使用 Elasticsearch 和 cAdvisor 監控 Docker 容器
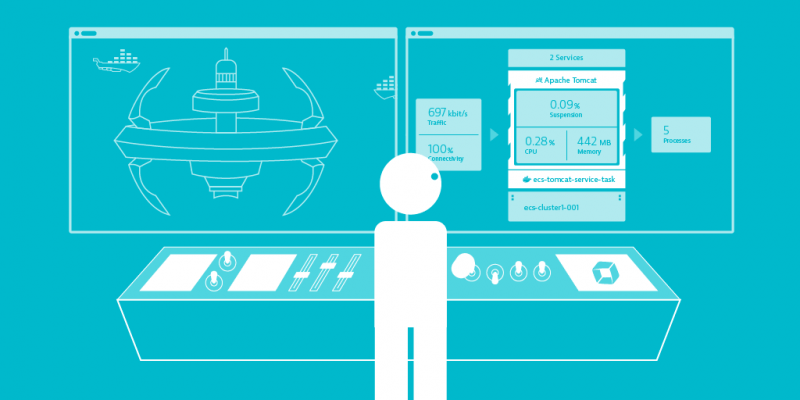
你需要監控下面的參數:
- 容器的數量和狀態。
- 一台容器是否已經移到另一個節點了,如果是,那是在什麼時候,移動到哪個節點?
- 給定節點上運行著的容器數量。
- 一段時間內的通信峰值。
- 孤兒卷和網路(LCTT 譯註:孤兒卷就是當你刪除容器時忘記刪除它的卷,這個卷就不會再被使用,但會一直佔用資源)。
- 可用磁碟空間、可用 inode 數。
- 容器數量與連接在
docker0和docker_gwbridge上的虛擬網卡數量不一致(LCTT 譯註:當 docker 啟動時,它會在宿主機器上創建一個名為 docker0 的虛擬網路介面)。 - 開啟和關閉 Swarm 節點。
- 收集並集中處理日誌。
本文的目標是介紹 Elasticsearch + Kibana + cAdvisor 的用法,使用它們來收集 Docker 容器的參數,分析數據併產生可視化報表。
閱讀本文後你可以發現有一個監控儀錶盤能夠部分解決上述列出的問題。但如果只是使用 cAdvisor,有些參數就無法顯示出來,比如 Swarm 模式的節點。
如果你有一些 cAdvisor 或其他工具無法解決的特殊需求,我建議你開發自己的數據收集器和數據處理器(比如 Beats),請注意我不會演示如何使用 Elasticsearch 來集中收集 Docker 容器的日誌。
我們為什麼要監控容器?
想像一下這個經典場景:你在管理一台或多台虛擬機,你把 tmux 工具用得很溜,用各種 session 事先設定好了所有基礎的東西,包括監控。然後生產環境出問題了,你使用 top、htop、iotop、jnettop 各種 top 來排查,然後你準備好修復故障。
現在重新想像一下你有 3 個節點,包含 50 台容器,你需要在一個地方查看整潔的歷史數據,這樣你知道問題出在哪個地方,而不是把你的生命浪費在那些字元界面來賭你可以找到問題點。
什麼是 Elastic Stack ?
Elastic Stack 就一個工具集,包括以下工具:
- Elasticsearch
- Kibana
- Logstash
- Beats
我們會使用其中一部分工具,比如使用 Elasticsearch 來分析基於 JSON 格式的文本,以及使用 Kibana 來可視化數據併產生報表。
另一個重要的工具是 Beats,但在本文中我們還是把精力放在容器上,官方的 Beats 工具不支持 Docker,所以我們選擇原生兼容 Elasticsearch 的 cAdvisor。
cAdvisor 工具負責收集、整合正在運行的容器數據,並導出報表。在本文中,這些報表被到入到 Elasticsearch 中。
cAdvisor 有兩個比較酷的特性:
- 它不只局限於 Docker 容器。
- 它有自己的 Web 伺服器,可以簡單地顯示當前節點的可視化報表。
設置測試集群,或搭建自己的基礎架構
和我以前的文章一樣,我習慣提供一個簡單的腳本,讓讀者不用花很多時間就能部署好和我一樣的測試環境。你可以使用以下(非生產環境使用的)腳本來搭建一個 Swarm 模式的集群,其中一個容器運行著 Elasticsearch。
如果你有充足的時間和經驗,你可以 搭建自己的基礎架構 。
如果要繼續閱讀本文,你需要:
- 運行 Docker 進程的一個或多個節點(docker 版本號大於等於 1.12)。
- 至少有一個獨立運行的 Elasticsearch 節點(版本號 2.4.X)。
重申一下,此 Elasticsearch 集群環境不能放在生產環境中使用。生產環境也不推薦使用單節點集群,所以如果你計劃安裝一個生產環境,請參考 Elastic 指南。
對喜歡嘗鮮的用戶的友情提示
我就是一個喜歡嘗鮮的人(當然我也已經在生產環境中使用了最新的 alpha 版本),但是在本文中,我不會使用最新的 Elasticsearch 5.0.0 alpha 版本,我還不是很清楚這個版本的功能,所以我不想成為那個引導你們出錯的關鍵。
所以本文中涉及的 Elasticsearch 版本為最新穩定版 2.4.0。
測試集群部署腳本
前面已經說過,我提供這個腳本給你們,讓你們不必費神去部署 Swarm 集群和 Elasticsearch,當然你也可以跳過這一步,用你自己的 Swarm 模式引擎和你自己的 Elasticserch 節點。
執行這段腳本之前,你需要:
- Docker Machine – 最終版:在 DigitalOcean 中提供 Docker 引擎。
- DigitalOcean API Token: 讓 docker 機器按照你的意思來啟動節點。
創建集群的腳本
現在萬事俱備,你可以把下面的代碼拷到 create-cluster.sh 文件中:
#!/usr/bin/env bash
#
# Create a Swarm Mode cluster with a single master and a configurable number of workers
workers=${WORKERS:-"worker1 worker2"}
#######################################
# Creates a machine on Digital Ocean
# Globals:
# DO_ACCESS_TOKEN The token needed to access DigitalOcean's API
# Arguments:
# $1 the actual name to give to the machine
#######################################
create_machine() {
docker-machine create
-d digitalocean
--digitalocean-access-token=$DO_ACCESS_TOKEN
--digitalocean-size 2gb
$1
}
#######################################
# Executes a command on the specified machine
# Arguments:
# $1 The machine on which to run the command
# $2..$n The command to execute on that machine
#######################################
machine_do() {
docker-machine ssh $@
}
main() {
if [ -z "$DO_ACCESS_TOKEN" ]; then
echo "Please export a DigitalOcean Access token: https://cloud.digitalocean.com/settings/api/tokens/new"
echo "export DO_ACCESS_TOKEN=<yourtokenhere>"
exit 1
fi
if [ -z "$WORKERS" ]; then
echo "You haven't provided your workers by setting the $WORKERS environment variable, using the default ones: $workers"
fi
# Create the first and only master
echo "Creating the master"
create_machine master1
master_ip=$(docker-machine ip master1)
# Initialize the swarm mode on it
echo "Initializing the swarm mode"
machine_do master1 docker swarm init --advertise-addr $master_ip
# Obtain the token to allow workers to join
worker_tkn=$(machine_do master1 docker swarm join-token -q worker)
echo "Worker token: ${worker_tkn}"
# Create and join the workers
for worker in $workers; do
echo "Creating worker ${worker}"
create_machine $worker
machine_do $worker docker swarm join --token $worker_tkn $master_ip:2377
done
}
main $@
賦予它可執行許可權:
chmod +x create-cluster.sh
創建集群
如文件名所示,我們可以用它來創建集群。默認情況下這個腳本會創建一個 master 和兩個 worker,如果你想修改 worker 個數,可以設置環境變數 WORKERS。
現在就來創建集群吧。
./create-cluster.sh
你可以出去喝杯咖啡,因為這需要花點時間。
最後集群部署好了。
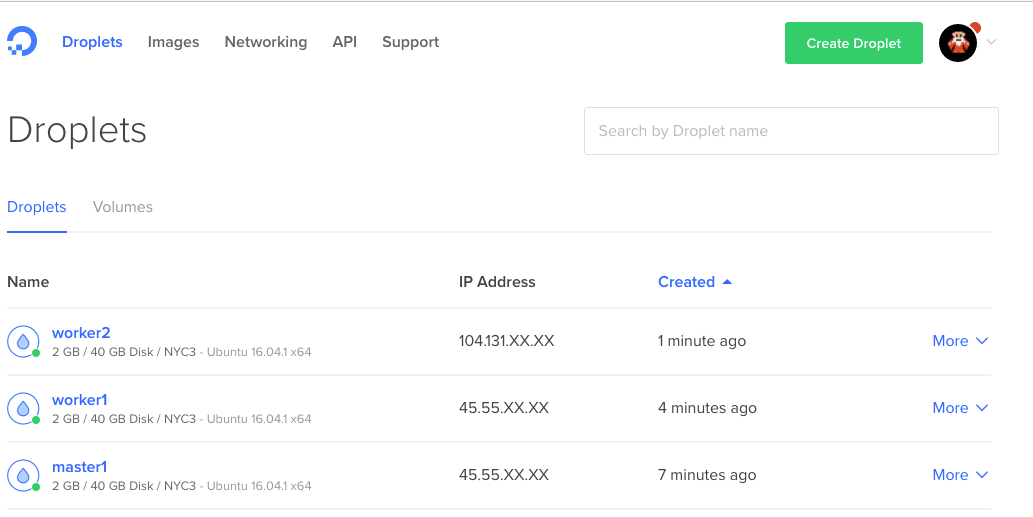
現在為了驗證 Swarm 模式集群已經正常運行,我們可以通過 ssh 登錄進 master:
docker-machine ssh master1
然後列出集群的節點:
docker node ls
ID HOSTNAME STATUS AVAILABILITY MANAGER STATUS
26fi3wiqr8lsidkjy69k031w2 * master1 Ready Active Leader
dyluxpq8sztj7kmwlzs51u4id worker2 Ready Active
epglndegvixag0jztarn2lte8 worker1 Ready Active
安裝 Elasticsearch 和 Kibana
注意,從現在開始所有的命令都運行在主節點 master1 上。
在生產環境中,你可能會把 Elasticsearch 和 Kibana 安裝在一個單獨的、大小合適的實例集合中。但是在我們的實驗中,我們還是把它們和 Swarm 模式集群安裝在一起。
為了將 Elasticsearch 和 cAdvisor 連通,我們需要創建一個自定義的網路,因為我們使用了集群,並且容器可能會分布在不同的節點上,我們需要使用 overlay 網路(LCTT 譯註:overlay 網路是指在不改變現有網路基礎設施的前提下,通過某種約定通信協議,把二層報文封裝在 IP 報文之上的新的數據格式,是目前最主流的容器跨節點數據傳輸和路由方案)。
也許你會問,「為什麼還要網路?我們不是可以用 link 嗎?」 請考慮一下,自從引入用戶定義網路後,link 機制就已經過時了。
以下內容摘自 Docker 文檔:
在 Docker network 特性出來以前,你可以使用 Docker link 特性實現容器互相發現、安全通信。而在 network 特性出來以後,你還可以使用 link,但是當容器處於默認橋接網路或用戶自定義網路時,它們的表現是不一樣的。
現在創建 overlay 網路,名稱為 monitoring:
docker network create monitoring -d overlay
Elasticsearch 容器
docker service create --network=monitoring
--mount type=volume,target=/usr/share/elasticsearch/data
--constraint node.hostname==worker1
--name elasticsearch elasticsearch:2.4.0
注意 Elasticsearch 容器被限定在 worker1 節點,這是因為它運行時需要依賴 worker1 節點上掛載的卷。
Kibana 容器
docker service create --network=monitoring --name kibana -e ELASTICSEARCH_URL="http://elasticsearch:9200" -p 5601:5601 kibana:4.6.0
如你所見,我們啟動這兩個容器時,都讓它們加入 monitoring 網路,這樣一來它們可以通過名稱(如 Kibana)被相同網路的其他服務訪問。
現在,通過 routing mesh 機制,我們可以使用瀏覽器訪問伺服器的 IP 地址來查看 Kibana 報表界面。
獲取 master1 實例的公共 IP 地址:
docker-machine ip master1
打開瀏覽器輸入地址:http://[master1 的 ip 地址]:5601/status
所有項目都應該是綠色:
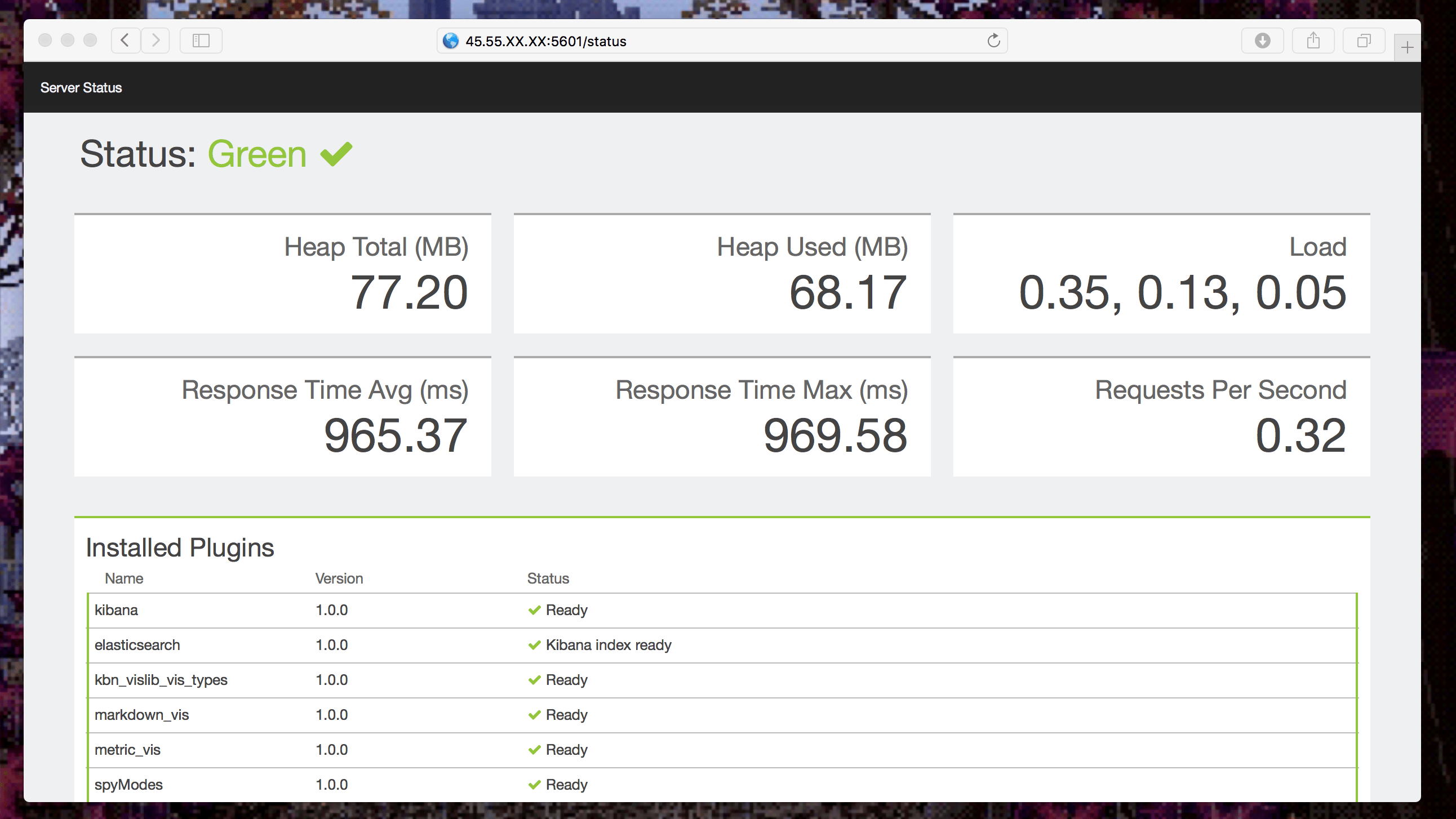
讓我們接下來開始收集數據!
收集容器的運行數據
收集數據之前,我們需要創建一個服務,以全局模式運行 cAdvisor,為每個有效節點設置一個定時任務。
這個服務與 Elasticsearch 處於相同的網路,以便於 cAdvisor 可以推送數據給 Elasticsearch。
docker service create --network=monitoring --mode global --name cadvisor
--mount type=bind,source=/,target=/rootfs,readonly=true
--mount type=bind,source=/var/run,target=/var/run,readonly=false
--mount type=bind,source=/sys,target=/sys,readonly=true
--mount type=bind,source=/var/lib/docker/,target=/var/lib/docker,readonly=true
google/cadvisor:latest
-storage_driver=elasticsearch
-storage_driver_es_host="http://elasticsearch:9200"
注意:如果你想配置 cAdvisor 選項,參考這裡。
現在 cAdvisor 在發送數據給 Elasticsearch,我們通過定義一個索引模型來檢索 Kibana 中的數據。有兩種方式可以做到這一點:通過 Kibana 或者通過 API。在這裡我們使用 API 方式實現。
我們需要在一個連接到 monitoring 網路的正在運行的容器中運行索引創建命令,你可以在 cAdvisor 容器中拿到 shell,不幸的是 Swarm 模式在開啟服務時會在容器名稱後面附加一個唯一的 ID 號,所以你需要手動指定 cAdvisor 容器的名稱。
拿到 shell:
docker exec -ti <cadvisor-container-name> sh
創建索引:
curl -XPUT http://elasticsearch:9200/.kibana/index-pattern/cadvisor -d '{"title" : "cadvisor*", "timeFieldName": "container_stats.timestamp"}'
如果你夠懶,可以只執行下面這一句:
docker exec $(docker ps | grep cadvisor | awk '{print $1}' | head -1) curl -XPUT http://elasticsearch:9200/.kibana/index-pattern/cadvisor -d '{"title" : "cadvisor*", "timeFieldName": "container_stats.timestamp"}'
把數據匯總成報表
你現在可以使用 Kibana 來創建一份美觀的報表了。但是不要著急,我為你們建了一份報表和一些圖形界面來方便你們入門。
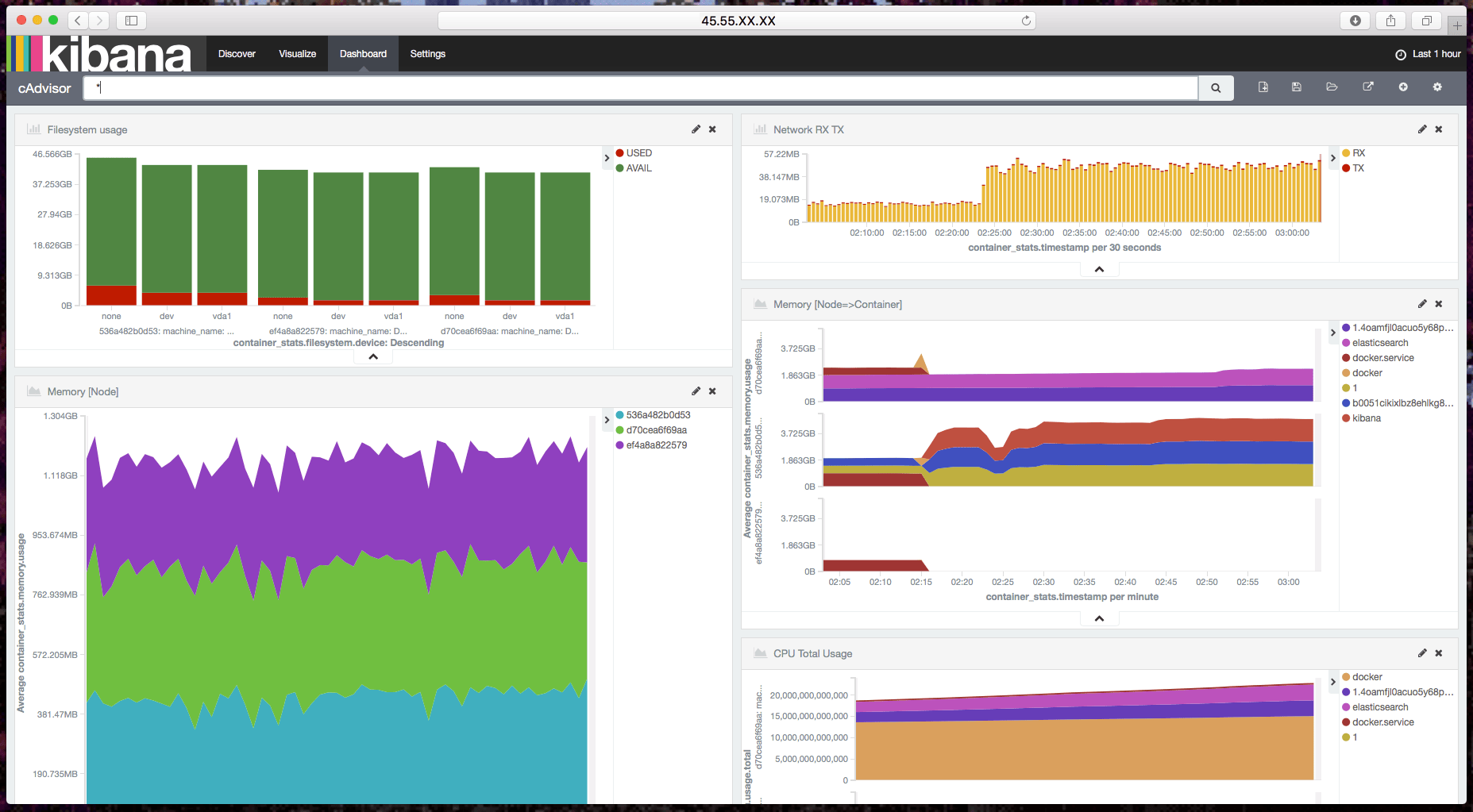
訪問 Kibana 界面 => Setting => Objects => Import,然後選擇包含以下內容的 JSON 文件,就可以導入我的配置信息了:
[
{
"_id": "cAdvisor",
"_type": "dashboard",
"_source": {
"title": "cAdvisor",
"hits": 0,
"description": "",
"panelsJSON": "[{"id":"Filesystem-usage","type":"visualization","panelIndex":1,"size_x":6,"size_y":3,"col":1,"row":1},{"id":"Memory-[Node-equal->Container]","type":"visualization","panelIndex":2,"size_x":6,"size_y":4,"col":7,"row":4},{"id":"memory-usage-by-machine","type":"visualization","panelIndex":3,"size_x":6,"size_y":6,"col":1,"row":4},{"id":"CPU-Total-Usage","type":"visualization","panelIndex":4,"size_x":6,"size_y":5,"col":7,"row":8},{"id":"Network-RX-TX","type":"visualization","panelIndex":5,"size_x":6,"size_y":3,"col":7,"row":1}]",
"optionsJSON": "{"darkTheme":false}",
"uiStateJSON": "{}",
"version": 1,
"timeRestore": false,
"kibanaSavedObjectMeta": {
"searchSourceJSON": "{"filter":[{"query":{"query_string":{"query":"*","analyze_wildcard":true}}}]}"
}
}
},
{
"_id": "Network",
"_type": "search",
"_source": {
"title": "Network",
"description": "",
"hits": 0,
"columns": [
"machine_name",
"container_Name",
"container_stats.network.name",
"container_stats.network.interfaces",
"container_stats.network.rx_bytes",
"container_stats.network.rx_packets",
"container_stats.network.rx_dropped",
"container_stats.network.rx_errors",
"container_stats.network.tx_packets",
"container_stats.network.tx_bytes",
"container_stats.network.tx_dropped",
"container_stats.network.tx_errors"
],
"sort": [
"container_stats.timestamp",
"desc"
],
"version": 1,
"kibanaSavedObjectMeta": {
"searchSourceJSON": "{"index":"cadvisor*","query":{"query_string":{"analyze_wildcard":true,"query":"*"}},"highlight":{"pre_tags":["@kibana-highlighted-field@"],"post_tags":["@/kibana-highlighted-field@"],"fields":{"*":{}},"fragment_size":2147483647},"filter":[]}"
}
}
},
{
"_id": "Filesystem-usage",
"_type": "visualization",
"_source": {
"title": "Filesystem usage",
"visState": "{"title":"Filesystem usage","type":"histogram","params":{"addLegend":true,"addTimeMarker":false,"addTooltip":true,"defaultYExtents":false,"mode":"stacked","scale":"linear","setYExtents":false,"shareYAxis":true,"times":[],"yAxis":{}},"aggs":[{"id":"1","type":"avg","schema":"metric","params":{"field":"container_stats.filesystem.usage","customLabel":"USED"}},{"id":"2","type":"terms","schema":"split","params":{"field":"machine_name","size":5,"order":"desc","orderBy":"1","row":false}},{"id":"3","type":"avg","schema":"metric","params":{"field":"container_stats.filesystem.capacity","customLabel":"AVAIL"}},{"id":"4","type":"terms","schema":"segment","params":{"field":"container_stats.filesystem.device","size":5,"order":"desc","orderBy":"1"}}],"listeners":{}}",
"uiStateJSON": "{"vis":{"colors":{"Average container_stats.filesystem.available":"#E24D42","Average container_stats.filesystem.base_usage":"#890F02","Average container_stats.filesystem.capacity":"#3F6833","Average container_stats.filesystem.usage":"#E24D42","USED":"#BF1B00","AVAIL":"#508642"}}}",
"description": "",
"version": 1,
"kibanaSavedObjectMeta": {
"searchSourceJSON": "{"index":"cadvisor*","query":{"query_string":{"analyze_wildcard":true,"query":"*"}},"filter":[]}"
}
}
},
{
"_id": "CPU-Total-Usage",
"_type": "visualization",
"_source": {
"title": "CPU Total Usage",
"visState": "{"title":"CPU Total Usage","type":"area","params":{"shareYAxis":true,"addTooltip":true,"addLegend":true,"smoothLines":false,"scale":"linear","interpolate":"linear","mode":"stacked","times":[],"addTimeMarker":false,"defaultYExtents":false,"setYExtents":false,"yAxis":{}},"aggs":[{"id":"1","type":"avg","schema":"metric","params":{"field":"container_stats.cpu.usage.total"}},{"id":"2","type":"date_histogram","schema":"segment","params":{"field":"container_stats.timestamp","interval":"auto","customInterval":"2h","min_doc_count":1,"extended_bounds":{}}},{"id":"3","type":"terms","schema":"group","params":{"field":"container_Name","size":5,"order":"desc","orderBy":"1"}},{"id":"4","type":"terms","schema":"split","params":{"field":"machine_name","size":5,"order":"desc","orderBy":"1","row":true}}],"listeners":{}}",
"uiStateJSON": "{}",
"description": "",
"version": 1,
"kibanaSavedObjectMeta": {
"searchSourceJSON": "{"index":"cadvisor*","query":{"query_string":{"query":"*","analyze_wildcard":true}},"filter":[]}"
}
}
},
{
"_id": "memory-usage-by-machine",
"_type": "visualization",
"_source": {
"title": "Memory [Node]",
"visState": "{"title":"Memory [Node]","type":"area","params":{"shareYAxis":true,"addTooltip":true,"addLegend":true,"smoothLines":false,"scale":"linear","interpolate":"linear","mode":"stacked","times":[],"addTimeMarker":false,"defaultYExtents":false,"setYExtents":false,"yAxis":{}},"aggs":[{"id":"1","type":"avg","schema":"metric","params":{"field":"container_stats.memory.usage"}},{"id":"2","type":"date_histogram","schema":"segment","params":{"field":"container_stats.timestamp","interval":"auto","customInterval":"2h","min_doc_count":1,"extended_bounds":{}}},{"id":"3","type":"terms","schema":"group","params":{"field":"machine_name","size":5,"order":"desc","orderBy":"1"}}],"listeners":{}}",
"uiStateJSON": "{}",
"description": "",
"version": 1,
"kibanaSavedObjectMeta": {
"searchSourceJSON": "{"index":"cadvisor*","query":{"query_string":{"query":"*","analyze_wildcard":true}},"filter":[]}"
}
}
},
{
"_id": "Network-RX-TX",
"_type": "visualization",
"_source": {
"title": "Network RX TX",
"visState": "{"title":"Network RX TX","type":"histogram","params":{"addLegend":true,"addTimeMarker":true,"addTooltip":true,"defaultYExtents":false,"mode":"stacked","scale":"linear","setYExtents":false,"shareYAxis":true,"times":[],"yAxis":{}},"aggs":[{"id":"1","type":"avg","schema":"metric","params":{"field":"container_stats.network.rx_bytes","customLabel":"RX"}},{"id":"2","type":"date_histogram","schema":"segment","params":{"field":"container_stats.timestamp","interval":"s","customInterval":"2h","min_doc_count":1,"extended_bounds":{}}},{"id":"3","type":"avg","schema":"metric","params":{"field":"container_stats.network.tx_bytes","customLabel":"TX"}}],"listeners":{}}",
"uiStateJSON": "{"vis":{"colors":{"RX":"#EAB839","TX":"#BF1B00"}}}",
"description": "",
"savedSearchId": "Network",
"version": 1,
"kibanaSavedObjectMeta": {
"searchSourceJSON": "{"filter":[]}"
}
}
},
{
"_id": "Memory-[Node-equal->Container]",
"_type": "visualization",
"_source": {
"title": "Memory [Node=>Container]",
"visState": "{"title":"Memory [Node=>Container]","type":"area","params":{"shareYAxis":true,"addTooltip":true,"addLegend":true,"smoothLines":false,"scale":"linear","interpolate":"linear","mode":"stacked","times":[],"addTimeMarker":false,"defaultYExtents":false,"setYExtents":false,"yAxis":{}},"aggs":[{"id":"1","type":"avg","schema":"metric","params":{"field":"container_stats.memory.usage"}},{"id":"2","type":"date_histogram","schema":"segment","params":{"field":"container_stats.timestamp","interval":"auto","customInterval":"2h","min_doc_count":1,"extended_bounds":{}}},{"id":"3","type":"terms","schema":"group","params":{"field":"container_Name","size":5,"order":"desc","orderBy":"1"}},{"id":"4","type":"terms","schema":"split","params":{"field":"machine_name","size":5,"order":"desc","orderBy":"1","row":true}}],"listeners":{}}",
"uiStateJSON": "{}",
"description": "",
"version": 1,
"kibanaSavedObjectMeta": {
"searchSourceJSON": "{"index":"cadvisor*","query":{"query_string":{"query":"* NOT container_Name.raw: \\\"/\\\" AND NOT container_Name.raw: \\\"/docker\\\"","analyze_wildcard":true}},"filter":[]}"
}
}
}
]
這裡還有很多東西可以玩,你也許想自定義報表界面,比如添加內存頁錯誤狀態,或者收發包的丟包數。如果你能實現開頭列表處我沒能實現的項目,那也是很好的。
總結
正確監控需要大量時間和精力,容器的 CPU、內存、IO、網路和磁碟,監控的這些參數還只是整個監控項目中的滄海一粟而已。
我不知道你做到了哪一階段,但接下來的任務也許是:
- 收集運行中的容器的日誌
- 收集應用的日誌
- 監控應用的性能
- 報警
- 監控健康狀態
如果你有意見或建議,請留言。祝你玩得開心。
現在你可以關掉這些測試系統了:
docker-machine rm master1 worker{1,2}
via: https://blog.codeship.com/monitoring-docker-containers-with-elasticsearch-and-cadvisor/
作者:Lorenzo Fontana 譯者:bazz2 校對:wxy
本文轉載來自 Linux 中國: https://github.com/Linux-CN/archive
對這篇文章感覺如何?
You may also like






More in:Linux中國

捐贈 Let's Encrypt,共建安全的互聯網

Let's Encrypt 正式發布,已經保護 380 萬個域名

關於Linux防火牆iptables的面試問答

Lets Encrypt 已被所有主流瀏覽器所信任









