極致技術探索:顯卡工作原理

自從 3dfx 推出最初的 Voodoo 加速器以來,不起眼的顯卡對你的 PC 是否可以玩遊戲起到決定性作用,PC 上任何其它設備都無法與其相比。其它組件當然也很重要,但對於一個擁有 32GB 內存、價值 500 美金的 CPU 和 基於 PCIe 的存儲設備的高端 PC,如果使用 10 年前的顯卡,都無法以最高解析度和細節質量運行當前 最高品質的遊戲 ,會發生卡頓甚至無響應。顯卡(也常被稱為 GPU,即 圖形處理單元 ),對遊戲性能影響極大,我們反覆強調這一點;但我們通常並不會深入了解顯卡的工作原理。
出於實際考慮,本文將概述 GPU 的上層功能特性,內容包括 AMD 顯卡、Nvidia 顯卡、Intel 集成顯卡以及 Intel 後續可能發布的獨立顯卡之間共同的部分。也應該適用於 Apple、Imagination Technologies、Qualcomm、ARM 和其它顯卡生產商發布的移動平台 GPU。
我們為何不使用 CPU 進行渲染?
我要說明的第一點是我們為何不直接使用 CPU 完成遊戲中的渲染工作。坦率的說,在理論上你確實可以直接使用 CPU 完成 渲染 工作。在顯卡沒有廣泛普及之前,早期的 3D 遊戲就是完全基於 CPU 運行的,例如 《 地下創世紀 (下文中簡稱 UU)。UU 是一個很特別的例子,原因如下:與《 毀滅戰士 相比,UU 具有一個更高級的渲染引擎,全面支持「向上或向下看」以及一些在當時比較高級的特性,例如 紋理映射 。但為支持這些高級特性,需要付出高昂的代價,很少有人可以擁有真正能運行起 UU 的 PC。
地下創世紀,圖片來自 GOG
對於早期的 3D 遊戲,包括《 半條命 》和《 雷神之錘 2 》在內的很多遊戲,內部包含一個軟體渲染器,讓沒有 3D 加速器的玩家也可以玩遊戲。但現代遊戲都棄用了這種方式,原因很簡單:CPU 是設計用於通用任務的微處理器,意味著缺少 GPU 提供的 專用硬體 和 功能 。對於 18 年前使用軟體渲染的那些遊戲,當代 CPU 可以輕鬆勝任;但對於當代最高品質的遊戲,除非明顯降低 景象質量 、解析度和各種虛擬特效,否則現有的 CPU 都無法勝任。
什麼是 GPU ?
GPU 是一種包含一系列專用硬體特性的設備,其中這些特性可以讓各種 3D 引擎更好地執行代碼,包括 形狀構建 ,紋理映射, 訪存 和 著色器 等。3D 引擎的功能特性影響著設計者如何設計 GPU。可能有人還記得,AMD HD5000 系列使用 VLIW5 架構 ;但在更高端的 HD 6000 系列中使用了 VLIW4 架構。通過 GCN (LCTT 譯註:GCN 是 Graphics Core Next 的縮寫,字面意思是「下一代圖形核心」,既是若干代微體系結構的代號,也是指令集的名稱),AMD 改變了並行化的實現方法,提高了每個時鐘周期的有效性能。

「GPU 革命」的前兩塊奠基石屬於 AMD 和 NV;而「第三個時代」則獨屬於 AMD。
Nvidia 在發布首款 GeForce 256 時(大致對應 Microsoft 推出 DirectX7 的時間點)提出了 GPU 這個術語,這款 GPU 支持在硬體上執行轉換和 光照計算 。將專用功能直接集成到硬體中是早期 GPU 的顯著技術特點。很多專用功能還在(以一種極為不同的方式)使用,畢竟對於特定類型的工作任務,使用 片上 專用計算資源明顯比使用一組 可編程單元 要更加高效和快速。
GPU 和 CPU 的核心有很多差異,但我們可以按如下方式比較其上層特性。CPU 一般被設計成儘可能快速和高效的執行單線程代碼。雖然 同時多線程 (SMT)或 超線程 (HT)在這方面有所改進,但我們實際上通過堆疊眾多高效率的單線程核心來擴展多線程性能。AMD 的 32 核心/64 線程 Epyc CPU 已經是我們能買到的核心數最多的 CPU;相比而言,Nvidia 最低端的 Pascal GPU 都擁有 384 個核心。但相比 CPU 的核心,GPU 所謂的核心是處理能力低得多的的處理單元。
注意: 簡單比較 GPU 核心數,無法比較或評估 AMD 與 Nvidia 的相對遊戲性能。在同樣 GPU 系列(例如 Nvidia 的 GeForce GTX 10 系列,或 AMD 的 RX 4xx 或 5xx 系列)的情況下,更高的 GPU 核心數往往意味著更高的性能。
你無法只根據核心數比較不同供應商或核心系列的 GPU 之間的性能,這是因為不同的架構對應的效率各不相同。與 CPU 不同,GPU 被設計用於並行計算。AMD 和 Nvidia 在結構上都劃分為計算資源 塊 。Nvidia 將這些塊稱之為 流處理器 (SM),而 AMD 則稱之為 計算單元 (CU)。
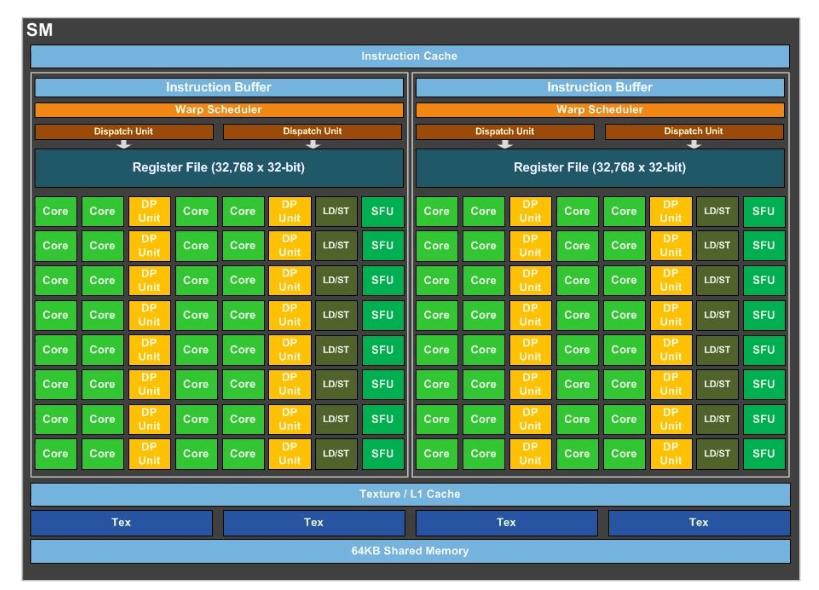
一個 Pascal 流處理器(SM)。
每個塊都包含如下組件:一組核心、一個 調度器 、一個 寄存器文件 、指令緩存、紋理和 L1 緩存以及紋理 映射單元 。SM/CU 可以被認為是 GPU 中最小的可工作塊。SM/CU 沒有涵蓋全部的功能單元,例如視頻解碼引擎,實際在屏幕繪圖所需的渲染輸出,以及與 板載 顯存 (VRAM)通信相關的 內存介面 都不在 SM/CU 的範圍內;但當 AMD 提到一個 APU 擁有 8 或 11 個 Vega 計算單元時,所指的是(等價的) 硅晶塊 數目。如果你查看任意一款 GPU 的模塊設計圖,你會發現圖中 SM/CU 是反覆出現很多次的部分。

這是 Pascal 的全平面圖
GPU 中的 SM/CU 數目越多,每個時鐘周期內可以並行完成的工作也越多。渲染是一種通常被認為是「高度並行」的計算問題,意味著隨著核心數增加帶來的可擴展性很高。
當我們討論 GPU 設計時,我們通常會使用一種形如 4096:160:64 的格式,其中第一個數字代表核心數。在核心系列(如 GTX970/GTX 980/GTX 980 Ti,如 RX 560/RX 580 等等)一致的情況下,核心數越高,GPU 也就相對更快。
紋理映射和渲染輸出
GPU 的另外兩個主要組件是紋理映射單元和渲染輸出。設計中的紋理映射單元數目決定了最大的 紋素 輸出以及可以多快的處理並將紋理映射到對象上。早期的 3D 遊戲很少用到紋理,這是因為繪製 3D 多邊形形狀的工作有較大的難度。紋理其實並不是 3D 遊戲必須的,但不使用紋理的現代遊戲屈指可數。
GPU 中的紋理映射單元數目用 4096:160:64 指標中的第二個數字表示。AMD、Nvidia 和 Intel 一般都等比例變更指標中的數字。換句話說,如果你找到一個指標為 4096:160:64 的 GPU,同系列中不會出現指標為 4096:320:64 的 GPU。紋理映射絕對有可能成為遊戲的瓶頸,但產品系列中次高級別的 GPU 往往提供更多的核心和紋理映射單元(是否擁有更高的渲染輸出單元取決於 GPU 系列和顯卡的指標)。
渲染輸出單元 (ROP),有時也叫做 光柵操作管道 是 GPU 輸出彙集成圖像的場所,圖像最終會在顯示器或電視上呈現。渲染輸出單元的數目乘以 GPU 的時鐘頻率決定了 像素填充速率 。渲染輸出單元數目越多意味著可以同時輸出的像素越多。渲染輸出單元還處理 抗鋸齒 ,啟用抗鋸齒(尤其是 超級採樣 抗鋸齒)會導致遊戲填充速率受限。
顯存帶寬與顯存容量
我們最後要討論的是 顯存帶寬 和 顯存容量 。顯存帶寬是指一秒時間內可以從 GPU 專用的顯存緩衝區內拷貝進或拷貝出多少數據。很多高級視覺特效(以及更常見的高解析度)需要更高的顯存帶寬,以便保證足夠的 幀率 ,因為需要拷貝進和拷貝出 GPU 核心的數據總量增大了。
在某些情況下,顯存帶寬不足會成為 GPU 的顯著瓶頸。以 Ryzen 5 2400G 為例的 AMD APU 就是嚴重帶寬受限的,以至於提高 DDR4 的時鐘頻率可以顯著提高整體性能。導致瓶頸的顯存帶寬閾值,也與遊戲引擎和遊戲使用的解析度相關。
板載內存大小也是 GPU 的重要指標。如果按指定細節級別或解析度運行所需的顯存量超過了可用的資源量,遊戲通常仍可以運行,但會使用 CPU 的主存來存儲額外的紋理數據;而從 DRAM 中提取數據比從板載顯存中提取數據要慢得多。這會導致遊戲在板載的快速訪問內存池和系統內存中共同提取數據時出現明顯的卡頓。
有一點我們需要留意,GPU 生產廠家通常為一款低端或中端 GPU 配置比通常更大的顯存,這是他們為產品提價的一種常用手段。很難說大顯存是否更具有吸引力,畢竟需要具體問題具體分析。大多數情況下,用更高的價格購買一款僅是顯存更高的顯卡是不划算的。經驗規律告訴我們,低端顯卡遇到顯存瓶頸之前就會碰到其它瓶頸。如果存在疑問,可以查看相關評論,例如 4G 版本或其它數目的版本是否性能超過 2G 版本。更多情況下,如果其它指標都相同,購買大顯存版本並不值得。
查看我們的極致技術探索系列,深入了解更多當前最熱的技術話題。
via: https://www.extremetech.com/gaming/269335-how-graphics-cards-work
作者:Joel Hruska 選題:lujun9972 譯者:pinewall 校對:wxy
本文轉載來自 Linux 中國: https://github.com/Linux-CN/archive
對這篇文章感覺如何?
You may also like






More in:Linux中國

捐贈 Let's Encrypt,共建安全的互聯網

Let's Encrypt 正式發布,已經保護 380 萬個域名

關於Linux防火牆iptables的面試問答

Lets Encrypt 已被所有主流瀏覽器所信任









