Python 集合是什麼,為什麼應該使用以及如何使用?

Python 配備了幾種內置數據類型來幫我們組織數據。這些結構包括列表、字典、元組和集合。
根據 Python 3 文檔:
集合是一個無序集合,沒有重複元素。基本用途包括成員測試和消除重複的條目。集合對象還支持數學運算,如並集、交集、差集和對等差分。
在本文中,我們將回顧並查看上述定義中列出的每個要素的示例。讓我們馬上開始,看看如何創建它。
初始化一個集合
有兩種方法可以創建一個集合:一個是給內置函數 set() 提供一個元素列表,另一個是使用花括弧 {}。
使用內置函數 set() 來初始化一個集合:
>>> s1 = set([1, 2, 3])
>>> s1
{1, 2, 3}
>>> type(s1)
<class 'set'>
使用 {}:
>>> s2 = {3, 4, 5}
>>> s2
{3, 4, 5}
>>> type(s2)
<class 'set'>
>>>
如你所見,這兩種方法都是有效的。但問題是,如果我們想要一個空的集合呢?
>>> s = {}
>>> type(s)
<class 'dict'>
沒錯,如果我們使用空花括弧,我們將得到一個字典而不是一個集合。=)
值得一提的是,為了簡單起見,本文中提供的所有示例都將使用整數集合,但集合可以包含 Python 支持的所有 可哈希的 數據類型。換句話說,即整數、字元串和元組,而不是列表或字典這樣的可變類型。
>>> s = {1, 'coffee', [4, 'python']}
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
TypeError: unhashable type: 'list'
既然你知道了如何創建一個集合以及它可以包含哪些類型的元素,那麼讓我們繼續看看為什麼我們總是應該把它放在我們的工具箱中。
為什麼你需要使用它
寫代碼時,你可以用不止一種方法來完成它。有些被認為是相當糟糕的,另一些則是清晰的、簡潔的和可維護的,或者是 「 Python 式的 」。
當一個經驗豐富的 Python 開發人員( Python 人 )調用一些不夠 「 Python 式的 」 的代碼時,他們通常認為著這些代碼不遵循通用指南,並且無法被認為是以一種好的方式(可讀性)來表達意圖。
讓我們開始探索 Python 集合那些不僅可以幫助我們提高可讀性,還可以加快程序執行時間的方式。
無序的集合元素
首先你需要明白的是:你無法使用索引訪問集合中的元素。
>>> s = {1, 2, 3}
>>> s[0]
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
TypeError: 'set' object does not support indexing
或者使用切片修改它們:
>>> s[0:2]
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
TypeError: 'set' object is not subscriptable
但是,如果我們需要刪除重複項,或者進行組合列表(與)之類的數學運算,那麼我們可以,並且應該始終使用集合。
我不得不提一下,在迭代時,集合的表現優於列表。所以,如果你需要它,那就加深對它的喜愛吧。為什麼?好吧,這篇文章並不打算解釋集合的內部工作原理,但是如果你感興趣的話,這裡有幾個鏈接,你可以閱讀它:
沒有重複項
寫這篇文章的時候,我總是不停地思考,我經常使用 for 循環和 if 語句檢查並刪除列表中的重複元素。記得那時我的臉紅了,而且不止一次,我寫了類似這樣的代碼:
>>> my_list = [1, 2, 3, 2, 3, 4]
>>> no_duplicate_list = []
>>> for item in my_list:
... if item not in no_duplicate_list:
... no_duplicate_list.append(item)
...
>>> no_duplicate_list
[1, 2, 3, 4]
或者使用列表解析:
>>> my_list = [1, 2, 3, 2, 3, 4]
>>> no_duplicate_list = []
>>> [no_duplicate_list.append(item) for item in my_list if item not in no_duplicate_list]
[None, None, None, None]
>>> no_duplicate_list
[1, 2, 3, 4]
但沒關係,因為我們現在有了武器裝備,沒有什麼比這更重要的了:
>>> my_list = [1, 2, 3, 2, 3, 4]
>>> no_duplicate_list = list(set(my_list))
>>> no_duplicate_list
[1, 2, 3, 4]
>>>
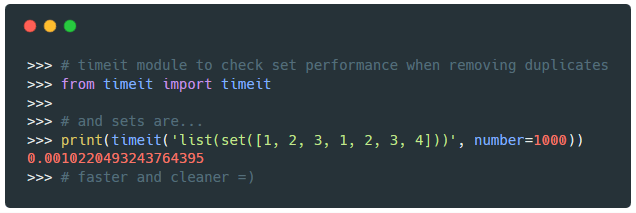
現在讓我們使用 timeit 模塊,查看列表和集合在刪除重複項時的執行時間:
>>> from timeit import timeit
>>> def no_duplicates(list):
... no_duplicate_list = []
... [no_duplicate_list.append(item) for item in list if item not in no_duplicate_list]
... return no_duplicate_list
...
>>> # 首先,讓我們看看列表的執行情況:
>>> print(timeit('no_duplicates([1, 2, 3, 1, 7])', globals=globals(), number=1000))
0.0018683355819786227
>>> from timeit import timeit
>>> # 使用集合:
>>> print(timeit('list(set([1, 2, 3, 1, 2, 3, 4]))', number=1000))
0.0010220493243764395
>>> # 快速而且乾淨 =)
使用集合而不是列表推導不僅讓我們編寫更少的代碼,而且還能讓我們獲得更具可讀性和高性能的代碼。
注意:請記住集合是無序的,因此無法保證在將它們轉換回列表時,元素的順序不變。
優美勝於醜陋
明了勝於晦澀
簡潔勝於複雜
扁平勝於嵌套
集合不正是這樣美麗、明了、簡單且扁平嗎?
成員測試
每次我們使用 if 語句來檢查一個元素,例如,它是否在列表中時,意味著你正在進行成員測試:
my_list = [1, 2, 3]
>>> if 2 in my_list:
... print('Yes, this is a membership test!')
...
Yes, this is a membership test!
在執行這些操作時,集合比列表更高效:
>>> from timeit import timeit
>>> def in_test(iterable):
... for i in range(1000):
... if i in iterable:
... pass
...
>>> timeit('in_test(iterable)',
... setup="from __main__ import in_test; iterable = list(range(1000))",
... number=1000)
12.459663048726043
>>> from timeit import timeit
>>> def in_test(iterable):
... for i in range(1000):
... if i in iterable:
... pass
...
>>> timeit('in_test(iterable)',
... setup="from __main__ import in_test; iterable = set(range(1000))",
... number=1000)
.12354438152988223
注意:上面的測試來自於這個 StackOverflow 話題。
因此,如果你在巨大的列表中進行這樣的比較,嘗試將該列錶轉換為集合,它應該可以加快你的速度。
如何使用
現在你已經了解了集合是什麼以及為什麼你應該使用它,現在讓我們快速瀏覽一下,看看我們如何修改和操作它。
添加元素
根據要添加的元素數量,我們要在 add() 和 update() 方法之間進行選擇。
add() 適用於添加單個元素:
>>> s = {1, 2, 3}
>>> s.add(4)
>>> s
{1, 2, 3, 4}
update() 適用於添加多個元素:
>>> s = {1, 2, 3}
>>> s.update([2, 3, 4, 5, 6])
>>> s
{1, 2, 3, 4, 5, 6}
請記住,集合會移除重複項。
移除元素
如果你希望在代碼中嘗試刪除不在集合中的元素時收到警報,請使用 remove()。否則,discard() 提供了一個很好的選擇:
>>> s = {1, 2, 3}
>>> s.remove(3)
>>> s
{1, 2}
>>> s.remove(3)
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
KeyError: 3
discard() 不會引起任何錯誤:
>>> s = {1, 2, 3}
>>> s.discard(3)
>>> s
{1, 2}
>>> s.discard(3)
>>> # 什麼都不會發生
我們也可以使用 pop() 來隨機丟棄一個元素:
>>> s = {1, 2, 3, 4, 5}
>>> s.pop() # 刪除一個任意的元素
1
>>> s
{2, 3, 4, 5}
或者 clear() 方法來清空一個集合:
>>> s = {1, 2, 3, 4, 5}
>>> s.clear() # 清空集合
>>> s
set()
union()
union() 或者 | 將創建一個新集合,其中包含我們提供集合中的所有元素:
>>> s1 = {1, 2, 3}
>>> s2 = {3, 4, 5}
>>> s1.union(s2) # 或者 's1 | s2'
{1, 2, 3, 4, 5}
intersection()
intersection 或 & 將返回一個由集合共同元素組成的集合:
>>> s1 = {1, 2, 3}
>>> s2 = {2, 3, 4}
>>> s3 = {3, 4, 5}
>>> s1.intersection(s2, s3) # 或者 's1 & s2 & s3'
{3}
difference()
使用 diference() 或 - 創建一個新集合,其值在 「s1」 中但不在 「s2」 中:
>>> s1 = {1, 2, 3}
>>> s2 = {2, 3, 4}
>>> s1.difference(s2) # 或者 's1 - s2'
{1}
symmetric_diference()
symetric_difference 或 ^ 將返回集合之間的不同元素。
>>> s1 = {1, 2, 3}
>>> s2 = {2, 3, 4}
>>> s1.symmetric_difference(s2) # 或者 's1 ^ s2'
{1, 4}
結論
我希望在閱讀本文之後,你會知道集合是什麼,如何操縱它的元素以及它可以執行的操作。知道何時使用集合無疑會幫助你編寫更清晰的代碼並加速你的程序。
如果你有任何疑問,請發表評論,我很樂意嘗試回答。另外,不要忘記,如果你已經理解了集合,它們在 Python Cheatsheet 中有自己的一席之地,在那裡你可以快速參考並重新認知你已經知道的內容。
via: https://www.pythoncheatsheet.org/blog/python-sets-what-why-how
作者:wilfredinni 譯者:MjSeven 校對:wxy
本文轉載來自 Linux 中國: https://github.com/Linux-CN/archive
對這篇文章感覺如何?
You may also like






More in:Linux中國

捐贈 Let's Encrypt,共建安全的互聯網

Let's Encrypt 正式發布,已經保護 380 萬個域名

關於Linux防火牆iptables的面試問答

Lets Encrypt 已被所有主流瀏覽器所信任









