在數據科學中使用 C 和 C++
雖然 Python 和 R 之類的語言在數據科學中越來越受歡迎,但是 C 和 C++ 對於高效的數據科學來說是一個不錯的選擇。在本文中,我們將使用 C99 和 C++11 編寫一個程序,該程序使用 Anscombe 的四重奏數據集,下面將對其進行解釋。
我在一篇涉及 Python 和 GNU Octave 的文章中寫了我不斷學習編程語言的動機,值得大家回顧。這裡所有的程序都需要在命令行上運行,而不是在圖形用戶界面(GUI)上運行。完整的示例可在 polyglot_fit 存儲庫中找到。
編程任務
你將在本系列中編寫的程序:
- 從 CSV 文件中讀取數據
- 用直線插值數據(即
f(x)=m ⋅ x + q) - 將結果繪製到圖像文件
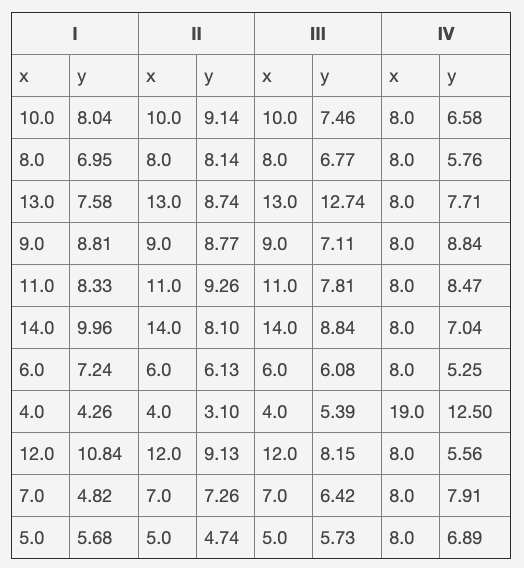
這是許多數據科學家遇到的普遍情況。示例數據是 Anscombe 的四重奏的第一組,如下表所示。這是一組人工構建的數據,當擬合直線時可以提供相同的結果,但是它們的曲線非常不同。數據文件是一個文本文件,其中的製表符用作列分隔符,前幾行作為標題。該任務將僅使用第一組(即前兩列)。
C 語言的方式
C 語言是通用編程語言,是當今使用最廣泛的語言之一(依據 TIOBE 指數、RedMonk 編程語言排名、編程語言流行度指數和 GitHub Octoverse 狀態 得來)。這是一種相當古老的語言(大約誕生在 1973 年),並且用它編寫了許多成功的程序(例如 Linux 內核和 Git 僅是其中的兩個例子)。它也是最接近計算機內部運行機制的語言之一,因為它直接用於操作內存。它是一種編譯語言;因此,源代碼必須由編譯器轉換為機器代碼。它的標準庫很小,功能也不多,因此人們開發了其它庫來提供缺少的功能。
我最常在數字運算中使用該語言,主要是因為其性能。我覺得使用起來很繁瑣,因為它需要很多樣板代碼,但是它在各種環境中都得到了很好的支持。C99 標準是最新版本,增加了一些漂亮的功能,並且得到了編譯器的良好支持。
我將一路介紹 C 和 C++ 編程的必要背景,以便初學者和高級用戶都可以繼續學習。
安裝
要使用 C99 進行開發,你需要一個編譯器。我通常使用 Clang,不過 GCC 是另一個有效的開源編譯器。對於線性擬合,我選擇使用 GNU 科學庫。對於繪圖,我找不到任何明智的庫,因此該程序依賴於外部程序:Gnuplot。該示例還使用動態數據結構來存儲數據,該結構在伯克利軟體分發版(BSD)中定義。
在 Fedora 中安裝很容易:
sudo dnf install clang gnuplot gsl gsl-devel代碼注釋
在 C99 中,注釋的格式是在行的開頭放置 //,行的其它部分將被解釋器丟棄。另外,/* 和 */ 之間的任何內容也將被丟棄。
// 這是一個注釋,會被解釋器忽略
/* 這也被忽略 */必要的庫
庫由兩部分組成:
- 頭文件,其中包含函數說明
- 包含函數定義的源文件
頭文件包含在源文件中,而庫文件的源文件則鏈接到可執行文件。因此,此示例所需的頭文件是:
// 輸入/輸出功能
#include <stdio.h>
// 標準庫
#include <stdlib.h>
// 字元串操作功能
#include <string.h>
// BSD 隊列
#include <sys/queue.h>
// GSL 科學功能
#include <gsl/gsl_fit.h>
#include <gsl/gsl_statistics_double.h>主函數
在 C 語言中,程序必須位於稱為主函數 main() 的特殊函數內:
int main(void) {
...
}這與上一教程中介紹的 Python 不同,後者將運行在源文件中找到的所有代碼。
定義變數
在 C 語言中,變數必須在使用前聲明,並且必須與類型關聯。每當你要使用變數時,都必須決定要在其中存儲哪種數據。你也可以指定是否打算將變數用作常量值,這不是必需的,但是編譯器可以從此信息中受益。 以下來自存儲庫中的 fitting_C99.c 程序:
const char *input_file_name = "anscombe.csv";
const char *delimiter = "t";
const unsigned int skip_header = 3;
const unsigned int column_x = 0;
const unsigned int column_y = 1;
const char *output_file_name = "fit_C99.csv";
const unsigned int N = 100;C 語言中的數組不是動態的,從某種意義上說,數組的長度必須事先確定(即,在編譯之前):
int data_array[1024];由於你通常不知道文件中有多少個數據點,因此請使用單鏈列表。這是一個動態數據結構,可以無限增長。幸運的是,BSD 提供了鏈表。這是一個示例定義:
struct data_point {
double x;
double y;
SLIST_ENTRY(data_point) entries;
};
SLIST_HEAD(data_list, data_point) head = SLIST_HEAD_INITIALIZER(head);
SLIST_INIT(&head);該示例定義了一個由結構化值組成的 data_point 列表,該結構化值同時包含 x 值和 y 值。語法相當複雜,但是很直觀,詳細描述它就會太冗長了。
列印輸出
要在終端上列印,可以使用 printf() 函數,其功能類似於 Octave 的 printf() 函數(在第一篇文章中介紹):
printf("#### Anscombe's first set with C99 ####n");printf() 函數不會在列印字元串的末尾自動添加換行符,因此你必須添加換行符。第一個參數是一個字元串,可以包含傳遞給函數的其他參數的格式信息,例如:
printf("Slope: %fn", slope);讀取數據
現在來到了困難的部分……有一些用 C 語言解析 CSV 文件的庫,但是似乎沒有一個庫足夠穩定或流行到可以放入到 Fedora 軟體包存儲庫中。我沒有為本教程添加依賴項,而是決定自己編寫此部分。同樣,討論這些細節太啰嗦了,所以我只會解釋大致的思路。為了簡潔起見,將忽略源代碼中的某些行,但是你可以在存儲庫中找到完整的示例代碼。
首先,打開輸入文件:
FILE* input_file = fopen(input_file_name, "r");然後逐行讀取文件,直到出現錯誤或文件結束:
while (!ferror(input_file) && !feof(input_file)) {
size_t buffer_size = 0;
char *buffer = NULL;
getline(&buffer, &buffer_size, input_file);
...
}getline() 函數是 POSIX.1-2008 標準新增的一個不錯的函數。它可以讀取文件中的整行,並負責分配必要的內存。然後使用 strtok() 函數將每一行分成 字元 。遍歷字元,選擇所需的列:
char *token = strtok(buffer, delimiter);
while (token != NULL)
{
double value;
sscanf(token, "%lf", &value);
if (column == column_x) {
x = value;
} else if (column == column_y) {
y = value;
}
column += 1;
token = strtok(NULL, delimiter);
}最後,當選擇了 x 和 y 值時,將新數據點插入鏈表中:
struct data_point *datum = malloc(sizeof(struct data_point));
datum->x = x;
datum->y = y;
SLIST_INSERT_HEAD(&head, datum, entries);malloc() 函數為新數據點動態分配(保留)一些持久性內存。
擬合數據
GSL 線性擬合函數 gslfitlinear() 期望其輸入為簡單數組。因此,由於你將不知道要創建的數組的大小,因此必須手動分配它們的內存:
const size_t entries_number = row - skip_header - 1;
double *x = malloc(sizeof(double) * entries_number);
double *y = malloc(sizeof(double) * entries_number);然後,遍歷鏈表以將相關數據保存到數組:
SLIST_FOREACH(datum, &head, entries) {
const double current_x = datum->x;
const double current_y = datum->y;
x[i] = current_x;
y[i] = current_y;
i += 1;
}現在你已經處理完了鏈表,請清理它。要總是釋放已手動分配的內存,以防止內存泄漏。內存泄漏是糟糕的、糟糕的、糟糕的(重要的話說三遍)。每次內存沒有釋放時,花園侏儒都會找不到自己的頭:
while (!SLIST_EMPTY(&head)) {
struct data_point *datum = SLIST_FIRST(&head);
SLIST_REMOVE_HEAD(&head, entries);
free(datum);
}終於,終於!你可以擬合你的數據了:
gsl_fit_linear(x, 1, y, 1, entries_number,
&intercept, &slope,
&cov00, &cov01, &cov11, &chi_squared);
const double r_value = gsl_stats_correlation(x, 1, y, 1, entries_number);
printf("Slope: %fn", slope);
printf("Intercept: %fn", intercept);
printf("Correlation coefficient: %fn", r_value);繪圖
你必須使用外部程序進行繪圖。因此,將擬合數據保存到外部文件:
const double step_x = ((max_x + 1) - (min_x - 1)) / N;
for (unsigned int i = 0; i < N; i += 1) {
const double current_x = (min_x - 1) + step_x * i;
const double current_y = intercept + slope * current_x;
fprintf(output_file, "%ft%fn", current_x, current_y);
}用於繪製兩個文件的 Gnuplot 命令是:
plot 'fit_C99.csv' using 1:2 with lines title 'Fit', 'anscombe.csv' using 1:2 with points pointtype 7 title 'Data'結果
在運行程序之前,你必須編譯它:
clang -std=c99 -I/usr/include/ fitting_C99.c -L/usr/lib/ -L/usr/lib64/ -lgsl -lgslcblas -o fitting_C99這個命令告訴編譯器使用 C99 標準、讀取 fitting_C99.c 文件、載入 gsl 和 gslcblas 庫、並將結果保存到 fitting_C99。命令行上的結果輸出為:
#### Anscombe's first set with C99 ####
Slope: 0.500091
Intercept: 3.000091
Correlation coefficient: 0.816421這是用 Gnuplot 生成的結果圖像:

C++11 方式
C++ 語言是一種通用編程語言,也是當今使用的最受歡迎的語言之一。它是作為 C 的繼承人創建的(誕生於 1983 年),重點是面向對象程序設計(OOP)。C++ 通常被視為 C 的超集,因此 C 程序應該能夠使用 C++ 編譯器進行編譯。這並非完全正確,因為在某些極端情況下它們的行為有所不同。 根據我的經驗,C++ 與 C 相比需要更少的樣板代碼,但是如果要進行面向對象開發,語法會更困難。C++11 標準是最新版本,增加了一些漂亮的功能,並且基本上得到了編譯器的支持。
由於 C++ 在很大程度上與 C 兼容,因此我將僅強調兩者之間的區別。我在本部分中沒有涵蓋的任何部分,則意味著它與 C 中的相同。
安裝
這個 C++ 示例的依賴項與 C 示例相同。 在 Fedora 上,運行:
sudo dnf install clang gnuplot gsl gsl-devel必要的庫
庫的工作方式與 C 語言相同,但是 include 指令略有不同:
#include <cstdlib>
#include <cstring>
#include <iostream>
#include <fstream>
#include <string>
#include <vector>
#include <algorithm>
extern "C" {
#include <gsl/gsl_fit.h>
#include <gsl/gsl_statistics_double.h>
}由於 GSL 庫是用 C 編寫的,因此你必須將這個特殊情況告知編譯器。
定義變數
與 C 語言相比,C++ 支持更多的數據類型(類),例如,與其 C 語言版本相比,string 類型具有更多的功能。相應地更新變數的定義:
const std::string input_file_name("anscombe.csv");對於字元串之類的結構化對象,你可以定義變數而無需使用 = 符號。
列印輸出
你可以使用 printf() 函數,但是 cout 對象更慣用。使用運算符 << 來指示要使用 cout 列印的字元串(或對象):
std::cout << "#### Anscombe's first set with C++11 ####" << std::endl;
...
std::cout << "Slope: " << slope << std::endl;
std::cout << "Intercept: " << intercept << std::endl;
std::cout << "Correlation coefficient: " << r_value << std::endl;讀取數據
該方案與以前相同。將打開文件並逐行讀取文件,但語法不同:
std::ifstream input_file(input_file_name);
while (input_file.good()) {
std::string line;
getline(input_file, line);
...
}使用與 C99 示例相同的功能提取行字元。代替使用標準的 C 數組,而是使用兩個向量。向量是 C++ 標準庫中對 C 數組的擴展,它允許動態管理內存而無需顯式調用 malloc():
std::vector<double> x;
std::vector<double> y;
// Adding an element to x and y:
x.emplace_back(value);
y.emplace_back(value);擬合數據
要在 C++ 中擬合,你不必遍歷列表,因為向量可以保證具有連續的內存。你可以將向量緩衝區的指針直接傳遞給擬合函數:
gsl_fit_linear(x.data(), 1, y.data(), 1, entries_number,
&intercept, &slope,
&cov00, &cov01, &cov11, &chi_squared);
const double r_value = gsl_stats_correlation(x.data(), 1, y.data(), 1, entries_number);
std::cout << "Slope: " << slope << std::endl;
std::cout << "Intercept: " << intercept << std::endl;
std::cout << "Correlation coefficient: " << r_value << std::endl;繪圖
使用與以前相同的方法進行繪圖。 寫入文件:
const double step_x = ((max_x + 1) - (min_x - 1)) / N;
for (unsigned int i = 0; i < N; i += 1) {
const double current_x = (min_x - 1) + step_x * i;
const double current_y = intercept + slope * current_x;
output_file << current_x << "t" << current_y << std::endl;
}
output_file.close();然後使用 Gnuplot 進行繪圖。
結果
在運行程序之前,必須使用類似的命令對其進行編譯:
clang++ -std=c++11 -I/usr/include/ fitting_Cpp11.cpp -L/usr/lib/ -L/usr/lib64/ -lgsl -lgslcblas -o fitting_Cpp11命令行上的結果輸出為:
#### Anscombe's first set with C++11 ####
Slope: 0.500091
Intercept: 3.00009
Correlation coefficient: 0.816421這就是用 Gnuplot 生成的結果圖像:

結論
本文提供了用 C99 和 C++11 編寫的數據擬合和繪圖任務的示例。由於 C++ 在很大程度上與 C 兼容,因此本文利用了它們的相似性來編寫了第二個示例。在某些方面,C++ 更易於使用,因為它部分減輕了顯式管理內存的負擔。但是其語法更加複雜,因為它引入了為 OOP 編寫類的可能性。但是,仍然可以用 C 使用 OOP 方法編寫軟體。由於 OOP 是一種編程風格,因此可以在任何語言中使用。在 C 中有一些很好的 OOP 示例,例如 GObject 和 Jansson庫。
對於數字運算,我更喜歡在 C99 中進行,因為它的語法更簡單並且得到了廣泛的支持。直到最近,C++11 還沒有得到廣泛的支持,我傾向於避免使用先前版本中的粗糙不足之處。對於更複雜的軟體,C++ 可能是一個不錯的選擇。
你是否也將 C 或 C++ 用於數據科學?在評論中分享你的經驗。
via: https://opensource.com/article/20/2/c-data-science
作者:Cristiano L. Fontana 選題:lujun9972 譯者:wxy 校對:wxy
本文轉載來自 Linux 中國: https://github.com/Linux-CN/archive
對這篇文章感覺如何?
You may also like






More in:Linux中國

捐贈 Let's Encrypt,共建安全的互聯網

Let's Encrypt 正式發布,已經保護 380 萬個域名

關於Linux防火牆iptables的面試問答

Lets Encrypt 已被所有主流瀏覽器所信任









