Instagram 基於 Python 語言的 Web Service 效率提升之道

為何需要提升效率?
Instagram,正如所有的軟體,受限於像伺服器和數據中心能源這樣的物理限制。鑒於這些限制,在我們的效率計劃中有兩個我們希望實現的主要目標:
- Instagram 應當能夠利用持續代碼發布正常地提供通信服務,防止因為自然災害、區域性網路問題等造成某一個數據中心區丟失。
- Instagram 應當能夠自由地滾動發布新產品和新功能,不必因容量而受阻。
想要實現這些目標,我們意識到我們需要持續不斷地監控我們的系統並與 回歸 進行戰鬥。
定義效率
Web services 的瓶頸通常在於每台伺服器上可用的 CPU 時間。在這種環境下,效率就意味著利用相同的 CPU 資源完成更多的任務,也就是說, 每秒處理更多的用戶請求 。當我們尋找優化方法時,我們面臨的第一個最大的挑戰就是嘗試量化我們當前的效率。到目前為止,我們一直在使用「每次請求的平均 CPU 時間」來評估效率,但使用這種指標也有其固有限制:
- 設備多樣性。使用 CPU 時間來測量 CPU 資源並非理想方案,因為它同時受到 CPU 型號與 CPU 負載的影響。
- 請求影響數據。測量每次請求的 CPU 資源並非理想方案,因為在使用 每次請求測量 方案時,添加或移除輕量級或重量級的請求也會影響到效率指標。
相對於 CPU 時間來說,CPU 指令是一種更好的指標,因為對於相同的請求,它會報告相同的數字,不管 CPU 型號和 CPU 負載情況如何。我們選擇使用了一種叫做」 每個活動用戶 「的指標,而不是將我們所有的數據關聯到每個用戶請求上。我們最終採用「 每個活動用戶在高峰期間的 CPU 指令 」來測量效率。我們建立好新的度量標準後,下一步就是通過對 Django 的分析來更多的了解一下我們的回歸。
Django web services 分析
通過分析我們的 Django web services,我們希望回答兩個主要問題:
- CPU 回歸會發生嗎?
- 是什麼導致了 CPU 回歸發生以及我們該怎樣修復它?
想要回答第一個問題,我們需要追蹤「 每個活動用戶的 CPU 指令 」指標。如果該指標增加,我們就知道已經發生了一次 CPU 回歸。
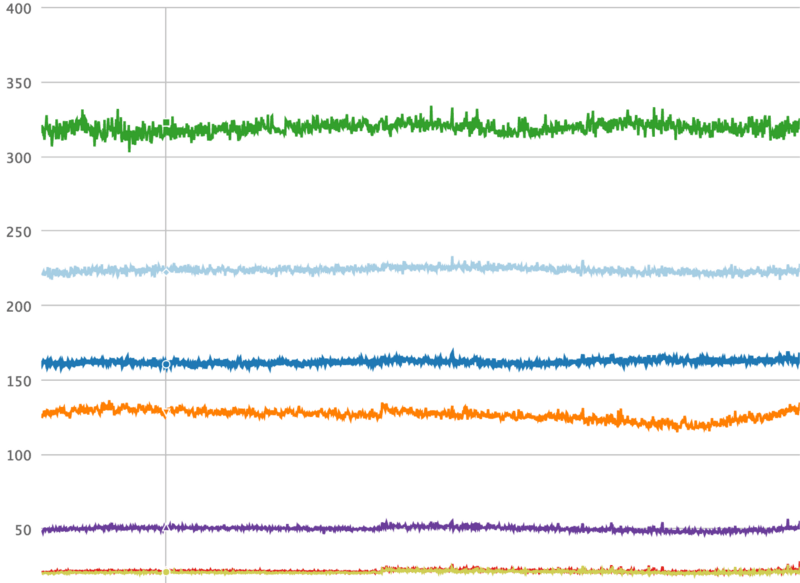
我們為此構建的工具叫做 Dynostats。Dynostats 利用 Django 中間件以一定的速率採樣用戶請求,記錄關鍵的效率以及性能指標,例如 CPU 總指令數、端到端請求時延、花費在訪問內存緩存(memcache)和資料庫服務的時間等。另一方面,每個請求都有很多可用於聚合的 元數據 ,例如端點名稱、HTTP 請求返回碼、服務該請求的伺服器名稱以及請求中最新提交的 哈希值 。對於單個請求記錄來說,有兩個方面非常強大,因為我們可以在不同的維度上進行切割,那將幫助我們減少任何導致 CPU 回歸的原因。例如,我們可以根據它們的端點名稱聚合所有請求,正如下面的時間序列圖所示,從圖中可以清晰地看出在特定端點上是否發生了回歸。
CPU 指令對測量效率很重要——當然,它們也很難獲得。Python 並沒有支持直接訪問 CPU 硬體計數器(CPU 硬體計數器是指可編程 CPU 寄存器,用於測量性能指標,例如 CPU 指令)的公共庫。另一方面,Linux 內核提供了 perf_event_open 系統調用。通過 Python ctypes 橋接技術能夠讓我們調用標準 C 庫的系統調用函數 syscall,它也為我們提供了兼容 C 的數據類型,從而可以編程硬體計數器並從它們讀取數據。
使用 Dynostats,我們已經可以找出 CPU 回歸,並探究 CPU 回歸發生的原因,例如哪個端點受到的影響最多,誰提交了真正會導致 CPU 回歸的變更等。然而,當開發者收到他們的變更已經導致一次 CPU 回歸發生的通知時,他們通常難以找出問題所在。如果問題很明顯,那麼回歸可能就不會一開始就被提交!
這就是為何我們需要一個 Python 分析器,(一旦 Dynostats 發現了它)從而使開發者能夠使用它找出回歸發生的根本原因。不同於白手起家,我們決定對一個現成的 Python 分析器 cProfile 做適當的修改。cProfile 模塊通常會提供一個統計集合來描述程序不同的部分執行時間和執行頻率。我們將 cProfile 的 定時器 替換成了一個從硬體計數器讀取的 CPU 指令計數器,以此取代對時間的測量。我們在採樣請求後產生數據並把數據發送到數據流水線。我們也會發送一些我們在 Dynostats 所擁有的類似元數據,例如伺服器名稱、集群、區域、端點名稱等。
在數據流水線的另一邊,我們創建了一個消費數據的 尾隨者 。尾隨者的主要功能是解析 cProfile 的統計數據並創建能夠表示 Python 函數級別的 CPU 指令的實體。如此,我們能夠通過 Python 函數來聚合 CPU 指令,從而更加方便地找出是什麼函數導致了 CPU 回歸。
監控與警報機制
在 Instagram,我們每天部署 30-50 次後端服務。這些部署中的任何一個都能發生 CPU 回歸的問題。因為每次發生通常都包含至少一個 差異 ,所以找出任何回歸是很容易的。我們的效率監控機制包括在每次發布前後都會在 Dynostats 中掃描 CPU 指令,並且當變更超出某個閾值時發出警告。對於長期會發生 CPU 回歸的情況,我們也有一個探測器為負載最繁重的端點提供日常和每周的變更掃描。
部署新的變更並非觸發一次 CPU 回歸的唯一情況。在許多情況下,新的功能和新的代碼路徑都由 全局環境變數 控制。 在一個計劃好的時間表上,給一部分用戶發布新功能是很常見事情。我們在 Dynostats 和 cProfile 統計數據中為每個請求添加了這個信息作為額外的元數據欄位。按這些欄位將請求分組可以找出由全局環境變數(GEV)改變導致的可能的 CPU 回歸問題。這讓我們能夠在它們對性能造成影響前就捕獲到 CPU 回歸。
接下來是什麼?
Dynostats 和我們定製的 cProfile,以及我們建立的支持它們的監控和警報機制能夠有效地找出大多數導致 CPU 回歸的元兇。這些進展已經幫助我們恢復了超過 50% 的不必要的 CPU 回歸,否則我們就根本不會知道。
我們仍然還有一些可以提升的方面,並很容易將它們地加入到 Instagram 的日常部署流程中:
- CPU 指令指標應該要比其它指標如 CPU 時間更加穩定,但我們仍然觀察了讓我們頭疼的差異。保持「 信噪比 」合理地低是非常重要的,這樣開發者們就可以集中於真實的回歸上。這可以通過引入 置信區間 的概念來提升,並在信噪比過高時發出警報。針對不同的端點,變化的閾值也可以設置為不同值。
- 通過更改 GEV 來探測 CPU 回歸的一個限制就是我們要在 Dynostats 中手動啟用這些比較的日誌輸出。當 GEV 的數量逐漸增加,開發了越來越多的功能,這就不便於擴展了。相反,我們能夠利用一個自動化框架來調度這些比較的日誌輸出,並對所有的 GEV 進行遍歷,然後當檢查到回歸時就發出警告。
- cProfile 需要一些增強以便更好地處理封裝函數以及它們的子函數。
鑒於我們在為 Instagram 的 web service 構建效率框架中所投入的工作,所以我們對於將來使用 Python 繼續擴展我們的服務很有信心。我們也開始向 Python 語言本身投入更多,並且開始探索從 Python 2 轉移 Python 3 之道。我們將會繼續探索並做更多的實驗以繼續提升基礎設施與開發者效率,我們期待著很快能夠分享更多的經驗。
本文作者 Min Ni 是 Instagram 的軟體工程師。
(題圖來自:nostarch.com)
作者:Min Ni 譯者:ChrisLeeGit 校對:wxy
本文轉載來自 Linux 中國: https://github.com/Linux-CN/archive
對這篇文章感覺如何?
You may also like






More in:Linux中國

捐贈 Let's Encrypt,共建安全的互聯網

Let's Encrypt 正式發布,已經保護 380 萬個域名

關於Linux防火牆iptables的面試問答

Lets Encrypt 已被所有主流瀏覽器所信任









