為什麼(大多數)高級語言運行效率較慢

首先,下文內容主要討論客戶端應用。如果你的程序有 99.9% 的時間都在等待網路 I/O,那麼這很可能不是拖慢語言運行效率的原因——優先考慮的問題當然是優化網路。在本文中,我們主要討論程序在本地執行的速度。
我將選用 C# 語言作為本文的參考語言,其原因有二:首先它是我常用的高級語言;其次如果我使用 Java 語言,許多使用 C# 的朋友會告訴我 C# 不會有這些問題,因為它有值類型(但這是錯誤的)。
接下來我將會討論,出於編程習慣編寫的代碼、使用 普遍編程方法 的代碼或使用庫或教程中提到的常用代碼來編寫程序時會發生什麼。我對那些使用難搞的辦法來解決語言自身毛病以「證明」語言沒毛病這事沒興趣,當然你可以和語言抗爭來避免它的毛病,但這並不能說明語言本身是沒有問題的。
回顧緩存消耗問題
首先我們先來回顧一下合理使用緩存的重要性。下圖是基於在 Haswell 架構下內存延遲對 CPU 影響的 數據:
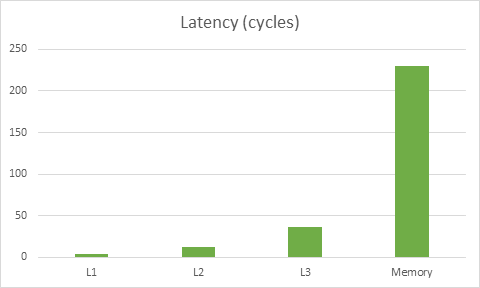
針對這款 CPU 讀取內存的延遲,CPU 需要消耗近 230 個運算周期從內存讀取數據,同時需要消耗 4 個運算周期來讀取 L1 緩衝區。因此錯誤的去使用緩存可導致運行速度拖慢近 50 倍。還好這並不是最糟糕的——在現代 CPU 中它們能同時地做多種操作,所以當你載入 L1 緩衝區內容的同時這個內容已經進入到了寄存器,因此數據從 L1 緩衝區載入這個過程的性能消耗就被部分或完整的掩蓋了起來。
撇開選擇合理的演算法不談,不誇張地講,在性能優化中你要考慮的最主要因素其實是緩存未命中。當你能夠有效的訪問一個數據時候,你才需要考慮優化你的每個具體的操作。與緩存未命中的問題相比,那些次要的低效問題對運行速度並沒有什麼過多的影響。
這對於編程語言的設計者來說是一個好消息!你都不必去編寫一個最高效的編譯器,你可以完全擺脫一些額外的開銷(比如:數組邊界檢查),你只需要專註怎麼設計語言能高效地編寫代碼來訪問數據,而不用擔心與 C 語言代碼比較運行速度。
為什麼 C# 存在緩存未命中問題
坦率地講 C# 在設計時就沒打算在現代緩存中實現高效運行。我又一次提到程序語言設計的局限性以及其帶給程序員無法編寫高效的代碼的「壓力」。大部分的理論上的解決方法其實都非常的不便,這裡我說的是那些編程語言「希望」你這樣編寫的慣用寫法。
C# 最基本的問題是對 基礎值類型 低下的支持性。其大部分的數據結構都是「內置」在語言內定義的(例如:棧,或其他內置對象)。但這些具有幫助性的內置結構體有一些大問題,以至於更像是創可貼而不是解決方案。
- 你得把自己定義的結構體類型在最先聲明——這意味著你如果需要用到這個類型作為堆分配,那麼所有的結構體都會被堆分配。你也可以使用一些類包裝器來打包你的結構體和其中的成員變數,但這十分的痛苦。如果類和結構體可以相同的方式聲明,並且可根據具體情況來使用,這將是更好的。當數據可以作為值地存儲在自定義的棧中,當這個數據需要被堆分配時你就可以將其定義為一個對象,比如 C++ 就是這樣工作的。因為只有少數的內容需要被堆分配,所以我們不鼓勵所有的內容都被定義為對象類型。
- 引用 值被苛刻的限制。你可以將一個引用值傳給函數,但只能這樣。你不能直接引用
List<int>中的元素,你必須先把所有的引用和索引全部存儲下來。你不能直接取得指向棧、對象中的變數(或其他變數)的指針。你只能把它們複製一份,除了將它們傳給一個函數(使用引用的方式)。當然這也是可以理解的。如果類型安全是一個先驅條件,靈活的引用變數和保證類型安全這兩項要同時支持太難了(雖然不是不可能)。這些限制背後的理念並不能改變限制存在的事實。 - 固定大小的緩衝區 不支持自定義類型,而且還必須使用
unsafe關鍵字。 - 有限的「數組切片」功能。雖然有提供
ArraySegment類,但並沒有人會使用它,這意味著如果只需要傳遞數組的一部分,你必須去創建一個IEnumerable對象,也就意味著要分配大小(包裝)。就算介面接受ArraySegment對象作為參數,也是不夠的——你只能用普通數組,而不能用List<T>,也不能用 棧數組 等等。
最重要的是,除了非常簡單的情況之外,C# 非常慣用堆分配。如果所有的數據都被堆分配,這意味著被訪問時會造成緩存未命中(從你無法決定對象是如何在堆中存儲開始)。所以當 C++ 程序面臨著如何有效的組織數據在緩存中的存儲這個挑戰時,C# 則鼓勵程序員去將數據分開地存放在一個個堆分配空間中。這就意味著程序員無法控制數據存儲方式了,也開始產生不必要的緩存未命中問題,而導致性能急速的下降。C# 已經支持原生編譯 也不會提升太多性能——畢竟在內存不足的情況下,提高代碼質量本就杯水車薪。
再加上存儲是有開銷的。在 64 位的機器上每個地址值占 8 位內存,而每次分配都會有存儲元數據而產生的開銷。與存儲著少量大數據(以固定偏移的方式存儲在其中)的堆相比,存儲著大量小數據的堆(並且其中的數據到處都被引用)會產生更多的內存開銷。儘管你可能不怎麼關心內存怎麼用,但事實上就是那些頭部內容和地址信息導致堆變得臃腫,也就是在浪費緩存了,所以也造成了更多的緩存未命中,降低了代碼性能。
當然有些時候也是有辦法的,比如你可以使用一個很大的 List<T> 來構造數據池以存儲分配你需要的數據和自己的結構體。這樣你就可以方便的遍歷或者批量更新你的數據池中的數據了。但這也會很混亂,因為無論你在哪要引用什麼對象都要先能引用這個池,然後每次引用都需要做數組索引。從上文可以得出,在 C# 中做類似這樣的處理的痛感比在 C++ 中做來的更痛,因為 C# 在設計時就是這樣。此外,通過這種方式來訪問池中的單個對象比直接將這個對象分配到內存來訪問更加的昂貴——前者你得先訪問池(這是個類)的地址,這意味著可能產生 2 次緩存未命中。你還可以通過複製 List<T> 的結構形式來避免更多的緩存未命中問題,但這就更難搞了。我就寫過很多類似的代碼,自然這樣的代碼只會水平很低而且容易出錯。
最後,我想說我指出的問題不僅是那些「熱門」的代碼。慣用手段編寫的 C# 代碼傾向於幾乎所有地方都用類和引用。意思就是在你的代碼中會頻率均勻地隨機出現數百次的運算周期損耗,使得操作的損耗似乎降低了。這雖然也可以被找出來,但你優化了這問題後,這還是一個 均勻變慢 的程序。
垃圾回收
在讀下文之前我會假設你已經知道為什麼在許多用例中垃圾回收是影響性能問題的重要原因。播放動畫時總是隨機的暫停通常都是大家都不能接受的吧。我會繼續解釋為什麼設計語言時還加劇了這個問題。
因為 C# 在處理變數上的一些局限性,它強烈不建議你去使用大內存塊分配來存儲很多裡面是內置對象的變數(可能存在棧中),這就使得你必須使用很多分配在堆中的小型類對象。說白了就是內存分配越多會導致花在垃圾回收上的時間就越多。
有些測評說 C# 或者 Java 是怎麼在一些特定的例子中打敗 C++ 的,其實是因為內存分配器都基於一種吞吐還算不錯的垃圾回收機制(廉價的分配,允許統一的釋放分配)。然而,這些測試場景都太特殊了。想要使 C# 的程序的內存分配率變得和那些非常普通的 C++ 程序都能達到的一樣就必須要耗費更大的精力來編寫它,所以這種比較就像是拿一個高度優化的管理程序和一個最簡單原生的程序相比較一樣。當你花同樣的精力來寫一個 C++ 程序時,肯定比你用 C# 來寫性能好的多。
我還是相信你可以寫出一套適用於高性能低延遲的應用的垃圾回收機制的(比如維護一個增量的垃圾回收,每次消耗固定的時間來做回收),但這還是不夠的,大部分的高級語言在設計時就沒考慮程序啟動時就會產生大量的垃圾,這將會是最大的問題。當你就像寫 C 一樣習慣的去少去在 C# 分配內存,垃圾回收在高性能應用中可能就不會暴露出很多的問題了。而就算你 真的 去實現了一個增量垃圾回收機制,這意味著你還可能需要為其做一個寫屏障——這就相當於又消耗了一些性能了。
看看 .Net 庫里那些基本類,內存分配幾乎無處不在!我數了下,在 .Net 核心框架 中公共類比結構體的數量多出 19 倍之多,為了使用它們,你就得把這些東西全都弄到內存中去。就算是 .Net 框架的創造者們也無法抵抗設計語言時的警告啊!我都不知道怎麼去統計了,使用基礎類庫時,你會很快意識到這不僅僅是值或對象的選擇問題了,就算如此也還是 伴隨 著超級多的內存分配。這一切都讓你覺得分配內存好像很容易一樣,其實怎麼可能呢,沒有內存分配你連一個整型值都沒法輸出!不說這個,就算你使用預分配的 StringBuilder,你要是不用標準庫來分配內存,也還不是連個整型都存不住。你要這麼問我那就挺蠢的了。
當然還不僅僅是標準庫,其他的 C# 庫也一樣。就算是 Unity(一個 遊戲引擎,可能能更多的關心平均性能問題)也會有一些全局返回已分配對象(或數組)的介面,或者強制調用時先將其分配內存再使用。舉個例子,在一個 GameObject 中要使用 GetComponents 來調用一個數組,Unity 會強制地分配一個數組以便調用。就此而言,其實有許多的介面可以採用,但他們不選擇,而去走常規路線來直接使用內存分配。寫 Unity 的同胞們寫的一手「好 C#」呀,但就是不那麼高性能罷了。
結語
如果你在設計一門新的語言,拜託你可以考慮一下我提到的那些性能問題。在你創造出一款「足夠聰明的編譯器」之後這些都不是什麼難題了。當然,沒有垃圾回收器就要求類型安全很難。當然,沒有一個規範的數據表示就創造一個垃圾回收器很難。當然,出現指向隨機值的指針時難以去推出其作用域規則。當然,還有大把大把的問題擺在那裡,然而解決了這些所有的問題,設計出來的語言就會是我們想的那樣嗎?那為什麼這麼多主要的語言都是在那些六十年代就已經被設計出的語言的基礎上迭代的呢?
儘管你不能修復這些問題,但也許你可以儘可能的靠近?或者可以使用域類型(比如 Rust 語言)去保證其類型安全。或者也許可以考慮直接放棄「類型安全成本」去使用更多的運行時檢查(如果這不會造成更多的緩存未命中的話,這其實沒什麼所謂。其實 C# 也有類似的東西,叫協變式數組,嚴格上講是違背系統數據類型的,會導致一些運行時異常)。
如果你想在高性能場景中替代 C++,最基本的一點就是要考慮數據的存放布局和存儲方式。
作者簡介:
我叫 Sebastian Sylvan。我來自瑞典,目前居住在西雅圖。我在微軟工作,研究全息透鏡。誠然我的觀點僅代表本人,與微軟公司無關。
我的博客以圖像、編程語言、性能等內容為主。聯繫我請點擊我的 Twitter 或 E-mail。
via: https://www.sebastiansylvan.com/post/why-most-high-level-languages-are-slow
作者:Sebastian Sylvan 譯者:kenxx 校對:wxy
本文轉載來自 Linux 中國: https://github.com/Linux-CN/archive
對這篇文章感覺如何?
You may also like






More in:Linux中國

捐贈 Let's Encrypt,共建安全的互聯網

Let's Encrypt 正式發布,已經保護 380 萬個域名

關於Linux防火牆iptables的面試問答

Lets Encrypt 已被所有主流瀏覽器所信任









