如何在命令行中整理數據

我兼職做數據審計。把我想像成一個校對者,校對的是數據表格而不是一頁一頁的文章。這些表是從關係資料庫導出的,並且規模相當小:100,000 到 1,000,000條記錄,50 到 200 個欄位。
我從來沒有見過沒有錯誤的數據表。如你所能想到的,這種混亂並不局限於重複記錄、拼寫和格式錯誤以及放置在錯誤欄位中的數據項。我還發現:
- 損壞的記錄分布在幾行上,因為數據項具有內嵌的換行符
- 在同一記錄中一個欄位中的數據項與另一個欄位中的數據項不一致
- 使用截斷數據項的記錄,通常是因為非常長的字元串被硬塞到具有 50 或 100 字元限制的欄位中
- 字元編碼失敗產生稱為亂碼的垃圾
- 不可見的控制字元,其中一些會導致數據處理錯誤
- 由上一個程序插入的替換字元和神秘的問號,這是由於不知道數據的編碼是什麼
解決這些問題並不困難,但找到它們存在非技術障礙。首先,每個人都不願處理數據錯誤。在我看到表格之前,數據所有者或管理人員可能已經經歷了 數據悲傷 的所有五個階段:
- 我們的數據沒有錯誤。
- 好吧,也許有一些錯誤,但它們並不重要。
- 好的,有很多錯誤;我們會讓我們的內部人員處理它們。
- 我們已經開始修復一些錯誤,但這很耗時間;我們將在遷移到新的資料庫軟體時執行此操作。
- 移至新資料庫時,我們沒有時間整理數據; 我們需要一些幫助。
第二個阻礙進展的是相信數據整理需要專用的應用程序——要麼是昂貴的專有程序,要麼是優秀的開源程序 OpenRefine 。為了解決專用應用程序無法解決的問題,數據管理人員可能會向程序員尋求幫助,比如擅長 Python 或 R 的人。
但是數據審計和整理通常不需要專用的應用程序。純文本數據表已經存在了幾十年,文本處理工具也是如此。打開 Bash shell,您將擁有一個工具箱,其中裝載了強大的文本處理器,如 grep、cut、paste、sort、uniq、tr 和 awk。它們快速、可靠、易於使用。
我在命令行上執行所有的數據審計工作,並且在 「cookbook」 網站上發布了許多數據審計技巧。我經常將操作存儲為函數和 shell 腳本(參見下面的示例)。
是的,命令行方法要求將要審計的數據從資料庫中導出。而且,審計結果需要稍後在資料庫中進行編輯,或者(資料庫允許)將整理的數據項導入其中,以替換雜亂的數據項。
但其優勢是顯著的。awk 將在普通的台式機或筆記本電腦上以幾秒鐘的時間處理數百萬條記錄。不複雜的正則表達式將找到您可以想像的所有數據錯誤。所有這些都將安全地發生在資料庫結構之外:命令行審計不會影響資料庫,因為它使用從資料庫中釋放的數據。
受過 Unix 培訓的讀者此時會沾沾自喜。他們還記得許多年前用這些方法操縱命令行上的數據。從那時起,計算機的處理能力和 RAM 得到了顯著提高,標準命令行工具的效率大大提高。數據審計從來沒有這麼快、這麼容易過。現在微軟的 Windows 10 可以運行 Bash 和 GNU/Linux 程序了,Windows 用戶也可以用 Unix 和 Linux 的座右銘來處理混亂的數據:保持冷靜,打開一個終端。

例子
假設我想在一個大的表中的特定欄位中找到最長的數據項。 這不是一個真正的數據審計任務,但它會顯示 shell 工具的工作方式。 為了演示目的,我將使用製表符分隔的表 full0 ,它有 1,122,023 條記錄(加上一個標題行)和 49 個欄位,我會查看 36 號欄位。(我得到欄位編號的函數在我的網站上有解釋)
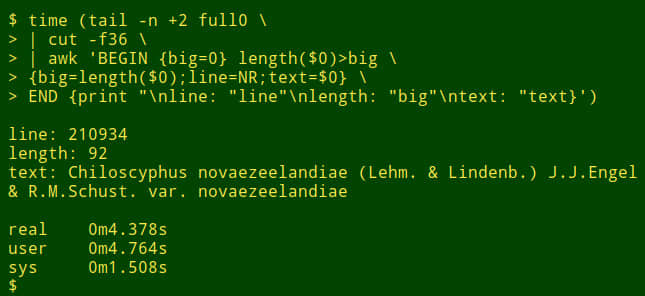
首先,使用 tail 命令從表 full0 移除標題行,結果管道至 cut 命令,截取第 36 個欄位,接下來,管道至 awk ,這裡有一個初始化為 0 的變數 big ,然後 awk 開始檢測第一行數據項的長度,如果長度大於 0 ,awk 將會設置 big 變數為新的長度,同時存儲行數到變數 line 中。整個數據項存儲在變數 text 中。然後 awk 開始輪流處理剩餘的 1,122,022 記錄項。同時,如果發現更長的數據項時,更新 3 個變數。最後,它列印出行號、數據項的長度,以及最長數據項的內容。(在下面的代碼中,為了清晰起見,將代碼分為幾行)
tail -n +2 full0
> | cut -f36
> | awk 'BEGIN {big=0} length($0)>big
> {big=length($0);line=NR;text=$0}
> END {print "nline: "line"nlength: "big"ntext: "text}'
大約花了多長時間?我的電腦大約用了 4 秒鐘(core i5,8GB RAM);
現在我可以將這個長長的命令封裝成一個 shell 函數,longest,它把第一個參數認為是文件名,第二個參數認為是欄位號:

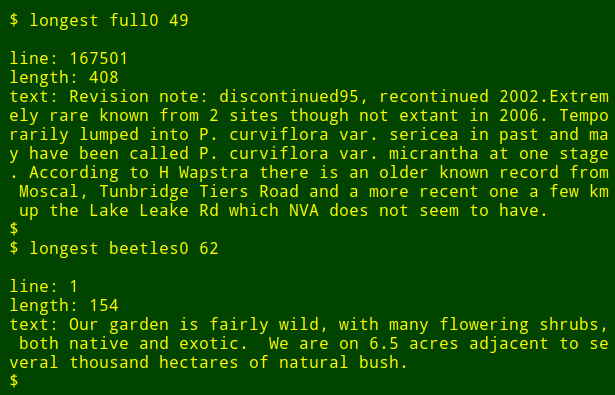
現在,我可以以函數的方式重新運行這個命令,在另一個文件中的另一個欄位中找最長的數據項,而不需要去記憶這個命令是如何寫的:
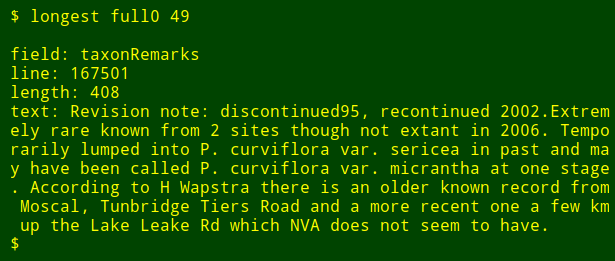
最後調整一下,我還可以輸出我要查詢欄位的名稱,我只需要使用 head 命令抽取表格第一行的標題行,然後將結果管道至 tr 命令,將製表位轉換為換行,然後將結果管道至 tail 和 head 命令,列印出第二個參數在列表中名稱,第二個參數就是欄位號。欄位的名字就存儲到變數 field 中,然後將它傳向 awk ,通過變數 fld 列印出來。(LCTT 譯註:按照下面的代碼,編號的方式應該是從右向左)
longest() { field=$(head -n 1 "$1" | tr 't' 'n' | tail -n +"$2" | head -n 1);
tail -n +2 "$1"
| cut -f"$2" |
awk -v fld="$field" 'BEGIN {big=0} length($0)>big
{big=length($0);line=NR;text=$0}
END {print "nfield: "fld"nline: "line"nlength: "big"ntext: "text}'; }
注意,如果我在多個不同的欄位中查找最長的數據項,我所要做的就是按向上箭頭來獲得最後一個最長的命令,然後刪除欄位號並輸入一個新的。
via: https://opensource.com/article/18/5/command-line-data-auditing
作者:Bob Mesibov 選題:lujun9972 譯者:amwps290 校對:wxy
本文轉載來自 Linux 中國: https://github.com/Linux-CN/archive
對這篇文章感覺如何?
You may also like






More in:Linux中國

捐贈 Let's Encrypt,共建安全的互聯網

Let's Encrypt 正式發布,已經保護 380 萬個域名

關於Linux防火牆iptables的面試問答

Lets Encrypt 已被所有主流瀏覽器所信任









