遞歸:夢中夢

遞歸是很神奇的,但是在大多數的編程類書藉中對遞歸講解的並不好。它們只是給你展示一個遞歸階乘的實現,然後警告你遞歸運行的很慢,並且還有可能因為棧緩衝區溢出而崩潰。「你可以將頭伸進微波爐中去烘乾你的頭髮,但是需要警惕顱內高壓並讓你的頭髮生爆炸,或者你可以使用毛巾來擦乾頭髮。」難怪人們不願意使用遞歸。但這種建議是很糟糕的,因為在演算法中,遞歸是一個非常強大的思想。

我們來看一下這個經典的遞歸階乘:
#include <stdio.h>
int factorial(int n)
{
int previous = 0xdeadbeef;
if (n == 0 || n == 1) {
return 1;
}
previous = factorial(n-1);
return n * previous;
}
int main(int argc)
{
int answer = factorial(5);
printf("%dn", answer);
}
遞歸階乘 - factorial.c
函數調用自身的這個觀點在一開始是讓人很難理解的。為了讓這個過程更形象具體,下圖展示的是當調用 factorial(5) 並且達到 n == 1這行代碼 時,棧上 端點的情況:
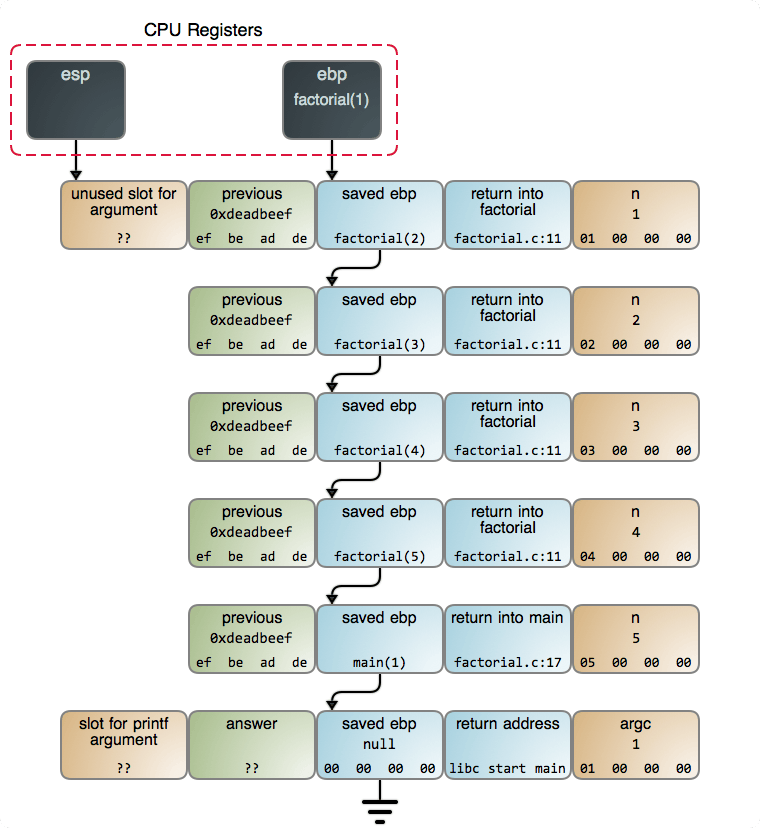
每次調用 factorial 都生成一個新的 棧幀。這些棧幀的創建和 銷毀 是使得遞歸版本的階乘慢於其相應的迭代版本的原因。在調用返回之前,累積的這些棧幀可能會耗盡棧空間,進而使你的程序崩潰。
而這些擔心經常是存在於理論上的。例如,對於每個 factorial 的棧幀佔用 16 位元組(這可能取決於棧排列以及其它因素)。如果在你的電腦上運行著現代的 x86 的 Linux 內核,一般情況下你擁有 8 GB 的棧空間,因此,factorial 程序中的 n 最多可以達到 512,000 左右。這是一個 巨大無比的結果,它將花費 8,971,833 比特來表示這個結果,因此,棧空間根本就不是什麼問題:一個極小的整數 —— 甚至是一個 64 位的整數 —— 在我們的棧空間被耗盡之前就早已經溢出了成千上萬次了。
過一會兒我們再去看 CPU 的使用,現在,我們先從比特和位元組回退一步,把遞歸看作一種通用技術。我們的階乘演算法可歸結為:將整數 N、N-1、 … 1 推入到一個棧,然後將它們按相反的順序相乘。實際上我們使用了程序調用棧來實現這一點,這是它的細節:我們在堆上分配一個棧並使用它。雖然調用棧具有特殊的特性,但是它也只是又一種數據結構而已,你可以隨意使用。我希望這個示意圖可以讓你明白這一點。
當你將棧調用視為一種數據結構,有些事情將變得更加清晰明了:將那些整數堆積起來,然後再將它們相乘,這並不是一個好的想法。那是一種有缺陷的實現:就像你拿螺絲刀去釘釘子一樣。相對更合理的是使用一個迭代過程去計算階乘。
但是,螺絲釘太多了,我們只能挑一個。有一個經典的面試題,在迷宮裡有一隻老鼠,你必須幫助這隻老鼠找到一個乳酪。假設老鼠能夠在迷宮中向左或者向右轉彎。你該怎麼去建模來解決這個問題?
就像現實生活中的很多問題一樣,你可以將這個老鼠找乳酪的問題簡化為一個圖,一個二叉樹的每個結點代表在迷宮中的一個位置。然後你可以讓老鼠在任何可能的地方都左轉,而當它進入一個死胡同時,再回溯回去,再右轉。這是一個老鼠行走的 迷宮示例:
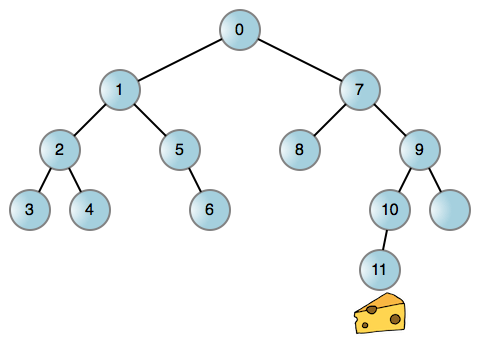
每到邊緣(線)都讓老鼠左轉或者右轉來到達一個新的位置。如果向哪邊轉都被攔住,說明相關的邊緣不存在。現在,我們來討論一下!這個過程無論你是調用棧還是其它數據結構,它都離不開一個遞歸的過程。而使用調用棧是非常容易的:
#include <stdio.h>
#include "maze.h"
int explore(maze_t *node)
{
int found = 0;
if (node == NULL)
{
return 0;
}
if (node->hasCheese){
return 1;// found cheese
}
found = explore(node->left) || explore(node->right);
return found;
}
int main(int argc)
{
int found = explore(&maze);
}
遞歸迷宮求解 下載
當我們在 maze.c:13 中找到乳酪時,棧的情況如下圖所示。你也可以在 GDB 輸出 中看到更詳細的數據,它是使用 命令 採集的數據。
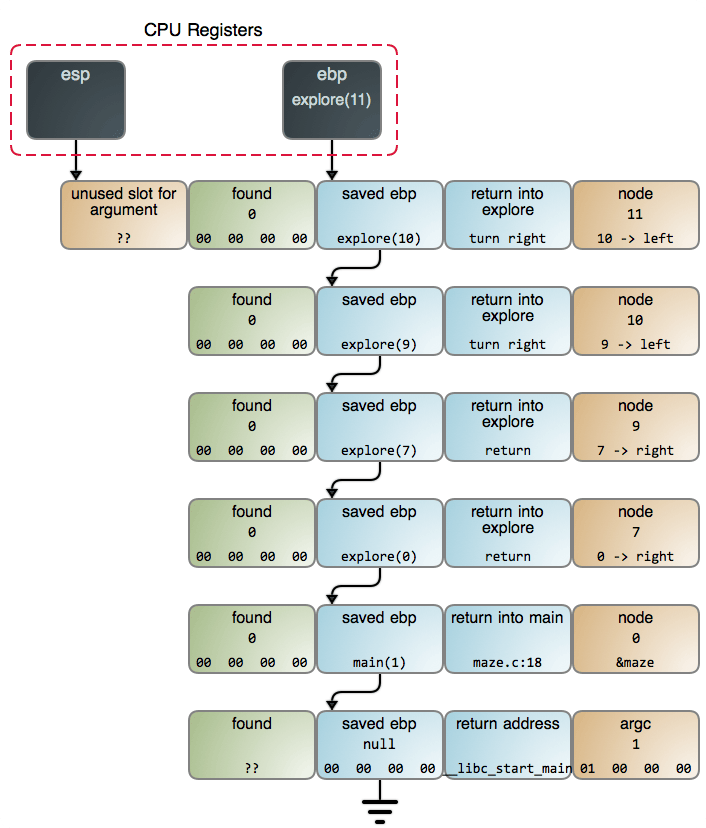
它展示了遞歸的良好表現,因為這是一個適合使用遞歸的問題。而且這並不奇怪:當涉及到演算法時,遞歸是規則,而不是例外。它出現在如下情景中——進行搜索時、進行遍歷樹和其它數據結構時、進行解析時、需要排序時——它無處不在。正如眾所周知的 pi 或者 e,它們在數學中像「神」一樣的存在,因為它們是宇宙萬物的基礎,而遞歸也和它們一樣:只是它存在於計算結構中。
Steven Skienna 的優秀著作 演算法設計指南 的精彩之處在於,他通過 「戰爭故事」 作為手段來詮釋工作,以此來展示解決現實世界中的問題背後的演算法。這是我所知道的拓展你的演算法知識的最佳資源。另一個讀物是 McCarthy 的 關於 LISP 實現的的原創論文。遞歸在語言中既是它的名字也是它的基本原理。這篇論文既可讀又有趣,在工作中能看到大師的作品是件讓人興奮的事情。
回到迷宮問題上。雖然它在這裡很難離開遞歸,但是並不意味著必須通過調用棧的方式來實現。你可以使用像 RRLL 這樣的字元串去跟蹤轉向,然後,依據這個字元串去決定老鼠下一步的動作。或者你可以分配一些其它的東西來記錄追尋乳酪的整個狀態。你仍然是實現了一個遞歸的過程,只是需要你實現一個自己的數據結構。
那樣似乎更複雜一些,因為棧調用更合適。每個棧幀記錄的不僅是當前節點,也記錄那個節點上的計算狀態(在這個案例中,我們是否只讓它走左邊,或者已經嘗試向右)。因此,代碼已經變得不重要了。然而,有時候我們因為害怕溢出和期望中的性能而放棄這種優秀的演算法。那是很愚蠢的!
正如我們所見,棧空間是非常大的,在耗盡棧空間之前往往會遇到其它的限制。一方面可以通過檢查問題大小來確保它能夠被安全地處理。而對 CPU 的擔心是由兩個廣為流傳的有問題的示例所導致的: 啞階乘 和可怕的無記憶的 O( 2 n ) Fibonacci 遞歸。它們並不是棧遞歸演算法的正確代表。
事實上棧操作是非常快的。通常,棧對數據的偏移是非常準確的,它在 緩存 中是熱數據,並且是由專門的指令來操作它的。同時,使用你自己定義的在堆上分配的數據結構的相關開銷是很大的。經常能看到人們寫的一些比棧調用遞歸更複雜、性能更差的實現方法。最後,現代的 CPU 的性能都是 非常好的 ,並且一般 CPU 不會是性能瓶頸所在。在考慮犧牲程序的簡單性時要特別注意,就像經常考慮程序的性能及性能的測量那樣。
下一篇文章將是探秘棧系列的最後一篇了,我們將了解尾調用、閉包、以及其它相關概念。然後,我們就該深入我們的老朋友—— Linux 內核了。感謝你的閱讀!

via:https://manybutfinite.com/post/recursion/
作者:Gustavo Duarte 譯者:qhwdw 校對:FSSlc
本文轉載來自 Linux 中國: https://github.com/Linux-CN/archive
對這篇文章感覺如何?
You may also like






More in:Linux中國

捐贈 Let's Encrypt,共建安全的互聯網

Let's Encrypt 正式發布,已經保護 380 萬個域名

關於Linux防火牆iptables的面試問答

Lets Encrypt 已被所有主流瀏覽器所信任









