在 GitLab 我們是如何擴展資料庫的

很長時間以來 GitLab.com 使用了一個單個的 PostgreSQL 資料庫伺服器和一個用於災難恢復的單個複製。在 GitLab.com 最初的幾年,它工作的還是很好的,但是,隨著時間的推移,我們看到這種設置的很多問題,在這篇文章中,我們將帶你了解我們在幫助解決 GitLab.com 和 GitLab 實例所在的主機時都做了些什麼。
例如,資料庫長久處於重壓之下, CPU 使用率幾乎所有時間都處於 70% 左右。並不是因為我們以最好的方式使用了全部的可用資源,而是因為我們使用了太多的(未經優化的)查詢去「衝擊」伺服器。我們意識到需要去優化設置,這樣我們就可以平衡負載,使 GitLab.com 能夠更靈活地應對可能出現在主資料庫伺服器上的任何問題。
在我們使用 PostgreSQL 去跟蹤這些問題時,使用了以下的四種技術:
- 優化你的應用程序代碼,以使查詢更加高效(並且理論上使用了很少的資源)。
- 使用一個連接池去減少必需的資料庫連接數量(及相關的資源)。
- 跨多個資料庫伺服器去平衡負載。
- 分片你的資料庫
在過去的兩年里,我們一直在積極地優化應用程序代碼,但它不是一個完美的解決方案,甚至,如果你改善了性能,當流量也增加時,你還需要去應用其它的幾種技術。出於本文的目的,我們將跳過優化應用代碼這個特定主題,而專註於其它技術。
連接池
在 PostgreSQL 中,一個連接是通過啟動一個操作系統進程來處理的,這反過來又需要大量的資源,更多的連接(及這些進程)將使用你的資料庫上的更多的資源。 PostgreSQL 也在 max_connections 設置中定義了一個強制的最大連接數量。一旦達到這個限制,PostgreSQL 將拒絕新的連接, 比如,下面的圖表示的設置:
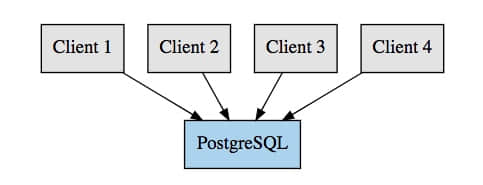
這裡我們的客戶端直接連接到 PostgreSQL,這樣每個客戶端請求一個連接。
通過連接池,我們可以有多個客戶端側的連接重複使用一個 PostgreSQL 連接。例如,沒有連接池時,我們需要 100 個 PostgreSQL 連接去處理 100 個客戶端連接;使用連接池後,我們僅需要 10 個,或者依據我們配置的 PostgreSQL 連接。這意味著我們的連接圖表將變成下面看到的那樣:
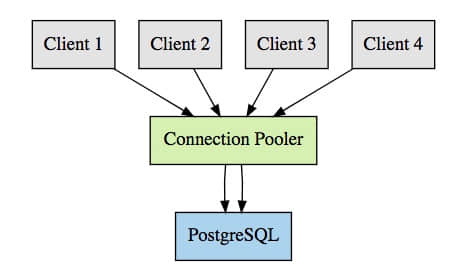
這裡我們展示了一個示例,四個客戶端連接到 pgbouncer,但不是使用了四個 PostgreSQL 連接,而是僅需要兩個。
對於 PostgreSQL 有兩個最常用的連接池:
pgpool 有一點特殊,因為它不僅僅是連接池:它有一個內置的查詢緩存機制,可以跨多個資料庫負載均衡、管理複製等等。
另一個 pgbouncer 是很簡單的:它就是一個連接池。
資料庫負載均衡
資料庫級的負載均衡一般是使用 PostgreSQL 的 「 熱備機 」 特性來實現的。 熱備機是允許你去運行只讀 SQL 查詢的 PostgreSQL 副本,與不允許運行任何 SQL 查詢的普通 備用機 相反。要使用負載均衡,你需要設置一個或多個熱備伺服器,並且以某些方式去平衡這些跨主機的只讀查詢,同時將其它操作發送到主伺服器上。擴展這樣的一個設置是很容易的:(如果需要的話)簡單地增加多個熱備機以增加只讀流量。
這種方法的另一個好處是擁有一個更具彈性的資料庫集群。即使主伺服器出現問題,僅使用次級伺服器也可以繼續處理 Web 請求;當然,如果這些請求最終使用主伺服器,你可能仍然會遇到錯誤。
然而,這種方法很難實現。例如,一旦它們包含寫操作,事務顯然需要在主伺服器上運行。此外,在寫操作完成之後,我們希望繼續使用主伺服器一會兒,因為在使用非同步複製的時候,熱備機伺服器上可能還沒有這些更改。
分片
分片是水平分割你的數據的行為。這意味著數據保存在特定的伺服器上並且使用一個分片鍵檢索。例如,你可以按項目分片數據並且使用項目 ID 做為分片鍵。當你的寫負載很高時,分片資料庫是很有用的(除了一個多主設置外,均衡寫操作沒有其它的簡單方法),或者當你有大量的數據並且你不再使用傳統方式保存它也是有用的(比如,你不能把它簡單地全部放進一個單個磁碟中)。
不幸的是,設置分片資料庫是一個任務量很大的過程,甚至,在我們使用諸如 Citus 的軟體時也是這樣。你不僅需要設置基礎設施 (不同的複雜程序取決於是你運行在你自己的數據中心還是託管主機的解決方案),你還得需要調整你的應用程序中很大的一部分去支持分片。
反對分片的案例
在 GitLab.com 上一般情況下寫負載是非常低的,同時大多數的查詢都是只讀查詢。在極端情況下,尖峰值達到每秒 1500 元組寫入,但是,在大多數情況下不超過每秒 200 元組寫入。另一方面,我們可以在任何給定的次級伺服器上輕鬆達到每秒 1000 萬元組讀取。
存儲方面,我們也不使用太多的數據:大約 800 GB。這些數據中的很大一部分是在後台遷移的,這些數據一經遷移後,我們的資料庫收縮的相當多。
接下來的工作量就是調整應用程序,以便於所有查詢都可以正確地使用分片鍵。 我們的一些查詢包含了一個項目 ID,它是我們使用的分片鍵,也有許多查詢沒有包含這個分片鍵。分片也會影響提交到 GitLab 的改變內容的過程,每個提交者現在必須確保在他們的查詢中包含分片鍵。
最後,是完成這些工作所需要的基礎設施。伺服器已經完成設置,監視也添加了、工程師們必須培訓,以便於他們熟悉上面列出的這些新的設置。雖然託管解決方案可能不需要你自己管理伺服器,但它不能解決所有問題。工程師們仍然需要去培訓(很可能非常昂貴)並需要為此支付賬單。在 GitLab 上,我們也非常樂意提供我們用過的這些工具,這樣社區就可以使用它們。這意味著如果我們去分片資料庫, 我們將在我們的 Omnibus 包中提供它(或至少是其中的一部分)。確保你提供的服務的唯一方法就是你自己去管理它,這意味著我們不能使用主機託管的解決方案。
最終,我們決定不使用資料庫分片,因為它是昂貴的、費時的、複雜的解決方案。
GitLab 的連接池
對於連接池我們有兩個主要的訴求:
- 它必須工作的很好(很顯然這是必需的)。
- 它必須易於在我們的 Omnibus 包中運用,以便於我們的用戶也可以從連接池中得到好處。
用下面兩步去評估這兩個解決方案(pgpool 和 pgbouncer):
- 執行各種技術測試(是否有效,配置是否容易,等等)。
- 找出使用這個解決方案的其它用戶的經驗,他們遇到了什麼問題?怎麼去解決的?等等。
pgpool 是我們考察的第一個解決方案,主要是因為它提供的很多特性看起來很有吸引力。我們其中的一些測試數據可以在 這裡 找到。
最終,基於多個因素,我們決定不使用 pgpool 。例如, pgpool 不支持 粘連接 。 當執行一個寫入並(嘗試)立即顯示結果時,它會出現問題。想像一下,創建一個 工單 並立即重定向到這個頁面, 沒有想到會出現 HTTP 404,這是因為任何用於只讀查詢的伺服器還沒有收到數據。針對這種情況的一種解決辦法是使用同步複製,但這會給錶帶來更多的其它問題,而我們希望避免這些問題。
另一個問題是, pgpool 的負載均衡邏輯與你的應用程序是不相干的,是通過解析 SQL 查詢並將它們發送到正確的伺服器。因為這發生在你的應用程序之外,你幾乎無法控制查詢運行在哪裡。這實際上對某些人也可能是有好處的, 因為你不需要額外的應用程序邏輯。但是,它也妨礙了你在需要的情況下調整路由邏輯。
由於配置選項非常多,配置 pgpool 也是很困難的。或許促使我們最終決定不使用它的原因是我們從過去使用過它的那些人中得到的反饋。即使是在大多數的案例都不是很詳細的情況下,我們收到的反饋對 pgpool 通常都持有負面的觀點。雖然出現的報怨大多數都與早期版本的 pgpool 有關,但仍然讓我們懷疑使用它是否是個正確的選擇。
結合上面描述的問題和反饋,最終我們決定不使用 pgpool 而是使用 pgbouncer 。我們用 pgbouncer 執行了一套類似的測試,並且對它的結果是非常滿意的。它非常容易配置(而且一開始不需要很多的配置),運用相對容易,僅專註於連接池(而且它真的很好),而且沒有明顯的負載開銷(如果有的話)。也許我唯一的報怨是,pgbouncer 的網站有點難以導航。
使用 pgbouncer 後,通過使用 事務池 我們可以將活動的 PostgreSQL 連接數從幾百個降到僅 10 - 20 個。我們選擇事務池是因為 Rails 資料庫連接是持久的。這個設置中,使用 會話池 不能讓我們降低 PostgreSQL 連接數,從而受益(如果有的話)。通過使用事務池,我們可以調低 PostgreSQL 的 max_connections 的設置值,從 3000 (這個特定值的原因我們也不清楚) 到 300 。這樣配置的 pgbouncer ,即使在尖峰時,我們也僅需要 200 個連接,這為我們提供了一些額外連接的空間,如 psql 控制台和維護任務。
對於使用事務池的負面影響方面,你不能使用預處理語句,因為 PREPARE 和 EXECUTE 命令也許最終在不同的連接中運行,從而產生錯誤的結果。 幸運的是,當我們禁用了預處理語句時,並沒有測量到任何響應時間的增加,但是我們 確定 測量到在我們的資料庫伺服器上內存使用減少了大約 20 GB。
為確保我們的 web 請求和後台作業都有可用連接,我們設置了兩個獨立的池: 一個有 150 個連接的後台進程連接池,和一個有 50 個連接的 web 請求連接池。對於 web 連接需要的請求,我們很少超過 20 個,但是,對於後台進程,由於在 GitLab.com 上後台運行著大量的進程,我們的尖峰值可以很容易達到 100 個連接。
今天,我們提供 pgbouncer 作為 GitLab EE 高可用包的一部分。對於更多的信息,你可以參考 「Omnibus GitLab PostgreSQL High Availability」。
GitLab 上的資料庫負載均衡
使用 pgpool 和它的負載均衡特性,我們需要一些其它的東西去分發負載到多個熱備伺服器上。
對於(但不限於) Rails 應用程序,它有一個叫 Makara 的庫,它實現了負載均衡的邏輯並包含了一個 ActiveRecord 的預設實現。然而,Makara 也有一些我們認為是有些遺憾的問題。例如,它支持的粘連接是非常有限的:當你使用一個 cookie 和一個固定的 TTL 去執行一個寫操作時,連接將粘到主伺服器。這意味著,如果複製極大地滯後於 TTL,最終你可能會發現,你的查詢運行在一個沒有你需要的數據的主機上。
Makara 也需要你做很多配置,如所有的資料庫主機和它們的角色,沒有服務發現機制(我們當前的解決方案也不支持它們,即使它是將來計劃的)。 Makara 也 似乎不是線程安全的,這是有問題的,因為 Sidekiq (我們使用的後台進程)是多線程的。 最終,我們希望儘可能地去控制負載均衡的邏輯。
除了 Makara 之外 ,還有一個 Octopus ,它也是內置的負載均衡機制。但是 Octopus 是面向分片資料庫的,而不僅是均衡只讀查詢的。因此,最終我們不考慮使用 Octopus。
最終,我們直接在 GitLab EE構建了自己的解決方案。 添加初始實現的 合併請求 可以在 這裡找到,儘管一些更改、提升和修復是以後增加的。
我們的解決方案本質上是通過用一個處理查詢的路由的代理對象替換 ActiveRecord::Base.connection 。這可以讓我們均衡負載儘可能多的查詢,甚至,包括不是直接來自我們的代碼中的查詢。這個代理對象基於調用方式去決定將查詢轉發到哪個主機, 消除了解析 SQL 查詢的需要。
粘連接
粘連接是通過在執行寫入時,將當前 PostgreSQL WAL 位置存儲到一個指針中實現支持的。在請求即將結束時,指針短期保存在 Redis 中。每個用戶提供他自己的 key,因此,一個用戶的動作不會導致其他的用戶受到影響。下次請求時,我們取得指針,並且與所有的次級伺服器進行比較。如果所有的次級伺服器都有一個超過我們的指針的 WAL 指針,那麼我們知道它們是同步的,我們可以為我們的只讀查詢安全地使用次級伺服器。如果一個或多個次級伺服器沒有同步,我們將繼續使用主伺服器直到它們同步。如果 30 秒內沒有寫入操作,並且所有的次級伺服器還沒有同步,我們將恢復使用次級伺服器,這是為了防止有些人的查詢永遠運行在主伺服器上。
檢查一個次級伺服器是否就緒十分簡單,它在如下的 Gitlab::Database::LoadBalancing::Host#caught_up? 中實現:
def caught_up?(location)
string = connection.quote(location)
query = "SELECT NOT pg_is_in_recovery() OR "
"pg_xlog_location_diff(pg_last_xlog_replay_location(), #{string}) >= 0 AS result"
row = connection.select_all(query).first
row && row['result'] == 't'
ensure
release_connection
end
這裡的大部分代碼是運行原生查詢(raw queries)和獲取結果的標準的 Rails 代碼,查詢的最有趣的部分如下:
SELECT NOT pg_is_in_recovery()
OR pg_xlog_location_diff(pg_last_xlog_replay_location(), WAL-POINTER) >= 0 AS result"
這裡 WAL-POINTER 是 WAL 指針,通過 PostgreSQL 函數 pg_current_xlog_insert_location() 返回的,它是在主伺服器上執行的。在上面的代碼片斷中,該指針作為一個參數傳遞,然後它被引用或轉義,並傳遞給查詢。
使用函數 pg_last_xlog_replay_location() 我們可以取得次級伺服器的 WAL 指針,然後,我們可以通過函數 pg_xlog_location_diff() 與我們的主伺服器上的指針進行比較。如果結果大於 0 ,我們就可以知道次級伺服器是同步的。
當一個次級伺服器被提升為主伺服器,並且我們的 GitLab 進程還不知道這一點的時候,添加檢查 NOT pg_is_in_recovery() 以確保查詢不會失敗。在這個案例中,主伺服器總是與它自己是同步的,所以它簡單返回一個 true。
後台進程
我們的後台進程代碼 總是 使用主伺服器,因為在後台執行的大部分工作都是寫入。此外,我們不能可靠地使用一個熱備機,因為我們無法知道作業是否在主伺服器執行,也因為許多作業並沒有直接綁定到用戶上。
連接錯誤
要處理連接錯誤,比如負載均衡器不會使用一個視作離線的次級伺服器,會增加主機上(包括主伺服器)的連接錯誤,將會導致負載均衡器多次重試。這是確保,在遇到偶發的小問題或資料庫失敗事件時,不會立即顯示一個錯誤頁面。當我們在負載均衡器級別上處理 熱備機衝突 的問題時,我們最終在次級伺服器上啟用了 hot_standby_feedback ,這樣就解決了熱備機衝突的所有問題,而不會對錶膨脹造成任何負面影響。
我們使用的過程很簡單:對於次級伺服器,我們在它們之間用無延遲試了幾次。對於主伺服器,我們通過使用越來越快的回退嘗試幾次。
更多信息你可以查看 GitLab EE 上的源代碼:
- https://gitlab.com/gitlab-org/gitlab-ee/tree/master/lib/gitlab/database/load_balancing.rb
- https://gitlab.com/gitlab-org/gitlab-ee/tree/master/lib/gitlab/database/load_balancing
資料庫負載均衡首次引入是在 GitLab 9.0 中,並且 僅 支持 PostgreSQL。更多信息可以在 9.0 release post 和 documentation 中找到。
Crunchy Data
我們與 Crunchy Data 一起協同工作來部署連接池和負載均衡。不久之前我還是唯一的 資料庫專家,它意味著我有很多工作要做。此外,我對 PostgreSQL 的內部細節的和它大量的設置所知有限 (或者至少現在是),這意味著我能做的也有限。因為這些原因,我們僱用了 Crunchy 去幫我們找出問題、研究慢查詢、建議模式優化、優化 PostgreSQL 設置等等。
在合作期間,大部分工作都是在相互信任的基礎上完成的,因此,我們共享私人數據,比如日誌。在合作結束時,我們從一些資料和公開的內容中刪除了敏感數據,主要的資料在 gitlab-com/infrastructure#1448,這又反過來導致產生和解決了許多分立的問題。
這次合作的好處是巨大的,它幫助我們發現並解決了許多的問題,如果必須我們自己來做的話,我們可能需要花上幾個月的時間來識別和解決它。
幸運的是,最近我們成功地僱傭了我們的 第二個資料庫專家 並且我們希望以後我們的團隊能夠發展壯大。
整合連接池和資料庫負載均衡
整合連接池和資料庫負載均衡可以讓我們去大幅減少運行資料庫集群所需要的資源和在分發到熱備機上的負載。例如,以前我們的主伺服器 CPU 使用率一直徘徊在 70%,現在它一般在 10% 到 20% 之間,而我們的兩台熱備機伺服器則大部分時間在 20% 左右:
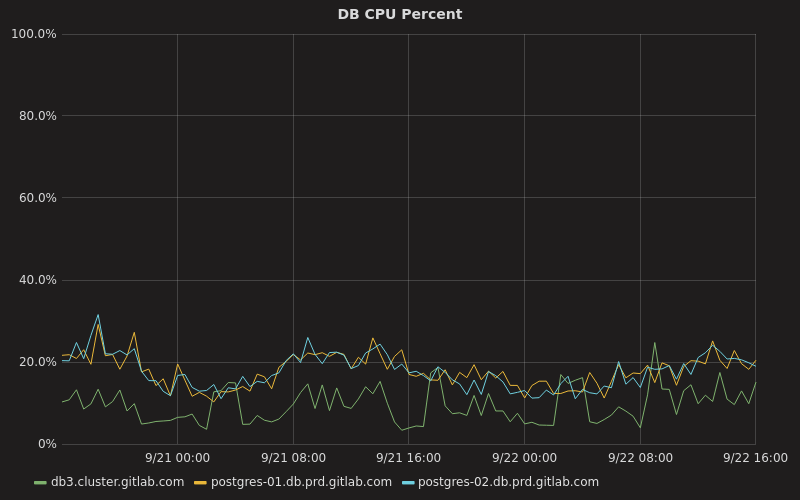
在這裡, db3.cluster.gitlab.com 是我們的主伺服器,而其它的兩台是我們的次級伺服器。
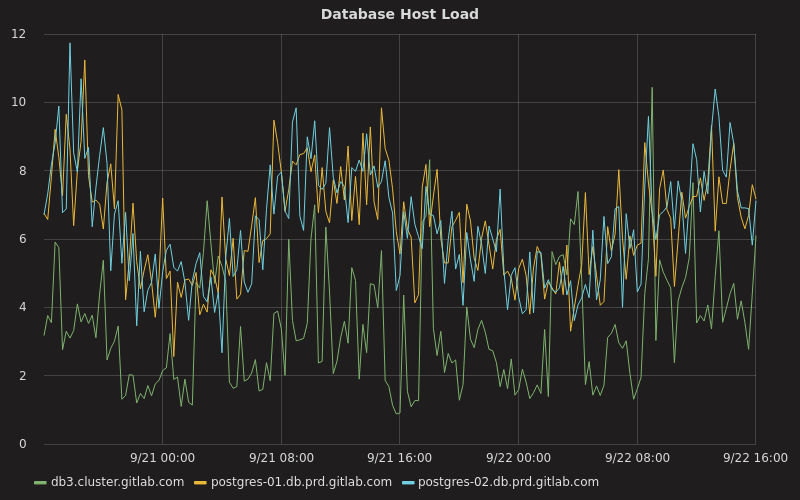
其它的負載相關的因素,如平均負載、磁碟使用、內存使用也大為改善。例如,主伺服器現在的平均負載幾乎不會超過 10,而不像以前它一直徘徊在 20 左右:
在業務繁忙期間,我們的次級伺服器每秒事務數在 12000 左右(大約為每分鐘 740000),而主伺服器每秒事務數在 6000 左右(大約每分鐘 340000):
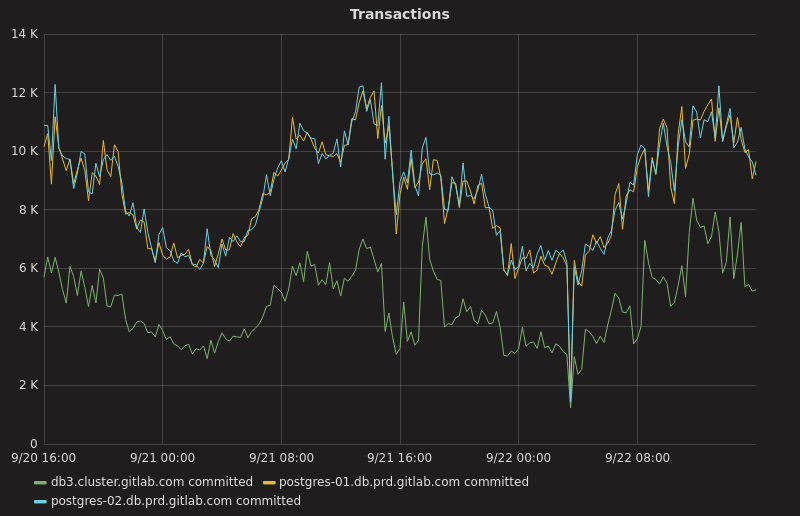
可惜的是,在部署 pgbouncer 和我們的資料庫負載均衡器之前,我們沒有關於事務速率的任何數據。
我們的 PostgreSQL 的最新統計數據的摘要可以在我們的 public Grafana dashboard 上找到。
我們的其中一些 pgbouncer 的設置如下:
| 設置 | 值 |
|---|---|
default_pool_size |
100 |
reserve_pool_size |
5 |
reserve_pool_timeout |
3 |
max_client_conn |
2048 |
pool_mode |
transaction |
server_idle_timeout |
30 |
除了前面所說的這些外,還有一些工作要作,比如: 部署服務發現(#2042), 持續改善如何檢查次級伺服器是否可用(#2866),和忽略落後於主伺服器太多的次級伺服器 (#2197)。
值得一提的是,到目前為止,我們還沒有任何計劃將我們的負載均衡解決方案,獨立打包成一個你可以在 GitLab 之外使用的庫,相反,我們的重點是為 GitLab EE 提供一個可靠的負載均衡解決方案。
如果你對它感興趣,並喜歡使用資料庫、改善應用程序性能、給 GitLab上增加資料庫相關的特性(比如: 服務發現),你一定要去查看一下我們的 招聘職位 和 資料庫專家手冊 去獲取更多信息。
via: https://about.gitlab.com/2017/10/02/scaling-the-gitlab-database/
作者:Yorick Peterse 譯者:qhwdw 校對:wxy
本文轉載來自 Linux 中國: https://github.com/Linux-CN/archive
對這篇文章感覺如何?
You may also like






More in:Linux中國

捐贈 Let's Encrypt,共建安全的互聯網

Let's Encrypt 正式發布,已經保護 380 萬個域名

關於Linux防火牆iptables的面試問答

Lets Encrypt 已被所有主流瀏覽器所信任









