PyCaret:機器學習模型開發變得簡單

PyCaret 是 R 編程語言中 Caret( 分類和回歸訓練 的縮寫)包的 Python 版本,具有許多優點。
- 提高工作效率: PyCaret 是一個低代碼庫,可讓你提高工作效率。由於花費更少的時間進行編碼,你和你的團隊現在可以專註於業務問題。
- 易於使用: 這個簡單易用的機器學習庫將幫助你以更少的代碼行執行端到端的機器學習實驗。
- 可用於商業: PyCaret 是一個可用於商業的解決方案。它允許你從選擇的 notebook 環境中快速有效地進行原型設計。
你可以在 Python 中創建一個虛擬環境並執行以下命令來安裝 PyCaret 完整版:
pip install pycaret [full]
機器學習從業者可以使用 PyCaret 進行分類、回歸、聚類、異常檢測、自然語言處理、關聯規則挖掘和時間序列分析。
使用 PyCaret 構建分類模型
本文通過從 PyCaret 的數據倉庫中獲取 Iris 數據集來解釋使用 PyCaret 構建分類模型。
我們將使用 Google Colab 環境使事情變得簡單,並按照下面提到的步驟進行操作。
步驟 1
首先,通過給出以下命令安裝 PyCaret:
pip install pycaret
步驟 2
接下來,載入數據集,如圖 2 所示:
from pycaret.datasets import get_data
dataset = get_data('iris')
(或者)
import pandas as pd
dataset = pd.read_csv('/path_to_data/file.csv')
步驟 3
現在設置 PyCaret 環境,如圖 2 所示:
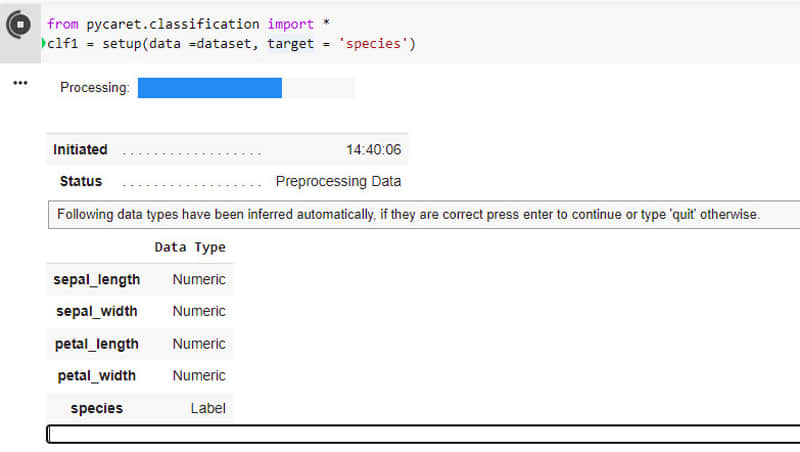
from pycaret.classification import *
clf1 = setup(data=dataset, target = 『species』)
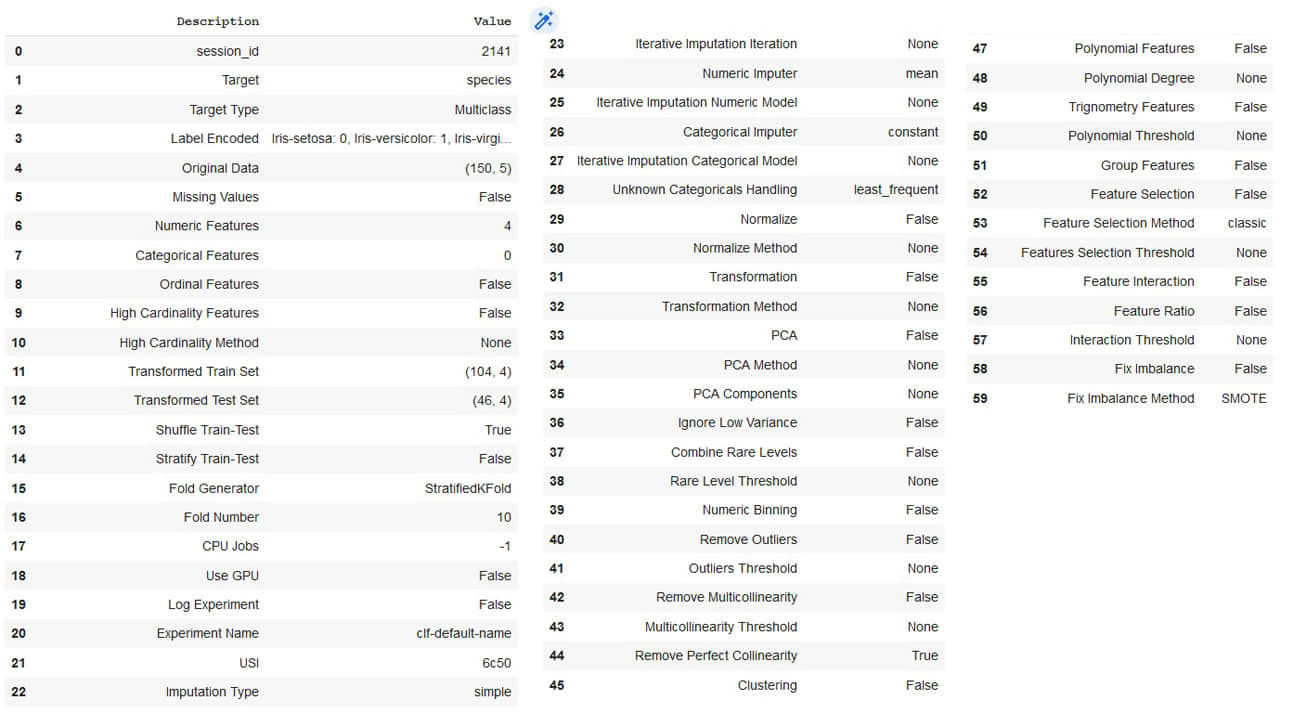
使用 PyCaret 構建任何類型的模型,環境設置是最重要的一步。默認情況下,setup() 函數接受參數 data(Pandas 數據幀)和 target(指向數據集中的類標籤變數)。setup() 函數的結果如圖 3 所示。 setup() 函數默認將 70% 的數據拆分為訓練集,30% 作為測試集,並進行數據預處理,如圖 3 所示。
步驟 4
接下來,找到最佳模型,如圖 4 所示:
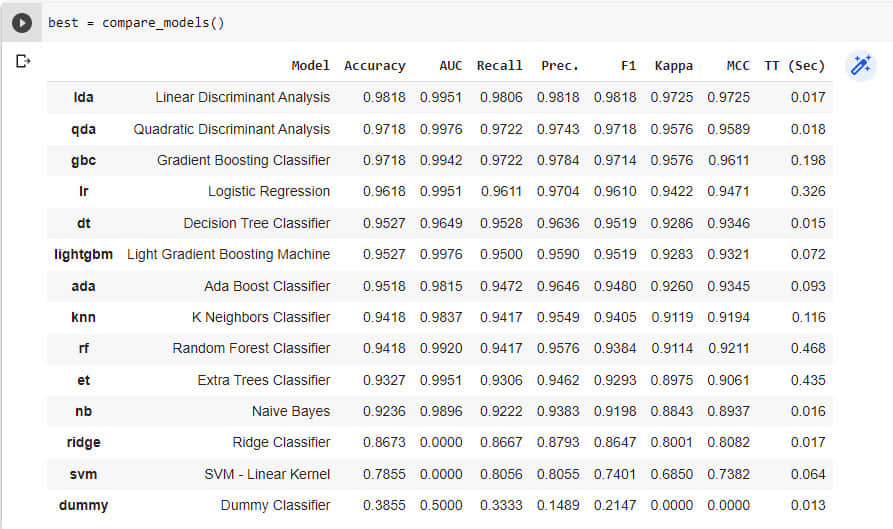
best = compare_models()
默認情況下,compare_models() 應用十倍交叉驗證,並針對具有較少訓練時間的不同分類器計算不同的性能指標,如準確度、AUC、召回率、精度、F1 分數、Kappa 和 MCC,如圖 4 所示。通過將 tubro=True 傳遞給 compare_models() 函數,我們可以嘗試所有分類器。
步驟 5
現在創建模型,如圖 5 所示:
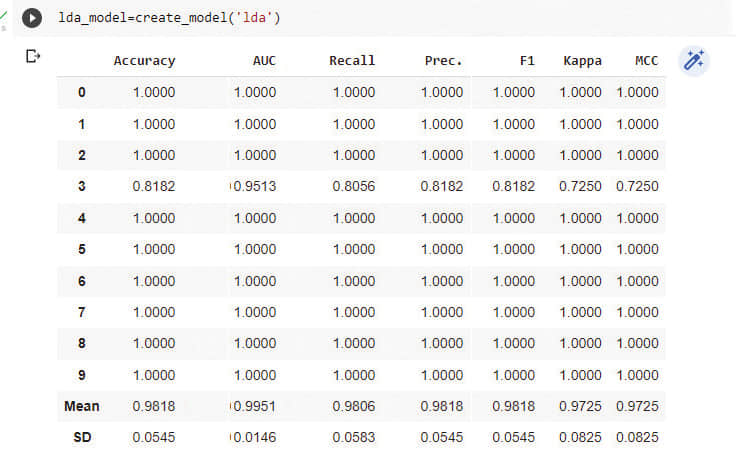
lda_model=create_model (『lda』)
線性判別分析分類器表現良好,如圖 4 所示。因此,通過將 lda 傳遞給 create_model() 函數,我們可以擬合模型。
步驟 6
下一步是微調模型,如圖 6 所示。
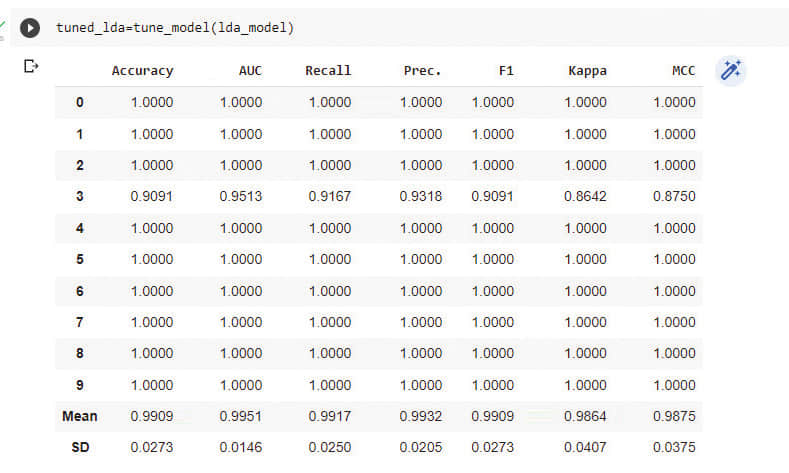
tuned_lda=tune_model(lda_model)
超參數的調整可以提高模型的準確性。tune_model() 函數將線性判別分析模型的精度從 0.9818 提高到 0.9909,如圖 7 所示。

步驟 7
下一步是進行預測,如圖 8 所示:

predictions=predict_model(tuned_lda)
predict_model() 函數用於對測試數據中存在的樣本進行預測。
步驟 8
現在繪製模型性能,如圖 9 所示:
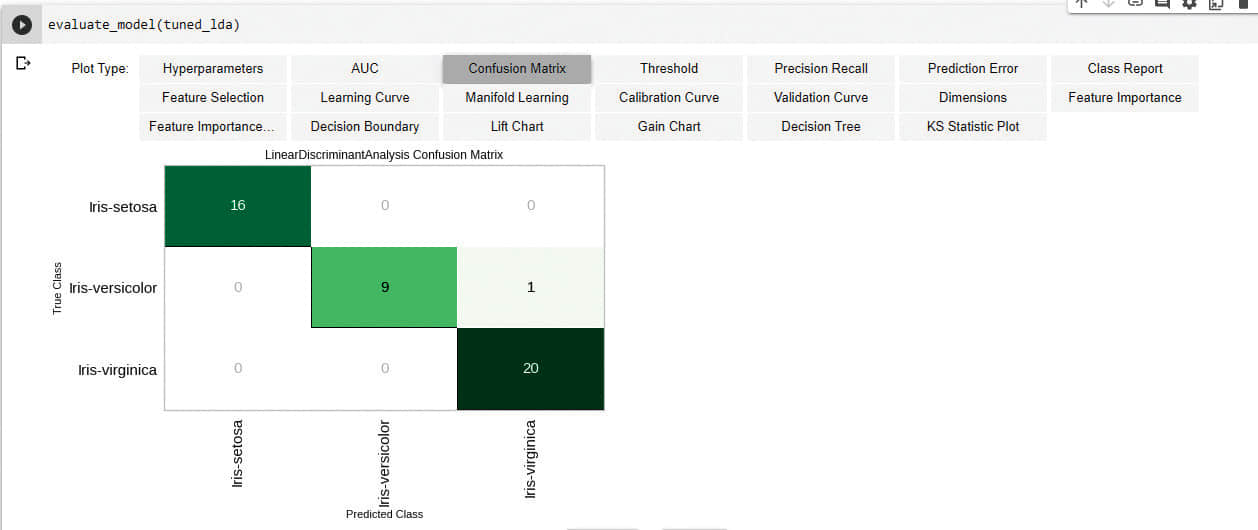
evaluate_model(tuned_lda)
evaluate_model() 函數用於以最小的努力開發不同的性能指標。你可以嘗試它們並查看輸出。
via: https://www.opensourceforu.com/2022/05/pycaret-machine-learning-model-development-made-easy/
作者:S Ratan Kumar 選題:lkxed 譯者:geekpi 校對:wxy
本文轉載來自 Linux 中國: https://github.com/Linux-CN/archive
對這篇文章感覺如何?
You may also like






More in:Linux中國

捐贈 Let's Encrypt,共建安全的互聯網

Let's Encrypt 正式發布,已經保護 380 萬個域名

關於Linux防火牆iptables的面試問答

Lets Encrypt 已被所有主流瀏覽器所信任









