如何使用機器學習來分析情感

本文將幫助你理解 情感分析 的概念,並且學習如何使用機器學習進行情感分析。我們使用了不同的機器學習演算法進行情感分析,然後將各個演算法的準確率結果進行比較,以確定哪一種演算法最適合這個問題。
情感分析是自然語言處理(NLP)中的一個重要的內容。情感指的是我們對某一事件、物品、情況或事物產生的感覺。情感分析是一個從文本中自動提取人類情感的研究領域。它在上世紀 90 年代初才慢慢地開始發展起來。
本文將讓你明白如何將機器學習(ML)用於情感分析,並比較不同機器學習演算法的結果。本文的目標不在於研究如何提高演算法性能。
如今,我們生活在一個快節奏的社會中,所有的商品都能在網上購買到,每個人都可以在網上發表自己的評論。而一些商品的負面網路評論可能會損害公司的聲譽,從而影響公司的銷售額。因此對公司來說,通過商品評論來了解客戶真正想要什麼變得非常重要。但是這些評論數據太多了,無法一個個地手動查看所有的評論。這就是情緒分析誕生的緣由。
現在,就讓我們看看如何用機器學習開發一個模型,來進行基本的情緒分析吧。
現在就開始吧!
獲取數據
第一步是選擇一個數據集。你可以從任何公開的評論中進行選擇,例如推文或電影評論。數據集中至少要包含兩列:標籤和實際的文本段。
下圖顯示了我們選取的部分數據集。

接下來,我們導入所需的庫:
import pandas as pd
import numpy as np
from nltk.stem.porter import PorterStemmer
import re
import string
正如你在上面代碼看到,我們導入了 NumPy 和 Pandas 庫來處理數據。至於其他庫,我們會在使用到它們時再說明。
數據集已準備就緒,並且已導入所需的庫。接著,我們需要用 Pandas 庫將數據集讀入到我們的項目中去。我們使用以下的代碼將數據集讀入 Pandas 數據幀 類型:
sentiment_dataframe = pd.read_csv(「/content/drive/MyDrive/Data/sentiments - sentiments.tsv」,sep = 『t』)
數據處理
現在我們的項目中已經導入好數據集了。然後,我們要對數據進行處理,以便演算法可以更好地理解數據集的特徵。我們首先為數據集中的列命名,通過下面的代碼來完成:
sentiment_dataframe.columns = [「label」,」body_text」]
然後,我們對 label 列進行數值化:negative 的評論替換為 1,positive 的評論替換為 0。下圖顯示了經過基本修改後的 sentiment_dataframe 的值。
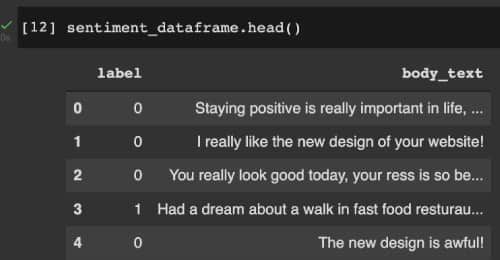
準備好特徵值、目標值
下一步是數據的預處理。這是非常重要的一步,因為機器學習演算法只能理解/處理數值形數據,而不能理解文本,所以此時要進行特徵抽取,將字元串/文本轉換成數值化的數據。此外,還需要刪除冗餘和無用的數據,因為這些數據可能會污染我們的訓練模型。我們在這一步中去除了雜訊數據、缺失值數據和不一致的數據。
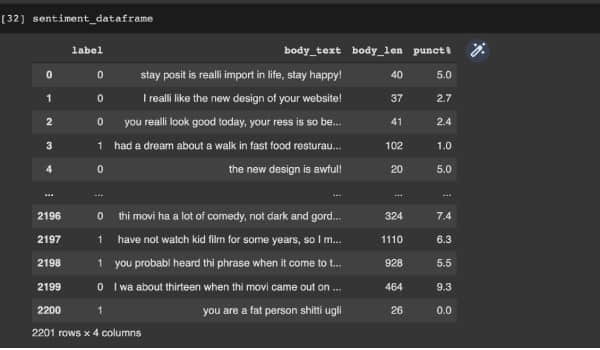
對於情感分析,我們在數據幀中添加特徵文本的長度和標點符號計數。我們還要進行詞幹提取,即將所有相似詞(如 「give」、「giving」 等)轉換為單一形式。完成後,我們將數據集分為兩部分:特徵值 X 和 目標值 Y。
上述內容是使用以下代碼完成的。下圖顯示了執行這些步驟後的數據幀。
def count_punct(text):
count = sum([1 for char in text if char in string.punctuation])
return round(count/(len(text) - text.count(「 「)),3)*100
tokenized_tweet = sentiment_dataframe[『body_text』].apply(lambda x: x.split())
stemmer = PorterStemmer()
tokenized_tweet = tokenized_tweet.apply(lambda x: [stemmer.stem(i) for i in x])
for i in range(len(tokenized_tweet)):
tokenized_tweet[i] = 『 『.join(tokenized_tweet[i])
sentiment_dataframe[『body_text』] = tokenized_tweet
sentiment_dataframe[『body_len』] = sentiment_dataframe[『body_text』].apply(lambda x:len(x) - x.count(「 「))
sentiment_dataframe[『punct%』] = sentiment_dataframe[『body_text』].apply(lambda x:count_punct(x))
X = sentiment_dataframe[『body_text』]
y = sentiment_dataframe[『label』]
特徵工程:文本特徵處理
我們接下來進行文本特徵抽取,對文本特徵進行數值化。為此,我們使用 計數向量器 ,它返回詞頻矩陣。
在此之後,計算數據幀 X 中的文本長度和標點符號計數等特徵。X 的示例如下圖所示。
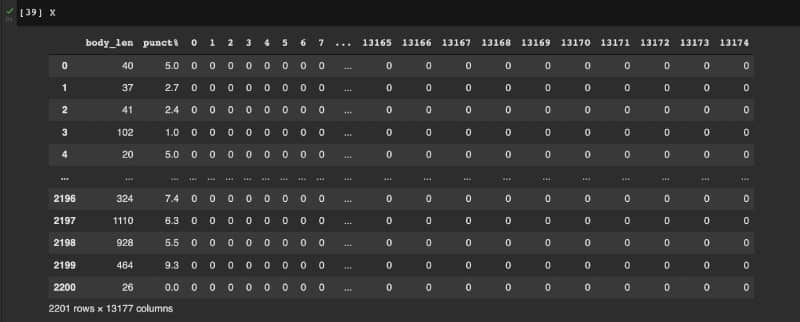
使用的機器學習演算法
現在數據已經可以訓練了。下一步是確定使用哪些演算法來訓練模型。如前所述,我們將嘗試多種機器學習演算法,並確定最適合情感分析的演算法。由於我們打算對文本進行二元分類,因此我們使用以下演算法:
- K-近鄰演算法(KNN)
- 邏輯回歸演算法
- 支持向量機(SVMs)
- 隨機梯度下降(SGD)
- 樸素貝葉斯演算法
- 決策樹演算法
- 隨機森林演算法
劃分數據集
首先,將數據集劃分為訓練集和測試集。使用 sklearn 庫,詳見以下代碼:
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X,y, test_size = 0.20, random_state = 99)
我們使用 20% 的數據進行測試,80% 的數據用於訓練。劃分數據的意義在於對一組新數據(即測試集)評估我們訓練的模型是否有效。
K-近鄰演算法
現在,讓我們開始訓練第一個模型。首先,我們使用 KNN 演算法。先訓練模型,然後再評估模型的準確率(具體的代碼都可以使用 Python 的 sklearn 庫來完成)。詳見以下代碼,KNN 訓練模型的準確率大約為 50%。
from sklearn.neighbors import KNeighborsClassifier
model = KNeighborsClassifier(n_neighbors=3)
model.fit(X_train, y_train)
model.score (X_test,y_test)
0.5056689342403629
邏輯回歸演算法
邏輯回歸模型的代碼十分類似——首先從庫中導入函數,擬合模型,然後對模型進行評估。下面的代碼使用邏輯回歸演算法,準確率大約為 66%。
from sklearn.linear_model import LogisticRegression
model = LogisticRegression()
model.fit (X_train,y_train)
model.score (X_test,y_test)
0.6621315192743764
支持向量機演算法
以下代碼使用 SVM,準確率大約為 67%。
from sklearn import svm
model = svm.SVC(kernel=』linear』)
model.fit(X_train, y_train)
model.score(X_test,y_test)
0.6780045351473923
隨機森林演算法
以下的代碼使用了隨機森林演算法,隨機森林訓練模型的準確率大約為 69%。
from sklearn.ensemble import RandomForestClassifier
model = RandomForestClassifier()
model.fit(X_train, y_train)
model.score(X_test,y_test)
0.6938775510204082
決策樹演算法
接下來,我們使用決策樹演算法,其準確率約為 61%。
from sklearn.tree import DecisionTreeClassifier
model = DecisionTreeClassifier()
model = model.fit(X_train,y_train)
model.score(X_test,y_test)
0.6190476190476191
隨機梯度下降演算法
以下的代碼使用隨機梯度下降演算法,其準確率大約為 49%。
from sklearn.linear_model import SGDClassifier
model = SGDClassifier()
model = model.fit(X_train,y_train)
model.score(X_test,y_test)
0.49206349206349204
樸素貝葉斯演算法
以下的代碼使用樸素貝葉斯演算法,樸素貝葉斯訓練模型的準確率大約為 60%。
from sklearn.naive_bayes import GaussianNB
model = GaussianNB()
model.fit(X_train, y_train)
model.score(X_test,y_test)
0.6009070294784581
情感分析的最佳演算法
接下來,我們繪製所有演算法的準確率圖。如下圖所示。
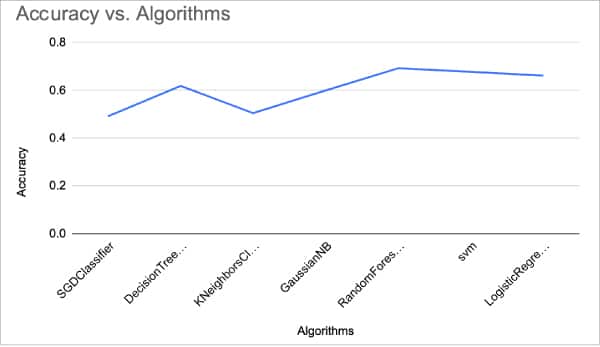
可以看到,對於情感分析這一問題,隨機森林演算法有最佳的準確率。由此,我們可以得出結論,隨機森林演算法是所有機器演算法中最適合情感分析的演算法。我們可以通過處理得到更好的特徵、嘗試其他矢量化技術、或者使用更好的數據集或更好的分類演算法,來進一步提高準確率。
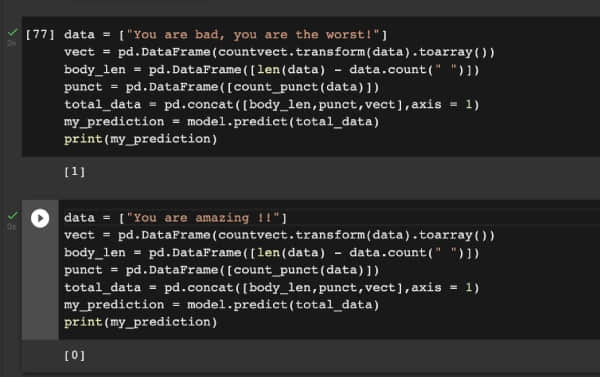
既然,隨機森林演算法是解決情感分析問題的最佳演算法,我將向你展示一個預處理數據的樣本。在下圖中,你可以看到模型會做出正確的預測!試試這個來改進你的項目吧!
via: https://www.opensourceforu.com/2022/09/how-to-analyse-sentiments-using-machine-learning/
作者:Jishnu Saurav Mittapalli 選題:lkxed 譯者:chai001125 校對:wxy
本文轉載來自 Linux 中國: https://github.com/Linux-CN/archive
對這篇文章感覺如何?
You may also like






More in:Linux中國

捐贈 Let's Encrypt,共建安全的互聯網

Let's Encrypt 正式發布,已經保護 380 萬個域名

關於Linux防火牆iptables的面試問答

Lets Encrypt 已被所有主流瀏覽器所信任









