
array([4, 4, 4, ..., 0, 4, 4])如你所看到的那樣,它會返回一個列表,每一個數據都是一個預測結果,表示一種武器,對應訓練數據集中的一條記錄。我們看到數字,而不是武器名,這是因為它和大多數分類演算法一樣,為分析大量數據而做出了優化。
對於數組數據,我們有多種方法將數字轉換成能被我們直觀理解的描述形式(如武器名)。在這個例子中,運用的技術是 LabelEncoding ,用的是 sklearn 中 preprocessing 庫中的 LabelEncoder 函數:
preprocessing.LableEncoder()。它可以對數據進行相關的轉換和逆轉換。在這個例子中,我們用了 LabelEncoder() 中的 inverse_transform 函數來看看武器 0 和 4 分別代表了什麼:
>>> preprocessing.LabelEncoder().inverse_transform(encoded_weapons)
array(['HANDS', 'FIREARM', 'HANDS', ..., 'FIREARM', 'FIREARM', 'FIREARM']這些數據看起來很有意思,但是並沒有得到這個模型的預測準確度是多少,我們來進行一些計算以得到其百分比:
>>> nn_model.score(X, y)
0.81999999999999995這些數據顯示出了我們的神經網路模型有將近82%的精確性。這的確是一個精確到令人印象深刻的結果,但是我們也不要忘了更換不同的數據集來測試他的有效性。這裡列舉了一些其他類型的測試,如:相互關係、模糊測試、矩陣測試等等。這些都可以用於測試模型的有效性。然而,雖然我們的模型具有很高的精確度,但是這對普通的犯罪數據集並不是很有用。就像我們用的這個數據集一樣,這個數據集中使用「槍支」這一類武器的記錄非常多,那麼無論我們之後輸入何種數據,預測結果都會更加偏向於使用「槍支」。
在我們分類之前清除數據、消除離群數據和畸變數據是很重要的。預處理越好,我們的精確度就越高。同樣,通過給模型/分類器塞過量數據來提高精確度(高於90%)是很不理智的,因為這樣非但不能達到目的,還會造成過度擬合。
如果你想用互動式圖形界面代替命令行,那麼 Jupyter notebooks 是一個很好的選擇。雖然大多數的事情在命令行中都能處理得很好,但當你開始用 snippets 來生成可視化時,就能體會到 Jupyter 給你帶來的好處。它可以把數據整理的比終端還好。
這篇文章給了大家一些機器學習的免費資源,當然也有大量的其他手冊和教程可供大家選擇。當然你也會發現,網上也有許多不同種類的開源數據集,想要使用哪一個完全取決於你自己的興趣愛好。在開始的時候,數據集是由Kaggle維護的,而且那些在官方靜態網站上的出色的資源是可以下載的。
本文由 紛寂 翻譯。更多詳情請訪問原文鏈接。
原文鏈接:https://opensource.com/article/18/3/getting-started-data-science
本文鏈接:https://linuxstory.org/getting-started-data-science/
轉載請註明來自 LinuxStory ,否則必究相關責任!
對這篇文章感覺如何?
You may also like





More in:開源學村

2022年,從學習Rust開始

使用 Linux 命令行解決Wordle 問題

如何殺死 Linux 中的殭屍進程

Linux 內核補丁提交初體驗









