人工智慧的巨大突破! AlphaGo 靠什麼擊敗李世石?

在剛剛結束的 Google 圍棋挑戰賽第一天的比賽中,李世石輸給了人工智慧產品 AlphaGo。要知道李世石可是職業九段選手啊,AlphaGo 的勝利難道只是巧合還是另有原因? Linux Story 小編帶你一起去看看 AlphaGo 背後的那些事。
何為 AlphaGo ?
AlphaGo 是 Google DeepMind 開發的圍棋程序。在2015年10月,它成為第一個不藉助讓子,在全尺寸19×19的棋盤上擊敗職業圍棋棋手的電腦圍棋程序。
AlphaGo 官網:https://deepmind.com/alpha-go.html
李世石簡介
李世乭(朝鮮語:이세돌,1983年3月2日-),韓國圍棋九段棋手,成長於韓國全羅南道偏僻的飛禽島,所以又被稱為「飛禽島少年」。因中文漢字無「乭」字(韓國自創字),故中文媒體多將其簡化為「石」(李世石)。早年棋風銳利,擅長大規模的攻殺,成績卓越,近年來隨著年紀漸長與技術逐漸成熟,開始轉變為全能棋風,能攻能守,剛柔並濟成為一代棋界巨匠。李世乭厲害之處在於他下棋的風格飄渺靈幻,時常有神來之筆,兼有強大的戰力且計算極為精準。同時他也有著高水準的心理質素,世界大賽上常在落後的情況下迎頭趕上逆轉拿下勝局。在2005到2010年期間與中國的圍棋第一人古力九段有多次交鋒,受到很大注意。
AlphaGo 背後的秘密
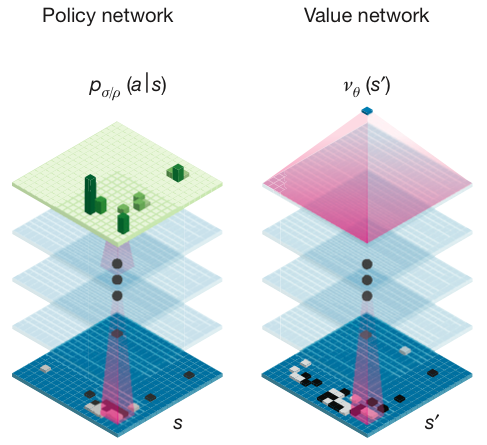
AlphaGo使用蒙特卡洛樹搜索(Monte-Carlo tree search),藉助價值網路(value network)與策略網路(policy network)這兩種深度神經網路,通過價值網路來評估大量選點,並通過策略網路選擇落點。AlphaGo最初通過模仿人類玩家,嘗試匹配職業棋手的棋局,一旦它達到了一定的熟練程度,它開始和自己對弈大量棋局,使用強化學習進一步改善它。圍棋無法僅通過尋找最佳步來解決;遊戲一盤平均有150步,每一步平均有200種可選的下法,意味著有太多需要解決的可能性。
- 蒙特卡洛樹搜索:一種博弈搜索演算法。詳情請見:https://en.wikipedia.org/wiki/Monte_Carlo_tree_search
- 價值網路(value network):網路中節點存在值和連接。詳情請見:https://en.wikipedia.org/wiki/Value_network
- 策略網路(policy network):用於選擇落子。
國際象棋的複雜度:
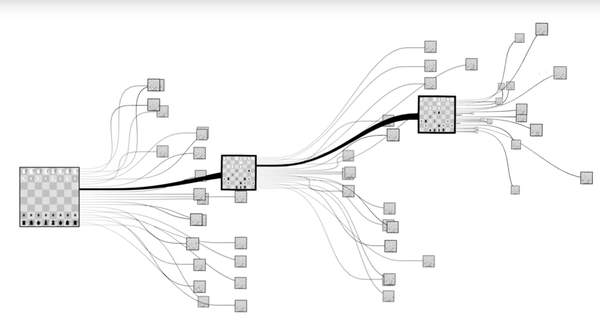
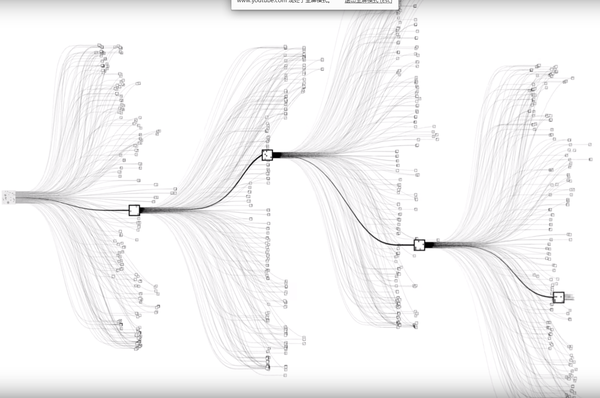
圍棋的複雜度:
神經網路示意圖:
與其說 AlphaGo 戰勝了李世石,還不如說是人類戰勝了自己。
Linux Story 提醒:更多詳情請閱讀原論文:
http://www.nature.com/nature/journal/v529/n7587/full/nature16961.html
本文鏈接:
http://www.linuxstory.org/why-alphago-beated-lee-se-dol/
參考文獻:
https://en.wikipedia.org/wiki/AlphaGo
對這篇文章感覺如何?
You may also like





1 Comment
Leave a reply
More in:人工智慧

邁向開源另一步:微軟將其深度學習工具包 CNTK 開源!

人工智慧終將飛入尋常百姓家










圖很贊!