在 Python 中使用機器學習來檢測釣魚鏈接

通過網路釣魚攻擊,攻擊者能夠獲得一些重要憑證,這些憑證可以用來進入你的銀行或其他金融賬戶。攻擊者發送的 URL 看起來與我們日常使用的原始應用程序完全相同。這也是人們經常相信它,並在其中輸入個人信息的原因。釣魚網址可以打開一個網頁,它看起來與你的銀行的原始登錄頁面相似。最近,這樣的網路釣魚攻擊正變得相當普遍,所以,檢測釣魚鏈接變得非常重要。因此,我將介紹如何在 Python 中使用機器學習來檢查一個鏈接是誤導性的還是真實的,因為它可以幫助我們看到網頁代碼及其輸出。注意,本文將使用 Jupyter Notebook。當然,你也可以使用 Google Colab 或 Amazon Sagemaker,如果你對這些更熟悉的話。
下載數據集
第一步,我們需要用於訓練數據集。你可以從下面的鏈接中下載數據集。
- 真實的鏈接:https://github.com/jishnusaurav/Phishing-attack-PCAP-analysis-using-scapy/blob/master/Phishing-Website-Detection/datasets/legitimate-urls.csv
- 釣魚鏈接:https://github.com/jishnusaurav/Phishing-attack-PCAP-analysis-using-scapy/blob/master/Phishing-Website-Detection/datasets/phishing-urls.csv
訓練機器進行預測
當數據集下載完成,我們需要使用以下幾行代碼來導入所需的庫:
import pandas as pd
from sklearn.ensemble import RandomForestClassifier
如果你沒有這些庫,你可以使用 pip 工具來安裝這些庫,如下圖所示:
當依賴安裝完成,你就可以導入數據集,並將其轉換為 pandas 數據框架,使用以下幾行代碼進一步處理:
legitimate_urls = pd.read_csv(「/home/jishnusaurav/jupyter/Phishing-Website-Detection/datasets/legitimate-urls.csv」)
phishing_urls = pd.read_csv(「/home/jishnusaurav/jupyter/Phishing-Website-Detection/datasets/phishing-urls.csv」)
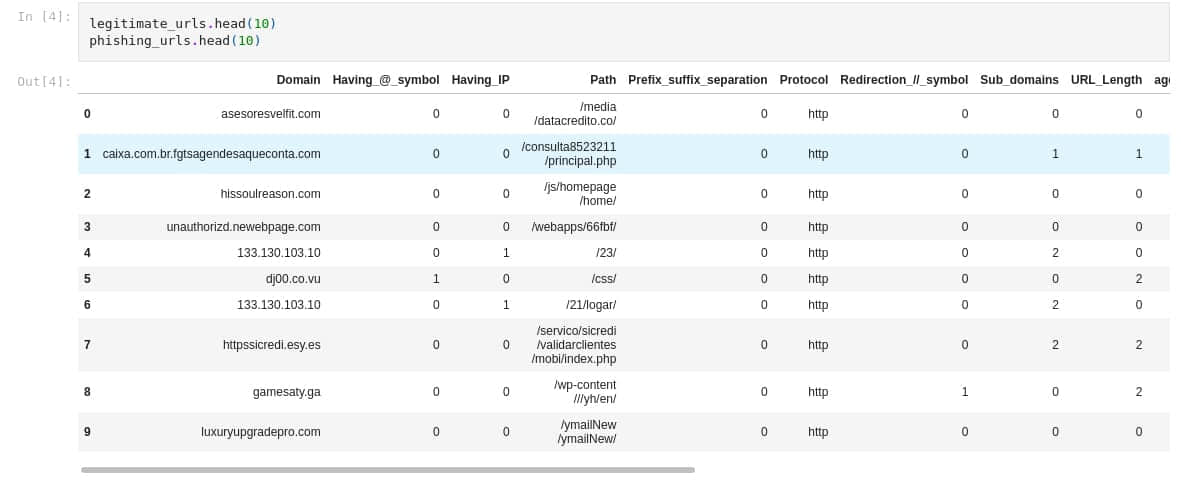
在成功導入後,我們需要把這兩個數據集合併,以便形成一個數據集。合併後的數據集的前幾行如下圖所示:
然後去掉那些我們不需要的列,如路徑(path)、協議(protocol)等,以達到預測的目的:
urls = urls.drop(urls.columns[[0,3,5]],axis=1)
在這之後,我們需要使用以下代碼將數據集分成測試和訓練兩部分:
data_train, data_test, labels_train, labels_test = train_test_split(urls_without_labels, labels, test_size=0.30, random_state=110)
接著,我們使用 sklearn 的隨機森林分類器建立一個模型,然後使用 fit 函數來訓練這個模型。
random_forest_classifier = RandomForestClassifier()
random_forest_classifier.fit(data_train,labels_train)
完成這些後,我們就可以使用 predict 函數來最終預測哪些鏈接是釣魚鏈接。下面這行可用於預測:
prediction_label = random_forest_classifier.predict(test_data)
就是這樣啦!你已經建立了一個機器學習模型,它可以預測一個鏈接是否是釣魚鏈接。試一下吧,我相信你會滿意的!
via: https://www.opensourceforu.com/2022/04/detect-a-phishing-url-using-machine-learning-in-python/
作者:Jishnu Saurav Mittapalli 選題:lkxed 譯者:lkxed 校對:wxy
本文轉載來自 Linux 中國: https://github.com/Linux-CN/archive
對這篇文章感覺如何?
You may also like






More in:Linux中國

捐贈 Let's Encrypt,共建安全的互聯網

Let's Encrypt 正式發布,已經保護 380 萬個域名

關於Linux防火牆iptables的面試問答

Lets Encrypt 已被所有主流瀏覽器所信任









