為什麼計算機採用 8 位位元組

我正在製作一份有關計算機以二進位表示事物的小冊子,有人問我一個問題 - 為什麼 x86 架構使用 8 位位元組?為什麼不能是其他大小呢?
對於類似這樣的問題,我認為有兩種可能性:
- 這是歷史原因造成的,其他尺寸(如 4、6 或 16 位)同樣有效。
- 8 位是客觀上的最佳選擇,即使歷史發展不同,我們仍然會使用 8 位位元組。
- 一些混合 1 和 2 的因素。
我對計算機歷史並不是非常著迷(與閱讀計算機文獻相比,我更喜歡使用計算機),但我總是很好奇計算機事物今天的方式是否存在本質原因,或者它們大多是歷史偶然的結果。因此,我們將談論一些計算機歷史。
作為歷史偶然性的一個例子:DNS 有一個 class 欄位,它有 5 種可能的值(internet、chaos、hesiod、none 和 any)。 對我來說,這是一個明顯的歷史意外的例子 - 如果我們今天重新設計 DNS 而不必擔心向後兼容性,我無法想像我們會以相同的方式定義類欄位。我不確定我們是否會使用 class 欄位!
這篇文章沒有明確的答案,但我在 Mastodon 上提問,並找到了一些潛在的 8 位位元組原因。我認為答案是這些原因的某種組合。
位元組和字有什麼區別?
首先,本文中經常提到 「 位元組 」 和 「 字 」。它們有什麼區別?我的理解是:
- 位元組的大小 是你可以定址的最小單元。例如,在我的計算機上,程序中的
0x20aa87c68可能是一個位元組的地址,然後0x20aa87c69是下一個位元組的地址。 - 字的大小 是位元組大小的某個倍數。我對此困惑了多年,維基百科的定義非常模糊(「字是特定處理器設計使用的自然數據單元」)。我最初認為字大小與寄存器大小相同(在 x86-64 上為 64 位)。但是根據 英特爾架構手冊 的第 4.1 節(「基本數據類型」),在 x86 上,雖然寄存器是 64 位的,但一個字是 16 位的。因此我困惑了 —— 在 x86 上,一個字是 16 位還是 64 位?它可以根據上下文而有不同的含義嗎?這是怎麼回事?
現在讓我們來討論一些使用 8 位位元組的可能原因!
原因 1:將英文字母適配到 1 位元組中
維基百科文章 表示 IBM System/360 於 1964 年引入了 8 位位元組。
在管理該項目的 Fred Brooks 的一段 視頻採訪 中,他講述了原因。以下是我轉錄的一些內容:
…… 6 位位元組在科學計算中確實更好,而 8 位位元組則更適合商業計算,每個位元組都可以針對另一個位元組進行調整,以使兩種位元組互相使用。
因此,這變成了一個高管決策,我決定根據 Jerry 的建議採用 8 位位元組。
……
我在我的 IBM 職業生涯中做出的最重要的技術決策是為 360 選擇 8 位位元組。
我相信字元處理將變得重要,而不是十進位數字。
使用 8 位位元組處理文本很有道理:2 6 為 64,因此 6 位不足以表示小寫字母、大寫字母和符號。
為了使用 8 位位元組,System/360 還引入了 EBCDIC 編碼,這是一種 8 位字元編碼。
接下來在 8 位位元組歷史上重要的機器似乎是 英特爾 8008,它設計用於計算機終端(Datapoint 2200)。終端需要能夠表示字母以及終端控制代碼,因此使用 8 位位元組對其來說很有意義。計算機歷史博物館上的 Datapoint 2200 手冊 在第 7 頁上說 Datapoint 2200 支持 ASCII(7 位)和 EBCDIC(8 位)。
為什麼 6 位位元組在科學計算中更好?
我對這條 「6 位位元組在科學計算中更好」 的評論很好奇。以下是 Gene Amdahl 的一段採訪摘錄:
我原本希望採用 24 和 48 而非 32 和 64,因為這將為我提供一個更合理的浮點系統。因為在浮點運算中,使用 32 位字大小時,你必須將指數保持在 8 位中用於指數符號,並且要使其在數字範圍上合理,你必須每次調整 4 個位而不是單個位。因此,這將導致你比使用二進位移位更快地失去一些信息。
我完全不理解這條評論 - 如果你使用 32 位字大小,為什麼指數必須是 8 位?如果你想要,為什麼不能使用 9 位或 10 位?但這是我在快速搜索中找到的全部內容。
為什麼大型機使用 36 位?
與 6 位位元組相關的問題是:許多大型機使用 36 位字大小。為什麼?在維基百科的 36 位計算 文章中有一個很好的解釋:
在計算機問世之前,即需要高精度科學和工程運算的領域,使用的是十位數碼電動機械計算器……這些計算器每位數碼均有一個專用按鍵,操作人員在輸入數字時需要用到所有手指,因此,雖然有些專業計算器有更多位數碼,但這種情況是個實際的限制。
因此,早期針對相同市場的二進位計算機通常使用 36 位字長度。這足以表示正負整數最高精度到十位數字(最小應為 35 位)。
因此,這種 36 位大小似乎是基於
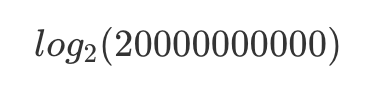
的,它等於 34.2。嗯。
我猜這個原因是在 50 年代,計算機非常昂貴。因此,如果您想要你的計算機支持十位十進位數字,你將設計它恰好具有足夠的位來執行此操作,而不會更多。
現在計算機更快更便宜,因此,如果您想要出於某種原因表示十位十進位數字,你只需使用 64 位即可 - 浪費一點空間通常並不會有太大問題。
還有人提到,一些具有 36 位字大小的計算機可以讓你選擇位元組大小 - 根據上下文,你可以使用 5 或 6 或 7 或 8 位位元組。
原因 2:與二進位編碼的十進位一起工作
20 世紀 60 年代,有一種流行的整數編碼叫做 二進位編碼的十進位 (縮寫為 BCD),它將每個十進位數字編碼為 4 位。
例如,如果你想要編碼數字 1234,在 BCD 中,它會是這樣的:
0001 0010 0011 0100
因此,如果你想要能夠輕鬆地與二進位編碼的十進位一起工作,你的位元組大小應該是 4 位的倍數,比如 8 位!
為什麼 BCD 很流行?
這個整數表示方法對我來說真的很奇怪 —— 為什麼不用更有效率的二進位來存儲整數呢?在早期的計算機中,效率非常重要!
我最好的猜測是,早期的計算機沒有像我們現在這樣的顯示器,所以一個位元組的內容被直接映射到開關燈上。
這是來自維基百科一個帶有一些亮燈的 IBM 650 顯示器的圖片(CC BY-SA 3.0 許可):

因此,如果你想讓人們能夠相對容易地從二進位表示中讀取十進位數,這樣做就更有意義了。我認為,今天 BCD 已經過時了,因為我們擁有顯示器,並且我們的計算機可以將用二進位表示的數字轉換為十進位,並顯示它們。
此外,我想知道,「 四位 」(意為 「4 位」)這個詞是不是來自 BCD 的。在 BCD 的上下文中,你經常會引用半個位元組(因為每個十進位數字是 4 位)。所以有一個 「4 位」 的詞語是有意義的,人們稱 4 個位為 「 四位 」。今天,「四位」 對我來說感覺像是一個古老的辭彙,除了作為一個趣聞我肯定從未使用過它(它是一個很有趣的詞!)。維基百科關於 「四位」 的文章支持了這個理論:
「四位」 用來描述存儲在 IBM 大型計算機中打包的十進位格式(BCD)中數字的位數。
還有一個人提到 BCD 的另一個原因是 金融計算。今天,如果你想存儲美元金額,你通常只需使用整數的分數,然後在需要美元部分時除以 100。這沒什麼大不了的,除法很快。但顯然,在 70 年代,將一個用二進位表示的整數除以一個 100 是非常慢的,所以重新設計如何表示整數,以避免除以 100 是值得的。
好了,關於 BCD 就說這麼多。
原因 3:8 是 2 的冪?
許多人說,CPU 的位元組大小是 2 的冪次方很重要。我無法確定這是真的還是假的,而且我對 「計算機使用二進位,所以 2 的冪次方很好」 這種解釋感到不滿意。這似乎非常合理,但我想深入探討一下。而且從歷史上看,肯定有很多使用位元組大小不是 2 的冪次方的機器,例如(來自這個來自 Stack Exchange 上復古計算版塊的 帖子):
- Cyber 180 大型機使用 6 位位元組
- Univac 1100/2200 系列使用 36 位字長
- PDP-8 是一台 12 位計算機
一些我聽到的關於 2 的冪次方很好的原因我還沒有理解:
- 一個單詞中的每個位都需要一個匯流排,而你希望匯流排數量是 2 的冪次方(為什麼?)
- 很多電路邏輯容易針對分而治之的技術(我需要一個例子來理解這個)
對我更有意義的原因是:
- 它使設計「時鐘分頻器」更容易,這些分頻器可以測量「在這條線路上發送了 8 位」,分別基於減半進行操作 - 你可以將 3 個減半時鐘分頻器串聯起來。Graham Sutherland 告訴我這個,他製作了這個非常酷的 分頻器模擬器,展示了這些分頻器的工作原理。該網站(Falstad)還有很多其他示例電路,似乎是製作電路模擬器的一個非常酷的方式。
- 如果你有一個指令可以將位元組中的特定位清零,則如果你的位元組大小為 8(2 的 3 次方),你可以只使用 3 位指令來指示哪一位。x86 似乎沒有這樣做,但 Z80 的位測試指令 是這樣做的。
- 有人提到一些處理器使用 進位前瞻加法器,它們按 4 位分組。經過一些快速的谷歌搜索,似乎有各種各樣的加法器電路。
- 點陣圖:你計算機的內存被組織成頁(通常大小為 2 的 n 次方)。它需要跟蹤每一頁是否空閑。操作系統使用點陣圖來完成這項工作,其中每個位對應一頁,並且根據頁面是空閑還是佔用,值為 0 或 1。如果你有一個 9 位的位元組,你需要除以 9 來在點陣圖中找到你要查找的頁面。除以 9 的速度比除以 8 慢,因為除以 2 的冪次方總是最快的。
我可能很糟糕地扭曲了其中一些解釋:在這裡,我非常超出了自己的知識領域。我們繼續前進吧。
原因 4:小位元組大小很好
你可能會想:好吧,如果 8 位位元組比 4 位位元組更好,為什麼不繼續增加位元組大小呢?我們可以有 16 位位元組啊!
有幾個保持位元組大小較小的理由:
- 它是一種空間浪費 —— 位元組是你可以定址的最小單位,如果你的計算機存儲了大量的 ASCII 文本(只需要 7 位),那麼每個字元分配 12 或 16 個位相當浪費,而你可以使用 8 個位代替。
- 隨著位元組變得越來越大,你的 CPU 需要變得更複雜。例如,你需要每個位線路一條匯流排線路。因此,我想簡單總是更好。
我對 CPU 架構的理解非常薄弱,所以就說到這裡吧。對我來說,「這是一種空間浪費」 的理由似乎相當有說服力。
原因 5:兼容性
英特爾 8008(1972 年)是 8080(1974 年)的前身,8080 是第一款 x86 處理器 8086(1976 年)的前身。似乎 8080 和 8086 很受歡迎,這就是我們現代 x86 計算機的來源。
我認為這裡有一個 「如果它好好的就不要動它」 的問題 - 我假設 8 位位元組功能良好,因此英特爾看不到需要更改設計的必要性。如果你保持相同的 8 位位元組,那麼你可以重複使用更多指令集。
此外,80 年代左右我們開始出現像 TCP 這樣的網路協議,它們使用 8 位位元組(通常稱為「 八位組 」),如果你要實現網路協議,你可能希望使用 8 位位元組。
就這些!
在我看來,8 位位元組的主要原因是:
- 很多早期的電腦公司都是美國的,美國使用最廣泛的語言是英語
- 這些人希望計算機擅長文本處理
- 較小的位元組大小通常更好
- 7 位是你可以用來容納所有英文字母和標點符號的最小尺寸
- 8 比 7 更好(因為它是 2 的冪次方)
- 一旦有得到成功應用的受歡迎的 8 位計算機,你希望保持相同的設計以實現兼容性。
有人指出 這本 1962 年的書 第 65 頁談到了 IBM 選擇 8 位位元組的原因,基本上說了相同的內容:
- 其完整的 256 個字元的容量被認為足以滿足絕大多數應用程序的需要。
- 在該容量範圍內,單個字元由單個位元組表示,因此任何特定記錄的長度並不因該記錄中字元而異。
- 8 位位元組在存儲空間上是相當經濟的。
- 對於純數字工作,一個十進位數字只需要 4 個比特表示,兩個這樣的 4 位位元組可以打包成一個 8 位位元組。儘管這種數字數據包裝不是必需的,但為了提高速度和存儲效率,它是一種常見做法。嚴格來說,4 位位元組屬於不同的代碼,但與 4 位及 8 位方案相比,它們的簡單性導致了更簡單的機器設計和更清晰的定址邏輯。
- 4 位和 8 位的位元組大小,作為 2 的冪次方,允許計算機設計師利用二進位定址和位級索引的強大功能(見第 4 章和第 5 章)。
總的來說,如果你在英語國家設計二進位計算機,選擇 8 位位元組似乎是一個非常自然的選擇。
(題圖:MJ/3526a0d5-bee5-4678-8637-e96e9843b53c)
via: https://jvns.ca/blog/2023/03/06/possible-reasons-8-bit-bytes/
作者:Julia Evans 選題:lkxed 譯者:ChatGPT 校對:wxy
本文轉載來自 Linux 中國: https://github.com/Linux-CN/archive
對這篇文章感覺如何?
You may also like






More in:Linux中國

捐贈 Let's Encrypt,共建安全的互聯網

Let's Encrypt 正式發布,已經保護 380 萬個域名

關於Linux防火牆iptables的面試問答

Lets Encrypt 已被所有主流瀏覽器所信任









