用 Spark SQL 進行結構化數據處理

有了 Spark SQL,用戶可以編寫 SQL 風格的查詢。這對於精通結構化查詢語言或 SQL 的廣大用戶群體來說,基本上是很有幫助的。用戶也將能夠在結構化數據上編寫互動式和臨時性的查詢。Spark SQL 彌補了 彈性分散式數據集 (RDD)和關係表之間的差距。RDD 是 Spark 的基本數據結構。它將數據作為分散式對象存儲在適合併行處理的節點集群中。RDD 很適合底層處理,但在運行時很難調試,程序員不能自動推斷 模式 。另外,RDD 沒有內置的優化功能。Spark SQL 提供了 數據幀 和數據集來解決這些問題。
Spark SQL 可以使用現有的 Hive 元存儲、SerDes 和 UDF。它可以使用 JDBC/ODBC 連接到現有的 BI 工具。
數據源
大數據處理通常需要處理不同的文件類型和數據源(關係型和非關係型)的能力。Spark SQL 支持一個統一的數據幀介面來處理不同類型的源,如下所示。
- 文件:
- CSV
- Text
- JSON
- XML
- JDBC/ODBC:
- MySQL
- Oracle
- Postgres
- 帶模式的文件:
- AVRO
- Parquet
- Hive 表:
- Spark SQL 也支持讀寫存儲在 Apache Hive 中的數據。
通過數據幀,用戶可以無縫地讀取這些多樣化的數據源,並對其進行轉換/連接。
Spark SQL 3.x 的新內容
在以前的版本中(Spark 2.x),查詢計劃是基於啟發式規則和成本估算的。從解析到邏輯和物理查詢計劃,最後到優化的過程是連續的。這些版本對轉換和行動的運行時特性幾乎沒有可見性。因此,由於以下原因,查詢計劃是次優的:
- 缺失和過時的統計數據
- 次優的啟發式方法
- 錯誤的成本估計
Spark 3.x 通過使用運行時數據來迭代改進查詢計劃和優化,增強了這個過程。前一階段的運行時統計數據被用來優化後續階段的查詢計劃。這裡有一個反饋迴路,有助於重新規劃和重新優化執行計劃。
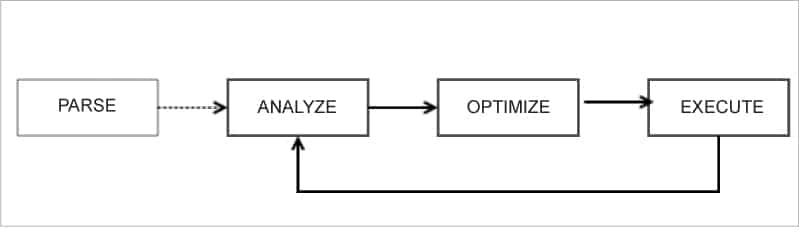
自適應查詢執行(AQE)
查詢被改變為邏輯計劃,最後變成物理計劃。這裡的概念是「重新優化」。它利用前一階段的可用數據,為後續階段重新優化。正因為如此,整個查詢的執行要快得多。
AQE 可以通過設置 SQL 配置來啟用,如下所示(Spark 3.0 中默認為 false):
spark.conf.set(「spark.sql.adaptive.enabled」,true)
動態合併「洗牌」分區
Spark 在「 洗牌 」操作後確定最佳的分區數量。在 AQE 中,Spark 使用默認的分區數,即 200 個。這可以通過配置來啟用。
spark.conf.set(「spark.sql.adaptive.coalescePartitions.enabled」,true)
動態切換連接策略
廣播哈希是最好的連接操作。如果其中一個數據集很小,Spark 可以動態地切換到廣播連接,而不是在網路上「洗牌」大量的數據。
動態優化傾斜連接
如果數據分布不均勻,數據會出現傾斜,會有一些大的分區。這些分區佔用了大量的時間。Spark 3.x 通過將大分區分割成多個小分區來進行優化。這可以通過設置來啟用:
spark.conf.set(「spark.sql.adaptive.skewJoin.enabled」,true)
其他改進措施
此外,Spark SQL 3.x還支持以下內容。
動態分區修剪
3.x 將只讀取基於其中一個表的值的相關分區。這消除了解析大表的需要。
連接提示
如果用戶對數據有了解,這允許用戶指定要使用的連接策略。這增強了查詢的執行過程。
兼容 ANSI SQL
在兼容 Hive 的早期版本的 Spark 中,我們可以在查詢中使用某些關鍵詞,這樣做是完全可行的。然而,這在 Spark SQL 3 中是不允許的,因為它有完整的 ANSI SQL 支持。例如,「將字元串轉換為整數」會在運行時產生異常。它還支持保留關鍵字。
較新的 Hadoop、Java 和 Scala 版本
從 Spark 3.0 開始,支持 Java 11 和 Scala 2.12。 Java 11 具有更好的原生協調和垃圾校正,從而帶來更好的性能。 Scala 2.12 利用了 Java 8 的新特性,優於 2.11。
Spark 3.x 提供了這些現成的有用功能,而無需開發人員操心。這將顯著提高 Spark 的整體性能。
via: https://www.opensourceforu.com/2022/05/structured-data-processing-with-spark-sql/
作者:Phani Kiran 選題:lkxed 譯者:geekpi 校對:wxy
本文轉載來自 Linux 中國: https://github.com/Linux-CN/archive
對這篇文章感覺如何?
You may also like






More in:Linux中國

捐贈 Let's Encrypt,共建安全的互聯網

Let's Encrypt 正式發布,已經保護 380 萬個域名

關於Linux防火牆iptables的面試問答

Lets Encrypt 已被所有主流瀏覽器所信任









