Python 科学数据分析初步

进行科学数据分析,并不一定要用那些昂贵的工具,你也可以试试这些“能干”的开源工具。
你或许是一个科学数据分析领域的新手,你可能有一些数学或者计算机基础,你也可能来自完全不相关的领域,但是别担心,数据科学能提供一切你所需要的。并且你不需要那些昂贵、特殊的企业版软件——在这篇文章中介绍的这些开源工具都将成为你的选择。
Python,它的机器学习和数据科学库(pandas,Keras,TensorFlow,scikit-learn,SciPy,NumPy 等等),和它的扩展的可视化列表库(Matplotlib,pyplot,Plotly 等等)对于初学者和专家等来说都是出色的开源工具。简单易学、普及率高、有社区提供支持,并且内置了最新的库和数据科学所用到的算法,这些工具都能给刚开始工作的你带来很大的帮助。
很多Python库都继承自某一个基础库(就是我们所熟知的依赖关系),而在科学数据分析领域,最基础的便是 NumPy 这个库。它专为数据科学分析设计,NumPy 库经常用于储存数据集中的关系型数据部分,这部分数据储存在它的 ndarray 类型中。这种数据类型便于存储来自关系型数据表(如 csv 或其他格式的文件)中的数据,反之亦然。当 scikit 库中的函数应用于多维数组的时候,其便利性就体现得更加明显。如果只是进行数据查询,那么SQL语言是很好的工具,但是对于复杂和资源密集型科学数据操作就显得蹩脚了,而把数据存储在 ndarray 中则可以提高效率和速度(但这种优势只在处理大量数据时才能显现出来)。当你开始用 pandas 来进行知识抽取和分析的时候,pandas 中的 DataFrame 数据类型与 NumPy 中的 ndarray 之间的强强联合会形成用于知识抽取和计算密集型操作的有力工具。
为了快速说明问题,让我们打开 Python 的 shell ,然后加载一个关于犯罪分析的数据集,这个数据集使用 pandas 的 DateFrame 类型存储,让我们来初探这个被加载的数据集。
>>> import pandas as pd
>>> crime_stats = pd.read_csv('BPD_Arrests.csv')
>>> crime_stats.head()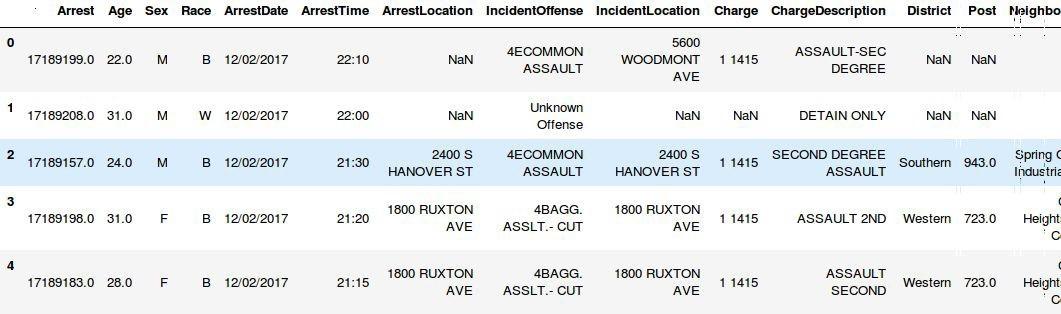
现在,在这个 pandas 的 DataFrame 类型数据集中,我们可以运用 SQL 查询语句进行大多数查询。例如,得到所有“Description”属性的唯一值,SQL 查询是这样的:
$ SELECT unique(“Description”) from crime_stats;在 pandas 的 DataFrame 里面实现相应功能的语句是这样的:
>>> crime_stats['Description'].unique()
['COMMON ASSAULT' 'LARCENY' 'ROBBERY - STREET' 'AGG. ASSAULT'
'LARCENY FROM AUTO' 'HOMICIDE' 'BURGLARY' 'AUTO THEFT'
'ROBBERY - RESIDENCE' 'ROBBERY - COMMERCIAL' 'ROBBERY - CARJACKING'
'ASSAULT BY THREAT' 'SHOOTING' 'RAPE' 'ARSON']这样的话就会返回一个 NumPy 数组(ndarray):
>>> type(crime_stats['Description'].unique())
之后,我们来把数据传递给一个神经元网络模型,来看看它的预测到底有多准确。给它一个类似的数据如犯罪时间,犯罪类型,和它发生的相关种种:,让它预测其用了哪种类型的武器,代码如下:
>>> from sklearn.neural_network import MLPClassifier
>>> import numpy as np
>>>
>>> prediction = crime_stats[[‘Weapon’]]
>>> predictors = crime_stats['CrimeTime', ‘CrimeCode’, ‘Neighborhood’]
>>>
>>> nn_model = MLPClassifier(solver='lbfgs', alpha=1e-5, hidden_layer_sizes=(5,
2), random_state=1)
>>>
>>>predict_weapon = nn_model.fit(prediction, predictors)现在,学习模型已经准备完毕,我们可以进行一些测试来估计它的预测质量和稳定性。让我们先从一些训练用的测试数据开始(这部分的原始数据是用来训练模型的,而不是用于创建模型的):
>>> predict_weapon.predict(training_set_weapons)
array([4, 4, 4, ..., 0, 4, 4])如你所看到的那样,它会返回一个列表,每一个数据都是一个预测结果,表示一种武器,对应训练数据集中的一条记录。我们看到数字,而不是武器名,这是因为它和大多数分类算法一样,为分析大量数据而做出了优化。
对于数组数据,我们有多种方法将数字转换成能被我们直观理解的描述形式(如武器名)。在这个例子中,运用的技术是 LabelEncoding ,用的是 sklearn 中 preprocessing 库中的 LabelEncoder 函数:
preprocessing.LableEncoder()。它可以对数据进行相关的转换和逆转换。在这个例子中,我们用了 LabelEncoder() 中的 inverse_transform 函数来看看武器 0 和 4 分别代表了什么:
>>> preprocessing.LabelEncoder().inverse_transform(encoded_weapons)
array(['HANDS', 'FIREARM', 'HANDS', ..., 'FIREARM', 'FIREARM', 'FIREARM']这些数据看起来很有意思,但是并没有得到这个模型的预测准确度是多少,我们来进行一些计算以得到其百分比:
>>> nn_model.score(X, y)
0.81999999999999995这些数据显示出了我们的神经网络模型有将近82%的精确性。这的确是一个精确到令人印象深刻的结果,但是我们也不要忘了更换不同的数据集来测试他的有效性。这里列举了一些其他类型的测试,如:相互关系、模糊测试、矩阵测试等等。这些都可以用于测试模型的有效性。然而,虽然我们的模型具有很高的精确度,但是这对普通的犯罪数据集并不是很有用。就像我们用的这个数据集一样,这个数据集中使用“枪支”这一类武器的记录非常多,那么无论我们之后输入何种数据,预测结果都会更加偏向于使用“枪支”。
在我们分类之前清除数据、消除离群数据和畸变数据是很重要的。预处理越好,我们的精确度就越高。同样,通过给模型/分类器塞过量数据来提高精确度(高于90%)是很不理智的,因为这样非但不能达到目的,还会造成过度拟合。
如果你想用交互式图形界面代替命令行,那么 Jupyter notebooks 是一个很好的选择。虽然大多数的事情在命令行中都能处理得很好,但当你开始用 snippets 来生成可视化时,就能体会到 Jupyter 给你带来的好处。它可以把数据整理的比终端还好。
这篇文章给了大家一些机器学习的免费资源,当然也有大量的其他手册和教程可供大家选择。当然你也会发现,网上也有许多不同种类的开源数据集,想要使用哪一个完全取决于你自己的兴趣爱好。在开始的时候,数据集是由Kaggle维护的,而且那些在官方静态网站上的出色的资源是可以下载的。
本文由 纷寂 翻译。更多详情请访问原文链接。
原文链接:https://opensource.com/article/18/3/getting-started-data-science
本文链接:https://linuxstory.org/getting-started-data-science/
转载请注明来自 LinuxStory ,否则必究相关责任!
对这篇文章感觉如何?
You may also like





More in:开源学村

2022年,从学习Rust开始

使用 Linux 命令行解决Wordle 问题

如何杀死 Linux 中的僵尸进程

Linux 内核补丁提交初体验









