文字間的戰鬥與其救世主 Unicode

我們都知道如何從鍵盤輸入文字,不是嗎?
那麼,請允許我挑戰你在你最愛的文本編輯器中輸入這段文字:

這段文字難以被輸入因為它包含著:
- 鍵盤上沒有的印刷符號,
- 平假名日文字元,
- 為符合平文式羅馬字標準,日本首都的名字中的兩個字母 「o」 頭頂帶有長音符號,
- 以及最後,用西里爾字母拼寫的名字德米特里。
毫無疑問,想要在早期的電腦中輸入這樣的句子是不可能的。這是因為早期電腦所使用的字符集有限,無法兼容多種書寫系統。而如今類似的限制已不復存在,馬上我們就能在文中看到。
電腦是如何儲存文字的?
計算機將字元作為數字儲存。它們再通過表格將這些數字與含有意義的字形一一對應。
在很長一段時間裡,計算機將每個字元作為 0 到 255 之間的數字儲存(這正好是一個位元組的長度)。但這用來代表人類書寫所用到的全部字元是遠遠不夠的。而解決這個問題的訣竅在於,取決於你住在地球上的哪一塊區域,系統會分別使用不同的對照表。
這裡有一張在法國常被廣泛使用的對照表 ISO 8859-15:
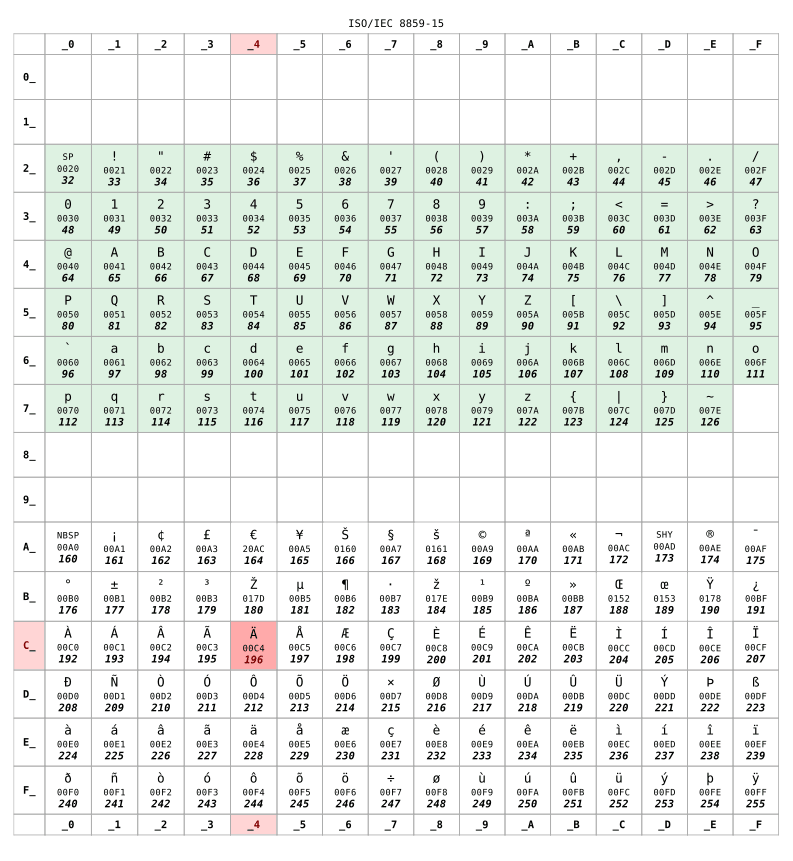
如果你住在俄羅斯,你的電腦大概會使用 KOI8-R 或是 Windows-1251 來進行編碼。現在讓我們假設我們在使用後者:
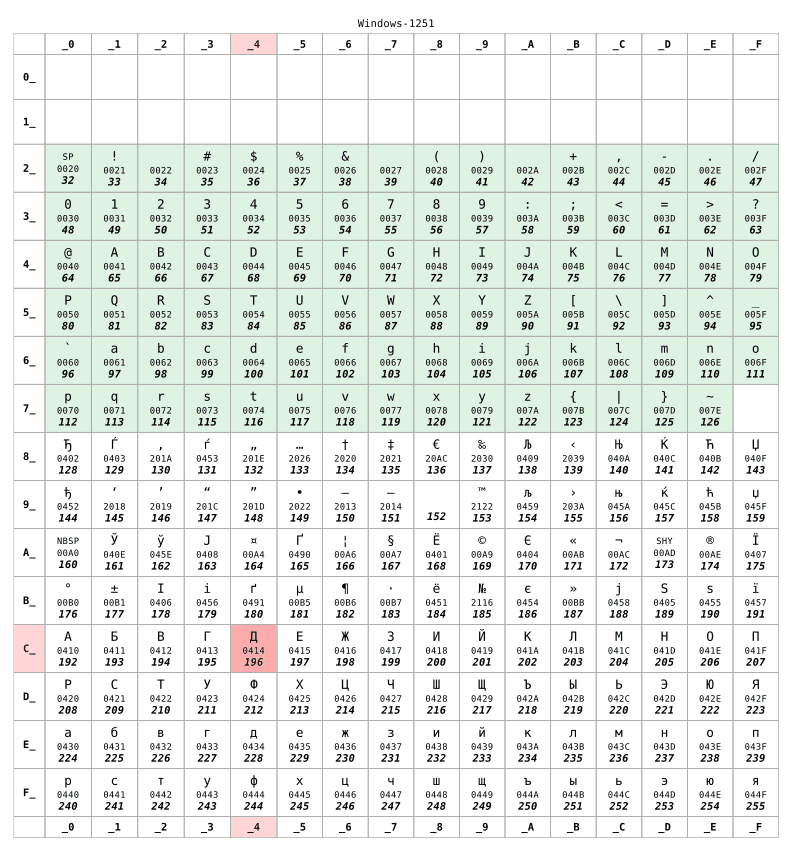
對於 128 之前的數字,兩張表格是一樣的。這個範圍與 US-ASCII 相對應,這是不同字元表格之間的最低兼容性。而對於 128 之後的數字,這兩張表格則完全不同了。
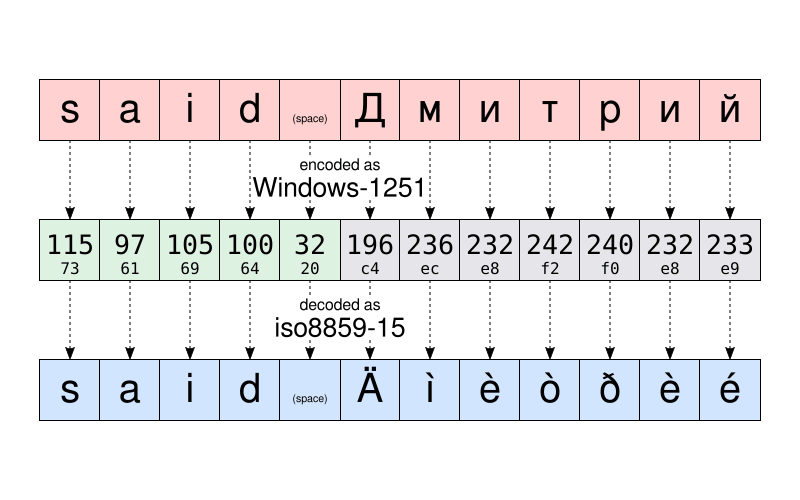
比如,依據 Windows-1251,字元串 「said Дмитрий」 會被儲存為:
115 97 105 100 32 196 236 232 242 240 232 233
按照計算機科學的常規方法,這十二個數字可被寫成更加緊湊的十六進位:
73 61 69 64 20 c4 ec e8 f2 f0 e8 e9
如果德米特里發給我這份文件,我在打開後可能會看到:
said Äìèòðèé
這份文件 看起來 被損壞了,實則不然。這些儲存在文件里的數據,即數字,並沒有發生改變。被顯示出的字元與 另一張表格 中的數據相對應,而非文字最初被寫出來時所用的編碼表。
讓我們來舉一個例子,就以字元 「Д」 為例。按照 Windows-1251,「Д」 的數字編碼為 196(c4)。儲存在文件里的只有數字 196。而正是這同樣的數字在 ISO8859-15 中與 「Ä」 相對應。這就是為什麼我的電腦錯誤地認為字形 「Ä」 就是應該被顯示的字形。
多提一句,你依然可以時不時地看到一些錯誤配置的網站展示,或由 用戶郵箱代理 發出的對收件人電腦所使用的字元編碼做出錯誤假設的郵件。這樣的故障有時被稱為亂碼(LCTT 譯註:原文用詞為 mojibake, 源自日語 文字化け)。好在這種情況在今天已經越來越少見了。
Unicode 拯救了世界
我解釋了不同國家間交換文件時會遇到的編碼問題。但事情還能更糟,同一個國家的不同生產商未必會使用相同的編碼。如果你在 80 年代用 Mac 和 PC 互傳過文件你就懂我是什麼意思了。
也不知道是不是巧合,Unicode 項目始於 1987 年,主導者來自 施樂 和…… 蘋果 。
這個項目的目標是定義一套通用字符集來允許同一段文字中 同時 出現人類書寫會用到的任何文字。最初的 Unicode 項目被限制在 65536 個不同字元(每個字元用 16 位表示,即每個字元兩位元組)。這個數字已被證實是遠遠不夠的。
於是,在 1996 年 Unicode 被擴展以支持高達 100 萬不同的 代碼點 。粗略來說,一個「代碼點」可被用來識別字元表中的一個條目。Unicode 項目的一個核心工作就是將世界上正在被使用(或曾被使用)的字母、符號、標點符號以及其他文字倉管起來,並給每一項條目分配一個代碼點用以準確分辨對應的字元。
這是一個龐大的項目:為了讓你有個大致了解,發佈於 2017 年的 Unicode 版本 10 定義了超過 136,000 個字元,覆蓋了 139 種現代和歷史上的語言文字。
隨著如此龐大數量的可能性,一個基本的編碼會需要每個字元 32 位(即 4 位元組)。但對於主要使用 US-ASCII 範圍內字元的文字,每個字元 4 位元組意味著 4 倍多的儲存需求以及 4 倍多的帶寬用以傳輸這些文字。
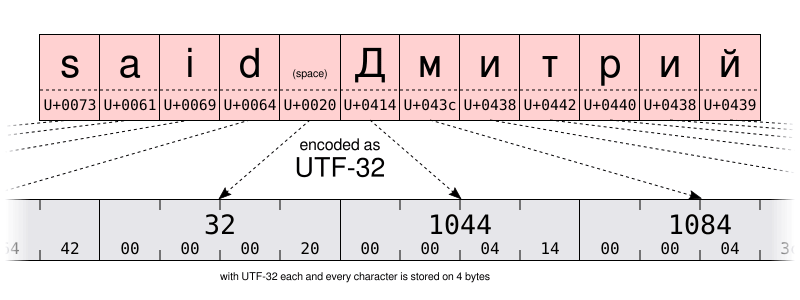
所以除了 UTF-32,Unicode 聯盟還定義了更加節約空間的 UTF-16 和 UTF-8 編碼,分別使用了 16 位和 8 位。但只有 8 位該如何儲存超過 100,000 個不同的值呢?事實是,你不能。但這其中竅門在於用一個代碼值(UTF-8 中的 8 位以及 UTF-16 中的 16 位)來儲存最常用的一些字元。再用幾個代碼值儲存最不常用的一些字元。所以說 UTF-8 和 UTF-16 是 可變長度 編碼。儘管這樣也有缺陷,但 UTF-8 是空間與時間效率之間一個不錯的折中。更不用提 UTF-8 可以向後兼容大部分 Unicode 之前的 1 位元組編碼,因為 UTF-8 經過了特別設計,任何有效的 US-ASCII 文件都是有效的 UTF-8 文件。你也可以說,UTF-8 是 US-ASCII 的超集。而在今天已經找不到不用 UTF-8 編碼的理由了。當然除非你書寫主要用的語言需要多位元組編碼,或是你不得不與一些殘留的老舊系統打交道。
在下面兩張圖中,你可以親自比較一下同一字元串的 UTF-16 和 UTF-8 編碼。特別注意 UTF-8 使用了一位元組來儲存拉丁字母表中的字元,但它使用了兩位元組來存儲西里爾字母表中的字元。這是 Windows-1251 西里爾編碼儲存同樣字元所需空間的兩倍。
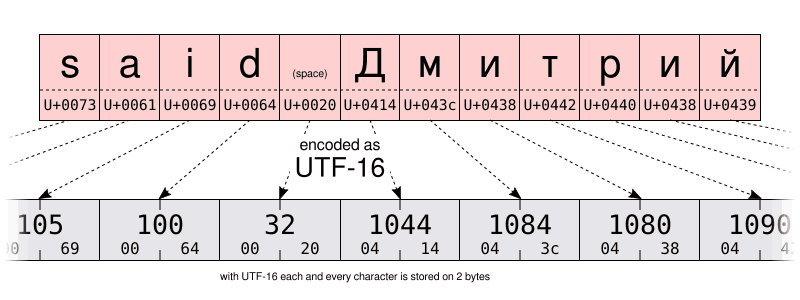
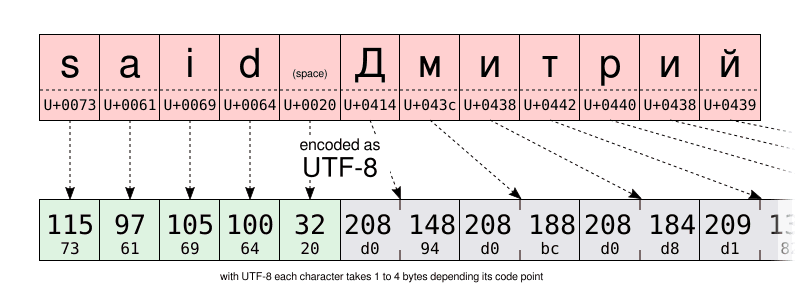
而這些對於打字有什麼用呢?
啊……知道一些你的電腦的能力與局限以及其底層機制也不是什麼壞事嘛。特別是我們馬上就要說到 Unicode 和十六進位。現在……讓我們再聊點歷史。真的就一點,我保證……
……就說從 80 年代起,電腦鍵盤曾經有過 Compose 鍵(有時候也被標為 Multi 鍵)就在 Shift 鍵的下邊。當按下這個鍵時,你會進入 「 組合 」 模式。一旦在這個模式下,你便可以通過輸入助記符來輸入你鍵盤上沒有的字元。比如說,在組合模式下,輸入 RO 便可生成字元 ®(當作是 O 裡面有一個 R 就能很容易記住)。

現在很難在現代鍵盤上看到 Compose 鍵了。這大概是因為佔據主導地位的 PC 不再用它了。但是在 Linux 上(可能還有其他系統)你可以模擬 Compose 鍵。這項設置可以通過 GUI 開啟,在大多數桌面環境下調用「鍵盤」控制面板:但具體的步驟取決於你的桌面環境以及版本。如果你成功啟用了那項設置,不要猶豫,在評論區分享你在你電腦上所採取的具體步驟。
(LCTT 譯註:如果有讀者想要嘗試,建議將 Compose 鍵設為大寫鎖定鍵,或是別的不常用的鍵,Ctrl 和 Alt 會被大部分 GUI 程序優先識別為功能鍵。還有一些我自己試驗時遇到過的問題,在開啟 Compose 鍵前要確認大寫鎖定是關閉的,輸入法要切換成英文,組合模式下輸入大小寫敏感。我試驗的系統是 Ubuntu 22.04 LTS。)
至於我自己嘛,我現在先假設你用的就是默認的 Shift+AltGr 組合來模擬 Compose 鍵。(LCTT 校註:AltGr 在歐洲鍵盤上是指右側的 Alt 鍵,在國際鍵盤上等價於 Ctrl+Alt 組合鍵。)
那麼,作為一個實際例子,嘗試輸入 「LEFT-POINTING DOUBLE ANGLE QUOTATION MARK(左雙角引號)」(LCTT 譯註:Guillemet,是法語和一些歐洲語言中的引號,與中文的書名號不同),你可以輸入 Shift+AltGr <<(你在敲助記符時不需要一直按著 Shift+AltGr)。如果你成功輸入了這個符號,你自己應該也能猜到要怎麼輸入 「RIGHT-POINTING DOUBLE ANGLE QUOTATION MARK(右雙角引號)」 了。
來看看另一個例子,試試 Shift+AltGr --- 來生成一個 「EM DASH(長破折號)」(LCTT 譯註:中文輸入法的長破折號由兩個 「EM DASH」 組成)。要做到這個,你需要按下主鍵盤上的的 連字元減號 鍵而非數字鍵盤上的那個。
值得注意的是 Compose 鍵在非 GUI 環境下也能工作。但是取決於你使用的是 X11 控制台還是只顯示文字的控制台,它們所支持的組合按鍵順序並不相同。
在控制台上,你可以通過命令 dumpkeys 來查看支持的組合按鍵列表(LCTT 譯註:可能需要 root 許可權):
dumpkeys --compose-only
在 GUI 下,組合鍵是在 Gtk/X11 層被實現的。想要知道 Gtk 所支持的助記符,可以查看頁面:https://help.ubuntu.com/community/GtkComposeTable
我們可以避免對 Gtk 字元組合的依賴嗎?
或許我是個純粹主義者,但是我為 Gtk 這種對 Compose 鍵進行硬編碼的方式感到悲哀。畢竟,不是所有 GUI 應用都會使用 Gtk 庫。而且我如果想要添加我自己的助記符的話就只能重新編譯 Gtk 了。
幸好在 X11 層也有對字元組合的支持。在以前則是通過令人尊敬的 X 輸入法(XIM)。
這個方法在比起基於 Gtk 的字元組合能夠在更加底層的地方工作,同時具備優秀的靈活性併兼容很多 X11 應用。
比如說,假設我只是想要添加 --> 組合來輸入字元 → (U+2192,RIGHTWARDS ARROW(朝右箭頭)),我只需要新建 ~/.XCompose 文件並寫入以下代碼:
cat > ~/.XCompose << EOT
# Load default compose table for the current local
include "%L"
# Custom definitions
<Multi_key> <minus> <minus> <greater> : U2192 # RIGHTWARDS ARROW
EOT
然後你就可以啟動一個新的 X11 應用,強制函數庫使用 XIM 作為輸入法,並開始測試:
GTK_IM_MODULE="xim" QT_IM_MODULE="xim" xterm
新的組合排序應該可以在你剛啟動的應用里被輸入了。我鼓勵你通過 man 5 compose 來進一步學習組合文件格式。
在你的 ~/.profile 中加入以下兩行來將 XIM 設為你所有應用的默認輸入法。這些改動會在下一次你登錄電腦時生效:
export GTK_IM_MODULE="xim"
export QT_IM_MODULE="xim"
這挺酷的,不是嗎?這樣你就可以隨意的加入你想要的組合排序。而且在默認的 XIM 設置中已經有幾個有意思的組合了。試一下輸入組合鍵 LLAP。
但我不得不提到兩個缺陷。XIM 已經比較老了,而且只適合我們這些不太需要多位元組輸入法的人。其次,當你用 XIM 作為輸入法的時候,你就不能利用 Ctrl+Shift+u 加上代碼點來輸入 Unicode 字元了。什麼?等一下?我還沒聊過那個?讓我們現在來聊一下吧:
如果我需要的字元沒有對應的組合鍵排序該怎麼辦?
組合鍵是一個不錯的工具,它可以用來輸入一些鍵盤上沒有的字元。但默認的組合集有限,而切換 XIM 並為一個你一生僅用一次的字元來定義一個新的組合排序十分麻煩。
但這能阻止你在同一段文字里混用日語、拉丁語,還有西里爾字元嗎?顯然不能,這多虧了 Unicode。比如說,名字 「あゆみ」 由三個字母組成:
- 「HIRAGANA LETTER A(平假名字母 あ)」 (U+3042)
- 「HIRAGANA LETTER YU(平假名字母 ゆ)」 (U+3086)
- 以及 「HIRAGANA LETTER MI(平假名字母 み)」 (U+307F)
我在上文提及了 Unicode 字元的正式名稱,並遵循了全部用大寫拼寫的規範。在它們的名字後面,你可以找到它們的 Unicode 代碼點,位於括弧之間並寫作 16 位的十六進位數字。這讓你想到什麼了嗎?
不管怎樣,一旦你知道了的一個字元的代碼點,你就可以按照以下組合輸入:
Ctrl+Shift+u,然後是XXXX(你想要的字元的 十六進位 代碼點)然後回車。
作為一種簡寫方式,如果你在輸入代碼點時不鬆開 Ctrl+Shift,你就不用敲回車。
不幸的是,這項功能的實現是在軟體庫層而非 X11 層,所以對其支持在不同應用間並不統一。以 LibreOffice 為例,你必須使用主鍵盤來輸入代碼點。而在基於 Gtk 的應用則接受來自數字鍵盤的輸入。
最後,當我和我的 Debian 系統上的控制台打交道時,我發現了一個類似的功能,但它需要你按下 Alt+XXXXX 而 XXXXX 是你想要的字元的 十進位 的代碼點。我很好奇這究竟是 Debian 獨有的功能,還是因為我使用的語言環境(Locale) 是 en_US.UTF-8。如果你對此有更多信息,我會很願意在評論區讀到它們的!
| GUI | 控制台 | 字元 |
|---|---|---|
Ctrl+Shift+u 3042 Enter |
Alt+12354 |
あ |
Ctrl+Shift+u 3086 Enter |
Alt+12422 |
ゆ |
Ctrl+Shift+u 307F Enter |
Alt+12415 |
み |
死鍵
最後值得一提的是,想要不(必須)依賴 Compose 鍵來輸入鍵組合還有一個更簡單的方法。
你的鍵盤上的某些鍵是專門用來創造字元組合的。這些鍵叫做 死鍵 。這是因為當你按下它們一次,看起來什麼都沒有發生,但它們會悄悄地改變你下一次按鍵所產生的字元。這個行為的靈感來自於機械打字機:在使用機械打字機時,按下一個死鍵會印下一個字元,但不會移動字盤。於是下一次按鍵則會在同一個地方印下另一個字元。視覺效果就是兩次按鍵的組合。
我們在法語里經常用到這個。舉例來說,想要輸入字母 ë 我必須按下死鍵 ¨ 然後再按下 e 鍵。同樣地,西班牙人的鍵盤上有著死鍵 ~。而在北歐語系下的鍵盤布局,你可以找到 ° 鍵。我可以念很久這份清單。
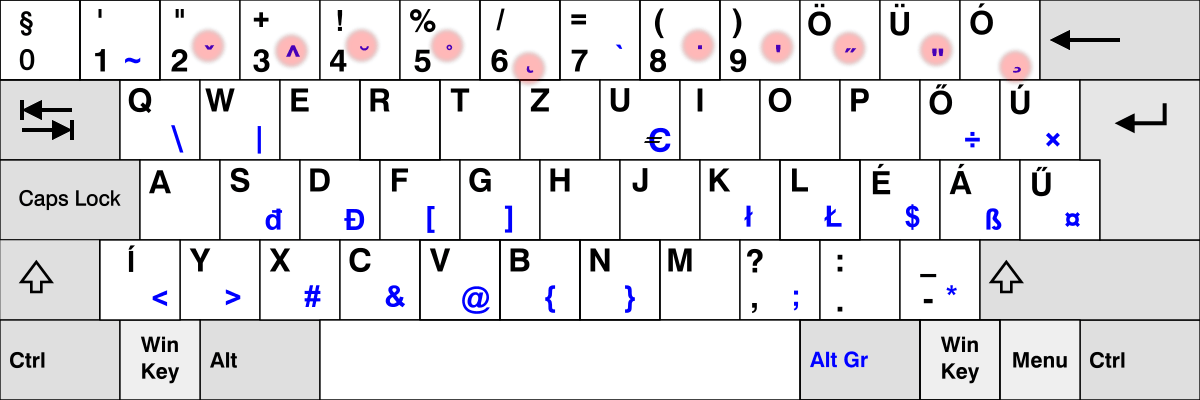
顯然,不是所有鍵盤都有所有死鍵。實際上,你的鍵盤上是找不到大部分死鍵的。比如說,我猜在你們當中只有小部分人——如果真的有的話——有死鍵 ¯ 來輸入 Tōkyō 所需要的長音符號(「平變音符」)。
對於那些你鍵盤上沒有的死鍵,你需要尋找別的解決方案。好消息是,我們已經用過那些技術了。但這一次我們要用它們來模擬死鍵,而非「普通」鍵。
那麼,我們的第一個選擇是利用 Compose - 來生成長音符號(你鍵盤上有的連字元減號)。按下時屏幕上什麼都不會出現,但當你接著按下 o 鍵你就能看到 ō。
Gtk 在組合模式下可以生成的一系列死鍵都能在 這裡 找到。
另一個解決方法則是利用 Unicode 字元 「COMBINING MACRON(組合長音符號)」(U+0304),然後字母 o。我把細節都留給你。但如果你好奇的話,你會發現你打出的結果有著微妙的不同,你並沒有真地打出 「LATIN SMALL LETTER O WITH MACRON(小寫拉丁字母 O 帶長音符號)」。我在上一句話的結尾用了大寫拼寫,這就是一個提示,引導你尋找通過 Unicode 組合字元按更少的鍵輸入 ō 的方法……現在我將這些留給你的聰明才智去解決了。
輪到你來練習了!
所以,你都學會了嗎?這些在你的電腦上工作嗎?現在輪到你來嘗試了:根據上面提出的線索,加上一點練習,現在你可以完成文章開頭給出的挑戰了。挑戰一下吧,然後把成果複製到評論區作為你成功的證明。
贏了也沒有獎勵,或許來自同伴的驚嘆能夠滿足你!
via: https://itsfoss.com/unicode-linux/
作者:Sylvain Leroux 選題:lkxed 譯者:yzuowei 校對:wxy
本文轉載來自 Linux 中國: https://github.com/Linux-CN/archive
對這篇文章感覺如何?
You may also like






More in:Linux中國

捐贈 Let's Encrypt,共建安全的互聯網

Let's Encrypt 正式發布,已經保護 380 萬個域名

關於Linux防火牆iptables的面試問答

Lets Encrypt 已被所有主流瀏覽器所信任









