如何在 Apache Kafka 中通過 KSQL 分析 Twitter 數據

介紹
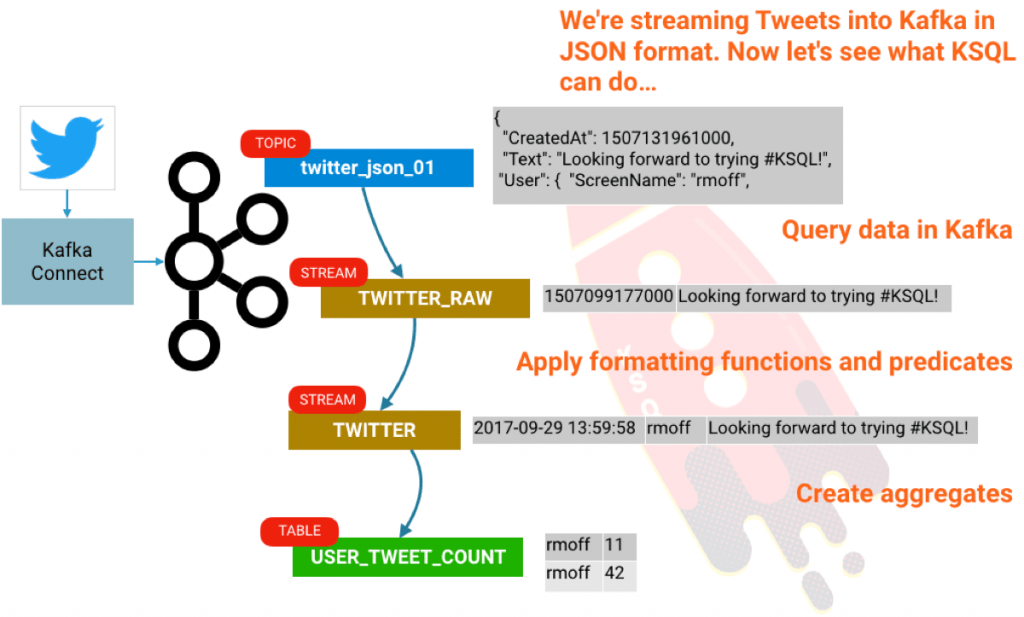
KSQL 是 Apache Kafka 中的開源的流式 SQL 引擎。它可以讓你在 Kafka 主題 上,使用一個簡單的並且是互動式的 SQL 介面,很容易地做一些複雜的流處理。在這個短文中,我們將看到如何輕鬆地配置並運行在一個沙箱中去探索它,並使用大家都喜歡的演示資料庫源: Twitter。我們將從推文的原始流中獲取,通過使用 KSQL 中的條件去過濾它,來構建一個聚合,如統計每個用戶每小時的推文數量。
Confluent
首先, 獲取一個 Confluent 平台的副本。我使用的是 RPM 包,但是,如果你需要的話,你也可以使用 tar、 zip 等等 。啟動 Confluent 系統:
$ confluent start
(如果你感興趣,這裡有一個 Confluent 命令行的快速教程)
我們將使用 Kafka Connect 從 Twitter 上拉取數據。 這個 Twitter 連接器可以在 GitHub 上找到。要安裝它,像下面這樣操作:
# Clone the git repo
cd /home/rmoff
git clone https://github.com/jcustenborder/kafka-connect-twitter.git
# Compile the code
cd kafka-connect-twitter
mvn clean package
要讓 Kafka Connect 去使用我們構建的連接器, 你要去修改配置文件。因為我們使用 Confluent 命令行,真實的配置文件是在 etc/schema-registry/connect-avro-distributed.properties,因此去修改它並增加如下內容:
plugin.path=/home/rmoff/kafka-connect-twitter/target/kafka-connect-twitter-0.2-SNAPSHOT.tar.gz
重啟動 Kafka Connect:
confluent stop connect
confluent start connect
一旦你安裝好插件,你可以很容易地去配置它。你可以直接使用 Kafka Connect 的 REST API ,或者創建你的配置文件,這就是我要在這裡做的。如果你需要全部的方法,請首先訪問 Twitter 來獲取你的 API 密鑰。
{
"name": "twitter_source_json_01",
"config": {
"connector.class": "com.github.jcustenborder.kafka.connect.twitter.TwitterSourceConnector",
"twitter.oauth.accessToken": "xxxx",
"twitter.oauth.consumerSecret": "xxxxx",
"twitter.oauth.consumerKey": "xxxx",
"twitter.oauth.accessTokenSecret": "xxxxx",
"kafka.delete.topic": "twitter_deletes_json_01",
"value.converter": "org.apache.kafka.connect.json.JsonConverter",
"key.converter": "org.apache.kafka.connect.json.JsonConverter",
"value.converter.schemas.enable": false,
"key.converter.schemas.enable": false,
"kafka.status.topic": "twitter_json_01",
"process.deletes": true,
"filter.keywords": "rickastley,kafka,ksql,rmoff"
}
}
假設你寫這些到 /home/rmoff/twitter-source.json,你可以現在運行:
$ confluent load twitter_source -d /home/rmoff/twitter-source.json
然後推文就從大家都喜歡的網路明星 [rick] 滾滾而來……
$ kafka-console-consumer --bootstrap-server localhost:9092 --from-beginning --topic twitter_json_01|jq '.Text'
{
"string": "RT @rickastley: 30 years ago today I said I was Never Gonna Give You Up. I am a man of my word - Rick x https://t.co/VmbMQA6tQB"
}
{
"string": "RT @mariteg10: @rickastley @Carfestevent Wonderful Rick!!nDo not forget Chile!!nWe hope you get back someday!!nHappy weekend for you!!n❤…"
}
KSQL
現在我們從 KSQL 開始 ! 馬上去下載並構建它:
cd /home/rmoff
git clone https://github.com/confluentinc/ksql.git
cd /home/rmoff/ksql
mvn clean compile install -DskipTests
構建完成後,讓我們來運行它:
./bin/ksql-cli local --bootstrap-server localhost:9092
======================================
= _ __ _____ ____ _ =
= | |/ // ____|/ __ | | =
= | ' /| (___ | | | | | =
= | < ___ | | | | | =
= | . ____) | |__| | |____ =
= |_|______/ __________| =
= =
= Streaming SQL Engine for Kafka =
Copyright 2017 Confluent Inc.
CLI v0.1, Server v0.1 located at http://localhost:9098
Having trouble? Type 'help' (case-insensitive) for a rundown of how things work!
ksql>
使用 KSQL, 我們可以讓我們的數據保留在 Kafka 主題上並可以查詢它。首先,我們需要去告訴 KSQL 主題上的 數據模式 是什麼,一個 twitter 消息實際上是一個非常巨大的 JSON 對象, 但是,為了簡潔,我們只選出其中幾行:
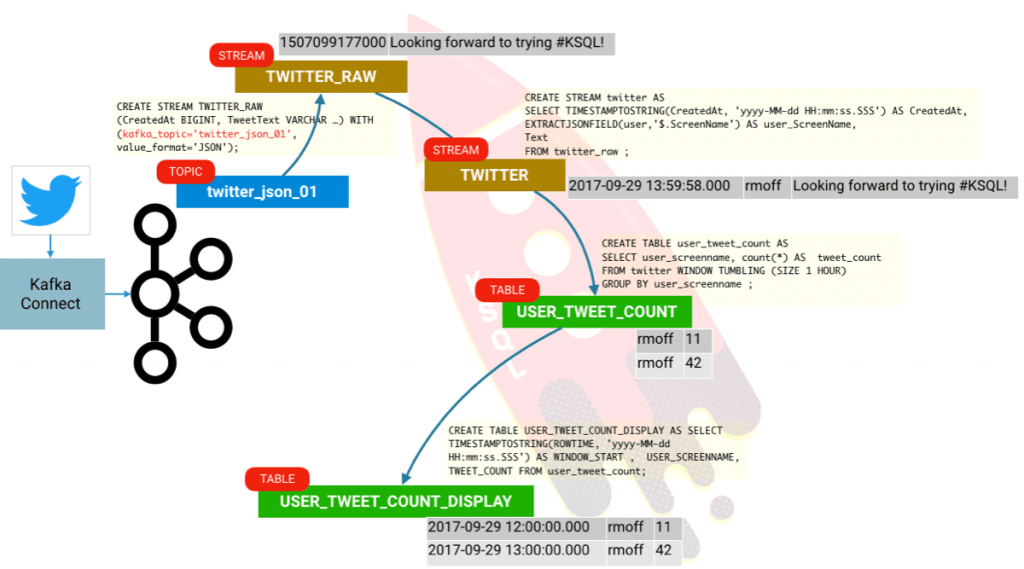
ksql> CREATE STREAM twitter_raw (CreatedAt BIGINT, Id BIGINT, Text VARCHAR) WITH (KAFKA_TOPIC='twitter_json_01', VALUE_FORMAT='JSON');
Message
-------------Stream created
在定義的模式中,我們可以查詢這些流。要讓 KSQL 從該主題的開始展示數據(而不是默認的當前時間點),運行如下命令:
ksql> SET 'auto.offset.reset' = 'earliest';
Successfully changed local property 'auto.offset.reset' from 'null' to 'earliest'
現在,讓我們看看這些數據,我們將使用 LIMIT 從句僅檢索一行:
ksql> SELECT text FROM twitter_raw LIMIT 1;
RT @rickastley: 30 years ago today I said I was Never Gonna Give You Up. I am a man of my word - Rick x https://t.co/VmbMQA6tQB
LIMIT reached for the partition.
Query terminated
ksql>
現在,讓我們使用剛剛定義和可用的推文內容的全部數據重新定義該流:
ksql> DROP stream twitter_raw;
Message
-----------------------------Source TWITTER_RAW was dropped
ksql> CREATE STREAM twitter_raw (CreatedAt bigint,Id bigint, Text VARCHAR, SOURCE VARCHAR, Truncated VARCHAR, InReplyToStatusId VARCHAR, InReplyToUserId VARCHAR, InReplyToScreenName VARCHAR, GeoLocation VARCHAR, Place VARCHAR, Favorited VARCHAR, Retweeted VARCHAR, FavoriteCount VARCHAR, User VARCHAR, Retweet VARCHAR, Contributors VARCHAR, RetweetCount VARCHAR, RetweetedByMe VARCHAR, CurrentUserRetweetId VARCHAR, PossiblySensitive VARCHAR, Lang VARCHAR, WithheldInCountries VARCHAR, HashtagEntities VARCHAR, UserMentionEntities VARCHAR, MediaEntities VARCHAR, SymbolEntities VARCHAR, URLEntities VARCHAR) WITH (KAFKA_TOPIC='twitter_json_01',VALUE_FORMAT='JSON');
Message
-------------Stream created
ksql>
現在,我們可以操作和檢查更多的最近的數據,使用一般的 SQL 查詢:
ksql> SELECT TIMESTAMPTOSTRING(CreatedAt, 'yyyy-MM-dd HH:mm:ss.SSS') AS CreatedAt,
EXTRACTJSONFIELD(user,'$.ScreenName') as ScreenName,Text
FROM twitter_raw
WHERE LCASE(hashtagentities) LIKE '%oow%' OR
LCASE(hashtagentities) LIKE '%ksql%';
2017-09-29 13:59:58.000 | rmoff | Looking forward to talking all about @apachekafka & @confluentinc』s #KSQL at #OOW17 on Sunday 13:45 https://t.co/XbM4eIuzeG
注意這裡沒有 LIMIT 從句,因此,你將在屏幕上看到 「continuous query」 的結果。不像關係型數據表中返回一個確定數量結果的查詢,一個持續查詢會運行在無限的流式數據上, 因此,它總是可能返回更多的記錄。點擊 Ctrl-C 去中斷然後返回到 KSQL 提示符。在以上的查詢中我們做了一些事情:
- TIMESTAMPTOSTRING 將時間戳從 epoch 格式轉換到人類可讀格式。(LCTT 譯註: epoch 指的是一個特定的時間 1970-01-01 00:00:00 UTC)
- EXTRACTJSONFIELD 來展示數據源中嵌套的用戶域中的一個欄位,它看起來像:
{
"CreatedAt": 1506570308000,
"Text": "RT @gwenshap: This is the best thing since partitioned bread :) https://t.co/1wbv3KwRM6",
[...]
"User": {
"Id": 82564066,
"Name": "Robin Moffatt uD83CuDF7BuD83CuDFC3uD83EuDD53",
"ScreenName": "rmoff",
[...]
- 應用斷言去展示內容,對 #(hashtag)使用模式匹配, 使用 LCASE 去強制小寫字母。(LCTT 譯註:hashtag 是twitter 中用來標註線索主題的標籤)
關於支持的函數列表,請查看 KSQL 文檔。
我們可以創建一個從這個數據中得到的流:
ksql> CREATE STREAM twitter AS
SELECT TIMESTAMPTOSTRING(CreatedAt, 'yyyy-MM-dd HH:mm:ss.SSS') AS CreatedAt,
EXTRACTJSONFIELD(user,'$.Name') AS user_Name,
EXTRACTJSONFIELD(user,'$.ScreenName') AS user_ScreenName,
EXTRACTJSONFIELD(user,'$.Location') AS user_Location,
EXTRACTJSONFIELD(user,'$.Description') AS user_Description,
Text,hashtagentities,lang
FROM twitter_raw ;
Message
----------------------------
Stream created and running
ksql> DESCRIBE twitter;
Field | Type
------------------------------------
ROWTIME | BIGINT
ROWKEY | VARCHAR(STRING)
CREATEDAT | VARCHAR(STRING)
USER_NAME | VARCHAR(STRING)
USER_SCREENNAME | VARCHAR(STRING)
USER_LOCATION | VARCHAR(STRING)
USER_DESCRIPTION | VARCHAR(STRING)
TEXT | VARCHAR(STRING)
HASHTAGENTITIES | VARCHAR(STRING)
LANG | VARCHAR(STRING)
ksql>
並且查詢這個得到的流:
ksql> SELECT CREATEDAT, USER_NAME, TEXT
FROM TWITTER
WHERE TEXT LIKE '%KSQL%';
2017-10-03 23:39:37.000 | Nicola Ferraro | RT @flashdba: Again, I'm really taken with the possibilities opened up by @confluentinc's KSQL engine #Kafka https://t.co/aljnScgvvs
聚合
在我們結束之前,讓我們去看一下怎麼去做一些聚合。
ksql> SELECT user_screenname, COUNT(*)
FROM twitter WINDOW TUMBLING (SIZE 1 HOUR)
GROUP BY user_screenname HAVING COUNT(*) > 1;
oracleace | 2
rojulman | 2
smokeinpublic | 2
ArtFlowMe | 2
[...]
你將可能得到滿屏幕的結果;這是因為 KSQL 在每次給定的時間窗口更新時實際發出聚合值。因為我們設置 KSQL 去讀取在主題上的全部消息(SET 'auto.offset.reset' = 'earliest';),它是一次性讀取這些所有的消息並計算聚合更新。這裡有一個微妙之處值得去深入研究。我們的入站推文流正好就是一個流。但是,現有它不能創建聚合,我們實際上是創建了一個表。一個表是在給定時間點的給定鍵的值的一個快照。 KSQL 聚合數據基於消息的事件時間,並且如果它更新了,通過簡單的相關窗口重申去操作後面到達的數據。困惑了嗎? 我希望沒有,但是,讓我們看一下,如果我們可以用這個例子去說明。 我們將申明我們的聚合作為一個真實的表:
ksql> CREATE TABLE user_tweet_count AS
SELECT user_screenname, count(*) AS tweet_count
FROM twitter WINDOW TUMBLING (SIZE 1 HOUR)
GROUP BY user_screenname ;
Message
---------------------------
Table created and running
看錶中的列,這裡除了我們要求的外,還有兩個隱含列:
ksql> DESCRIBE user_tweet_count;
Field | Type
-----------------------------------
ROWTIME | BIGINT
ROWKEY | VARCHAR(STRING)
USER_SCREENNAME | VARCHAR(STRING)
TWEET_COUNT | BIGINT
ksql>
我們看一下這些是什麼:
ksql> SELECT TIMESTAMPTOSTRING(ROWTIME, 'yyyy-MM-dd HH:mm:ss.SSS') ,
ROWKEY, USER_SCREENNAME, TWEET_COUNT
FROM user_tweet_count
WHERE USER_SCREENNAME= 'rmoff';
2017-09-29 11:00:00.000 | rmoff : Window{start=1506708000000 end=-} | rmoff | 2
2017-09-29 12:00:00.000 | rmoff : Window{start=1506711600000 end=-} | rmoff | 4
2017-09-28 22:00:00.000 | rmoff : Window{start=1506661200000 end=-} | rmoff | 2
2017-09-29 09:00:00.000 | rmoff : Window{start=1506700800000 end=-} | rmoff | 4
2017-09-29 15:00:00.000 | rmoff : Window{start=1506722400000 end=-} | rmoff | 2
2017-09-29 13:00:00.000 | rmoff : Window{start=1506715200000 end=-} | rmoff | 6
ROWTIME 是窗口開始時間, ROWKEY 是 GROUP BY(USER_SCREENNAME)加上窗口的組合。因此,我們可以通過創建另外一個衍生的表來整理一下:
ksql> CREATE TABLE USER_TWEET_COUNT_DISPLAY AS
SELECT TIMESTAMPTOSTRING(ROWTIME, 'yyyy-MM-dd HH:mm:ss.SSS') AS WINDOW_START ,
USER_SCREENNAME, TWEET_COUNT
FROM user_tweet_count;
Message
---------------------------
Table created and running
現在它更易於查詢和查看我們感興趣的數據:
ksql> SELECT WINDOW_START , USER_SCREENNAME, TWEET_COUNT
FROM USER_TWEET_COUNT_DISPLAY WHERE TWEET_COUNT> 20;
2017-09-29 12:00:00.000 | VikasAatOracle | 22
2017-09-28 14:00:00.000 | Throne_ie | 50
2017-09-28 14:00:00.000 | pikipiki_net | 22
2017-09-29 09:00:00.000 | johanlouwers | 22
2017-09-28 09:00:00.000 | yvrk1973 | 24
2017-09-28 13:00:00.000 | cmosoares | 22
2017-09-29 11:00:00.000 | ypoirier | 24
2017-09-28 14:00:00.000 | pikisec | 22
2017-09-29 07:00:00.000 | Throne_ie | 22
2017-09-29 09:00:00.000 | ChrisVoyance | 24
2017-09-28 11:00:00.000 | ChrisVoyance | 28
結論
所以我們有了它! 我們可以從 Kafka 中取得數據, 並且很容易使用 KSQL 去探索它。 而不僅是去瀏覽和轉換數據,我們可以很容易地使用 KSQL 從流和表中建立流處理。
如果你對 KSQL 能夠做什麼感興趣,去查看:
- KSQL 公告
- 我們最近的 KSQL 在線研討會 和 Kafka 峰會講演
- clickstream 演示,它是 KSQL 的 GitHub 倉庫 的一部分
- 我最近做的演講 展示了 KSQL 如何去支持基於流的 ETL 平台
記住,KSQL 現在正處於開發者預覽階段。 歡迎在 KSQL 的 GitHub 倉庫上提出任何問題, 或者去我們的 community Slack group 的 #KSQL 頻道。
via: https://www.confluent.io/blog/using-ksql-to-analyse-query-and-transform-data-in-kafka
作者:Robin Moffatt 譯者:qhwdw 校對:wxy
本文轉載來自 Linux 中國: https://github.com/Linux-CN/archive
對這篇文章感覺如何?
You may also like






More in:Linux中國

捐贈 Let's Encrypt,共建安全的互聯網

Let's Encrypt 正式發布,已經保護 380 萬個域名

關於Linux防火牆iptables的面試問答

Lets Encrypt 已被所有主流瀏覽器所信任









