三個開源的分散式追蹤工具

分散式追蹤系統能夠從頭到尾地追蹤跨越了多個應用、服務、資料庫以及像代理這樣的中間件的分散式軟體的請求。它能幫助你更深入地理解系統中到底發生了什麼。追蹤系統以圖形化的方式,展示出每個已知步驟以及某個請求在每個步驟上的耗時。
用戶可以通過這些展示來判斷系統的哪個環節有延遲或阻塞,當請求失敗時,運維和開發人員可以看到準確的問題源頭,而不需要去測試整個系統,比如用二叉查找樹的方法去定位問題。在開發迭代的過程中,追蹤系統還能夠展示出可能引起性能變化的環節。通過異常行為的警告自動地感知到性能的退化,總是比客戶告訴你要好。
這種追蹤是怎麼工作的呢?給每個請求分配一個特殊 ID,這個 ID 通常會插入到請求頭部中。它唯一標識了對應的事務。一般把事務叫做 蹤跡 ,「蹤跡」是整個事務的抽象概念。每一個「蹤跡」由 單元 組成,「單元」代表著一次請求中真正執行的操作,比如一次服務調用,一次資料庫請求等。每一個「單元」也有自己唯一的 ID。「單元」之下也可以創建子「單元」,子「單元」可以有多個父「單元」。
當一次事務(或者說蹤跡)運行過之後,就可以在追蹤系統的表示層上搜索了。有幾個工具可以用作表示層,我們下文會討論,不過,我們先看下面的圖,它是我在 Istio walkthrough 視頻教程中提到的 Jaeger 界面,展示了單個蹤跡中的多個單元。很明顯,這個圖能讓你一目了然地對事務有更深的了解。
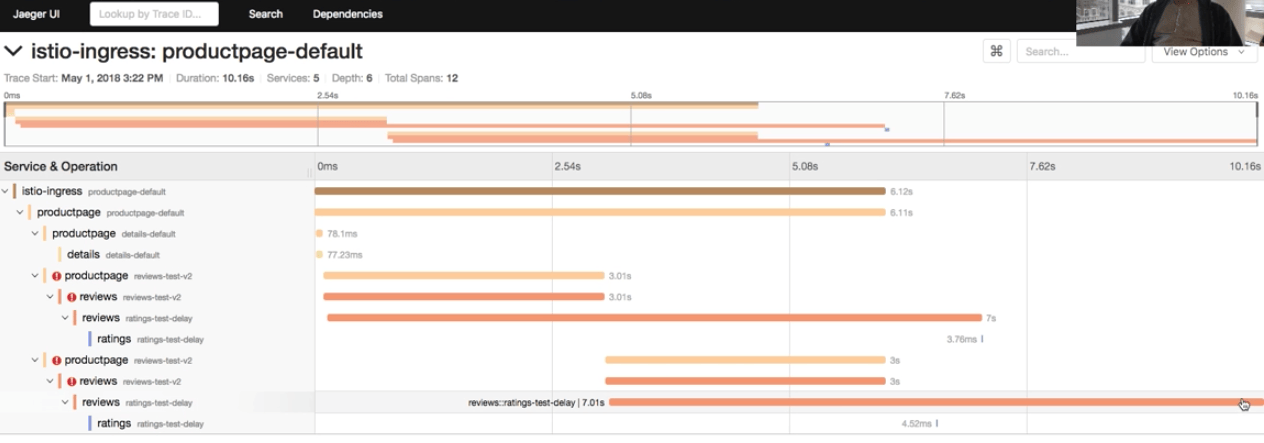
這個演示使用了 Istio 內置的 OpenTracing 實現,所以我甚至不需要修改自己的應用代碼就可以獲得追蹤數據。我也用到了 Jaeger,它是兼容 OpenTracing 的。
那麼 OpenTracing 到底是什麼呢?我們來看看。
OpenTracing API
OpenTracing 是源自 Zipkin 的規範,以提供跨平台兼容性。它提供了對廠商中立的 API,用來嚮應用程序添加追蹤功能並將追蹤數據發送到分散式的追蹤系統。按照 OpenTracing 規範編寫的庫,可以被任何兼容 OpenTracing 的系統使用。採用這個開放標準的開源工具有 Zipkin、Jaeger 和 Appdash 等。甚至像 Datadog 和 Instana 這種付費工具也在採用。因為現在 OpenTracing 已經無處不在,這樣的趨勢有望繼續發展下去。
OpenCensus
OpenTracing 已經說過了,可 OpenCensus 又是什麼呢?它在搜索結果中老是出現。它是一個和 OpenTracing 完全不同或者互補的競爭標準嗎?
這個問題的答案取決於你的提問對象。我先盡我所能地解釋一下它們的不同(按照我的理解):OpenCensus 更加全面或者說它包羅萬象。OpenTracing 專註於建立開放的 API 和規範,而不是為每一種開發語言和追蹤系統都提供開放的實現。OpenCensus 不僅提供規範,還提供開發語言的實現,和連接協議,而且它不僅只做追蹤,還引入了額外的度量指標,這些一般不在分散式追蹤系統的職責範圍。
使用 OpenCensus,我們能夠在運行著應用程序的主機上查看追蹤數據,但它也有個可插拔的導出器系統,用於導出數據到中心聚合器。目前 OpenCensus 團隊提供的導出器包括 Zipkin、Prometheus、Jaeger、Stackdriver、Datadog 和 SignalFx,不過任何人都可以創建一個導出器。
依我看這兩者有很多重疊的部分,沒有哪個一定比另外一個好,但是重要的是,要知道它們做什麼事情和不做什麼事情。OpenTracing 主要是一個規範,具體的實現和獨斷的設計由其他人來做。OpenCensus 更加獨斷地為本地組件提供了全面的解決方案,但是仍然需要其他系統做遠程的聚合。
可選工具
Zipkin
Zipkin 是最早出現的這類工具之一。 谷歌在 2010 年發表了介紹其內部追蹤系統 Dapper 的論文,Twitter 以此為基礎開發了 Zipkin。Zipkin 的開發語言 Java,用 Cassandra 或 ElasticSearch 作為可擴展的存儲後端,這些選擇能滿足大部分公司的需求。Zipkin 支持的最低 Java 版本是 Java 6,它也使用了 Thrift 的二進位通信協議,Thrift 在 Twitter 的系統中很流行,現在作為 Apache 項目在託管。
這個系統包括上報器(客戶端)、數據收集器、查詢服務和一個 web 界面。Zipkin 只傳輸一個帶事務上下文的蹤跡 ID 來告知接收者追蹤的進行,所以說在生產環境中是安全的。每一個客戶端收集到的數據,會非同步地傳輸到數據收集器。收集器把這些單元的數據存到資料庫,web 界面負責用可消費的格式展示這些數據給用戶。客戶端傳輸數據到收集器有三種方式:HTTP、Kafka 和 Scribe。
Zipkin 社區 還提供了 Brave,一個跟 Zipkin 兼容的 Java 客戶端的實現。由於 Brave 沒有任何依賴,所以它不會拖累你的項目,也不會使用跟你們公司標準不兼容的庫來搞亂你的項目。除 Brave 之外,還有很多其他的 Zipkin 客戶端實現,因為 Zipkin 和 OpenTracing 標準是兼容的,所以這些實現也能用到其他的分散式追蹤系統中。流行的 Spring 框架中一個叫 Spring Cloud Sleuth 的分散式追蹤組件,它和 Zipkin 是兼容的。
Jaeger
Jaeger 來自 Uber,是一個比較新的項目,CNCF(雲原生計算基金會)已經把 Jaeger 託管為孵化項目。Jaeger 使用 Golang 開發,因此你不用擔心在伺服器上安裝依賴的問題,也不用擔心開發語言的解釋器或虛擬機的開銷。和 Zipkin 類似,Jaeger 也支持用 Cassandra 和 ElasticSearch 做可擴展的存儲後端。Jaeger 也完全兼容 OpenTracing 標準。
Jaeger 的架構跟 Zipkin 很像,有客戶端(上報器)、數據收集器、查詢服務和一個 web 界面,不過它還有一個在各個伺服器上運行著的代理,負責在伺服器本地做數據聚合。代理通過一個 UDP 連接接收數據,然後分批處理,發送到數據收集器。收集器接收到的數據是 Thrift 協議的格式,它把數據存到 Cassandra 或者 ElasticSearch 中。查詢服務能直接訪問資料庫,並給 web 界面提供所需的信息。
默認情況下,Jaeger 客戶端不會採集所有的追蹤數據,只抽樣了 0.1% 的( 1000 個采 1 個)追蹤數據。對大多數系統來說,保留所有的追蹤數據並傳輸的話就太多了。不過,通過配置代理可以調整這個值,客戶端會從代理獲取自己的配置。這個抽樣並不是完全隨機的,並且正在變得越來越好。Jaeger 使用概率抽樣,試圖對是否應該對新蹤跡進行抽樣進行有根據的猜測。 自適應採樣已經在路線圖當中,它將通過添加額外的、能夠幫助做決策的上下文來改進採樣演算法。
Appdash
Appdash 也是一個用 Golang 寫的分散式追蹤系統,和 Jaeger 一樣。Appdash 是 Sourcegraph 公司基於谷歌的 Dapper 和 Twitter 的 Zipkin 開發的。同樣的,它也支持 Opentracing 標準,不過這是後來添加的功能,依賴了一個與默認組件不同的組件,因此增加了風險和複雜度。
從高層次來看,Appdash 的架構主要有三個部分:客戶端、本地收集器和遠程收集器。因為沒有很多文檔,所以這個架構描述是基於對系統的測試以及查看源碼。寫代碼時需要把 Appdash 的客戶端添加進來。Appdash 提供了 Python、Golang 和 Ruby 的實現,不過 OpenTracing 庫可以與 Appdash 的 OpenTracing 實現一起使用。 客戶端收集單元數據,並將它們發送到本地收集器。然後,本地收集器將數據發送到中心的 Appdash 伺服器,這個伺服器上運行著自己的本地收集器,它的本地收集器是其他所有節點的遠程收集器。
via: https://opensource.com/article/18/9/distributed-tracing-tools
作者:Dan Barker 選題:lujun9972 譯者:belitex 校對:wxy
本文轉載來自 Linux 中國: https://github.com/Linux-CN/archive
對這篇文章感覺如何?
You may also like






More in:Linux中國

捐贈 Let's Encrypt,共建安全的互聯網

Let's Encrypt 正式發布,已經保護 380 萬個域名

關於Linux防火牆iptables的面試問答

Lets Encrypt 已被所有主流瀏覽器所信任









