關於 BPF 和 eBPF 的筆記
今天,我喜歡的 meetup 網站上有一篇我超愛的文章!Suchakra Sharma(@tuxology 在 twitter/github)的一篇非常棒的關於傳統 BPF 和在 Linux 中最新加入的 eBPF 的討論文章,正是它促使我想去寫一個 eBPF 的程序!
這篇文章就是 —— BSD 包過濾器:一個新的用戶級包捕獲架構
我想在討論的基礎上去寫一些筆記,因為,我覺得它超級棒!
開始前,這裡有個 幻燈片 和一個 pdf。這個 pdf 非常好,結束的位置有一些鏈接,在 PDF 中你可以直接點擊這個鏈接。
什麼是 BPF?
在 BPF 出現之前,如果你想去做包過濾,你必須拷貝所有的包到用戶空間,然後才能去過濾它們(使用 「tap」)。
這樣做存在兩個問題:
- 如果你在用戶空間中過濾,意味著你將拷貝所有的包到用戶空間,拷貝數據的代價是很昂貴的。
- 使用的過濾演算法很低效。
問題 #1 的解決方法似乎很明顯,就是將過濾邏輯移到內核中。(雖然具體實現的細節並沒有明確,我們將在稍後討論)
但是,為什麼過濾演算法會很低效?
如果你運行 tcpdump host foo,它實際上運行了一個相當複雜的查詢,用下圖的這個樹來描述它:
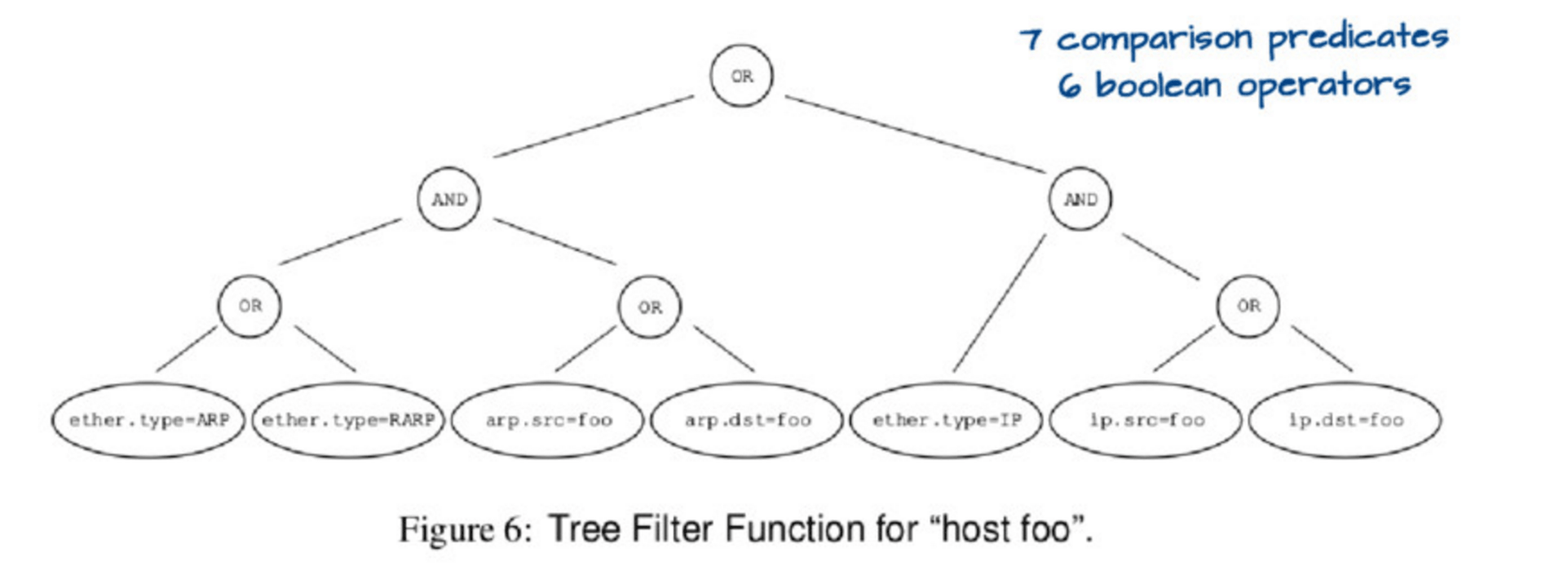
評估這個樹有點複雜。因此,可以用一種更簡單的方式來表示這個樹,像這樣:

然後,如果你設置 ether.type = IP 和 ip.src = foo,你必然明白匹配的包是 host foo,你也不用去檢查任何其它的東西了。因此,這個數據結構(它們稱為「控制流圖」 ,或者 「CFG」)是表示你真實希望去執行匹配檢查的程序的最佳方法,而不是用前面的樹。
為什麼 BPF 要工作在內核中
這裡的關鍵點是,包僅僅是個位元組的數組。BPF 程序是運行在這些位元組的數組之上。它們不允許有循環(loop),但是,它們 可以 有聰明的辦法知道 IP 包頭(IPv6 和 IPv4 長度是不同的)以及基於它們的長度來找到 TCP 埠:
x = ip_header_length
port = *(packet_start + x + port_offset)
(看起來不一樣,其實它們基本上都相同)。在這個論文/幻燈片上有一個非常詳細的虛擬機的描述,因此,我不打算解釋它。
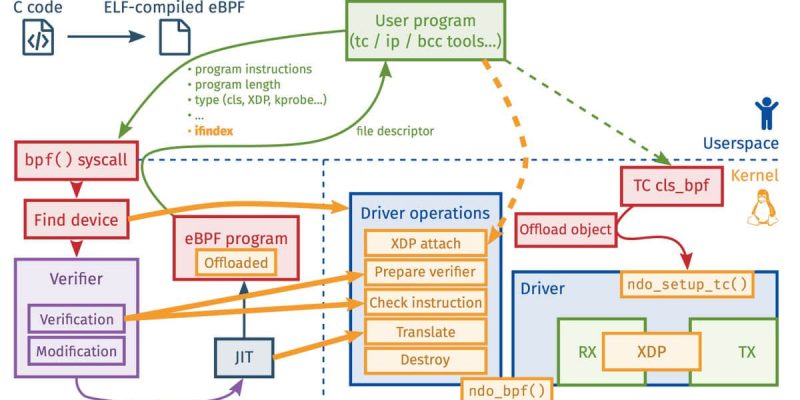
當你運行 tcpdump host foo 後,這時發生了什麼?就我的理解,應該是如下的過程。
- 轉換
host foo為一個高效的 DAG 規則 - 轉換那個 DAG 規則為 BPF 虛擬機的一個 BPF 程序(BPF 位元組碼)
- 發送 BPF 位元組碼到 Linux 內核,由 Linux 內核驗證它
- 編譯這個 BPF 位元組碼程序為一個 原生 代碼。例如,這是個ARM 上的 JIT 代碼 以及 x86 的機器碼
- 當包進入時,Linux 運行原生代碼去決定是否過濾這個包。對於每個需要去處理的包,它通常僅需運行 100 - 200 個 CPU 指令就可以完成,這個速度是非常快的!
現狀:eBPF
畢竟 BPF 出現已經有很長的時間了!現在,我們可以擁有一個更加令人激動的東西,它就是 eBPF。我以前聽說過 eBPF,但是,我覺得像這樣把這些片斷拼在一起更好(我在 4 月份的 netdev 上我寫了這篇 XDP & eBPF 的文章回復)
關於 eBPF 的一些事實是:
- eBPF 程序有它們自己的位元組碼語言,並且從那個位元組碼語言編譯成內核原生代碼,就像 BPF 程序一樣
- eBPF 運行在內核中
- eBPF 程序不能隨心所欲的訪問內核內存。而是通過內核提供的函數去取得一些受嚴格限制的所需要的內容的子集
- 它們 可以 與用戶空間的程序通過 BPF 映射進行通訊
- 這是 Linux 3.18 的
bpf系統調用
kprobes 和 eBPF
你可以在 Linux 內核中挑選一個函數(任意函數),然後運行一個你寫的每次該函數被調用時都運行的程序。這樣看起來是不是很神奇。
例如:這裡有一個 名為 disksnoop 的 BPF 程序,它的功能是當你開始/完成寫入一個塊到磁碟時,觸發它執行跟蹤。下圖是它的代碼片斷:
BPF_HASH(start, struct request *);
void trace_start(struct pt_regs *ctx, struct request *req) {
// stash start timestamp by request ptr
u64 ts = bpf_ktime_get_ns();
start.update(&req, &ts);
}
...
b.attach_kprobe(event="blk_start_request", fn_name="trace_start")
b.attach_kprobe(event="blk_mq_start_request", fn_name="trace_start")
本質上它聲明一個 BPF 哈希(它的作用是當請求開始/完成時,這個程序去觸發跟蹤),一個名為 trace_start 的函數將被編譯進 BPF 位元組碼,然後附加 trace_start 到內核函數 blk_start_request 上。
這裡使用的是 bcc 框架,它可以讓你寫 Python 式的程序去生成 BPF 代碼。你可以在 https://github.com/iovisor/bcc 找到它(那裡有非常多的示常式序)。
uprobes 和 eBPF
因為我知道可以附加 eBPF 程序到內核函數上,但是,我不知道能否將 eBPF 程序附加到用戶空間函數上!那會有更多令人激動的事情。這是 在 Python 中使用一個 eBPF 程序去計數 malloc 調用的示例。
附加 eBPF 程序時應該考慮的事情
- 帶 XDP 的網卡(我之前寫過關於這方面的文章)
- tc egress/ingress (在網路棧上)
- kprobes(任意內核函數)
- uprobes(很明顯,任意用戶空間函數??像帶調試符號的任意 C 程序)
- probes 是為 dtrace 構建的名為 「USDT probes」 的探針(像 這些 mysql 探針)。這是一個 使用 dtrace 探針的示常式序
- JVM
- 跟蹤點
- seccomp / landlock 安全相關的事情
- 等等
這個討論超級棒
在幻燈片里有很多非常好的鏈接,並且在 iovisor 倉庫里有個 LINKS.md。雖然現在已經很晚了,但是我馬上要去寫我的第一個 eBPF 程序了!
via: https://jvns.ca/blog/2017/06/28/notes-on-bpf---ebpf/
作者:Julia Evans 譯者:qhwdw 校對:wxy
本文轉載來自 Linux 中國: https://github.com/Linux-CN/archive
對這篇文章感覺如何?
You may also like






More in:Linux中國

捐贈 Let's Encrypt,共建安全的互聯網

Let's Encrypt 正式發布,已經保護 380 萬個域名

關於Linux防火牆iptables的面試問答

Lets Encrypt 已被所有主流瀏覽器所信任









