用 Python 實現 Python 解釋器

介紹
Byterun 是一個用 Python 實現的 Python 解釋器。隨著我對 Byterun 的開發,我驚喜地的發現,這個 Python 解釋器的基礎結構用 500 行代碼就能實現。在這一章我們會搞清楚這個解釋器的結構,給你足夠探索下去的背景知識。我們的目標不是向你展示解釋器的每個細節---像編程和計算機科學其他有趣的領域一樣,你可能會投入幾年的時間去深入了解這個主題。
Byterun 是 Ned Batchelder 和我完成的,建立在 Paul Swartz 的工作之上。它的結構和主要的 Python 實現(CPython)差不多,所以理解 Byterun 會幫助你理解大多數解釋器,特別是 CPython 解釋器。(如果你不知道你用的是什麼 Python,那麼很可能它就是 CPython)。儘管 Byterun 很小,但它能執行大多數簡單的 Python 程序(這一章是基於 Python 3.5 及其之前版本生成的位元組碼的,在 Python 3.6 中生成的位元組碼有一些改變)。
Python 解釋器
在開始之前,讓我們限定一下「Pyhton 解釋器」的意思。在討論 Python 的時候,「解釋器」這個詞可以用在很多不同的地方。有的時候解釋器指的是 Python REPL,即當你在命令行下敲下 python 時所得到的互動式環境。有時候人們會或多或少的互換使用 「Python 解釋器」和「Python」來說明從頭到尾執行 Python 代碼的這一過程。在本章中,「解釋器」有一個更精確的意思:Python 程序的執行過程中的最後一步。
在解釋器接手之前,Python 會執行其他 3 個步驟:詞法分析,語法解析和編譯。這三步合起來把源代碼轉換成 代碼對象 ,它包含著解釋器可以理解的指令。而解釋器的工作就是解釋代碼對象中的指令。
你可能很奇怪執行 Python 代碼會有編譯這一步。Python 通常被稱為解釋型語言,就像 Ruby,Perl 一樣,它們和像 C,Rust 這樣的編譯型語言相對。然而,這個術語並不是它看起來的那樣精確。大多數解釋型語言包括 Python 在內,確實會有編譯這一步。而 Python 被稱為解釋型的原因是相對於編譯型語言,它在編譯這一步的工作相對較少(解釋器做相對多的工作)。在這章後面你會看到,Python 的編譯器比 C 語言編譯器需要更少的關於程序行為的信息。
Python 的 Python 解釋器
Byterun 是一個用 Python 寫的 Python 解釋器,這點可能讓你感到奇怪,但沒有比用 C 語言寫 C 語言編譯器更奇怪的了。(事實上,廣泛使用的 gcc 編譯器就是用 C 語言本身寫的)你可以用幾乎任何語言寫一個 Python 解釋器。
用 Python 寫 Python 既有優點又有缺點。最大的缺點就是速度:用 Byterun 執行代碼要比用 CPython 執行慢的多,CPython 解釋器是用 C 語言實現的,並做了認真優化。然而 Byterun 是為了學習而設計的,所以速度對我們不重要。使用 Python 最大優勢是我們可以僅僅實現解釋器,而不用擔心 Python 運行時部分,特別是對象系統。比如當 Byterun 需要創建一個類時,它就會回退到「真正」的 Python。另外一個優勢是 Byterun 很容易理解,部分原因是它是用人們很容易理解的高級語言寫的(Python !)(另外我們不會對解釋器做優化 —— 再一次,清晰和簡單比速度更重要)
構建一個解釋器
在我們考察 Byterun 代碼之前,我們需要從高層次對解釋器結構有一些了解。Python 解釋器是如何工作的?
Python 解釋器是一個 虛擬機 ,是一個模擬真實計算機的軟體。我們這個虛擬機是 棧機器 ,它用幾個棧來完成操作(與之相對的是 寄存器機器 ,它從特定的內存地址讀寫數據)。
Python 解釋器是一個 位元組碼解釋器 :它的輸入是一些稱作 位元組碼 的指令集。當你寫 Python 代碼時,詞法分析器、語法解析器和編譯器會生成 代碼對象 讓解釋器去操作。每個代碼對象都包含一個要被執行的指令集 —— 它就是位元組碼 —— 以及還有一些解釋器需要的信息。位元組碼是 Python 代碼的一個 中間層表示 :它以一種解釋器可以理解的方式來表示源代碼。這和彙編語言作為 C 語言和機器語言的中間表示很類似。
微型解釋器
為了讓說明更具體,讓我們從一個非常小的解釋器開始。它只能計算兩個數的和,只能理解三個指令。它執行的所有代碼只是這三個指令的不同組合。下面就是這三個指令:
LOAD_VALUEADD_TWO_VALUESPRINT_ANSWER
我們不關心詞法、語法和編譯,所以我們也不在乎這些指令集是如何產生的。你可以想像,當你寫下 7 + 5,然後一個編譯器為你生成那三個指令的組合。如果你有一個合適的編譯器,你甚至可以用 Lisp 的語法來寫,只要它能生成相同的指令。
假設
7 + 5
生成這樣的指令集:
what_to_execute = {
"instructions": [("LOAD_VALUE", 0), # the first number
("LOAD_VALUE", 1), # the second number
("ADD_TWO_VALUES", None),
("PRINT_ANSWER", None)],
"numbers": [7, 5] }
Python 解釋器是一個 棧機器 ,所以它必須通過操作棧來完成這個加法(見下圖)。解釋器先執行第一條指令,LOAD_VALUE,把第一個數壓到棧中。接著它把第二個數也壓到棧中。然後,第三條指令,ADD_TWO_VALUES,先把兩個數從棧中彈出,加起來,再把結果壓入棧中。最後一步,把結果彈出並輸出。
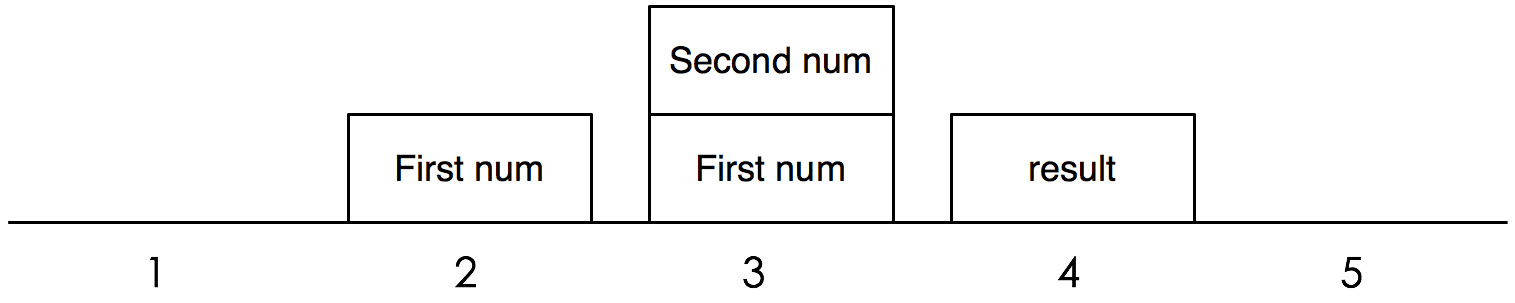
LOAD_VALUE這條指令告訴解釋器把一個數壓入棧中,但指令本身並沒有指明這個數是多少。指令需要一個額外的信息告訴解釋器去哪裡找到這個數。所以我們的指令集有兩個部分:指令本身和一個常量列表。(在 Python 中,位元組碼就是我們所稱的「指令」,而解釋器「執行」的是代碼對象。)
為什麼不把數字直接嵌入指令之中?想像一下,如果我們加的不是數字,而是字元串。我們可不想把字元串這樣的東西加到指令中,因為它可以有任意的長度。另外,我們這種設計也意味著我們只需要對象的一份拷貝,比如這個加法 7 + 7, 現在常量表 "numbers"只需包含一個[7]。
你可能會想為什麼會需要除了ADD_TWO_VALUES之外的指令。的確,對於我們兩個數加法,這個例子是有點人為製作的意思。然而,這個指令卻是建造更複雜程序的輪子。比如,就我們目前定義的三個指令,只要給出正確的指令組合,我們可以做三個數的加法,或者任意個數的加法。同時,棧提供了一個清晰的方法去跟蹤解釋器的狀態,這為我們增長的複雜性提供了支持。
現在讓我們來完成我們的解釋器。解釋器對象需要一個棧,它可以用一個列表來表示。它還需要一個方法來描述怎樣執行每條指令。比如,LOAD_VALUE會把一個值壓入棧中。
class Interpreter:
def __init__(self):
self.stack = []
def LOAD_VALUE(self, number):
self.stack.append(number)
def PRINT_ANSWER(self):
answer = self.stack.pop()
print(answer)
def ADD_TWO_VALUES(self):
first_num = self.stack.pop()
second_num = self.stack.pop()
total = first_num + second_num
self.stack.append(total)
這三個方法完成了解釋器所理解的三條指令。但解釋器還需要一樣東西:一個能把所有東西結合在一起並執行的方法。這個方法就叫做 run_code,它把我們前面定義的字典結構 what-to-execute 作為參數,循環執行裡面的每條指令,如果指令有參數就處理參數,然後調用解釋器對象中相應的方法。
def run_code(self, what_to_execute):
instructions = what_to_execute["instructions"]
numbers = what_to_execute["numbers"]
for each_step in instructions:
instruction, argument = each_step
if instruction == "LOAD_VALUE":
number = numbers[argument]
self.LOAD_VALUE(number)
elif instruction == "ADD_TWO_VALUES":
self.ADD_TWO_VALUES()
elif instruction == "PRINT_ANSWER":
self.PRINT_ANSWER()
為了測試,我們創建一個解釋器對象,然後用前面定義的 7 + 5 的指令集來調用 run_code。
interpreter = Interpreter()
interpreter.run_code(what_to_execute)
顯然,它會輸出 12。
儘管我們的解釋器功能十分受限,但這個過程幾乎和真正的 Python 解釋器處理加法是一樣的。這裡,我們還有幾點要注意。
首先,一些指令需要參數。在真正的 Python 位元組碼當中,大概有一半的指令有參數。像我們的例子一樣,參數和指令打包在一起。注意指令的參數和傳遞給對應方法的參數是不同的。
第二,指令ADD_TWO_VALUES不需要任何參數,它從解釋器棧中彈出所需的值。這正是以基於棧的解釋器的特點。
記得我們說過只要給出合適的指令集,不需要對解釋器做任何改變,我們就能做多個數的加法。考慮下面的指令集,你覺得會發生什麼?如果你有一個合適的編譯器,什麼代碼才能編譯出下面的指令集?
what_to_execute = {
"instructions": [("LOAD_VALUE", 0),
("LOAD_VALUE", 1),
("ADD_TWO_VALUES", None),
("LOAD_VALUE", 2),
("ADD_TWO_VALUES", None),
("PRINT_ANSWER", None)],
"numbers": [7, 5, 8] }
從這點出發,我們開始看到這種結構的可擴展性:我們可以通過向解釋器對象增加方法來描述更多的操作(只要有一個編譯器能為我們生成組織良好的指令集就行)。
變數
接下來給我們的解釋器增加變數的支持。我們需要一個保存變數值的指令 STORE_NAME;一個取變數值的指令LOAD_NAME;和一個變數到值的映射關係。目前,我們會忽略命名空間和作用域,所以我們可以把變數和值的映射直接存儲在解釋器對象中。最後,我們要保證what_to_execute除了一個常量列表,還要有個變數名字的列表。
>>> def s():
... a = 1
... b = 2
... print(a + b)
# a friendly compiler transforms `s` into:
what_to_execute = {
"instructions": [("LOAD_VALUE", 0),
("STORE_NAME", 0),
("LOAD_VALUE", 1),
("STORE_NAME", 1),
("LOAD_NAME", 0),
("LOAD_NAME", 1),
("ADD_TWO_VALUES", None),
("PRINT_ANSWER", None)],
"numbers": [1, 2],
"names": ["a", "b"] }
我們的新的實現在下面。為了跟蹤哪個名字綁定到哪個值,我們在__init__方法中增加一個environment字典。我們也增加了STORE_NAME和LOAD_NAME方法,它們獲得變數名,然後從environment字典中設置或取出這個變數值。
現在指令的參數就有兩個不同的意思,它可能是numbers列表的索引,也可能是names列表的索引。解釋器通過檢查所執行的指令就能知道是那種參數。而我們打破這種邏輯 ,把指令和它所用何種參數的映射關係放在另一個單獨的方法中。
class Interpreter:
def __init__(self):
self.stack = []
self.environment = {}
def STORE_NAME(self, name):
val = self.stack.pop()
self.environment[name] = val
def LOAD_NAME(self, name):
val = self.environment[name]
self.stack.append(val)
def parse_argument(self, instruction, argument, what_to_execute):
""" Understand what the argument to each instruction means."""
numbers = ["LOAD_VALUE"]
names = ["LOAD_NAME", "STORE_NAME"]
if instruction in numbers:
argument = what_to_execute["numbers"][argument]
elif instruction in names:
argument = what_to_execute["names"][argument]
return argument
def run_code(self, what_to_execute):
instructions = what_to_execute["instructions"]
for each_step in instructions:
instruction, argument = each_step
argument = self.parse_argument(instruction, argument, what_to_execute)
if instruction == "LOAD_VALUE":
self.LOAD_VALUE(argument)
elif instruction == "ADD_TWO_VALUES":
self.ADD_TWO_VALUES()
elif instruction == "PRINT_ANSWER":
self.PRINT_ANSWER()
elif instruction == "STORE_NAME":
self.STORE_NAME(argument)
elif instruction == "LOAD_NAME":
self.LOAD_NAME(argument)
僅僅五個指令,run_code這個方法已經開始變得冗長了。如果保持這種結構,那麼每條指令都需要一個if分支。這裡,我們要利用 Python 的動態方法查找。我們總會給一個稱為FOO的指令定義一個名為FOO的方法,這樣我們就可用 Python 的getattr函數在運行時動態查找方法,而不用這個大大的分支結構。run_code方法現在是這樣:
def execute(self, what_to_execute):
instructions = what_to_execute["instructions"]
for each_step in instructions:
instruction, argument = each_step
argument = self.parse_argument(instruction, argument, what_to_execute)
bytecode_method = getattr(self, instruction)
if argument is None:
bytecode_method()
else:
bytecode_method(argument)
真實的 Python 位元組碼
現在,放棄我們的小指令集,去看看真正的 Python 位元組碼。位元組碼的結構和我們的小解釋器的指令集差不多,除了位元組碼用一個位元組而不是一個名字來代表這條指令。為了理解它的結構,我們將考察一個函數的位元組碼。考慮下面這個例子:
>>> def cond():
... x = 3
... if x < 5:
... return 'yes'
... else:
... return 'no'
...
Python 在運行時會暴露一大批內部信息,並且我們可以通過 REPL 直接訪問這些信息。對於函數對象cond,cond.__code__是與其關聯的代碼對象,而cond.__code__.co_code就是它的位元組碼。當你寫 Python 代碼時,你永遠也不會想直接使用這些屬性,但是這可以讓我們做出各種惡作劇,同時也可以看看內部機制。
>>> cond.__code__.co_code # the bytecode as raw bytes
b'dx01x00}x00x00|x00x00dx02x00kx00x00rx16x00dx03x00Sdx04x00Sdx00
x00S'
>>> list(cond.__code__.co_code) # the bytecode as numbers
[100, 1, 0, 125, 0, 0, 124, 0, 0, 100, 2, 0, 107, 0, 0, 114, 22, 0, 100, 3, 0, 83,
100, 4, 0, 83, 100, 0, 0, 83]
當我們直接輸出這個位元組碼,它看起來完全無法理解 —— 唯一我們了解的是它是一串位元組。很幸運,我們有一個很強大的工具可以用:Python 標準庫中的dis模塊。
dis是一個位元組碼反彙編器。反彙編器以為機器而寫的底層代碼作為輸入,比如彙編代碼和位元組碼,然後以人類可讀的方式輸出。當我們運行dis.dis,它輸出每個位元組碼的解釋。
>>> dis.dis(cond)
2 0 LOAD_CONST 1 (3)
3 STORE_FAST 0 (x)
3 6 LOAD_FAST 0 (x)
9 LOAD_CONST 2 (5)
12 COMPARE_OP 0 (<)
15 POP_JUMP_IF_FALSE 22
4 18 LOAD_CONST 3 ('yes')
21 RETURN_VALUE
6 >> 22 LOAD_CONST 4 ('no')
25 RETURN_VALUE
26 LOAD_CONST 0 (None)
29 RETURN_VALUE
這些都是什麼意思?讓我們以第一條指令LOAD_CONST為例子。第一列的數字(2)表示對應源代碼的行數。第二列的數字是位元組碼的索引,告訴我們指令LOAD_CONST在位置 0 。第三列是指令本身對應的人類可讀的名字。如果第四列存在,它表示指令的參數。如果第五列存在,它是一個關於參數是什麼的提示。
考慮這個位元組碼的前幾個位元組:[100, 1, 0, 125, 0, 0]。這 6 個位元組表示兩條帶參數的指令。我們可以使用dis.opname,一個位元組到可讀字元串的映射,來找到指令 100 和指令 125 代表的是什麼:
>>> dis.opname[100]
'LOAD_CONST'
>>> dis.opname[125]
'STORE_FAST'
第二和第三個位元組 —— 1 、0 ——是LOAD_CONST的參數,第五和第六個位元組 —— 0、0 —— 是STORE_FAST的參數。就像我們前面的小例子,LOAD_CONST需要知道的到哪去找常量,STORE_FAST需要知道要存儲的名字。(Python 的LOAD_CONST和我們小例子中的LOAD_VALUE一樣,LOAD_FAST和LOAD_NAME一樣)。所以這六個位元組代表第一行源代碼x = 3 (為什麼用兩個位元組表示指令的參數?如果 Python 使用一個位元組,每個代碼對象你只能有 256 個常量/名字,而用兩個位元組,就增加到了 256 的平方,65536個)。
條件語句與循環語句
到目前為止,我們的解釋器只能一條接著一條的執行指令。這有個問題,我們經常會想多次執行某個指令,或者在特定的條件下跳過它們。為了可以寫循環和分支結構,解釋器必須能夠在指令中跳轉。在某種程度上,Python 在位元組碼中使用GOTO語句來處理循環和分支!讓我們再看一個cond函數的反彙編結果:
>>> dis.dis(cond)
2 0 LOAD_CONST 1 (3)
3 STORE_FAST 0 (x)
3 6 LOAD_FAST 0 (x)
9 LOAD_CONST 2 (5)
12 COMPARE_OP 0 (<)
15 POP_JUMP_IF_FALSE 22
4 18 LOAD_CONST 3 ('yes')
21 RETURN_VALUE
6 >> 22 LOAD_CONST 4 ('no')
25 RETURN_VALUE
26 LOAD_CONST 0 (None)
29 RETURN_VALUE
第三行的條件表達式if x < 5被編譯成四條指令:LOAD_FAST、 LOAD_CONST、 COMPARE_OP和 POP_JUMP_IF_FALSE。x < 5對應載入x、載入 5、比較這兩個值。指令POP_JUMP_IF_FALSE完成這個if語句。這條指令把棧頂的值彈出,如果值為真,什麼都不發生。如果值為假,解釋器會跳轉到另一條指令。
這條將被載入的指令稱為跳轉目標,它作為指令POP_JUMP的參數。這裡,跳轉目標是 22,索引為 22 的指令是LOAD_CONST,對應源碼的第 6 行。(dis用>>標記跳轉目標。)如果X < 5為假,解釋器會忽略第四行(return yes),直接跳轉到第6行(return "no")。因此解釋器通過跳轉指令選擇性的執行指令。
Python 的循環也依賴於跳轉。在下面的位元組碼中,while x < 5這一行產生了和if x < 10幾乎一樣的位元組碼。在這兩種情況下,解釋器都是先執行比較,然後執行POP_JUMP_IF_FALSE來控制下一條執行哪個指令。第四行的最後一條位元組碼JUMP_ABSOLUT(循環體結束的地方),讓解釋器返回到循環開始的第 9 條指令處。當 x < 10變為假,POP_JUMP_IF_FALSE會讓解釋器跳到循環的終止處,第 34 條指令。
>>> def loop():
... x = 1
... while x < 5:
... x = x + 1
... return x
...
>>> dis.dis(loop)
2 0 LOAD_CONST 1 (1)
3 STORE_FAST 0 (x)
3 6 SETUP_LOOP 26 (to 35)
>> 9 LOAD_FAST 0 (x)
12 LOAD_CONST 2 (5)
15 COMPARE_OP 0 (<)
18 POP_JUMP_IF_FALSE 34
4 21 LOAD_FAST 0 (x)
24 LOAD_CONST 1 (1)
27 BINARY_ADD
28 STORE_FAST 0 (x)
31 JUMP_ABSOLUTE 9
>> 34 POP_BLOCK
5 >> 35 LOAD_FAST 0 (x)
38 RETURN_VALUE
探索位元組碼
我希望你用dis.dis來試試你自己寫的函數。一些有趣的問題值得探索:
- 對解釋器而言 for 循環和 while 循環有什麼不同?
- 能不能寫出兩個不同函數,卻能產生相同的位元組碼?
elif是怎麼工作的?列表推導呢?
幀
到目前為止,我們已經知道了 Python 虛擬機是一個棧機器。它能順序執行指令,在指令間跳轉,壓入或彈出棧值。但是這和我們期望的解釋器還有一定距離。在前面的那個例子中,最後一條指令是RETURN_VALUE,它和return語句相對應。但是它返回到哪裡去呢?
為了回答這個問題,我們必須再增加一層複雜性: 幀 。一個幀是一些信息的集合和代碼的執行上下文。幀在 Python 代碼執行時動態地創建和銷毀。每個幀對應函數的一次調用 —— 所以每個幀只有一個代碼對象與之關聯,而一個代碼對象可以有多個幀。比如你有一個函數遞歸的調用自己 10 次,這會產生 11 個幀,每次調用對應一個,再加上啟動模塊對應的一個幀。總的來說,Python 程序的每個作用域都有一個幀,比如,模塊、函數、類定義。
幀存在於 調用棧 中,一個和我們之前討論的完全不同的棧。(你最熟悉的棧就是調用棧,就是你經常看到的異常回溯,每個以"File 'program.py'"開始的回溯對應一個幀。)解釋器在執行位元組碼時操作的棧,我們叫它 數據棧 。其實還有第三個棧,叫做 塊棧 ,用於特定的控制流塊,比如循環和異常處理。調用棧中的每個幀都有它自己的數據棧和塊棧。
讓我們用一個具體的例子來說明一下。假設 Python 解釋器執行到下面標記為 3 的地方。解釋器正處於foo函數的調用中,它接著調用bar。下面是幀調用棧、塊棧和數據棧的示意圖。我們感興趣的是解釋器先從最底下的foo()開始,接著執行foo的函數體,然後到達bar。
>>> def bar(y):
... z = y + 3 # <--- (3) ... and the interpreter is here.
... return z
...
>>> def foo():
... a = 1
... b = 2
... return a + bar(b) # <--- (2) ... which is returning a call to bar ...
...
>>> foo() # <--- (1) We're in the middle of a call to foo ...
3
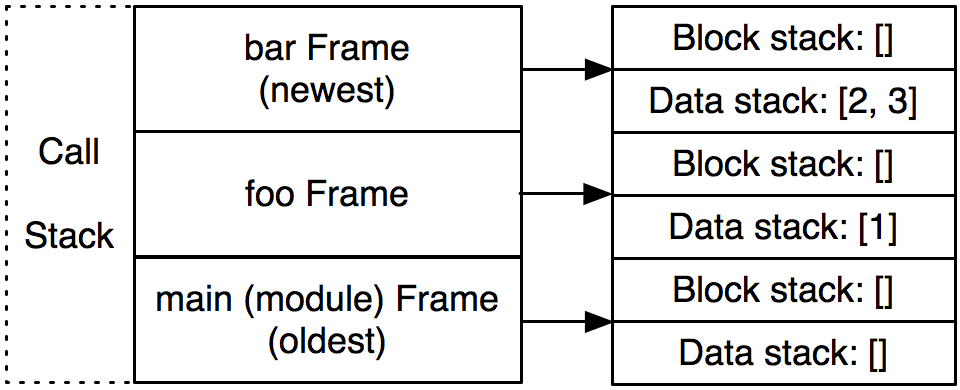
現在,解釋器處於bar函數的調用中。調用棧中有 3 個幀:一個對應於模塊層,一個對應函數foo,另一個對應函數bar。(見上圖)一旦bar返回,與它對應的幀就會從調用棧中彈出並丟棄。
位元組碼指令RETURN_VALUE告訴解釋器在幀之間傳遞一個值。首先,它把位於調用棧棧頂的幀中的數據棧的棧頂值彈出。然後把整個幀彈出丟棄。最後把這個值壓到下一個幀的數據棧中。
當 Ned Batchelder 和我在寫 Byterun 時,很長一段時間我們的實現中一直有個重大的錯誤。我們整個虛擬機中只有一個數據棧,而不是每個幀都有一個。我們寫了很多測試代碼,同時在 Byterun 和真正的 Python 上運行,希望得到一致結果。我們幾乎通過了所有測試,只有一樣東西不能通過,那就是 生成器 。最後,通過仔細的閱讀 CPython 的源碼,我們發現了錯誤所在(感謝 Michael Arntzenius 對這個 bug 的洞悉)。把數據棧移到每個幀就解決了這個問題。
回頭在看看這個 bug,我驚訝的發現 Python 真的很少依賴於每個幀有一個數據棧這個特性。在 Python 中幾乎所有的操作都會清空數據棧,所以所有的幀公用一個數據棧是沒問題的。在上面的例子中,當bar執行完後,它的數據棧為空。即使foo公用這一個棧,它的值也不會受影響。然而,對應生成器,它的一個關鍵的特點是它能暫停一個幀的執行,返回到其他的幀,一段時間後它能返回到原來的幀,並以它離開時的相同狀態繼續執行。
Byterun
現在我們有足夠的 Python 解釋器的知識背景去考察 Byterun。
Byterun 中有四種對象。
VirtualMachine類,它管理高層結構,尤其是幀調用棧,並包含了指令到操作的映射。這是一個比前面Inteprter對象更複雜的版本。Frame類,每個Frame類都有一個代碼對象,並且管理著其他一些必要的狀態位,尤其是全局和局部命名空間、指向調用它的整的指針和最後執行的位元組碼指令。Function類,它被用來代替真正的 Python 函數。回想一下,調用函數時會創建一個新的幀。我們自己實現了Function,以便我們控制新的Frame的創建。Block類,它只是包裝了塊的 3 個屬性。(塊的細節不是解釋器的核心,我們不會花時間在它身上,把它列在這裡,是因為 Byterun 需要它。)
VirtualMachine 類
每次程序運行時只會創建一個VirtualMachine實例,因為我們只有一個 Python 解釋器。VirtualMachine 保存調用棧、異常狀態、在幀之間傳遞的返回值。它的入口點是run_code方法,它以編譯後的代碼對象為參數,以創建一個幀為開始,然後運行這個幀。這個幀可能再創建出新的幀;調用棧隨著程序的運行而增長和縮短。當第一個幀返回時,執行結束。
class VirtualMachineError(Exception):
pass
class VirtualMachine(object):
def __init__(self):
self.frames = [] # The call stack of frames.
self.frame = None # The current frame.
self.return_value = None
self.last_exception = None
def run_code(self, code, global_names=None, local_names=None):
""" An entry point to execute code using the virtual machine."""
frame = self.make_frame(code, global_names=global_names,
local_names=local_names)
self.run_frame(frame)
Frame 類
接下來,我們來寫Frame對象。幀是一個屬性的集合,它沒有任何方法。前面提到過,這些屬性包括由編譯器生成的代碼對象;局部、全局和內置命名空間;前一個幀的引用;一個數據棧;一個塊棧;最後執行的指令指針。(對於內置命名空間我們需要多做一點工作,Python 在不同模塊中對這個命名空間有不同的處理;但這個細節對我們的虛擬機不重要。)
class Frame(object):
def __init__(self, code_obj, global_names, local_names, prev_frame):
self.code_obj = code_obj
self.global_names = global_names
self.local_names = local_names
self.prev_frame = prev_frame
self.stack = []
if prev_frame:
self.builtin_names = prev_frame.builtin_names
else:
self.builtin_names = local_names['__builtins__']
if hasattr(self.builtin_names, '__dict__'):
self.builtin_names = self.builtin_names.__dict__
self.last_instruction = 0
self.block_stack = []
接著,我們在虛擬機中增加對幀的操作。這有 3 個幫助函數:一個創建新的幀的方法(它負責為新的幀找到名字空間),和壓棧和出棧的方法。第四個函數,run_frame,完成執行幀的主要工作,待會我們再討論這個方法。
class VirtualMachine(object):
[... 刪節 ...]
# Frame manipulation
def make_frame(self, code, callargs={}, global_names=None, local_names=None):
if global_names is not None and local_names is not None:
local_names = global_names
elif self.frames:
global_names = self.frame.global_names
local_names = {}
else:
global_names = local_names = {
'__builtins__': __builtins__,
'__name__': '__main__',
'__doc__': None,
'__package__': None,
}
local_names.update(callargs)
frame = Frame(code, global_names, local_names, self.frame)
return frame
def push_frame(self, frame):
self.frames.append(frame)
self.frame = frame
def pop_frame(self):
self.frames.pop()
if self.frames:
self.frame = self.frames[-1]
else:
self.frame = None
def run_frame(self):
pass
# we'll come back to this shortly
Function 類
Function的實現有點曲折,但是大部分的細節對理解解釋器不重要。重要的是當調用函數時 —— 即調用 __call__方法 —— 它創建一個新的Frame並運行它。
class Function(object):
"""
Create a realistic function object, defining the things the interpreter expects.
"""
__slots__ = [
'func_code', 'func_name', 'func_defaults', 'func_globals',
'func_locals', 'func_dict', 'func_closure',
'__name__', '__dict__', '__doc__',
'_vm', '_func',
]
def __init__(self, name, code, globs, defaults, closure, vm):
"""You don't need to follow this closely to understand the interpreter."""
self._vm = vm
self.func_code = code
self.func_name = self.__name__ = name or code.co_name
self.func_defaults = tuple(defaults)
self.func_globals = globs
self.func_locals = self._vm.frame.f_locals
self.__dict__ = {}
self.func_closure = closure
self.__doc__ = code.co_consts[0] if code.co_consts else None
# Sometimes, we need a real Python function. This is for that.
kw = {
'argdefs': self.func_defaults,
}
if closure:
kw['closure'] = tuple(make_cell(0) for _ in closure)
self._func = types.FunctionType(code, globs, **kw)
def __call__(self, *args, **kwargs):
"""When calling a Function, make a new frame and run it."""
callargs = inspect.getcallargs(self._func, *args, **kwargs)
# Use callargs to provide a mapping of arguments: values to pass into the new
# frame.
frame = self._vm.make_frame(
self.func_code, callargs, self.func_globals, {}
)
return self._vm.run_frame(frame)
def make_cell(value):
"""Create a real Python closure and grab a cell."""
# Thanks to Alex Gaynor for help with this bit of twistiness.
fn = (lambda x: lambda: x)(value)
return fn.__closure__[0]
接著,回到VirtualMachine對象,我們對數據棧的操作也增加一些幫助方法。位元組碼操作的棧總是在當前幀的數據棧。這些幫助函數讓我們的POP_TOP、LOAD_FAST以及其他操作棧的指令的實現可讀性更高。
class VirtualMachine(object):
[... 刪節 ...]
# Data stack manipulation
def top(self):
return self.frame.stack[-1]
def pop(self):
return self.frame.stack.pop()
def push(self, *vals):
self.frame.stack.extend(vals)
def popn(self, n):
"""Pop a number of values from the value stack.
A list of `n` values is returned, the deepest value first.
"""
if n:
ret = self.frame.stack[-n:]
self.frame.stack[-n:] = []
return ret
else:
return []
在我們運行幀之前,我們還需兩個方法。
第一個方法,parse_byte_and_args 以一個位元組碼為輸入,先檢查它是否有參數,如果有,就解析它的參數。這個方法同時也更新幀的last_instruction屬性,它指向最後執行的指令。一條沒有參數的指令只有一個位元組長度,而有參數的位元組有3個位元組長。參數的意義依賴於指令是什麼。比如,前面說過,指令POP_JUMP_IF_FALSE,它的參數指的是跳轉目標。BUILD_LIST,它的參數是列表的個數。LOAD_CONST,它的參數是常量的索引。
一些指令用簡單的數字作為參數。對於另一些,虛擬機需要一點努力去發現它含意。標準庫中的dis模塊中有一個備忘單,它解釋什麼參數有什麼意思,這讓我們的代碼更加簡潔。比如,列表dis.hasname告訴我們LOAD_NAME、 IMPORT_NAME、LOAD_GLOBAL,以及另外的 9 個指令的參數都有同樣的意義:對於這些指令,它們的參數代表了代碼對象中的名字列表的索引。
class VirtualMachine(object):
[... 刪節 ...]
def parse_byte_and_args(self):
f = self.frame
opoffset = f.last_instruction
byteCode = f.code_obj.co_code[opoffset]
f.last_instruction += 1
byte_name = dis.opname[byteCode]
if byteCode >= dis.HAVE_ARGUMENT:
# index into the bytecode
arg = f.code_obj.co_code[f.last_instruction:f.last_instruction+2]
f.last_instruction += 2 # advance the instruction pointer
arg_val = arg[0] + (arg[1] * 256)
if byteCode in dis.hasconst: # Look up a constant
arg = f.code_obj.co_consts[arg_val]
elif byteCode in dis.hasname: # Look up a name
arg = f.code_obj.co_names[arg_val]
elif byteCode in dis.haslocal: # Look up a local name
arg = f.code_obj.co_varnames[arg_val]
elif byteCode in dis.hasjrel: # Calculate a relative jump
arg = f.last_instruction + arg_val
else:
arg = arg_val
argument = [arg]
else:
argument = []
return byte_name, argument
下一個方法是dispatch,它查找給定的指令並執行相應的操作。在 CPython 中,這個分派函數用一個巨大的 switch 語句實現,有超過 1500 行的代碼。幸運的是,我們用的是 Python,我們的代碼會簡潔的多。我們會為每一個位元組碼名字定義一個方法,然後用getattr來查找。就像我們前面的小解釋器一樣,如果一條指令叫做FOO_BAR,那麼它對應的方法就是byte_FOO_BAR。現在,我們先把這些方法當做一個黑盒子。每個指令方法都會返回None或者一個字元串why,有些情況下虛擬機需要這個額外why信息。這些指令方法的返回值,僅作為解釋器狀態的內部指示,千萬不要和執行幀的返回值相混淆。
class VirtualMachine(object):
[... 刪節 ...]
def dispatch(self, byte_name, argument):
""" Dispatch by bytename to the corresponding methods.
Exceptions are caught and set on the virtual machine."""
# When later unwinding the block stack,
# we need to keep track of why we are doing it.
why = None
try:
bytecode_fn = getattr(self, 'byte_%s' % byte_name, None)
if bytecode_fn is None:
if byte_name.startswith('UNARY_'):
self.unaryOperator(byte_name[6:])
elif byte_name.startswith('BINARY_'):
self.binaryOperator(byte_name[7:])
else:
raise VirtualMachineError(
"unsupported bytecode type: %s" % byte_name
)
else:
why = bytecode_fn(*argument)
except:
# deal with exceptions encountered while executing the op.
self.last_exception = sys.exc_info()[:2] + (None,)
why = 'exception'
return why
def run_frame(self, frame):
"""Run a frame until it returns (somehow).
Exceptions are raised, the return value is returned.
"""
self.push_frame(frame)
while True:
byte_name, arguments = self.parse_byte_and_args()
why = self.dispatch(byte_name, arguments)
# Deal with any block management we need to do
while why and frame.block_stack:
why = self.manage_block_stack(why)
if why:
break
self.pop_frame()
if why == 'exception':
exc, val, tb = self.last_exception
e = exc(val)
e.__traceback__ = tb
raise e
return self.return_value
Block 類
在我們完成每個位元組碼方法前,我們簡單的討論一下塊。一個塊被用於某種控制流,特別是異常處理和循環。它負責保證當操作完成後數據棧處於正確的狀態。比如,在一個循環中,一個特殊的迭代器會存在棧中,當循環完成時它從棧中彈出。解釋器需要檢查循環仍在繼續還是已經停止。
為了跟蹤這些額外的信息,解釋器設置了一個標誌來指示它的狀態。我們用一個變數why實現這個標誌,它可以是None或者是下面幾個字元串之一:"continue"、"break"、"excption"、return。它們指示對塊棧和數據棧進行什麼操作。回到我們迭代器的例子,如果塊棧的棧頂是一個loop塊,why的代碼是continue,迭代器就應該保存在數據棧上,而如果why是break,迭代器就會被彈出。
塊操作的細節比這個還要繁瑣,我們不會花時間在這上面,但是有興趣的讀者值得仔細的看看。
Block = collections.namedtuple("Block", "type, handler, stack_height")
class VirtualMachine(object):
[... 刪節 ...]
# Block stack manipulation
def push_block(self, b_type, handler=None):
level = len(self.frame.stack)
self.frame.block_stack.append(Block(b_type, handler, stack_height))
def pop_block(self):
return self.frame.block_stack.pop()
def unwind_block(self, block):
"""Unwind the values on the data stack corresponding to a given block."""
if block.type == 'except-handler':
# The exception itself is on the stack as type, value, and traceback.
offset = 3
else:
offset = 0
while len(self.frame.stack) > block.level + offset:
self.pop()
if block.type == 'except-handler':
traceback, value, exctype = self.popn(3)
self.last_exception = exctype, value, traceback
def manage_block_stack(self, why):
""" """
frame = self.frame
block = frame.block_stack[-1]
if block.type == 'loop' and why == 'continue':
self.jump(self.return_value)
why = None
return why
self.pop_block()
self.unwind_block(block)
if block.type == 'loop' and why == 'break':
why = None
self.jump(block.handler)
return why
if (block.type in ['setup-except', 'finally'] and why == 'exception'):
self.push_block('except-handler')
exctype, value, tb = self.last_exception
self.push(tb, value, exctype)
self.push(tb, value, exctype) # yes, twice
why = None
self.jump(block.handler)
return why
elif block.type == 'finally':
if why in ('return', 'continue'):
self.push(self.return_value)
self.push(why)
why = None
self.jump(block.handler)
return why
return why
指令
剩下了的就是完成那些指令方法了:byte_LOAD_FAST、byte_BINARY_MODULO等等。而這些指令的實現並不是很有趣,這裡我們只展示了一小部分,完整的實現在 GitHub 上。(這裡包括的指令足夠執行我們前面所述的所有代碼了。)
class VirtualMachine(object):
[... 刪節 ...]
## Stack manipulation
def byte_LOAD_CONST(self, const):
self.push(const)
def byte_POP_TOP(self):
self.pop()
## Names
def byte_LOAD_NAME(self, name):
frame = self.frame
if name in frame.f_locals:
val = frame.f_locals[name]
elif name in frame.f_globals:
val = frame.f_globals[name]
elif name in frame.f_builtins:
val = frame.f_builtins[name]
else:
raise NameError("name '%s' is not defined" % name)
self.push(val)
def byte_STORE_NAME(self, name):
self.frame.f_locals[name] = self.pop()
def byte_LOAD_FAST(self, name):
if name in self.frame.f_locals:
val = self.frame.f_locals[name]
else:
raise UnboundLocalError(
"local variable '%s' referenced before assignment" % name
)
self.push(val)
def byte_STORE_FAST(self, name):
self.frame.f_locals[name] = self.pop()
def byte_LOAD_GLOBAL(self, name):
f = self.frame
if name in f.f_globals:
val = f.f_globals[name]
elif name in f.f_builtins:
val = f.f_builtins[name]
else:
raise NameError("global name '%s' is not defined" % name)
self.push(val)
## Operators
BINARY_OPERATORS = {
'POWER': pow,
'MULTIPLY': operator.mul,
'FLOOR_DIVIDE': operator.floordiv,
'TRUE_DIVIDE': operator.truediv,
'MODULO': operator.mod,
'ADD': operator.add,
'SUBTRACT': operator.sub,
'SUBSCR': operator.getitem,
'LSHIFT': operator.lshift,
'RSHIFT': operator.rshift,
'AND': operator.and_,
'XOR': operator.xor,
'OR': operator.or_,
}
def binaryOperator(self, op):
x, y = self.popn(2)
self.push(self.BINARY_OPERATORS[op](x, y))
COMPARE_OPERATORS = [
operator.lt,
operator.le,
operator.eq,
operator.ne,
operator.gt,
operator.ge,
lambda x, y: x in y,
lambda x, y: x not in y,
lambda x, y: x is y,
lambda x, y: x is not y,
lambda x, y: issubclass(x, Exception) and issubclass(x, y),
]
def byte_COMPARE_OP(self, opnum):
x, y = self.popn(2)
self.push(self.COMPARE_OPERATORS[opnum](x, y))
## Attributes and indexing
def byte_LOAD_ATTR(self, attr):
obj = self.pop()
val = getattr(obj, attr)
self.push(val)
def byte_STORE_ATTR(self, name):
val, obj = self.popn(2)
setattr(obj, name, val)
## Building
def byte_BUILD_LIST(self, count):
elts = self.popn(count)
self.push(elts)
def byte_BUILD_MAP(self, size):
self.push({})
def byte_STORE_MAP(self):
the_map, val, key = self.popn(3)
the_map[key] = val
self.push(the_map)
def byte_LIST_APPEND(self, count):
val = self.pop()
the_list = self.frame.stack[-count] # peek
the_list.append(val)
## Jumps
def byte_JUMP_FORWARD(self, jump):
self.jump(jump)
def byte_JUMP_ABSOLUTE(self, jump):
self.jump(jump)
def byte_POP_JUMP_IF_TRUE(self, jump):
val = self.pop()
if val:
self.jump(jump)
def byte_POP_JUMP_IF_FALSE(self, jump):
val = self.pop()
if not val:
self.jump(jump)
## Blocks
def byte_SETUP_LOOP(self, dest):
self.push_block('loop', dest)
def byte_GET_ITER(self):
self.push(iter(self.pop()))
def byte_FOR_ITER(self, jump):
iterobj = self.top()
try:
v = next(iterobj)
self.push(v)
except StopIteration:
self.pop()
self.jump(jump)
def byte_BREAK_LOOP(self):
return 'break'
def byte_POP_BLOCK(self):
self.pop_block()
## Functions
def byte_MAKE_FUNCTION(self, argc):
name = self.pop()
code = self.pop()
defaults = self.popn(argc)
globs = self.frame.f_globals
fn = Function(name, code, globs, defaults, None, self)
self.push(fn)
def byte_CALL_FUNCTION(self, arg):
lenKw, lenPos = divmod(arg, 256) # KWargs not supported here
posargs = self.popn(lenPos)
func = self.pop()
frame = self.frame
retval = func(*posargs)
self.push(retval)
def byte_RETURN_VALUE(self):
self.return_value = self.pop()
return "return"
動態類型:編譯器不知道它是什麼
你可能聽過 Python 是一種動態語言 —— 它是動態類型的。在我們建造解釋器的過程中,已經透露出這樣的信息。
動態的一個意思是很多工作是在運行時完成的。前面我們看到 Python 的編譯器沒有很多關於代碼真正做什麼的信息。舉個例子,考慮下面這個簡單的函數mod。它取兩個參數,返回它們的模運算值。從它的位元組碼中,我們看到變數a和b首先被載入,然後位元組碼BINAY_MODULO完成這個模運算。
>>> def mod(a, b):
... return a % b
>>> dis.dis(mod)
2 0 LOAD_FAST 0 (a)
3 LOAD_FAST 1 (b)
6 BINARY_MODULO
7 RETURN_VALUE
>>> mod(19, 5)
4
計算 19 % 5 得4,—— 一點也不奇怪。如果我們用不同類的參數呢?
>>> mod("by%sde", "teco")
'bytecode'
剛才發生了什麼?你可能在其它地方見過這樣的語法,格式化字元串。
>>> print("by%sde" % "teco")
bytecode
用符號%去格式化字元串會調用位元組碼BUNARY_MODULO。它取棧頂的兩個值求模,不管這兩個值是字元串、數字或是你自己定義的類的實例。位元組碼在函數編譯時生成(或者說,函數定義時)相同的位元組碼會用於不同類的參數。
Python 的編譯器關於位元組碼的功能知道的很少,而取決於解釋器來決定BINAYR_MODULO應用於什麼類型的對象並完成正確的操作。這就是為什麼 Python 被描述為 動態類型 :直到運行前你不必知道這個函數參數的類型。相反,在一個靜態類型語言中,程序員需要告訴編譯器參數的類型是什麼(或者編譯器自己推斷出參數的類型。)
編譯器的無知是優化 Python 的一個挑戰 —— 只看位元組碼,而不真正運行它,你就不知道每條位元組碼在幹什麼!你可以定義一個類,實現__mod__方法,當你對這個類的實例使用%時,Python 就會自動調用這個方法。所以,BINARY_MODULO其實可以運行任何代碼。
看看下面的代碼,第一個a % b看起來沒有用。
def mod(a,b):
a % b
return a %b
不幸的是,對這段代碼進行靜態分析 —— 不運行它 —— 不能確定第一個a % b沒有做任何事。用 %調用__mod__可能會寫一個文件,或是和程序的其他部分交互,或者其他任何可以在 Python 中完成的事。很難優化一個你不知道它會做什麼的函數。在 Russell Power 和 Alex Rubinsteyn 的優秀論文中寫道,「我們可以用多快的速度解釋 Python?」,他們說,「在普遍缺乏類型信息下,每條指令必須被看作一個INVOKE_ARBITRARY_METHOD。」
總結
Byterun 是一個比 CPython 容易理解的簡潔的 Python 解釋器。Byterun 複製了 CPython 的主要結構:一個基於棧的解釋器對稱之為位元組碼的指令集進行操作,它們順序執行或在指令間跳轉,向棧中壓入和從中彈出數據。解釋器隨著函數和生成器的調用和返回,動態的創建、銷毀幀,並在幀之間跳轉。Byterun 也有著和真正解釋器一樣的限制:因為 Python 使用動態類型,解釋器必須在運行時決定指令的正確行為。
我鼓勵你去反彙編你的程序,然後用 Byterun 來運行。你很快會發現這個縮短版的 Byterun 所沒有實現的指令。完整的實現在 https://github.com/nedbat/byterun,或者你可以仔細閱讀真正的 CPython 解釋器ceval.c,你也可以實現自己的解釋器!
致謝
感謝 Ned Batchelder 發起這個項目並引導我的貢獻,感謝 Michael Arntzenius 幫助調試代碼和這篇文章的修訂,感謝 Leta Montopoli 的修訂,以及感謝整個 Recurse Center 社區的支持和鼓勵。所有的不足全是我自己沒搞好。
via: http://aosabook.org/en/500L/a-python-interpreter-written-in-python.html
作者: Allison Kaptur 譯者:qingyunha 校對:wxy
本文轉載來自 Linux 中國: https://github.com/Linux-CN/archive
對這篇文章感覺如何?
You may also like






More in:Linux中國

捐贈 Let's Encrypt,共建安全的互聯網

Let's Encrypt 正式發布,已經保護 380 萬個域名

關於Linux防火牆iptables的面試問答

Lets Encrypt 已被所有主流瀏覽器所信任









