使用時間序列數據,用開源工具助力你的邊緣項目

InfluxData 是一個開源的時間序列資料庫平台。下面介紹了它是如何被用於邊緣應用案例的。
收集到的隨時間變化的數據稱為時間序列數據。今天,它已經成為每個行業和生態系統的一部分。它是不斷增長的物聯網行業的一大組成部分,將成為人們日常生活的重要部分。但時間序列數據及其需求很難處理。這是因為沒有專門為處理時間序列數據而構建的工具。在這篇文章中,我將詳細介紹這些問題,以及過去 10 年來 InfluxData 如何解決這些問題。
InfluxData
InfluxData 是一個開源的時間序列資料庫平台。你可能通過 InfluxDB 了解該公司,但你可能不知道它專門從事時間序列資料庫開發。這很重要,因為在管理時間序列數據時,你要處理兩個問題:存儲生命周期和查詢。
在存儲生命周期中,開發人員通常首先收集和分析非常詳細的數據。但開發人員希望存儲較小的、降低採樣率的數據集,以描述其趨勢,而不佔用太多的存儲空間。
查詢資料庫時,你不希望基於 ID 查詢數據,而是希望基於時間範圍進行查詢。使用時間序列數據最常見的一件事是在一段時間內對其進行匯總。在典型的關係型資料庫中存儲數據時,這種查詢是很慢的,這種資料庫使用行和列來描述不同數據點的關係。專門為處理時間序列數據而設計的資料庫可以更快地處理這類查詢。InfluxDB 有自己的內置查詢語言:Flux,這是專門為查詢時間序列數據集而構建的。
數據採集
數據採集和數據處理都有一些很棒的工具。InfluxData 有 12 個以上的客戶端庫,允許你使用自己選擇的編程語言編寫和查詢數據。這是自定義用法的一個很好的工具。開源攝取代理 Telegraf 包括 300 多個輸入和輸出插件。如果你是一個開發者,你也可以貢獻自己的插件。
InfluxDB 還可以接受上傳小體積歷史數據集的 CSV 文件,以及大數據集的批量導入。
import math
bicycles3 = from(bucket: "smartcity")
|> range(start:2021-03-01T00:00:00z, stop: 2021-04-01T00:00:00z)
|> filter(fn: (r) => r._measurement == "city_IoT")
|> filter(fn: (r) => r._field == "counter")
|> filter(fn: (r) => r.source == "bicycle")
|> filter(fn: (r) => r.neighborhood_id == "3")
|> aggregateWindow(every: 1h, fn: mean, createEmpty:false)
bicycles4 = from(bucket: "smartcity")
|> range(start:2021-03-01T00:00:00z, stop: 2021-04-01T00:00:00z)
|> filter(fn: (r) => r._measurement == "city_IoT")
|> filter(fn: (r) => r._field == "counter")
|> filter(fn: (r) => r.source == "bicycle")
|> filter(fn: (r) => r.neighborhood_id == "4")
|> aggregateWindow(every: 1h, fn: mean, createEmpty:false)join(tables: {neighborhood_3: bicycles3, neighborhood_4: bicycles4}, on ["_time"], method: "inner")
|> keep(columns: ["_time", "_value_neighborhood_3","_value_neighborhood_4"])
|> map(fn: (r) => ({
r with
difference_value : math.abs(x: (r._value_neighborhood_3 - r._value_neighborhood_4))
}))
Flux
Flux 是我們的內部查詢語言,從零開始建立,用於處理時間序列數據。它也是我們一些工具的基礎動力,包括 任務 、 警報 和 通知 。要剖析上面的 Flux 查詢,需要定義一些東西。首先,「 桶 」就是我們所說的資料庫。你可以配置存儲桶,然後將數據流添加到其中。查詢會調用 smartcity 存儲桶,其範圍為特定的一天(準確地說是 24 小時)。你可以從存儲桶中獲取所有數據,但大多數用戶都包含一個數據範圍。這是你能做的最基本的 Flux 查詢。
接下來,我添加過濾器,將數據過濾到更精確、更易於管理的地方。例如,我過濾分配給 id 為 3 的社區中的自行車數量。從那裡,我使用 aggregateWindow 獲取每小時的平均值。這意味著我希望收到一個包含 24 列的表,每小時一列。我也對 id 為 4 的社區進行同樣的查詢。最後,我將這兩張表相疊加,得出這兩個社區自行車使用量的差異。
如果你想知道什麼時候是交通高峰,這是不錯的選擇。顯然,這只是 Flux 查詢功能的一個小例子。但它提供了一個很好的例子,使用了 Flux 附帶的一些工具。我還有很多的數據分析和統計功能。但對於這一點,我建議查看 Flux 文檔。
import "influxdata/influxdb/tasks"
option task = {name: PB_downsample, every: 1h, offset: 10s}
from(bucket: "plantbuddy")
|>range(start: tasks.lastSuccess(orTime: -task.every))
|>filter(fn: (r) => r["_measurement"] == "sensor_data")
|>aggregateWindow(every: 10m, fn:last, createEmpty:false)
|>yield(name: "last")
|>to(bucket: "downsampled")
任務
InfluxDB 任務 是一個定時 Flux 腳本,它接收輸入數據流並以某種方式修改或分析它。然後,它將修改後的數據存儲在新的存儲桶中或執行其他操作。將較小的數據集存儲到新的存儲桶中,稱為「 降採樣 」,這是資料庫的核心功能,也是時間序列數據生命周期的核心部分。
你可以在當前任務示例中看到,我已經對數據進行了降採樣。我得到每 10 分鐘增量的最後一個值,並將該值存儲在降採樣桶中。原始數據集在這 10 分鐘內可能有數千個數據點,但現在降採樣桶只有 60 個新值。需要注意的一點是,我還使用了範圍內的 lastSuccess 函數。這會告訴 InfluxDB 從上次成功運行的時間開始運行此任務,以防它在過去 2 小時內失敗,在這種情況下,它可以追溯 3 個小時內的最後一次成功運行。這對於內置錯誤處理非常有用。
檢查和警報
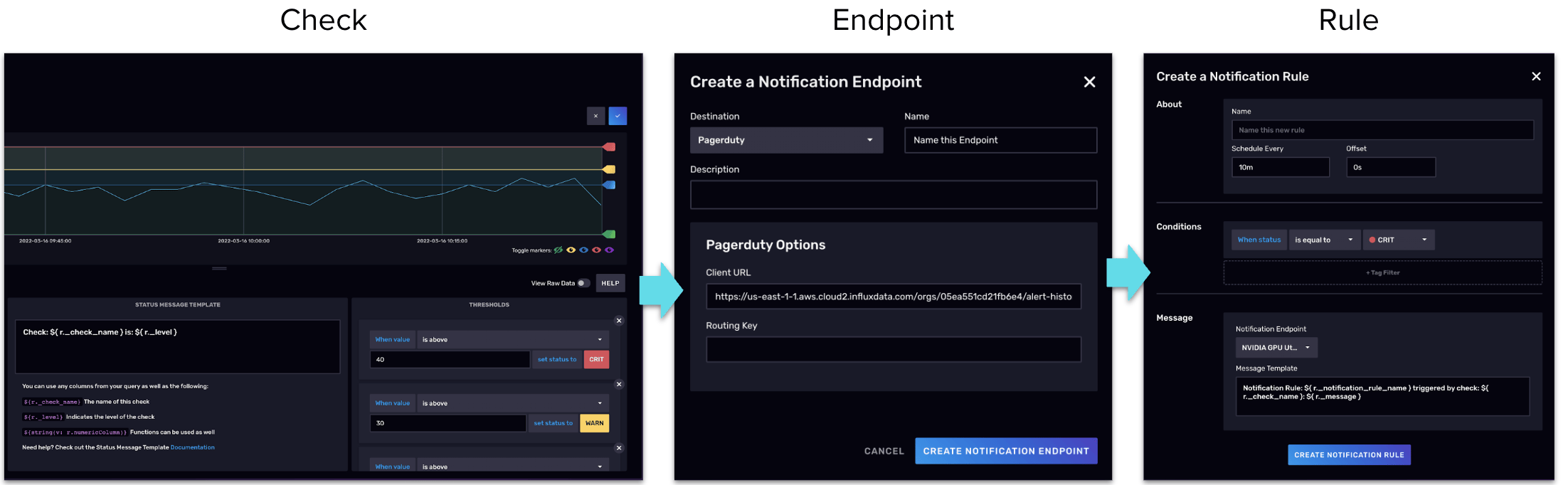
InfluxDB 包含一個 警報 或 檢查 和 通知 系統。這個系統非常簡單直白。首先進行檢查,定期查看數據以查找你定義的異常。通常,這是用閾值定義的。例如,任何低於 32°F 的溫度值都被指定為「WARN」值,高於 32°F 都被分配為「OK」值,低於 0°F 都被賦予「CRITICAL」值。從那開始,你的檢查可以按你認為必要的頻率運行。你的檢查以及每個檢查的當前狀態都有歷史記錄。在不需要的時候,你不需要設置通知。你可以根據需要參考你的警報歷史記錄。
許多人選擇設置通知。為此,你需要定義一個 通知端點 。例如,聊天應用程序可以進行 HTTP 調用以接收通知。然後你定義何時接收通知,例如,你可以每小時運行一次檢查。你可以每 24 小時運行一次通知。你可以讓通知響應值更改,例如,「WARN」更改為「CRITICAL」,或者當值為「CRITICAL」時,無論如何都從「OK」更改為「WARN」。這是一個高度可定製的系統。從這個系統創建的 Flux 代碼也可以編輯。
邊緣
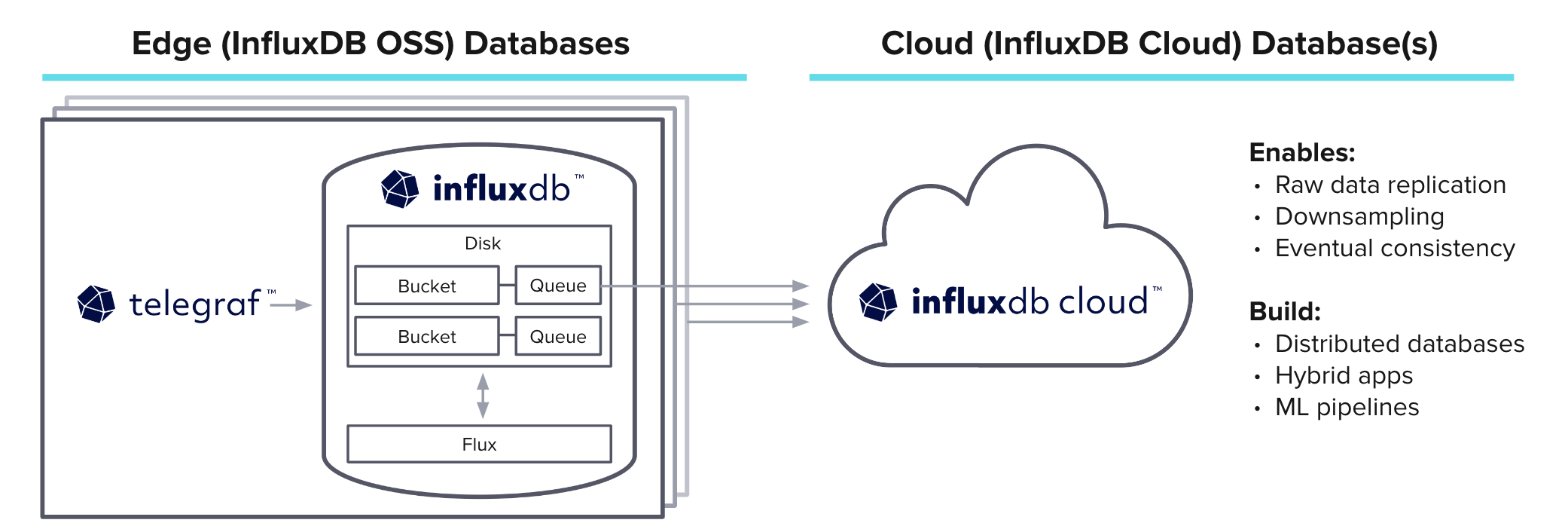
最後,我想把所有的核心功能放在一起,包括最近發布的一個非常特別的新功能。「Edge to cloud」 是一個非常強大的工具,允許你運行開源 InfluxDB,並在出現連接問題時在本地存儲數據。連接修復後,它會將數據流傳輸到 InfluxData 雲平台。
這對於邊緣設備和重要數據非常重要,因為任何數據丟失都是有害的。你定義一個要複製到雲的存儲桶,然後該存儲桶有一個磁碟支持的隊列來本地存儲數據。然後定義雲存儲桶應該複製到的內容。在連接到雲端之前,數據都存儲在本地。
InfluxDB 和物聯網邊緣
假設你有一個項目,你想使用連接到植物上的物聯網感測器 監測家裡植物的健康狀況。該項目是使用你的筆記本電腦作為邊緣設備設置的。當你的筆記本電腦合上或關閉時,它會在本地存儲數據,然後在重新連接時將數據流傳到我的雲存儲桶。
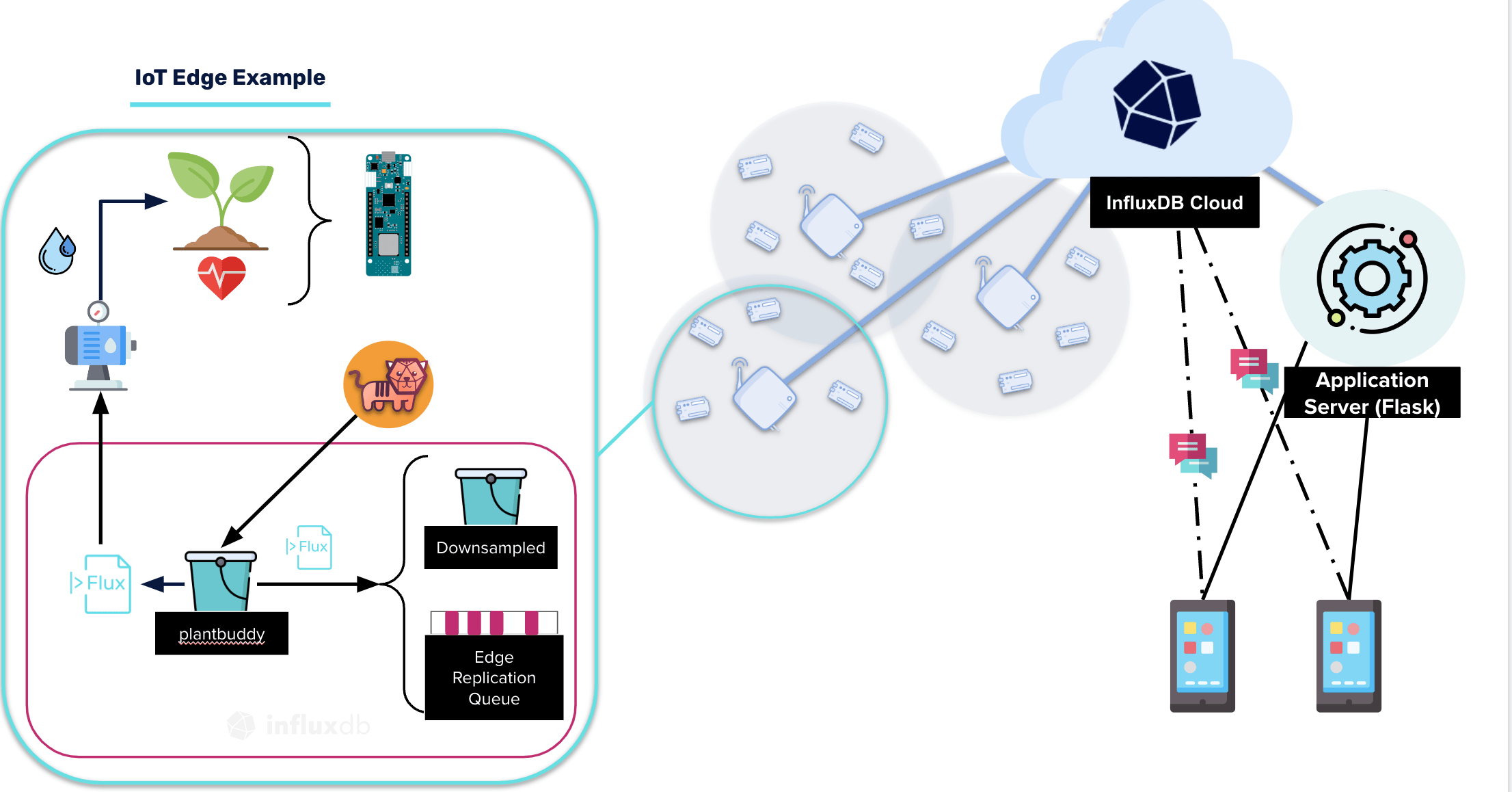
需要注意的一點是,在將數據存儲到複製桶之前,這會對本地設備上的數據進行降採樣。你的植物感測器每秒提供一個數據點。但它將數據壓縮為一分鐘的平均數,因此存儲的數據更少了。在雲賬戶中,你可以添加一些警報和通知,讓你知道植物的水分何時低於某個水平,需要澆水。也可以在網站上使用視覺效果來告訴用戶植物的健康狀況。
資料庫是許多應用程序的主幹。在像 InfluxDB 的時間序列資料庫平台中使用帶有時間戳的數據可以節省開發人員的時間,並使他們能夠訪問各種工具和服務。InfluxDB 的維護者喜歡看到人們在我們的開源社區中構建什麼,所以請與我們聯繫,並與其他人共享你的項目和代碼!
via: https://opensource.com/article/23/1/time-series-data-edge-open-source-tools
作者:Zoe Steinkamp 選題:lkxed 譯者:ZhangZhanhaoxiang 校對:wxy
本文轉載來自 Linux 中國: https://github.com/Linux-CN/archive
對這篇文章感覺如何?
You may also like






More in:Linux中國

捐贈 Let's Encrypt,共建安全的互聯網

Let's Encrypt 正式發布,已經保護 380 萬個域名

關於Linux防火牆iptables的面試問答

Lets Encrypt 已被所有主流瀏覽器所信任









