漫遊 HTTP/2

HTTP 是什麼
首先我們要明白 HTTP 是什麼。HTTP 是一個基於 TCP/IP 的應用層通信協議,它是客戶端和服務端在互聯網互相通訊的標準。它定義了內容是如何通過互聯網進行請求和傳輸的。HTTP 是在應用層中抽象出的一個標準,使得主機(客戶端和服務端)之間的通信得以通過 TCP/IP 來進行請求和響應。TCP 默認使用的埠是 80,當然也可以使用其它埠,比如 HTTPS 使用的就是 443 埠。
HTTP/0.9 - 單行協議 (1991)
HTTP 最早的規範可以追溯到 1991 年,那時候的版本是 HTTP/0.9,該版本極其簡單,只有一個叫做 GET的請求方式。如果客戶端要訪問服務端上的一個頁面,只需要如下非常簡單的請求:
GET /index.html
服務端對應的返回類似如下:
(response body)
(connection closed)
就這麼簡單,服務端捕獲到請求後立馬返回 HTML 並且關閉連接,在這之中
- 沒有 頭信息
- 僅支持
GET這一種請求方法 - 必須返回 HTML
如同你所看到的,當時的 HTTP 協議只是一塊基礎的墊腳石。
HTTP/1.0 - 1996
在 1996 年,新版本的 HTTP 對比之前的版本有了極大的改進,同時也被命名為 HTTP/1.0。
與 HTTP/0.9 只能返回 HTML 不同的是,HTTP/1.0 支持處理多種返回的格式,比如圖片、視頻、文本或者其他格式的文件。它還增加了更多的請求方法(如 POST 和 HEAD),請求和響應的格式也相應做了改變,兩者都增加了頭信息;引入了狀態碼來定義返回的特徵;引入了字符集支持;支持 多段類型 、用戶驗證信息、緩存、內容編碼格式等等。
一個簡單的 HTTP/1.0 請求大概是這樣的:
GET / HTTP/1.0
Host: kamranahmed.info
User-Agent: Mozilla/5.0 (Macintosh; Intel Mac OS X 10_10_5)
Accept: */*
正如你所看到的,在請求中附帶了客戶端中的一些個人信息、響應類型要求等內容。這些是在 HTTP/0.9 無法實現的,因為那時候沒有頭信息。
一個對上述請求的響應例子如下所示:
HTTP/1.0 200 OK
Content-Type: text/plain
Content-Length: 137582
Expires: Thu, 05 Dec 1997 16:00:00 GMT
Last-Modified: Wed, 5 August 1996 15:55:28 GMT
Server: Apache 0.84
(response body)
(connection closed)
從 HTTP/1.0 (HTTP 後面跟的是版本號)早期開始,在狀態碼 200 之後就附帶一個原因短語(你可以用來描述狀態碼)。
在這個較新一點的版本中,請求和響應的頭信息仍然必須是 ASCII 編碼,但是響應的內容可以是任意類型,如圖片、視頻、HTML、文本或其他類型,伺服器可以返回任意內容給客戶端。所以這之後,HTTP 中的「 超文本 」成了名不副實。 HMTP ( 超媒體傳輸協議 )可能會更有意義,但是我猜我們還是會一直沿用這個名字。
HTTP/1.0 的一個主要缺點就是它不能在一個連接內擁有多個請求。這意味著,當客戶端需要從伺服器獲取東西時,必須建立一個新的 TCP 連接,並且處理完單個請求後連接即被關閉。需要下一個東西時,你必須重新建立一個新的連接。這樣的壞處在哪呢?假設你要訪問一個有 10 張圖片,5 個 樣式表 和 5 個 JavaScript 的總計 20 個文件才能完整展示的一個頁面。由於一個連接在處理完成一次請求後即被關閉,所以將有 20 個單獨的連接,每一個文件都將通過各自對應的連接單獨處理。當連接數量變得龐大的時候就會面臨嚴重的性能問題,因為 TCP 啟動需要經過三次握手,才能緩慢開始。
三次握手
三次握手是一個簡單的模型,所有的 TCP 連接在傳輸應用數據之前都需要在三次握手中傳輸一系列數據包。
SYN- 客戶端選取一個隨機數,我們稱為x,然後發送給伺服器。SYN ACK- 伺服器響應對應請求的ACK包中,包含了一個由伺服器隨機產生的數字,我們稱為y,並且把客戶端發送的x+1,一併返回給客戶端。ACK- 客戶端在從伺服器接受到y之後把y加上1作為一個ACK包返回給伺服器。
一旦三次握手完成後,客戶端和伺服器之間就可以開始交換數據。值得注意的是,當客戶端發出最後一個 ACK 數據包後,就可以立刻向伺服器發送應用數據包,而伺服器則需要等到收到這個 ACK 數據包後才能接受應用數據包。
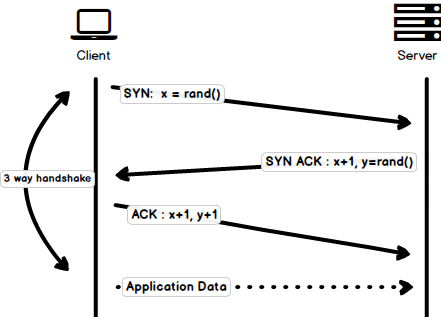
請注意,上圖有點小問題,客戶端發回的最後一個 ACK 包僅包含
y+1,上圖應該是ACK:y+1而不是ACK:x+1,y+1
然而,某些 HTTP/1.0 的實現試圖通過新引入一個稱為 Connection: keep-alive 的頭信息來克服這一問題,這個頭信息意味著告訴伺服器「嘿,伺服器,請不要關閉此連接,我還要用它」。但是,這並沒有得到廣泛的支持,問題依然存在。
除了無連接之外,HTTP 還是一個無狀態的協議,即伺服器不維護有關客戶端的信息。因此每個請求必須給伺服器必要的信息才能完成請求,每個請求都與之前的舊的請求無關。所以,這增加了推波助瀾的作用,客戶端除了需要新建大量連接之外,在每次連接中還需要發送許多重複的數據,這導致了帶寬的大量浪費。
HTTP/1.1 - 1999
HTTP/1.0 經過僅僅 3 年,下一個版本,即 HTTP/1.1 就在 1999 年發布了,改進了它的前身很多問題,主要的改進包括:
- 增加了許多 HTTP 請求方法,包括
PUT、PATCH、HEAD、OPTIONS、DELETE。 - 主機標識符
Host在HTTP/1.0並不是必須的,而在HTTP/1.1是必須的。 - 如上所述的持久連接。在
HTTP/1.0中每個連接只有一個請求並在該請求結束後被立即關閉,這導致了性能問題和增加了延遲。HTTP/1.1引入了持久連接,即連接在默認情況下是不關閉並保持開放的,這允許多個連續的請求使用這個連接。要關閉該連接只需要在頭信息加入Connection: close,客戶通常在最後一個請求里發送這個頭信息就能安全地關閉連接。 - 新版本還引入了「 管線化 」的支持,客戶端可以不用等待伺服器返迴響應,就能在同一個連接內發送多個請求給伺服器,而伺服器必須以接收到的請求相同的序列發送響應。但是你可能會問了,客戶端如何知道哪裡是第一個響應下載完成而下一個響應內容開始的地方呢?要解決這個問題,頭信息必須有
Content-Length,客戶可以使用它來確定哪些響應結束之後可以開始等待下一個響應。- 值得注意的是,為了從持久連接或管線化中受益, 頭部信息必須包含
Content-Length,因為這會使客戶端知道什麼時候完成了傳輸,然後它可以發送下一個請求(持久連接中,以正常的依次順序發送請求)或開始等待下一個響應(啟用管線化時)。 - 但是,使用這種方法仍然有一個問題。那就是,如果數據是動態的,伺服器無法提前知道內容長度呢?那麼在這種情況下,你就不能使用這種方法中獲益了嗎?為了解決這個問題,
HTTP/1.1引進了分塊編碼。在這種情況下,伺服器可能會忽略Content-Length來支持分塊編碼(更常見一些)。但是,如果它們都不可用,那麼連接必須在請求結束時關閉。
- 值得注意的是,為了從持久連接或管線化中受益, 頭部信息必須包含
- 在動態內容的情況下分塊傳輸,當伺服器在傳輸開始但無法得到
Content-Length時,它可能會開始按塊發送內容(一塊接一塊),並在傳輸時為每一個小塊添加Content-Length。當發送完所有的數據塊後,即整個傳輸已經完成後,它發送一個空的小塊,比如設置Content-Length為 0 ,以便客戶端知道傳輸已完成。為了通知客戶端塊傳輸的信息,伺服器在頭信息中包含了Transfer-Encoding: chunked。 - 不像 HTTP/1.0 中只有 Basic 身份驗證方式,
HTTP/1.1包括 摘要驗證方式 和 代理驗證方式 。 - 緩存。
- 範圍請求 。
- 字符集。
- 內容協商 。
- 客戶端 cookies。
- 支持壓縮。
- 新的狀態碼。
- 等等。
我不打算在這裡討論所有 HTTP/1.1 的特性,因為你可以圍繞這個話題找到很多關於這些的討論。我建議你閱讀 HTTP/1.0 和 HTTP/1.1 版本之間的主要差異,希望了解更多可以讀原始的 RFC。
HTTP/1.1 在 1999 年推出,到現在已經是多年前的標準。雖然,它比前一代改善了很多,但是網路日新月異,它已經垂垂老矣。相比之前,載入網頁更是一個資源密集型任務,打開一個簡單的網頁已經需要建立超過 30 個連接。你或許會說,HTTP/1.1 具有持久連接,為什麼還有這麼多連接呢?其原因是,在任何時刻 HTTP/1.1 只能有一個未完成的連接。 HTTP/1.1 試圖通過引入管線來解決這個問題,但它並沒有完全地解決。因為一旦管線遇到了緩慢的請求或龐大的請求,後面的請求便被阻塞住,它們必須等待上一個請求完成。為了克服 HTTP/1.1 的這些缺點,開發人員開始實現一些解決方法,例如使用 spritesheets、在 CSS 中編碼圖像、單個巨型 CSS / JavaScript 文件、域名切分等。
SPDY - 2009
谷歌走在業界前列,為了使網路速度更快,提高網路安全,同時減少網頁的等待時間,他們開始實驗替代的協議。在 2009 年,他們宣布了 SPDY。
SPDY是谷歌的商標,而不是一個縮寫。
顯而易見的是,如果我們繼續增加帶寬,網路性能開始的時候能夠得到提升,但是到了某個階段後帶來的性能提升就很有限了。但是如果把這些優化放在等待時間上,比如減少等待時間,將會有持續的性能提升。這就是 SPDY 優化之前的協議的核心思想,減少等待時間來提升網路性能。
對於那些不知道其中區別的人,等待時間就是延遲,即數據從源到達目的地需要多長時間(單位為毫秒),而帶寬是每秒鐘數據的傳輸量(比特每秒)。
SPDY 的特點包括:復用、壓縮、優先順序、安全性等。我不打算展開 SPDY 的細節。在下一章節,當我們將介紹 HTTP/2,這些都會被提到,因為 HTTP/2 大多特性是從 SPDY 受啟發的。
SPDY 沒有試圖取代 HTTP,它是處於應用層的 HTTP 之上的一個傳輸層,它只是在請求被發送之前做了一些修改。它開始成為事實標準,大多數瀏覽器都開始支持了。
2015年,谷歌不想有兩個相互競爭的標準,所以他們決定將其合併到 HTTP 協議,這樣就導致了 HTTP/2 的出現和 SPDY 的廢棄。
HTTP/2 - 2015
現在想必你明白了為什麼我們需要另一個版本的 HTTP 協議了。 HTTP/2 是專為了低延遲地內容傳輸而設計。主要特點和與 HTTP/1.1 的差異包括:
- 使用二進位替代明文
- 多路傳輸 - 多個非同步 HTTP 請求可以使用單一連接
- 報頭使用 HPACK 壓縮
- 伺服器推送 - 單個請求多個響應
- 請求優先順序
- 安全性
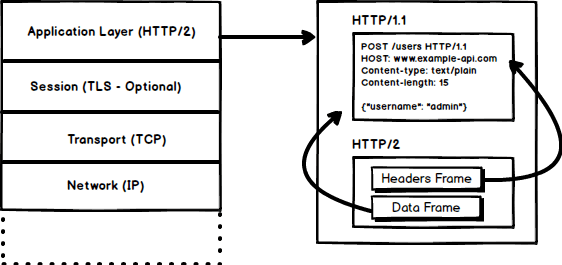
1. 二進位協議
HTTP/2 通過使其成為一個二進位協議以解決 HTTP/1.x 中存在的延遲問題。作為一個二進位協議,它更容易解析,但可讀性卻不如 HTTP/1.x。 幀 和 流 的概念組成了 HTTP/2 的主要部分。
幀和流
現在 HTTP 消息是由一個或多個幀組成的。HEADERS 幀承載了 元數據 ,DATA 幀則承載了內容。還有其他類型的幀(HEADERS、DATA、RST_STREAM、SETTINGS、PRIORITY 等等),這些你可以通過 HTTP/2 規範來了解。
每個 HTTP/2 請求和響應都被賦予一個唯一的流 ID,並切分成幀。幀就是一小片二進位數據。幀的集合稱為流,每個幀都有個標識了其所屬流的流 ID,所以在同一個流下的每個幀具有共同的報頭。值得注意的是,除了流 ID 是唯一的之外,由客戶端發起的請求使用了奇數作為流 ID,從來自伺服器的響應使用了偶數作為流 ID。
除了 HEADERS 幀和 DATA 幀,另一個值得一提的幀是 RST_STREAM。這是一個特殊的幀類型,用來中止流,即客戶可以發送此幀讓伺服器知道,我不再需要這個流了。在 HTTP/1.1 中讓伺服器停止給客戶端發送響應的唯一方法是關閉連接,這樣造成了延遲增加,因為之後要發送請求時,就要必須打開一個新的請求。而在 HTTP/2,客戶端可以使用 RST_STREAM 來停止接收特定的數據流,而連接仍然打開著,可以被其他請求使用。
2. 多路傳輸
因為 HTTP/2 是一個二進位協議,而且如上所述它使用幀和流來傳輸請求與響應,一旦建立了 TCP 連接,相同連接內的所有流都可以同過這個 TCP 連接非同步發送,而不用另外打開連接。反過來說,伺服器也可以使用同樣的非同步方式返迴響應,也就是說這些響應可以是無序的,客戶端使用分配的流 ID 來識別數據包所屬的流。這也解決了 HTTP/1.x 中請求管道被阻塞的問題,即客戶端不必等待佔用時間的請求而其他請求仍然可以被處理。
3. HPACK 請求頭部壓縮
RFC 花了一篇文檔的篇幅來介紹針對發送的頭信息的優化,它的本質是當我們在同一客戶端上不斷地訪問伺服器時,許多冗餘數據在頭部中被反覆發送,有時候僅僅是 cookies 就能增加頭信息的大小,這會佔用許多寬頻和增加傳輸延遲。為了解決這個問題,HTTP/2 引入了頭信息壓縮。
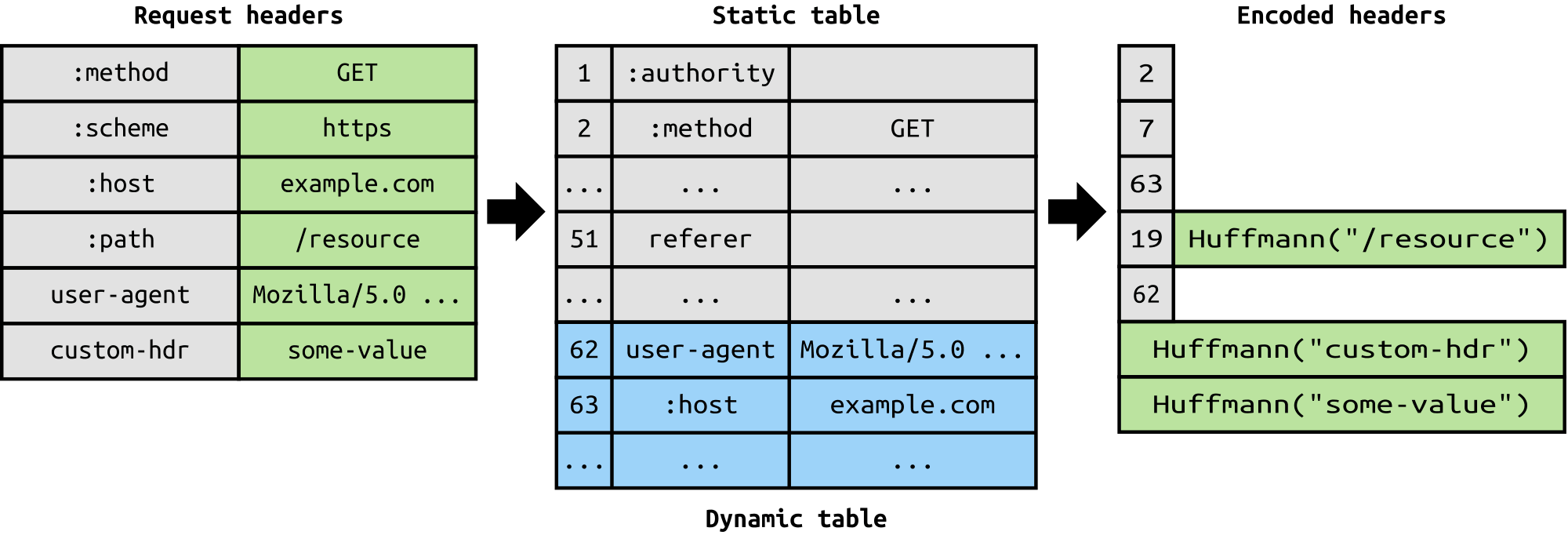
不像請求和響應那樣,頭信息中的信息不會以 gzip 或者 compress 等格式壓縮。而是採用一種不同的機制來壓縮頭信息,客戶端和伺服器同時維護一張頭信息表,儲存了使用了哈夫曼編碼進行編碼後的頭信息的值,並且後續請求中若出現同樣的欄位則忽略重複值(例如 用戶代理 等),只發送存在兩邊信息表中它的引用即可。
我們說的頭信息,它們同 HTTP/1.1 中一樣,並在此基礎上增加了一些偽頭信息,如 :scheme,:host 和 :path。
4. 伺服器推送
伺服器推送是 HTTP/2 的另一個巨大的特點。對於伺服器來說,當它知道客戶端需要一定的資源後,它可以把數據推送到客戶端,即使客戶端沒有請求它。例如,假設一個瀏覽器在載入一個網頁時,它解析了整個頁面,發現有一些內容必須要從服務端獲取,然後發送相應的請求到伺服器以獲取這些內容。
伺服器推送減少了傳輸這些數據需要來回請求的次數。它是如何做到的呢?伺服器通過發送一個名字為 PUSH_PROMISE 特殊的幀通知到客戶端「嘿,我準備要發送這個資源給你了,不要再問我要了。」這個 PUSH_PROMISE 幀與要產生推送的流聯繫在一起,並包含了要推送的流 ID,也就是說這個流將會被伺服器推送到客戶端上。
5. 請求優先順序
當流被打開的時候,客戶端可以在 HEADERS 幀中包含優先順序信息來為流指定優先順序。在任何時候,客戶端都可以發送 PRIORITY 幀來改變流的優先順序。
如果沒有任何優先順序信息,伺服器將非同步地無序地處理這些請求。如果流分配了優先順序,伺服器將基於這個優先順序來決定需要分配多少資源來處理這個請求。
6. 安全性
在是否強制使用 TLS 來增加安全性的問題上產生了大範圍的討論,討論的結果是不強制使用。然而大多數廠商只有在使用 TLS 時才能使用 HTTP/2。所以 HTTP/2 雖然規範上不要求加密,但是加密已經約定俗成了。這樣,在 TLS 之上實現 HTTP/2 就有了一些強制要求,比如,TLS 的最低版本為 1.2,必須達到某種級別的最低限度的密鑰大小,需要布署 ephemeral 密鑰等等。
到現在 HTTP/2 已經完全超越了 SPDY,並且還在不斷成長,HTTP/2 有很多關係性能的提升,我們應該開始布署它了。
如果你想更深入的了解細節,請訪問該規範的鏈接和 HTTP/2 性能提升演示的鏈接。請在留言板寫下你的疑問或者評論,最後如果你發現有錯誤,請同樣留言指出。
這就是全部了,我們之後再見~
via: http://kamranahmed.info/blog/2016/08/13/http-in-depth/
作者:Kamran Ahmed 譯者:NearTan 校對:wxy
本文轉載來自 Linux 中國: https://github.com/Linux-CN/archive
對這篇文章感覺如何?
You may also like






More in:Linux中國

捐贈 Let's Encrypt,共建安全的互聯網

Let's Encrypt 正式發布,已經保護 380 萬個域名

關於Linux防火牆iptables的面試問答

Lets Encrypt 已被所有主流瀏覽器所信任









