Kubernetes 分散式應用部署實戰:以人臉識別應用為例
簡介
夥計們,請搬好小板凳坐好,下面將是一段漫長的旅程,期望你能夠樂在其中。
我將基於 Kubernetes 部署一個分散式應用。我曾試圖編寫一個儘可能真實的應用,但由於時間和精力有限,最終砍掉了很多細節。
我將聚焦 Kubernetes 及其部署。
讓我們開始吧。
應用
TL;DR
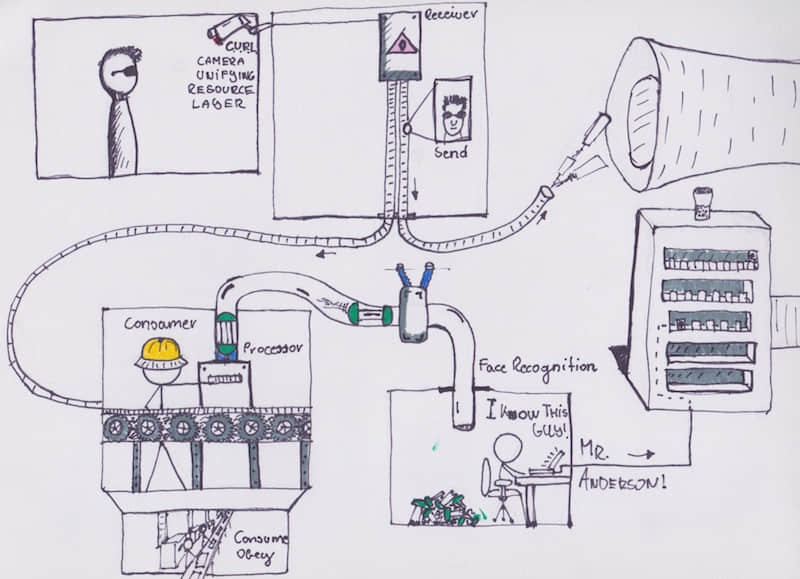
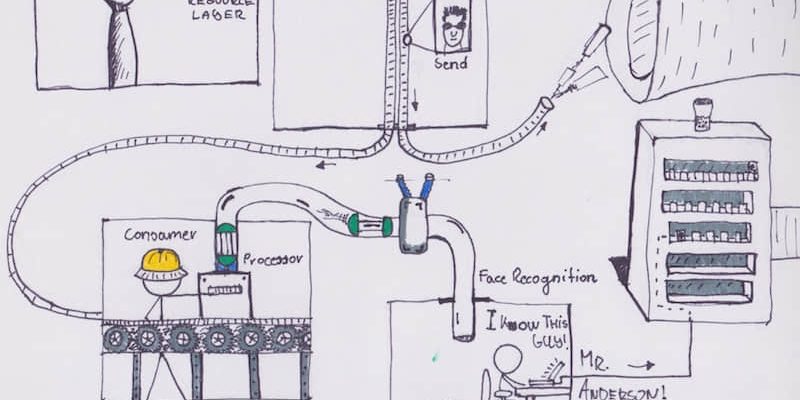
該應用本身由 6 個組件構成。代碼可以從如下鏈接中找到:Kubenetes 集群示例。
這是一個人臉識別服務,通過比較已知個人的圖片,識別給定圖片對應的個人。前端頁面用表格形式簡要的展示圖片及對應的個人。具體而言,向 接收器 發送請求,請求包含指向一個圖片的鏈接。圖片可以位於任何位置。接受器將圖片地址存儲到資料庫 (MySQL) 中,然後向隊列發送處理請求,請求中包含已保存圖片的 ID。這裡我們使用 NSQ 建立隊列。
圖片處理 服務一直監聽處理請求隊列,從中獲取任務。處理過程包括如下幾步:獲取圖片 ID,讀取圖片,通過 gRPC 將圖片路徑發送至 Python 編寫的 人臉識別 後端。如果識別成功,後端給出圖片對應個人的名字。圖片處理器進而根據個人 ID 更新圖片記錄,將其標記為處理成功。如果識別不成功,圖片被標記為待解決。如果圖片識別過程中出現錯誤,圖片被標記為失敗。
標記為失敗的圖片可以通過計劃任務等方式進行重試。
那麼具體是如何工作的呢?我們深入探索一下。
接收器
接收器服務是整個流程的起點,通過如下形式的 API 接收請求:
curl -d '{"path":"/unknown_images/unknown0001.jpg"}' http://127.0.0.1:8000/image/post
此時,接收器將 路徑 存儲到共享資料庫集群中,該實體存儲後將從資料庫服務收到對應的 ID。本應用採用「 實體對象 的唯一標識由持久層提供」的模型。獲得實體 ID 後,接收器向 NSQ 發送消息,至此接收器的工作完成。
圖片處理器
從這裡開始變得有趣起來。圖片處理器首次運行時會創建兩個 Go 協程 ,具體為:
Consume
這是一個 NSQ 消費者,需要完成三項必需的任務。首先,監聽隊列中的消息。其次,當有新消息到達時,將對應的 ID 追加到一個線程安全的 ID 片段中,以供第二個協程處理。最後,告知第二個協程處理新任務,方法為 sync.Condition。
ProcessImages
該協程會處理指定 ID 片段,直到對應片段全部處理完成。當處理完一個片段後,該協程並不是在一個通道上睡眠等待,而是進入懸掛狀態。對每個 ID,按如下步驟順序處理:
- 與人臉識別服務建立 gRPC 連接,其中人臉識別服務會在人臉識別部分進行介紹
- 從資料庫獲取圖片對應的實體
- 為 斷路器 準備兩個函數
- 函數 1: 用於 RPC 方法調用的主函數
- 函數 2: 基於 ping 的斷路器健康檢查
- 調用函數 1 將圖片路徑發送至人臉識別服務,其中路徑應該是人臉識別服務可以訪問的,最好是共享的,例如 NFS
- 如果調用失敗,將圖片實體狀態更新為 FAILEDPROCESSING
- 如果調用成功,返回值是一個圖片的名字,對應資料庫中的一個個人。通過聯合 SQL 查詢,獲取對應個人的 ID
- 將資料庫中的圖片實體狀態更新為 PROCESSED,更新圖片被識別成的個人的 ID
這個服務可以複製多份同時運行。
斷路器
即使對於一個複製資源幾乎沒有開銷的系統,也會有意外的情況發生,例如網路故障或任何兩個服務之間的通信存在問題等。我在 gRPC 調用中實現了一個簡單的斷路器,這十分有趣。
下面給出工作原理:
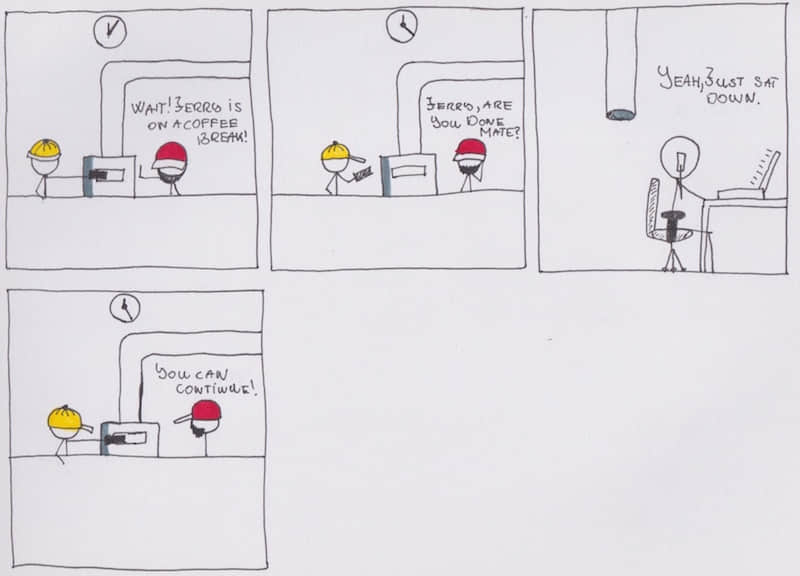
當出現 5 次不成功的服務調用時,斷路器啟動並阻斷後續的調用請求。經過指定的時間後,它對服務進行健康檢查並判斷是否恢復。如果問題依然存在,等待時間會進一步增大。如果已經恢復,斷路器停止對服務調用的阻斷,允許請求流量通過。
前端
前端只包含一個極其簡單的表格視圖,通過 Go 自身的 html/模板顯示一系列圖片。
人臉識別
人臉識別是整個識別的關鍵點。僅因為追求靈活性,我將這個服務設計為基於 gRPC 的服務。最初我使用 Go 編寫,但後續發現基於 Python 的實現更加適合。事實上,不算 gRPC 部分的代碼,人臉識別部分僅有 7 行代碼。我使用的人臉識別庫極為出色,它包含 OpenCV 的全部 C 綁定。維護 API 標準意味著只要標準本身不變,實現可以任意改變。
注意:我曾經試圖使用 GoCV,這是一個極好的 Go 庫,但欠缺所需的 C 綁定。推薦馬上了解一下這個庫,它會讓你大吃一驚,例如編寫若干行代碼即可實現實時攝像處理。
這個 Python 庫的工作方式本質上很簡單。準備一些你認識的人的圖片,把信息記錄下來。對於我而言,我有一個圖片文件夾,包含若干圖片,名稱分別為 hannibal_1.jpg、 hannibal_2.jpg、 gergely_1.jpg、 john_doe.jpg。在資料庫中,我使用兩個表記錄信息,分別為 person、 person_images,具體如下:
+----+----------+
| id | name |
+----+----------+
| 1 | Gergely |
| 2 | John Doe |
| 3 | Hannibal |
+----+----------+
+----+----------------+-----------+
| id | image_name | person_id |
+----+----------------+-----------+
| 1 | hannibal_1.jpg | 3 |
| 2 | hannibal_2.jpg | 3 |
+----+----------------+-----------+
人臉識別庫識別出未知圖片後,返回圖片的名字。我們接著使用類似下面的聯合查詢找到對應的個人。
select person.name, person.id from person inner join person_images as pi on person.id = pi.person_id where image_name = 'hannibal_2.jpg';
gRPC 調用返回的個人 ID 用於更新圖片的 person 列。
NSQ
NSQ 是 Go 編寫的小規模隊列,可擴展且佔用系統內存較少。NSQ 包含一個查詢服務,用於消費者接收消息;包含一個守護進程,用於發送消息。
在 NSQ 的設計理念中,消息發送程序應該與守護進程在同一台主機上,故發送程序僅需發送至 localhost。但守護進程與查詢服務相連接,這使其構成了全局隊列。
這意味著有多少 NSQ 守護進程就有多少對應的發送程序。但由於其資源消耗極小,不會影響主程序的資源使用。
配置
為了儘可能增加靈活性以及使用 Kubernetes 的 ConfigSet 特性,我在開發過程中使用 .env 文件記錄配置信息,例如資料庫服務的地址以及 NSQ 的查詢地址。在生產環境或 Kubernetes 環境中,我將使用環境變數屬性配置。
應用小結
這就是待部署應用的全部架構信息。應用的各個組件都是可變更的,他們之間僅通過資料庫、消息隊列和 gRPC 進行耦合。考慮到更新機制的原理,這是部署分散式應用所必須的;在部署部分我會繼續分析。
使用 Kubernetes 部署應用
基礎知識
Kubernetes 是什麼?
這裡我會提到一些基礎知識,但不會深入細節,細節可以用一本書的篇幅描述,例如 Kubernetes 構建與運行。另外,如果你願意挑戰自己,可以查看官方文檔:Kubernetes 文檔。
Kubernetes 是容器化服務及應用的管理器。它易於擴展,可以管理大量容器;更重要的是,可以通過基於 yaml 的模板文件高度靈活地進行配置。人們經常把 Kubernetes 比作 Docker Swarm,但 Kubernetes 的功能不僅僅如此。例如,Kubernetes 不關心底層容器實現,你可以使用 LXC 與 Kubernetes 的組合,效果與使用 Docker 一樣好。Kubernetes 在管理容器的基礎上,可以管理已部署的服務或應用集群。如何操作呢?讓我們概覽一下用於構成 Kubernetes 的模塊。
在 Kubernetes 中,你給出期望的應用狀態,Kubernetes 會盡其所能達到對應的狀態。狀態可以是已部署、已暫停,有 2 個副本等,以此類推。
Kubernetes 使用標籤和注釋標記組件,包括服務、部署、副本組、守護進程組等在內的全部組件都被標記。考慮如下場景,為了識別 pod 與應用的對應關係,使用 app: myapp 標籤。假設應用已部署 2 個容器,如果你移除其中一個容器的 app 標籤,Kubernetes 只能識別到一個容器(隸屬於應用),進而啟動一個新的具有 myapp 標籤的實例。
Kubernetes 集群
要使用 Kubernetes,需要先搭建一個 Kubernetes 集群。搭建 Kubernetes 集群可能是一個痛苦的經歷,但所幸有工具可以幫助我們。Minikube 為我們在本地搭建一個單節點集群。AWS 的一個 beta 服務工作方式類似於 Kubernetes 集群,你只需請求節點並定義你的部署即可。Kubernetes 集群組件的文檔如下:Kubernetes 集群組件。
節點
節點 是工作單位,形式可以是虛擬機、物理機,也可以是各種類型的雲主機。
Pod
Pod 是本地容器邏輯上組成的集合,即一個 Pod 中可能包含若干個容器。Pod 創建後具有自己的 DNS 和虛擬 IP,這樣 Kubernetes 可以對到達流量進行負載均衡。你幾乎不需要直接和容器打交道;即使是調試的時候,例如查看日誌,你通常調用 kubectl logs deployment/your-app -f 查看部署日誌,而不是使用 -c container_name 查看具體某個容器的日誌。-f 參數表示從日誌尾部進行流式輸出。
部署
在 Kubernetes 中創建任何類型的資源時,後台使用一個 部署 組件,它指定了資源的期望狀態。使用部署對象,你可以將 Pod 或服務變更為另外的狀態,也可以更新應用或上線新版本應用。你一般不會直接操作副本組 (後續會描述),而是通過部署對象創建並管理。
服務
默認情況下,Pod 會獲取一個 IP 地址。但考慮到 Pod 是 Kubernetes 中的易失性組件,我們需要更加持久的組件。不論是隊列,MySQL、內部 API 或前端,都需要長期運行並使用保持不變的 IP 或更好的 DNS 記錄。
為解決這個問題,Kubernetes 提供了 服務 組件,可以定義訪問模式,支持的模式包括負載均衡、簡單 IP 或內部 DNS。
Kubernetes 如何獲知服務運行正常呢?你可以配置健康性檢查和可用性檢查。健康性檢查是指檢查容器是否處於運行狀態,但容器處於運行狀態並不意味著服務運行正常。對此,你應該使用可用性檢查,即請求應用的一個特別 介面 。
由於服務非常重要,推薦你找時間閱讀以下文檔:服務。嚴肅的說,需要閱讀的東西很多,有 24 頁 A4 紙的篇幅,涉及網路、服務及自動發現。這也有助於你決定是否真的打算在生產環境中使用 Kubernetes。
DNS / 服務發現
在 Kubernetes 集群中創建服務後,該服務會從名為 kube-proxy 和 kube-dns 的特殊 Kubernetes 部署中獲取一個 DNS 記錄。它們兩個用於提供集群內的服務發現。如果你有一個正在運行的 MySQL 服務並配置 clusterIP: no,那麼集群內部任何人都可以通過 mysql.default.svc.cluster.local 訪問該服務,其中:
mysql– 服務的名稱default– 命名空間的名稱svc– 對應服務分類cluster.local– 本地集群的域名
可以使用自定義設置更改本地集群的域名。如果想讓服務可以從集群外訪問,需要使用 DNS 服務,並使用例如 Nginx 將 IP 地址綁定至記錄。服務對應的對外 IP 地址可以使用如下命令查詢:
- 節點埠方式 –
kubectl get -o jsonpath="{.spec.ports[0].nodePort}" services mysql - 負載均衡方式 –
kubectl get -o jsonpath="{.spec.ports[0].LoadBalancer}" services mysql
模板文件
類似 Docker Compose、TerraForm 或其它的服務管理工具,Kubernetes 也提供了基礎設施描述模板。這意味著,你幾乎不用手動操作。
以 Nginx 部署為例,查看下面的 yaml 模板:
apiVersion: apps/v1
kind: Deployment #(1)
metadata: #(2)
name: nginx-deployment
labels: #(3)
app: nginx
spec: #(4)
replicas: 3 #(5)
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
containers: #(6)
- name: nginx
image: nginx:1.7.9
ports:
- containerPort: 80
在這個示例部署中,我們做了如下操作:
- (1) 使用
kind關鍵字定義模板類型 - (2) 使用
metadata關鍵字,增加該部署的識別信息 - (3) 使用
labels標記每個需要創建的資源 - (4) 然後使用
spec關鍵字描述所需的狀態 - (5) nginx 應用需要 3 個副本
- (6) Pod 中容器的模板定義部分
- 容器名稱為 nginx
- 容器模板為 nginx:1.7.9 (本例使用 Docker 鏡像)
副本組
副本組 是一個底層的副本管理器,用於保證運行正確數目的應用副本。相比而言,部署是更高層級的操作,應該用於管理副本組。除非你遇到特殊的情況,需要控制副本的特性,否則你幾乎不需要直接操作副本組。
守護進程組
上面提到 Kubernetes 始終使用標籤,還有印象嗎? 守護進程組 是一個控制器,用於確保守護進程化的應用一直運行在具有特定標籤的節點中。
例如,你將所有節點增加 logger 或 mission_critical 的標籤,以便運行日誌 / 審計服務的守護進程。接著,你創建一個守護進程組並使用 logger 或 mission_critical 節點選擇器。Kubernetes 會查找具有該標籤的節點,確保守護進程的實例一直運行在這些節點中。因而,節點中運行的所有進程都可以在節點內訪問對應的守護進程。
以我的應用為例,NSQ 守護進程可以用守護進程組實現。具體而言,將對應節點增加 recevier 標籤,創建一個守護進程組並配置 receiver 應用選擇器,這樣這些節點上就會一直運行接收者組件。
守護進程組具有副本組的全部優勢,可擴展且由 Kubernetes 管理,意味著 Kubernetes 管理其全生命周期的事件,確保持續運行,即使出現故障,也會立即替換。
擴展
在 Kubernetes 中,擴展是稀鬆平常的事情。副本組負責 Pod 運行的實例數目。就像你在 nginx 部署那個示例中看到的那樣,對應設置項 replicas:3。我們可以按應用所需,讓 Kubernetes 運行多份應用副本。
當然,設置項有很多。你可以指定讓多個副本運行在不同的節點上,也可以指定各種不同的應用啟動等待時間。想要在這方面了解更多,可以閱讀 水平擴展 和 Kubernetes 中的互動式擴展;當然 副本組 的細節對你也有幫助,畢竟 Kubernetes 中的擴展功能都來自於該模塊。
Kubernetes 部分小結
Kubernetes 是容器編排的便捷工具,工作單元為 Pod,具有分層架構。最頂層是部署,用於操作其它資源,具有高度可配置性。對於你的每個命令調用,Kubernetes 提供了對應的 API,故理論上你可以編寫自己的代碼,向 Kubernetes API 發送數據,得到與 kubectl 命令同樣的效果。
截至目前,Kubernetes 原生支持所有主流雲服務供應商,而且完全開源。如果你願意,可以貢獻代碼;如果你希望對工作原理有深入了解,可以查閱代碼:GitHub 上的 Kubernetes 項目。
Minikube
接下來我會使用 Minikube 這款本地 Kubernetes 集群模擬器。它並不擅長模擬多節點集群,但可以很容易地給你提供本地學習環境,讓你開始探索,這很棒。Minikube 基於可高度調優的虛擬機,由 VirtualBox 類似的虛擬化工具提供。
我用到的全部 Kubernetes 模板文件可以在這裡找到:Kubernetes 文件。
注意:在你後續測試可擴展性時,會發現副本一直處於 Pending 狀態,這是因為 minikube 集群中只有一個節點,不應該允許多副本運行在同一個節點上,否則明顯只是耗盡了可用資源。使用如下命令可以查看可用資源:
kubectl get nodes -o yaml
構建容器
Kubernetes 支持大多數現有的容器技術。我這裡使用 Docker。每一個構建的服務容器,對應代碼庫中的一個 Dockerfile 文件。我推薦你仔細閱讀它們,其中大多數都比較簡單。對於 Go 服務,我採用了最近引入的多步構建的方式。Go 服務基於 Alpine Linux 鏡像創建。人臉識別程序使用 Python、NSQ 和 MySQL 使用對應的容器。
上下文
Kubernetes 使用命名空間。如果你不額外指定命名空間,Kubernetes 會使用 default 命名空間。為避免污染默認命名空間,我會一直指定命名空間,具體操作如下:
❯ kubectl config set-context kube-face-cluster --namespace=face
Context "kube-face-cluster" created.
創建上下文之後,應馬上啟用:
❯ kubectl config use-context kube-face-cluster
Switched to context "kube-face-cluster".
此後,所有 kubectl 命令都會使用 face 命名空間。
(LCTT 譯註:作者後續並沒有使用 face 命名空間,模板文件中的命名空間仍為 default,可能 face 命名空間用於開發環境。如果希望使用 face 命令空間,需要將內部 DNS 地址中的 default 改成 face;如果只是測試,可以不執行這兩條命令。)
應用部署
Pods 和 服務概覽:
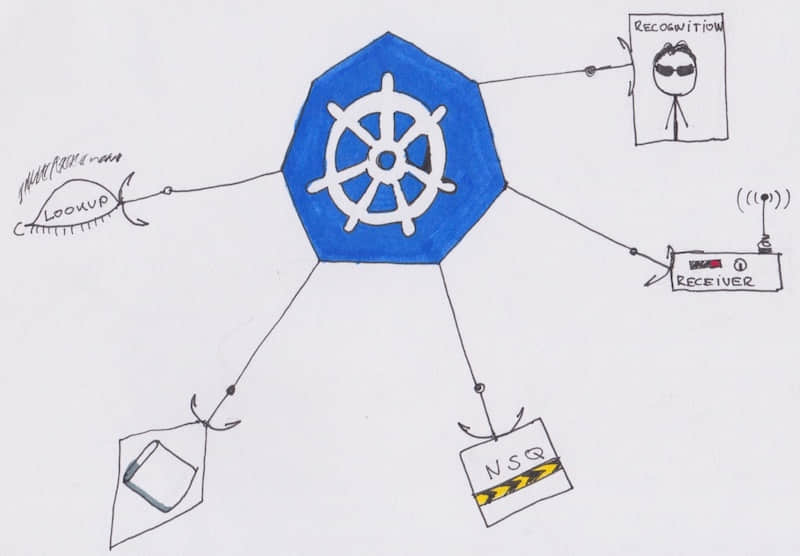
MySQL
第一個要部署的服務是資料庫。
按照 Kubernetes 的示例 Kubenetes MySQL 進行部署,即可以滿足我的需求。注意:示例配置文件的 MYSQL_PASSWORD 欄位使用了明文密碼,我將使用 Kubernetes Secrets 對象以提高安全性。
我創建了一個 Secret 對象,對應的本地 yaml 文件如下:
apiVersion: v1
kind: Secret
metadata:
name: kube-face-secret
type: Opaque
data:
mysql_password: base64codehere
mysql_userpassword: base64codehere
其中 base64 編碼通過如下命令生成:
echo -n "ubersecurepassword" | base64
echo -n "root:ubersecurepassword" | base64
(LCTT 譯註:secret yaml 文件中的 data 應該有兩條,一條對應 mysql_password,僅包含密碼;另一條對應 mysql_userpassword,包含用戶和密碼。後文會用到 mysql_userpassword,但沒有提及相應的生成)
我的部署 yaml 對應部分如下:
...
- name: MYSQL_ROOT_PASSWORD
valueFrom:
secretKeyRef:
name: kube-face-secret
key: mysql_password
...
另外值得一提的是,我使用卷將資料庫持久化,卷對應的定義如下:
...
volumeMounts:
- name: mysql-persistent-storage
mountPath: /var/lib/mysql
...
volumes:
- name: mysql-persistent-storage
persistentVolumeClaim:
claimName: mysql-pv-claim
...
其中 presistentVolumeClain 是關鍵,告知 Kubernetes 當前資源需要持久化存儲。持久化存儲的提供方式對用戶透明。類似 Pods,如果想了解更多細節,參考文檔:Kubernetes 持久化存儲。
(LCTT 譯註:使用 presistentVolumeClain 之前需要創建 presistentVolume,對於單節點可以使用本地存儲,對於多節點需要使用共享存儲,因為 Pod 可以能調度到任何一個節點)
使用如下命令部署 MySQL 服務:
kubectl apply -f mysql.yaml
這裡比較一下 create 和 apply。apply 是一種 宣告式 的對象配置命令,而 create 是 命令式 的命令。當下我們需要知道的是, create 通常對應一項任務,例如運行某個組件或創建一個部署;相比而言,當我們使用 apply 的時候,用戶並沒有指定具體操作,Kubernetes 會根據集群目前的狀態定義需要執行的操作。故如果不存在名為 mysql 的服務,當我執行 apply -f mysql.yaml 時,Kubernetes 會創建該服務。如果再次執行這個命令,Kubernetes 會忽略該命令。但如果我再次運行 create ,Kubernetes 會報錯,告知服務已經創建。
想了解更多信息,請閱讀如下文檔:Kubernetes 對象管理,命令式配置和宣告式配置。
運行如下命令查看執行進度信息:
# 描述完整信息
kubectl describe deployment mysql
# 僅描述 Pods 信息
kubectl get pods -l app=mysql
(第一個命令)輸出示例如下:
...
Type Status Reason
---- ------ --- Available True MinimumReplicasAvailable
Progressing True NewReplicaSetAvailable
OldReplicaSets: <none>
NewReplicaSet: mysql-55cd6b9f47 (1/1 replicas created)
...
對於 get pods 命令,輸出示例如下:
NAME READY STATUS RESTARTS AGE
mysql-78dbbd9c49-k6sdv 1/1 Running 0 18s
可以使用下面的命令測試資料庫實例:
kubectl run -it --rm --image=mysql:5.6 --restart=Never mysql-client -- mysql -h mysql -pyourpasswordhere
特別提醒:如果你在這裡修改了密碼,重新 apply 你的 yaml 文件並不能更新容器。因為資料庫是持久化的,密碼並不會改變。你需要先使用 kubectl delete -f mysql.yaml 命令刪除整個部署。
運行 show databases 後,應該可以看到如下信息:
If you don't see a command prompt, try pressing enter.
mysql>
mysql>
mysql> show databases;
+--------------------+
| Database |
+--------------------+
| information_schema |
| kube |
| mysql |
| performance_schema |
+--------------------+
4 rows in set (0.00 sec)
mysql> exit
Bye
你會注意到,我還將一個資料庫初始化 SQL 文件掛載到容器中,MySQL 容器會自動運行該文件,導入我將用到的部分數據和模式。
對應的卷定義如下:
volumeMounts:
- name: mysql-persistent-storage
mountPath: /var/lib/mysql
- name: bootstrap-script
mountPath: /docker-entrypoint-initdb.d/database_setup.sql
volumes:
- name: mysql-persistent-storage
persistentVolumeClaim:
claimName: mysql-pv-claim
- name: bootstrap-script
hostPath:
path: /Users/hannibal/golang/src/github.com/Skarlso/kube-cluster-sample/database_setup.sql
type: File
(LCTT 譯註:資料庫初始化腳本需要改成對應的路徑,如果是多節點,需要是共享存儲中的路徑。另外,作者給的 sql 文件似乎有誤,person_images 表中的 person_id 列數字都小 1,作者默認 id 從 0 開始,但應該是從 1 開始)
運行如下命令查看引導腳本是否正確執行:
~/golang/src/github.com/Skarlso/kube-cluster-sample/kube_files master*
❯ kubectl run -it --rm --image=mysql:5.6 --restart=Never mysql-client -- mysql -h mysql -uroot -pyourpasswordhere kube
If you don't see a command prompt, try pressing enter.
mysql> show tables;
+----------------+
| Tables_in_kube |
+----------------+
| images |
| person |
| person_images |
+----------------+
3 rows in set (0.00 sec)
mysql>
(LCTT 譯註:上述代碼塊中的第一行是作者執行命令所在路徑,執行第二行的命令無需在該目錄中進行)
上述操作完成了資料庫服務的初始化。使用如下命令可以查看服務日誌:
kubectl logs deployment/mysql -f
NSQ 查詢
NSQ 查詢將以內部服務的形式運行。由於不需要外部訪問,這裡使用 clusterIP: None 在 Kubernetes 中將其設置為 無頭服務 ,意味著該服務不使用負載均衡模式,也不使用單獨的服務 IP。DNS 將基於服務 選擇器 。
我們的 NSQ 查詢服務對應的選擇器為:
selector:
matchLabels:
app: nsqlookup
那麼,內部 DNS 對應的實體類似於:nsqlookup.default.svc.cluster.local。
無頭服務的更多細節,可以參考:無頭服務。
NSQ 服務與 MySQL 服務大同小異,只需要少許修改即可。如前所述,我將使用 NSQ 原生的 Docker 鏡像,名稱為 nsqio/nsq。鏡像包含了全部的 nsq 命令,故 nsqd 也將使用該鏡像,只是使用的命令不同。對於 nsqlookupd,命令如下:
command: ["/nsqlookupd"]
args: ["--broadcast-address=nsqlookup.default.svc.cluster.local"]
你可能會疑惑,--broadcast-address 參數是做什麼用的?默認情況下,nsqlookup 使用容器的主機名作為廣播地址;這意味著,當用戶運行回調時,回調試圖訪問的地址類似於 http://nsqlookup-234kf-asdf:4161/lookup?topics=image,但這顯然不是我們期望的。將廣播地址設置為內部 DNS 後,回調地址將是 http://nsqlookup.default.svc.cluster.local:4161/lookup?topic=images,這正是我們期望的。
NSQ 查詢還需要轉發兩個埠,一個用於廣播,另一個用於 nsqd 守護進程的回調。在 Dockerfile 中暴露相應埠,在 Kubernetes 模板中使用它們,類似如下:
容器模板:
ports:
- containerPort: 4160
hostPort: 4160
- containerPort: 4161
hostPort: 4161
服務模板:
spec:
ports:
- name: main
protocol: TCP
port: 4160
targetPort: 4160
- name: secondary
protocol: TCP
port: 4161
targetPort: 4161
埠名稱是必須的,Kubernetes 基於名稱進行區分。(LCTT 譯註:埠名更新為作者 GitHub 對應文件中的名稱)
像之前那樣,使用如下命令創建服務:
kubectl apply -f nsqlookup.yaml
nsqlookupd 部分到此結束。截至目前,我們已經準備好兩個主要的組件。
接收器
這部分略微複雜。接收器需要完成三項工作:
- 創建一些部署
- 創建 nsq 守護進程
- 將本服務對外公開
部署
第一個要創建的部署是接收器本身,容器鏡像為 skarlso/kube-receiver-alpine。
NSQ 守護進程
接收器需要使用 NSQ 守護進程。如前所述,接收器在其內部運行一個 NSQ,這樣與 nsq 的通信可以在本地進行,無需通過網路。為了讓接收器可以這樣操作,NSQ 需要與接收器部署在同一個節點上。
NSQ 守護進程也需要一些調整的參數配置:
ports:
- containerPort: 4150
hostPort: 4150
- containerPort: 4151
hostPort: 4151
env:
- name: NSQLOOKUP_ADDRESS
value: nsqlookup.default.svc.cluster.local
- name: NSQ_BROADCAST_ADDRESS
value: nsqd.default.svc.cluster.local
command: ["/nsqd"]
args: ["--lookupd-tcp-address=$(NSQLOOKUP_ADDRESS):4160", "--broadcast-address=$(NSQ_BROADCAST_ADDRESS)"]
其中我們配置了 lookup-tcp-address 和 broadcast-address 參數。前者是 nslookup 服務的 DNS 地址,後者用於回調,就像 nsqlookupd 配置中那樣。
對外公開
下面即將創建第一個對外公開的服務。有兩種方式可供選擇。考慮到該 API 負載較高,可以使用負載均衡的方式。另外,如果希望將其部署到生產環境中的任選節點,也應該使用負載均衡方式。
但由於我使用的本地集群只有一個節點,那麼使用 NodePort 的方式就足夠了。NodePort 方式將服務暴露在對應節點的固定埠上。如果未指定埠,將從 30000-32767 數字範圍內隨機選其一個。也可以指定埠,可以在模板文件中使用 nodePort 設置即可。可以通過 <NodeIP>:<NodePort> 訪問該服務。如果使用多個節點,負載均衡可以將多個 IP 合併為一個 IP。
更多信息,請參考文檔:服務發布。
結合上面的信息,我們定義了接收器服務,對應的模板如下:
apiVersion: v1
kind: Service
metadata:
name: receiver-service
spec:
ports:
- protocol: TCP
port: 8000
targetPort: 8000
selector:
app: receiver
type: NodePort
如果希望固定使用 8000 埠,需要增加 nodePort 配置,具體如下:
apiVersion: v1
kind: Service
metadata:
name: receiver-service
spec:
ports:
- protocol: TCP
port: 8000
targetPort: 8000
selector:
app: receiver
type: NodePort
nodePort: 8000
(LCTT 譯註:雖然作者沒有寫,但我們應該知道需要運行的部署命令 kubectl apply -f receiver.yaml。)
圖片處理器
圖片處理器用於將圖片傳送至識別組件。它需要訪問 nslookupd、 mysql 以及後續部署的人臉識別服務的 gRPC 介面。事實上,這是一個無聊的服務,甚至其實並不是服務(LCTT 譯註:第一個服務是指在整個架構中,圖片處理器作為一個服務;第二個服務是指 Kubernetes 服務)。它並需要對外暴露埠,這是第一個只包含部署的組件。長話短說,下面是完整的模板:
apiVersion: apps/v1
kind: Deployment
metadata:
name: image-processor-deployment
spec:
selector:
matchLabels:
app: image-processor
replicas: 1
template:
metadata:
labels:
app: image-processor
spec:
containers:
- name: image-processor
image: skarlso/kube-processor-alpine:latest
env:
- name: MYSQL_CONNECTION
value: "mysql.default.svc.cluster.local"
- name: MYSQL_USERPASSWORD
valueFrom:
secretKeyRef:
name: kube-face-secret
key: mysql_userpassword
- name: MYSQL_PORT
# TIL: If this is 3306 without " kubectl throws an error.
value: "3306"
- name: MYSQL_DBNAME
value: kube
- name: NSQ_LOOKUP_ADDRESS
value: "nsqlookup.default.svc.cluster.local:4161"
- name: GRPC_ADDRESS
value: "face-recog.default.svc.cluster.local:50051"
文件中唯一需要提到的是用於配置應用的多個環境變數屬性,主要關注 nsqlookupd 地址 和 gRPC 地址。
運行如下命令完成部署:
kubectl apply -f image_processor.yaml
人臉識別
人臉識別服務的確包含一個 Kubernetes 服務,具體而言是一個比較簡單、僅供圖片處理器使用的服務。模板如下:
apiVersion: v1
kind: Service
metadata:
name: face-recog
spec:
ports:
- protocol: TCP
port: 50051
targetPort: 50051
selector:
app: face-recog
clusterIP: None
更有趣的是,該服務涉及兩個卷,分別為 known_people 和 unknown_people。你能猜到卷中包含什麼內容嗎?對,是圖片。known_people 卷包含所有新圖片,接收器收到圖片後將圖片發送至該卷對應的路徑,即掛載點。在本例中,掛載點為 /unknown_people,人臉識別服務需要能夠訪問該路徑。
對於 Kubernetes 和 Docker 而言,這很容易。卷可以使用掛載的 S3 或 某種 nfs,也可以是宿主機到虛擬機的本地掛載。可選方式有很多 (至少有一打那麼多)。為簡潔起見,我將使用本地掛載方式。
掛載卷分為兩步。第一步,需要在 Dockerfile 中指定卷:
VOLUME [ "/unknown_people", "/known_people" ]
第二步,就像之前為 MySQL Pod 掛載卷那樣,需要在 Kubernetes 模板中配置;相比而言,這裡使用 hostPath,而不是 MySQL 例子中的 PersistentVolumeClaim:
volumeMounts:
- name: known-people-storage
mountPath: /known_people
- name: unknown-people-storage
mountPath: /unknown_people
volumes:
- name: known-people-storage
hostPath:
path: /Users/hannibal/Temp/known_people
type: Directory
- name: unknown-people-storage
hostPath:
path: /Users/hannibal/Temp/
type: Directory
(LCTT 譯註:對於多節點模式,由於人臉識別服務和接收器服務可能不在一個節點上,故需要使用共享存儲而不是節點本地存儲。另外,出於 Python 代碼的邏輯,推薦保持兩個文件夾的嵌套結構,即 known_people 作為子目錄。)
我們還需要為 known_people 文件夾做配置設置,用於人臉識別程序。當然,使用環境變數屬性可以完成該設置:
env:
- name: KNOWN_PEOPLE
value: "/known_people"
Python 代碼按如下方式搜索圖片:
known_people = os.getenv('KNOWN_PEOPLE', 'known_people')
print("Known people images location is: %s" % known_people)
images = self.image_files_in_folder(known_people)
其中 image_files_in_folder 函數定義如下:
def image_files_in_folder(self, folder):
return [os.path.join(folder, f) for f in os.listdir(folder) if re.match(r'.*.(jpg|jpeg|png)', f, flags=re.I)]
看起來不錯。
如果接收器現在收到一個類似下面的請求(接收器會後續將其發送出去):
curl -d '{"path":"/unknown_people/unknown220.jpg"}' http://192.168.99.100:30251/image/post
圖像處理器會在 /unknown_people 目錄搜索名為 unknown220.jpg 的圖片,接著在 known_folder 文件中找到 unknown220.jpg 對應個人的圖片,最後返回匹配圖片的名稱。
查看日誌,大致信息如下:
# 接收器
❯ curl -d '{"path":"/unknown_people/unknown219.jpg"}' http://192.168.99.100:30251/image/post
got path: {Path:/unknown_people/unknown219.jpg}
image saved with id: 4
image sent to nsq
# 圖片處理器
2018/03/26 18:11:21 INF 1 [images/ch] querying nsqlookupd http://nsqlookup.default.svc.cluster.local:4161/lookup?topic=images
2018/03/26 18:11:59 Got a message: 4
2018/03/26 18:11:59 Processing image id: 4
2018/03/26 18:12:00 got person: Hannibal
2018/03/26 18:12:00 updating record with person id
2018/03/26 18:12:00 done
我們已經使用 Kubernetes 部署了應用正常工作所需的全部服務。
前端
更進一步,可以使用簡易的 Web 應用更好的顯示資料庫中的信息。這也是一個對外公開的服務,使用的參數可以參考接收器。
部署後效果如下:

回顧
到目前為止我們做了哪些操作呢?我一直在部署服務,用到的命令匯總如下:
kubectl apply -f mysql.yaml
kubectl apply -f nsqlookup.yaml
kubectl apply -f receiver.yaml
kubectl apply -f image_processor.yaml
kubectl apply -f face_recognition.yaml
kubectl apply -f frontend.yaml
命令順序可以打亂,因為除了圖片處理器的 NSQ 消費者外的應用在啟動時並不會建立連接,而且圖片處理器的 NSQ 消費者會不斷重試。
使用 kubectl get pods 查詢正在運行的 Pods,示例如下:
❯ kubectl get pods
NAME READY STATUS RESTARTS AGE
face-recog-6bf449c6f-qg5tr 1/1 Running 0 1m
image-processor-deployment-6467468c9d-cvx6m 1/1 Running 0 31s
mysql-7d667c75f4-bwghw 1/1 Running 0 36s
nsqd-584954c44c-299dz 1/1 Running 0 26s
nsqlookup-7f5bdfcb87-jkdl7 1/1 Running 0 11s
receiver-deployment-5cb4797598-sf5ds 1/1 Running 0 26s
運行 minikube service list:
❯ minikube service list
|-------------|----------------------|-----------------------------|
| NAMESPACE | NAME | URL |
|-------------|----------------------|-----------------------------|
| default | face-recog | No node port |
| default | kubernetes | No node port |
| default | mysql | No node port |
| default | nsqd | No node port |
| default | nsqlookup | No node port |
| default | receiver-service | http://192.168.99.100:30251 |
| kube-system | kube-dns | No node port |
| kube-system | kubernetes-dashboard | http://192.168.99.100:30000 |
|-------------|----------------------|-----------------------------|
滾動更新
滾動更新 過程中會發生什麼呢?
在軟體開發過程中,需要變更應用的部分組件是常有的事情。如果我希望在不影響其它組件的情況下變更一個組件,我們的集群會發生什麼變化呢?我們還需要最大程度的保持向後兼容性,以免影響用戶體驗。謝天謝地,Kubernetes 可以幫我們做到這些。
目前的 API 一次只能處理一個圖片,不能批量處理,對此我並不滿意。
代碼
目前,我們使用下面的代碼段處理單個圖片的情形:
// PostImage 對圖片提交做出響應,將圖片信息保存到資料庫中
// 並將該信息發送給 NSQ 以供後續處理使用
func PostImage(w http.ResponseWriter, r *http.Request) {
...
}
func main() {
router := mux.NewRouter()
router.HandleFunc("/image/post", PostImage).Methods("POST")
log.Fatal(http.ListenAndServe(":8000", router))
}
我們有兩種選擇。一種是增加新介面 /images/post 給用戶使用;另一種是在原介面基礎上修改。
新版客戶端有回退特性,在新介面不可用時回退使用舊介面。但舊版客戶端沒有這個特性,故我們不能馬上修改代碼邏輯。考慮如下場景,你有 90 台伺服器,計劃慢慢執行滾動更新,依次對各台伺服器進行業務更新。如果一台服務需要大約 1 分鐘更新業務,那麼整體更新完成需要大約 1 個半小時的時間(不考慮並行更新的情形)。
更新過程中,一些伺服器運行新代碼,一些伺服器運行舊代碼。用戶請求被負載均衡到各個節點,你無法控制請求到達哪台伺服器。如果客戶端的新介面請求被調度到運行舊代碼的伺服器,請求會失敗;客戶端可能會回退使用舊介面,(但由於我們已經修改舊介面,本質上仍然是調用新介面),故除非請求剛好到達到運行新代碼的伺服器,否則一直都會失敗。這裡我們假設不使用 粘性會話 。
而且,一旦所有伺服器更新完畢,舊版客戶端不再能夠使用你的服務。
這裡,你可能會說你並不需要保留舊代碼;某些情況下,確實如此。因此,我們打算直接修改舊代碼,讓其通過少量參數調用新代碼。這樣操作操作相當於移除了舊代碼。當所有客戶端遷移完畢後,這部分代碼也可以安全地刪除。
新的介面
讓我們添加新的路由方法:
...
router.HandleFunc("/images/post", PostImages).Methods("POST")
...
更新舊的路由方法,使其調用新的路由方法,修改部分如下:
// PostImage 對圖片提交做出響應,將圖片信息保存到資料庫中
// 並將該信息發送給 NSQ 以供後續處理使用
func PostImage(w http.ResponseWriter, r *http.Request) {
var p Path
err := json.NewDecoder(r.Body).Decode(&p)
if err != nil {
fmt.Fprintf(w, "got error while decoding body: %s", err)
return
}
fmt.Fprintf(w, "got path: %+vn", p)
var ps Paths
paths := make([]Path, 0)
paths = append(paths, p)
ps.Paths = paths
var pathsJSON bytes.Buffer
err = json.NewEncoder(&pathsJSON).Encode(ps)
if err != nil {
fmt.Fprintf(w, "failed to encode paths: %s", err)
return
}
r.Body = ioutil.NopCloser(&pathsJSON)
r.ContentLength = int64(pathsJSON.Len())
PostImages(w, r)
}
當然,方法名可能容易混淆,但你應該能夠理解我想表達的意思。我將請求中的單個路徑封裝成新方法所需格式,然後將其作為請求發送給新介面處理。僅此而已。在 滾動更新批量圖片的 PR 中可以找到更多的修改方式。
至此,我們使用兩種方法調用接收器:
# 單路徑模式
curl -d '{"path":"unknown4456.jpg"}' http://127.0.0.1:8000/image/post
# 多路徑模式
curl -d '{"paths":[{"path":"unknown4456.jpg"}]}' http://127.0.0.1:8000/images/post
這裡用到的客戶端是 curl。一般而言,如果客戶端本身是一個服務,我會做一些修改,在新介面返回 404 時繼續嘗試舊介面。
為了簡潔,我不打算為 NSQ 和其它組件增加批量圖片處理的能力。這些組件仍然是一次處理一個圖片。這部分修改將留給你作為擴展內容。 🙂
新鏡像
為實現滾動更新,我首先需要為接收器服務創建一個新的鏡像。新鏡像使用新標籤,告訴大家版本號為 v1.1。
docker build -t skarlso/kube-receiver-alpine:v1.1 .
新鏡像創建後,我們可以開始滾動更新了。
滾動更新
在 Kubernetes 中,可以使用多種方式完成滾動更新。
手動更新
不妨假設在我配置文件中使用的容器版本為 v1.0,那麼實現滾動更新只需運行如下命令:
kubectl rolling-update receiver --image:skarlso/kube-receiver-alpine:v1.1
如果滾動更新過程中出現問題,我們總是可以回滾:
kubectl rolling-update receiver --rollback
容器將回滾到使用上一個版本鏡像,操作簡捷無煩惱。
應用新的配置文件
手動更新的不足在於無法版本管理。
試想下面的場景。你使用手工更新的方式對若干個伺服器進行滾動升級,但其它人並不知道這件事。之後,另外一個人修改了模板文件並將其應用到集群中,更新了全部伺服器;更新過程中,突然發現服務不可用了。
長話短說,由於模板無法識別已經手動更新的伺服器,這些伺服器會按模板變更成錯誤的狀態。這種做法很危險,千萬不要這樣做。
推薦的做法是,使用新版本信息更新模板文件,然後使用 apply 命令應用模板文件。
對於滾動擴展,Kubernetes 推薦通過部署結合副本組完成。但這意味著待滾動更新的應用至少有 2 個副本,否則無法完成 (除非將 maxUnavailable 設置為 1)。我在模板文件中增加了副本數量、設置了接收器容器的新鏡像版本。
replicas: 2
...
spec:
containers:
- name: receiver
image: skarlso/kube-receiver-alpine:v1.1
...
更新過程中,你會看到如下信息:
❯ kubectl rollout status deployment/receiver-deployment
Waiting for rollout to finish: 1 out of 2 new replicas have been updated...
通過在模板中增加 strategy 段,你可以增加更多的滾動擴展配置:
strategy:
type: RollingUpdate
rollingUpdate:
maxSurge: 1
maxUnavailable: 0
關於滾動更新的更多信息,可以參考如下文檔:部署的滾動更新,部署的更新, 部署的管理 和 使用副本控制器完成滾動更新等。
MINIKUBE 用戶需要注意:由於我們使用單個主機上使用單節點配置,應用只有 1 份副本,故需要將 maxUnavailable 設置為 1。否則 Kubernetes 會阻止更新,新版本會一直處於 Pending 狀態;這是因為我們在任何時刻都不允許出現沒有(正在運行的) receiver 容器的場景。
擴展
Kubernetes 讓擴展成為相當容易的事情。由於 Kubernetes 管理整個集群,你僅需在模板文件中添加你需要的副本數目即可。
這篇文章已經比較全面了,但文章的長度也越來越長。我計劃再寫一篇後續文章,在 AWS 上使用多節點、多副本方式實現擴展。敬請期待。
清理環境
kubectl delete deployments --all
kubectl delete services -all
寫在最後的話
各位看官,本文就寫到這裡了。我們在 Kubernetes 上編寫、部署、更新和擴展(老實說,並沒有實現)了一個分散式應用。
如果你有任何疑惑,請在下面的評論區留言交流,我很樂意回答相關問題。
希望閱讀本文讓你感到愉快。我知道,這是一篇相對長的文章,我也曾經考慮進行拆分;但整合在一起的單頁教程也有其好處,例如利於搜索、保存頁面或更進一步將頁面列印為 PDF 文檔。
Gergely 感謝你閱讀本文。
via: https://skarlso.github.io/2018/03/15/kubernetes-distributed-application/
作者:hannibal 譯者:pinewall 校對:wxy
本文轉載來自 Linux 中國: https://github.com/Linux-CN/archive
對這篇文章感覺如何?
You may also like






More in:Linux中國

捐贈 Let's Encrypt,共建安全的互聯網

Let's Encrypt 正式發布,已經保護 380 萬個域名

關於Linux防火牆iptables的面試問答

Lets Encrypt 已被所有主流瀏覽器所信任









