x86 和 ARM 的 Python 爬蟲速度對比

假如說,如果你的老闆給你的任務是一次又一次地訪問競爭對手的網站,把對方商品的價格記錄下來,而且要純手工操作,恐怕你會想要把整個辦公室都燒掉。
之所以現在網路爬蟲的影響力如此巨大,就是因為網路爬蟲可以被用於追蹤客戶的情緒和趨向、搜尋空缺的職位、監控房地產的交易,甚至是獲取 UFC 的比賽結果。除此以外,還有很多意想不到的用途。
對於有這方面愛好的人來說,爬蟲無疑是一個很好的工具。因此,我使用了 Scrapy 這個基於 Python 編寫的開源網路爬蟲框架。
鑒於我不太了解這個工具是否會對我的計算機造成傷害,我並沒有將它搭建在我的主力機器上,而是搭建在了一台樹莓派上面。
令人感到意外的是,Scrapy 在樹莓派上面的性能並不差,或許這是 ARM 架構伺服器的又一個成功例子?
我嘗試 Google 了一下,但並沒有得到令我滿意的結果,僅僅找到了一篇相關的《Drupal 建站對比》。這篇文章的結論是,ARM 架構伺服器性能比昂貴的 x86 架構伺服器要更好。
從另一個角度來看,這種 web 服務可以看作是一個「被爬蟲」服務,但和 Scrapy 對比起來,前者是基於 LAMP 技術棧,而後者則依賴於 Python,這就導致兩者之間沒有太多的可比性。
那我們該怎樣做呢?只能在一些 VPS 上搭建服務來對比一下了。
什麼是 ARM 架構處理器?
ARM 是目前世界上最流行的 CPU 架構。
但 ARM 架構處理器在很多人眼中的地位只是作為一個省錢又省電的選擇,而不是跑在生產環境中的處理器的首選。
然而,誕生於英國劍橋的 ARM CPU,最初是用於極其昂貴的 Acorn Archimedes 計算機上的,這是當時世界上最強大的桌面計算機,甚至在很長一段時間內,它的運算速度甚至比最快的 386 還要快好幾倍。
Acorn 公司和 Commodore、Atari 的理念類似,他們認為一家偉大的計算機公司就應該製造出偉大的計算機,讓人感覺有點目光短淺。而比爾蓋茨的想法則有所不同,他力圖在更多不同種類和價格的 x86 機器上使用他的 DOS 系統。
擁有大量用戶基數的平台會成為第三方開發者開發軟體的平台,而軟體資源豐富又會讓你的計算機更受用戶歡迎。
即使是蘋果公司也幾乎被打敗。在 x86 晶元上投入大量的財力,最終,這些晶元被用於生產環境計算任務。
但 ARM 架構也並沒有消失。基於 ARM 架構的晶元不僅運算速度快,同時也非常節能。因此諸如機頂盒、PDA、數碼相機、MP3 播放器這些電子產品多數都會採用 ARM 架構的晶元,甚至在很多需要用電池或不配備大散熱風扇的電子產品上,都可以見到 ARM 晶元的身影。
而 ARM 則脫離 Acorn 成為了一種特殊的商業模式,他們不生產實物晶元,僅僅是向晶元生產廠商出售相關的知識產權。
因此,這或多或少是 ARM 晶元被應用於如此之多的手機和平板電腦上的原因。當 Linux 被移植到這種架構的晶元上時,開源技術的大門就已經向它打開了,這才讓我們今天得以在這些晶元上運行 web 爬蟲程序。
伺服器端的 ARM
諸如微軟和 Cloudflare 這些大廠都在基礎設施建設上花了重金,所以對於我們這些預算不高的用戶來說,可以選擇的餘地並不多。
實際上,如果你的信用卡只夠付每月數美元的 VPS 費用,一直以來只能考慮 Scaleway 這個高性價比的廠商。
但自從數個月前公有雲巨頭 AWS 推出了他們自研的 ARM 處理器 AWS Graviton 之後,選擇似乎就豐富了一些。
我決定在其中選擇一款 VPS 廠商,將它提供的 ARM 處理器和 x86 處理器作出對比。
深入了解
所以我們要對比的是什麼指標呢?
Scaleway
Scaleway 自身的定位是「專為開發者設計」。我覺得這個定位很準確,對於開發和原型設計來說,Scaleway 提供的產品確實可以作為一個很好的沙盒環境。
Scaleway 提供了一個簡潔的儀錶盤頁面,讓用戶可以快速地從主頁進入 bash shell 界面。對於很多小企業、自由職業者或者技術顧問,如果想要運行 web 爬蟲,這個產品毫無疑問是一個物美價廉的選擇。
ARM 方面我們選擇 ARM64-2GB 這一款伺服器,每月只需要 3 歐元。它帶有 4 個 Cavium ThunderX 核心,這是在 2014 年推出的第一款伺服器級的 ARMv8 處理器。但現在看來它已經顯得有點落後了,並逐漸被更新的 ThunderX2 取代。
x86 方面我們選擇 1-S,每月的費用是 4 歐元。它擁有 2 個英特爾 Atom C3995 核心。英特爾的 Atom 系列處理器的特點是低功耗、單線程,最初是用在筆記本電腦上的,後來也被伺服器所採用。
兩者在處理器以外的條件都大致相同,都使用 2 GB 的內存、50 GB 的 SSD 存儲以及 200 Mbit/s 的帶寬。磁碟驅動器可能會有所不同,但由於我們運行的是 web 爬蟲,基本都是在內存中完成操作,因此這方面的差異可以忽略不計。
為了避免我不能熟練使用包管理器的尷尬局面,兩方的操作系統我都會選擇使用 Debian 9。
Amazon Web Services(AWS)
當你還在註冊 AWS 賬號的時候,使用 Scaleway 的用戶可能已經把提交信用卡信息、啟動 VPS 實例、添加 sudo 用戶、安裝依賴包這一系列流程都完成了。AWS 的操作相對來說比較繁瑣,甚至需要詳細閱讀手冊才能知道你正在做什麼。
當然這也是合理的,對於一些需求複雜或者特殊的企業用戶,確實需要通過詳細的配置來定製合適的使用方案。
我們所採用的 AWS Graviton 處理器是 AWS EC2( 彈性計算雲 )的一部分,我會以按需實例的方式來運行,這也是最貴但最簡捷的方式。AWS 同時也提供競價實例,這樣可以用較低的價格運行實例,但實例的運行時間並不固定。如果實例需要長時間持續運行,還可以選擇預留實例。
看,AWS 就是這麼複雜……
我們分別選擇 a1.medium 和 t2.small 兩種型號的實例進行對比,兩者都帶有 2GB 內存。這個時候問題來了,這裡提到的 vCPU 又是什麼?兩種型號的不同之處就在於此。
對於 a1.medium 型號的實例,vCPU 是 AWS Graviton 晶元提供的單個計算核心。這個晶元由被亞馬遜在 2015 收購的以色列廠商 Annapurna Labs 研發,是 AWS 獨有的單線程 64 位 ARMv8 內核。它的按需價格為每小時 0.0255 美元。
而 t2.small 型號實例使用英特爾至強系列晶元,但我不確定具體是其中的哪一款。它每個核心有兩個線程,但我們並不能用到整個核心,甚至整個線程。
我們能用到的只是「20% 的基準性能,可以使用 CPU 積分突破這個基準」。這可能有一定的原因,但我沒有弄懂。它的按需價格是每小時 0.023 美元。
在鏡像庫中沒有 Debian 發行版的鏡像,因此我選擇了 Ubuntu 18.04。
癟四與大頭蛋爬取 Moz 排行榜前 500 的網站
要測試這些 VPS 的 CPU 性能,就該使用爬蟲了。一個方法是對幾個網站在儘可能短的時間裡發出儘可能多的請求,但這種操作不太禮貌,我的做法是只向大量網站發出少數幾個請求。
為此,我編寫了 beavis.py(癟四)這個爬蟲程序(致敬我最喜歡的物理學家和製片人 Mike Judge)。這個程序會將 Moz 上排行前 500 的網站都爬取 3 層的深度,並計算 「wood」 和 「ass」 這兩個單詞在 HTML 文件中出現的次數。(LCTT 譯註:beavis(癟四)和 butt-head(大頭蛋) 都是 Mike Judge 的動畫片《癟四與大頭蛋》中的角色)
但我實際爬取的網站可能不足 500 個,因為我需要遵循網站的 robot.txt 協定,另外還有些網站需要提交 javascript 請求,也不一定會計算在內。但這已經是一個足以讓 CPU 保持繁忙的爬蟲任務了。
Python 的全局解釋器鎖機制會讓我的程序只能用到一個 CPU 線程。為了測試多線程的性能,我需要啟動多個獨立的爬蟲程序進程。
因此我還編寫了 butthead.py,儘管大頭蛋很粗魯,它也總是比癟四要略勝一籌。
我將整個爬蟲任務拆分為多個部分,這可能會對爬取到的鏈接數量有一點輕微的影響。但無論如何,每次爬取都會有所不同,我們要關注的是爬取了多少個頁面,以及耗時多長。
在 ARM 伺服器上安裝 Scrapy
安裝 Scrapy 的過程與晶元的不同架構沒有太大的關係,都是安裝 pip 和相關的依賴包之後,再使用 pip 來安裝 Scrapy。
據我觀察,在使用 ARM 的機器上使用 pip 安裝 Scrapy 確實耗時要長一點,我估計是由於需要從源碼編譯為二進位文件。
在 Scrapy 安裝結束後,就可以通過 shell 來查看它的工作狀態了。
在 Scaleway 的 ARM 機器上,Scrapy 安裝完成後會無法正常運行,這似乎和 service_identity 模塊有關。這個現象也會在樹莓派上出現,但在 AWS Graviton 上不會出現。
對於這個問題,可以用這個命令來解決:
sudo pip3 install service_identity --force --upgrade接下來就可以開始對比了。
單線程爬蟲
Scrapy 的官方文檔建議將爬蟲程序的 CPU 使用率控制在 80% 到 90% 之間,在真實操作中並不容易,尤其是對於我自己寫的代碼。根據我的觀察,實際的 CPU 使用率變動情況是一開始非常繁忙,隨後稍微下降,接著又再次升高。
在爬取任務的最後,也就是大部分目標網站都已經被爬取了的這個階段,會持續數分鐘的時間。這讓人有點失望,因為在這個階段當中,任務的運行時長只和網站的大小有比較直接的關係,並不能以之衡量 CPU 的性能。
所以這並不是一次嚴謹的基準測試,只是我通過自己寫的爬蟲程序來觀察實際的現象。
下面我們來看看最終的結果。首先是 Scaleway 的機器:
| 機器種類 | 耗時 | 爬取頁面數 | 每小時爬取頁面數 | 每百萬頁面費用(歐元) |
|---|---|---|---|---|
| Scaleway ARM64-2GB | 108m 59.27s | 38,205 | 21,032.623 | 0.28527 |
| Scaleway 1-S | 97m 44.067s | 39,476 | 24,324.648 | 0.33011 |
我使用了 top 工具來查看爬蟲程序運行期間的 CPU 使用率。在任務剛開始的時候,兩者的 CPU 使用率都達到了 100%,但 ThunderX 大部分時間都達到了 CPU 的極限,無法看出來 Atom 的性能會比 ThunderX 超出多少。
通過 top 工具,我還觀察了它們的內存使用情況。隨著爬取任務的進行,ARM 機器的內存使用率最終達到了 14.7%,而 x86 則最終是 15%。
從運行日誌還可以看出來,當 CPU 使用率到達極限時,會有大量的超時頁面產生,最終導致頁面丟失。這也是合理出現的現象,因為 CPU 過於繁忙會無法完整地記錄所有爬取到的頁面。
如果僅僅是為了對比爬蟲的速度,頁面丟失並不是什麼大問題。但在實際中,業務成果和爬蟲數據的質量是息息相關的,因此必須為 CPU 留出一些用量,以防出現這種現象。
再來看看 AWS 這邊:
| 機器種類 | 耗時 | 爬取頁面數 | 每小時爬取頁面數 | 每百萬頁面費用(美元) |
|---|---|---|---|---|
| a1.medium | 100m 39.900s | 41,294 | 24,612.725 | 1.03605 |
| t2.small | 78m 53.171s | 41,200 | 31,336.286 | 0.73397 |
為了方便比較,對於在 AWS 上跑的爬蟲,我記錄的指標和 Scaleway 上一致,但似乎沒有達到預期的效果。這裡我沒有使用 top,而是使用了 AWS 提供的控制台來監控 CPU 的使用情況,從監控結果來看,我的爬蟲程序並沒有完全用到這兩款伺服器所提供的所有性能。
a1.medium 型號的機器尤為如此,在任務開始階段,它的 CPU 使用率達到了峰值 45%,但隨後一直在 20% 到 30% 之間。
讓我有點感到意外的是,這個程序在 ARM 處理器上的運行速度相當慢,但卻遠未達到 Graviton CPU 能力的極限,而在 Intel Atom 處理器上則可以在某些時候達到 CPU 能力的極限。它們運行的代碼是完全相同的,處理器的不同架構可能導致了對代碼的不同處理方式。
箇中原因無論是由於處理器本身的特性,還是二進位文件的編譯,又或者是兩者皆有,對我來說都是一個黑盒般的存在。我認為,既然在 AWS 機器上沒有達到 CPU 處理能力的極限,那麼只有在 Scaleway 機器上跑出來的性能數據是可以作為參考的。
t2.small 型號的機器性能讓人費解。CPU 利用率大概 20%,最高才達到 35%,是因為手冊中說的「20% 的基準性能,可以使用 CPU 積分突破這個基準」嗎?但在控制台中可以看到 CPU 積分並沒有被消耗。
為了確認這一點,我安裝了 stress 這個軟體,然後運行了一段時間,這個時候發現居然可以把 CPU 使用率提高到 100% 了。
顯然,我需要調整一下它們的配置文件。我將 CONCURRENT_REQUESTS 參數設置為 5000,將 REACTOR_THREADPOOL_MAXSIZE 參數設置為 120,將爬蟲任務的負載調得更大。
| 機器種類 | 耗時 | 爬取頁面數 | 每小時爬取頁面數 | 每萬頁面費用(美元) |
|---|---|---|---|---|
| a1.medium | 46m 13.619s | 40,283 | 52,285.047 | 0.48771 |
| t2.small | 41m7.619s | 36,241 | 52,871.857 | 0.43501 |
| t2.small(無 CPU 積分) | 73m 8.133s | 34,298 | 28,137.8891 | 0.81740 |
a1.medium 型號機器的 CPU 使用率在爬蟲任務開始後 5 分鐘飆升到了 100%,隨後下降到 80% 並持續了 20 分鐘,然後再次攀升到 96%,直到任務接近結束時再次下降。這大概就是我想要的效果了。
而 t2.small 型號機器在爬蟲任務的前期就達到了 50%,並一直保持在這個水平直到任務接近結束。如果每個核心都有兩個線程,那麼 50% 的 CPU 使用率確實是單個線程可以達到的極限了。
現在我們看到它們的性能都差不多了。但至強處理器的線程持續跑滿了 CPU,Graviton 處理器則只是有一段時間如此。可以認為 Graviton 略勝一籌。
然而,如果 CPU 積分耗盡了呢?這種情況下的對比可能更為公平。為了測試這種情況,我使用 stress 把所有的 CPU 積分用完,然後再次啟動了爬蟲任務。
在沒有 CPU 積分的情況下,CPU 使用率在 27% 就到達極限不再上升了,同時又出現了丟失頁面的現象。這麼看來,它的性能比負載較低的時候更差。
多線程爬蟲
將爬蟲任務分散到不同的進程中,可以有效利用機器所提供的多個核心。
一開始,我將爬蟲任務分布在 10 個不同的進程中並同時啟動,結果發現比每個核心僅使用 1 個進程的時候還要慢。
經過嘗試,我得到了一個比較好的方案。把爬蟲任務分布在 10 個進程中,但每個核心只啟動 1 個進程,在每個進程接近結束的時候,再從剩餘的進程中選出 1 個進程啟動起來。
如果還需要優化,還可以讓運行時間越長的爬蟲進程在啟動順序中排得越靠前,我也在嘗試實現這個方法。
想要預估某個域名的頁面量,一定程度上可以參考這個域名主頁的鏈接數量。我用另一個程序來對這個數量進行了統計,然後按照降序排序。經過這樣的預處理之後,只會額外增加 1 分鐘左右的時間。
結果,爬蟲運行的總耗時超過了兩個小時!畢竟把鏈接最多的域名都堆在同一個進程中也存在一定的弊端。
針對這個問題,也可以通過調整各個進程爬取的域名數量來進行優化,又或者在排序之後再作一定的修改。不過這種優化可能有點複雜了。
因此,我還是用回了最初的方法,它的效果還是相當不錯的:
| 機器種類 | 耗時 | 爬取頁面數 | 每小時爬取頁面數 | 每萬頁面費用(歐元) |
|---|---|---|---|---|
| Scaleway ARM64-2GB | 62m 10.078s | 36,158 | 34,897.0719 | 0.17193 |
| Scaleway 1-S | 60m 56.902s | 36,725 | 36,153.5529 | 0.22128 |
畢竟,使用多個核心能夠大大加快爬蟲的速度。
我認為,如果讓一個經驗豐富的程序員來優化的話,一定能夠更好地利用所有的計算核心。但對於開箱即用的 Scrapy 來說,想要提高性能,使用更快的線程似乎比使用更多核心要簡單得多。
從數量來看,Atom 處理器在更短的時間內爬取到了更多的頁面。但如果從性價比角度來看,ThunderX 又是稍稍領先的。不過總的來說差距不大。
爬取結果分析
在爬取了 38205 個頁面之後,我們可以統計到在這些頁面中 「ass」 出現了 24170435 次,而 「wood」 出現了 54368 次。
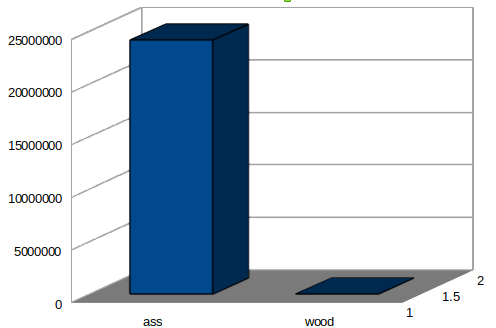
「wood」 的出現次數不少,但和 「ass」 比起來簡直微不足道。
結論
從上面的數據來看,對於性能而言,CPU 的架構並沒有它們的問世時間重要,2018 年生產的 AWS Graviton 是單線程情況下性能最佳的。
你當然可以說按核心來比,Xeon 仍然贏了。但是,你不但需要計算美元的變化,甚至還要計算線程數。
另外在性能方面 2017 年生產的 Atom 輕鬆擊敗了 2014 年生產的 ThunderX,而 ThunderX 則在性價比方面佔優。當然,如果你使用 AWS 的機器的話,還是使用 Graviton 吧。
總之,ARM 架構的硬體是可以用來運行爬蟲程序的,而且在性能和費用方面也相當有競爭力。
而這種差異是否足以讓你將整個技術架構遷移到 ARM 上?這就是另一回事了。當然,如果你已經是 AWS 用戶,並且你的代碼有很強的可移植性,那麼不妨嘗試一下 a1 型號的實例。
希望 ARM 設備在不久的將來能夠在公有雲上大放異彩。
源代碼
這是我第一次使用 Python 和 Scrapy 來做一個項目,所以我的代碼寫得可能不是很好,例如代碼中使用全局變數就有點力不從心。
不過我仍然會在下面開源我的代碼。
要運行這些代碼,需要預先安裝 Scrapy,並且需要 Moz 上排名前 500 的網站的 csv 文件。如果要運行 butthead.py,還需要安裝 psutil 這個庫。
import scrapy
from scrapy.spiders import CrawlSpider, Rule
from scrapy.linkextractors import LinkExtractor
from scrapy.crawler import CrawlerProcess
ass = 0
wood = 0
totalpages = 0
def getdomains():
moz500file = open('top500.domains.05.18.csv')
domains = []
moz500csv = moz500file.readlines()
del moz500csv[0]
for csvline in moz500csv:
leftquote = csvline.find('"')
rightquote = leftquote + csvline[leftquote + 1:].find('"')
domains.append(csvline[leftquote + 1:rightquote])
return domains
def getstartpages(domains):
startpages = []
for domain in domains:
startpages.append('http://' + domain)
return startpages
class AssWoodItem(scrapy.Item):
ass = scrapy.Field()
wood = scrapy.Field()
url = scrapy.Field()
class AssWoodPipeline(object):
def __init__(self):
self.asswoodstats = []
def process_item(self, item, spider):
self.asswoodstats.append((item.get('url'), item.get('ass'), item.get('wood')))
def close_spider(self, spider):
asstally, woodtally = 0, 0
for asswoodcount in self.asswoodstats:
asstally += asswoodcount[1]
woodtally += asswoodcount[2]
global ass, wood, totalpages
ass = asstally
wood = woodtally
totalpages = len(self.asswoodstats)
class BeavisSpider(CrawlSpider):
name = "Beavis"
allowed_domains = getdomains()
start_urls = getstartpages(allowed_domains)
#start_urls = [ 'http://medium.com' ]
custom_settings = {
'DEPTH_LIMIT': 3,
'DOWNLOAD_DELAY': 3,
'CONCURRENT_REQUESTS': 1500,
'REACTOR_THREADPOOL_MAXSIZE': 60,
'ITEM_PIPELINES': { '__main__.AssWoodPipeline': 10 },
'LOG_LEVEL': 'INFO',
'RETRY_ENABLED': False,
'DOWNLOAD_TIMEOUT': 30,
'COOKIES_ENABLED': False,
'AJAXCRAWL_ENABLED': True
}
rules = ( Rule(LinkExtractor(), callback='parse_asswood'), )
def parse_asswood(self, response):
if isinstance(response, scrapy.http.TextResponse):
item = AssWoodItem()
item['ass'] = response.text.casefold().count('ass')
item['wood'] = response.text.casefold().count('wood')
item['url'] = response.url
yield item
if __name__ == '__main__':
process = CrawlerProcess({
'USER_AGENT': 'Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1)'
})
process.crawl(BeavisSpider)
process.start()
print('Uhh, that was, like, ' + str(totalpages) + ' pages crawled.')
print('Uh huhuhuhuh. It said ass ' + str(ass) + ' times.')
print('Uh huhuhuhuh. It said wood ' + str(wood) + ' times.')beavis.py
import scrapy, time, psutil
from scrapy.spiders import CrawlSpider, Rule, Spider
from scrapy.linkextractors import LinkExtractor
from scrapy.crawler import CrawlerProcess
from multiprocessing import Process, Queue, cpu_count
ass = 0
wood = 0
totalpages = 0
linkcounttuples =[]
def getdomains():
moz500file = open('top500.domains.05.18.csv')
domains = []
moz500csv = moz500file.readlines()
del moz500csv[0]
for csvline in moz500csv:
leftquote = csvline.find('"')
rightquote = leftquote + csvline[leftquote + 1:].find('"')
domains.append(csvline[leftquote + 1:rightquote])
return domains
def getstartpages(domains):
startpages = []
for domain in domains:
startpages.append('http://' + domain)
return startpages
class AssWoodItem(scrapy.Item):
ass = scrapy.Field()
wood = scrapy.Field()
url = scrapy.Field()
class AssWoodPipeline(object):
def __init__(self):
self.asswoodstats = []
def process_item(self, item, spider):
self.asswoodstats.append((item.get('url'), item.get('ass'), item.get('wood')))
def close_spider(self, spider):
asstally, woodtally = 0, 0
for asswoodcount in self.asswoodstats:
asstally += asswoodcount[1]
woodtally += asswoodcount[2]
global ass, wood, totalpages
ass = asstally
wood = woodtally
totalpages = len(self.asswoodstats)
class ButtheadSpider(CrawlSpider):
name = "Butthead"
custom_settings = {
'DEPTH_LIMIT': 3,
'DOWNLOAD_DELAY': 3,
'CONCURRENT_REQUESTS': 250,
'REACTOR_THREADPOOL_MAXSIZE': 30,
'ITEM_PIPELINES': { '__main__.AssWoodPipeline': 10 },
'LOG_LEVEL': 'INFO',
'RETRY_ENABLED': False,
'DOWNLOAD_TIMEOUT': 30,
'COOKIES_ENABLED': False,
'AJAXCRAWL_ENABLED': True
}
rules = ( Rule(LinkExtractor(), callback='parse_asswood'), )
def parse_asswood(self, response):
if isinstance(response, scrapy.http.TextResponse):
item = AssWoodItem()
item['ass'] = response.text.casefold().count('ass')
item['wood'] = response.text.casefold().count('wood')
item['url'] = response.url
yield item
def startButthead(domainslist, urlslist, asswoodqueue):
crawlprocess = CrawlerProcess({
'USER_AGENT': 'Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1)'
})
crawlprocess.crawl(ButtheadSpider, allowed_domains = domainslist, start_urls = urlslist)
crawlprocess.start()
asswoodqueue.put( (ass, wood, totalpages) )
if __name__ == '__main__':
asswoodqueue = Queue()
domains=getdomains()
startpages=getstartpages(domains)
processlist =[]
cores = cpu_count()
for i in range(10):
domainsublist = domains[i * 50:(i + 1) * 50]
pagesublist = startpages[i * 50:(i + 1) * 50]
p = Process(target = startButthead, args = (domainsublist, pagesublist, asswoodqueue))
processlist.append(p)
for i in range(cores):
processlist[i].start()
time.sleep(180)
i = cores
while i != 10:
time.sleep(60)
if psutil.cpu_percent() < 66.7:
processlist[i].start()
i += 1
for i in range(10):
processlist[i].join()
for i in range(10):
asswoodtuple = asswoodqueue.get()
ass += asswoodtuple[0]
wood += asswoodtuple[1]
totalpages += asswoodtuple[2]
print('Uhh, that was, like, ' + str(totalpages) + ' pages crawled.')
print('Uh huhuhuhuh. It said ass ' + str(ass) + ' times.')
print('Uh huhuhuhuh. It said wood ' + str(wood) + ' times.')
butthead.py
via: https://blog.dxmtechsupport.com.au/speed-test-x86-vs-arm-for-web-crawling-in-python/
作者:James Mawson 選題:lujun9972 譯者:HankChow 校對:wxy
本文轉載來自 Linux 中國: https://github.com/Linux-CN/archive
對這篇文章感覺如何?
You may also like






More in:Linux中國

捐贈 Let's Encrypt,共建安全的互聯網

Let's Encrypt 正式發布,已經保護 380 萬個域名

關於Linux防火牆iptables的面試問答

Lets Encrypt 已被所有主流瀏覽器所信任









