如何收集 NGINX 指標(第二篇)

如何獲取你所需要的 NGINX 指標
如何獲取需要的指標取決於你正在使用的 NGINX 版本以及你希望看到哪些指標。(參見 如何監控 NGINX(第一篇) 來深入了解NGINX指標。)自由開源的 NGINX 和商業版的 NGINX Plus 都有可以報告指標度量的狀態模塊,NGINX 也可以在其日誌中配置輸出特定指標:
指標可用性
| 指標 | NGINX (開源) | NGINX Plus | NGINX 日誌 |
|---|---|---|---|
| accepts(接受) / accepted(已接受) | x | x | |
| handled(已處理) | x | x | |
| dropped(已丟棄) | x | x | |
| active(活躍) | x | x | |
| requests (請求數)/ total(全部請求數) | x | x | |
| 4xx 代碼 | x | x | |
| 5xx 代碼 | x | x | |
| request time(請求處理時間) | x |
指標收集:NGINX(開源版)
開源版的 NGINX 會在一個簡單的狀態頁面上顯示幾個與伺服器狀態有關的基本指標,它們由你啟用的 HTTP stub status module 所提供。要檢查該模塊是否已啟用,運行以下命令:
nginx -V 2>&1 | grep -o with-http_stub_status_module
如果你看到終端輸出了 httpstubstatus_module,說明該狀態模塊已啟用。
如果該命令沒有輸出,你需要啟用該狀態模塊。你可以在從源代碼構建 NGINX 時使用 --with-http_stub_status_module 配置參數:
./configure
…
--with-http_stub_status_module
make
sudo make install
在驗證該模塊已經啟用或你自己啟用它後,你還需要修改 NGINX 配置文件,來給狀態頁面設置一個本地可訪問的 URL(例如: /nginx_status):
server {
location /nginx_status {
stub_status on;
access_log off;
allow 127.0.0.1;
deny all;
}
}
註:nginx 配置中的 server 塊通常並不放在主配置文件中(例如:/etc/nginx/nginx.conf),而是放在主配置會載入的輔助配置文件中。要找到主配置文件,首先運行以下命令:
nginx -t
打開列出的主配置文件,在以 http 塊結尾的附近查找以 include 開頭的行,如:
include /etc/nginx/conf.d/*.conf;
在其中一個包含的配置文件中,你應該會找到主 server 塊,你可以如上所示配置 NGINX 的指標輸出。更改任何配置後,通過執行以下命令重新載入配置文件:
nginx -s reload
現在,你可以瀏覽狀態頁看到你的指標:
Active connections: 24
server accepts handled requests
1156958 1156958 4491319
Reading: 0 Writing: 18 Waiting : 6
請注意,如果你希望從遠程計算機訪問該狀態頁面,則需要將遠程計算機的 IP 地址添加到你的狀態配置文件的白名單中,在上面的配置文件中的白名單僅有 127.0.0.1。
NGINX 的狀態頁面是一種快速查看指標狀況的簡單方法,但當連續監測時,你需要按照標準間隔自動記錄該數據。監控工具箱 Nagios 或者 Datadog,以及收集統計信息的服務 collectD 已經可以解析 NGINX 的狀態信息了。
指標收集: NGINX Plus
商業版的 NGINX Plus 通過它的 ngxhttpstatus_module 提供了比開源版 NGINX 更多的指標。NGINX Plus 以位元組流的方式提供這些額外的指標,提供了關於上游系統和高速緩存的信息。NGINX Plus 也會報告所有的 HTTP 狀態碼類型(1XX,2XX,3XX,4XX,5XX)的計數。一個 NGINX Plus 狀態報告例子可在此查看:
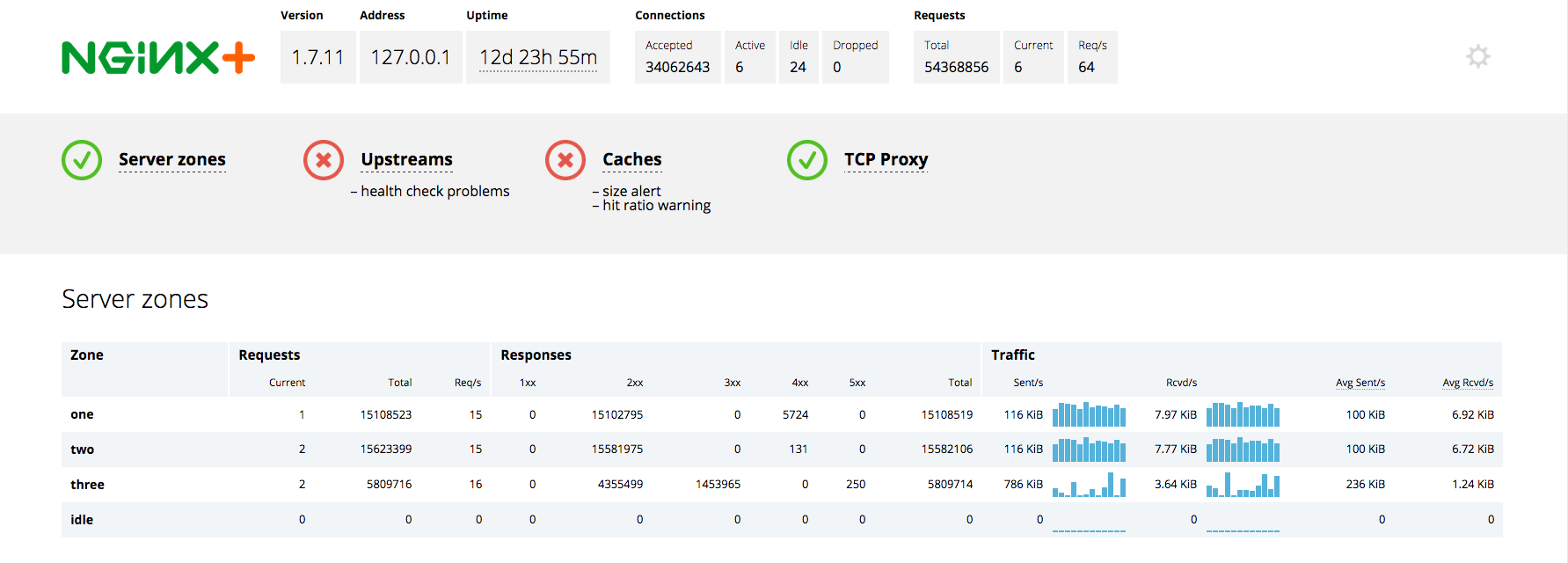
註:NGINX Plus 在狀態儀錶盤中的「Active」連接的定義和開源 NGINX 通過 stubstatusmodule 收集的「Active」連接指標略有不同。在 NGINX Plus 指標中,「Active」連接不包括Waiting狀態的連接(即「Idle」連接)。
NGINX Plus 也可以輸出 JSON 格式的指標,可以用於集成到其他監控系統。在 NGINX Plus 中,你可以看到 給定的上游伺服器組的指標和健康狀況,或者簡單地從上游伺服器的單個伺服器得到響應代碼的計數:
{"1xx":0,"2xx":3483032,"3xx":0,"4xx":23,"5xx":0,"total":3483055}
要啟動 NGINX Plus 指標儀錶盤,你可以在 NGINX 配置文件的 http 塊內添加狀態 server 塊。 (參見上一節,為收集開源版 NGINX 指標而如何查找相關的配置文件的說明。)例如,要設置一個狀態儀錶盤 (http://your.ip.address:8080/status.html)和一個 JSON 介面(http://your.ip.address:8080/status),可以添加以下 server 塊來設定:
server {
listen 8080;
root /usr/share/nginx/html;
location /status {
status;
}
location = /status.html {
}
}
當你重新載入 NGINX 配置後,狀態頁就可以用了:
nginx -s reload
關於如何配置擴展狀態模塊,官方 NGINX Plus 文檔有 詳細介紹 。
指標收集:NGINX 日誌
NGINX 的 日誌模塊 會把可自定義的訪問日誌寫到你配置的指定位置。你可以通過添加或移除變數來自定義日誌的格式和包含的數據。要存儲詳細的日誌,最簡單的方法是添加下面一行在你配置文件的 server 塊中(參見上上節,為收集開源版 NGINX 指標而如何查找相關的配置文件的說明。):
access_log logs/host.access.log combined;
更改 NGINX 配置文件後,執行如下命令重新載入配置文件:
nginx -s reload
默認包含的 「combined」 的日誌格式,會包括一系列關鍵的數據,如實際的 HTTP 請求和相應的響應代碼。在下面的示例日誌中,NGINX 記錄了請求 /index.html 時的 200(成功)狀態碼和訪問不存在的請求文件 /fail 的 404(未找到)錯誤。
127.0.0.1 - - [19/Feb/2015:12:10:46 -0500] "GET /index.html HTTP/1.1" 200 612 "-" "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_10_1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/40.0.2214.111 Safari 537.36"
127.0.0.1 - - [19/Feb/2015:12:11:05 -0500] "GET /fail HTTP/1.1" 404 570 "-" "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_10_1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/40.0.2214.111 Safari/537.36"
你可以通過在 NGINX 配置文件中的 http 塊添加一個新的日誌格式來記錄請求處理時間:
log_format nginx '$remote_addr - $remote_user [$time_local] '
'"$request" $status $body_bytes_sent $request_time '
'"$http_referer" "$http_user_agent"';
並修改配置文件中 server 塊的 access_log 行:
access_log logs/host.access.log nginx;
重新載入配置文件後(運行 nginx -s reload),你的訪問日誌將包括響應時間,如下所示。單位為秒,精度到毫秒。在這個例子中,伺服器接收到一個對 /big.pdf 的請求時,發送 33973115 位元組後返回 206(成功)狀態碼。處理請求用時 0.202 秒(202毫秒):
127.0.0.1 - - [19/Feb/2015:15:50:36 -0500] "GET /big.pdf HTTP/1.1" 206 33973115 0.202 "-" "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_10_1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/40.0.2214.111 Safari/537.36"
你可以使用各種工具和服務來解析和分析 NGINX 日誌。例如,rsyslog 可以監視你的日誌,並將其傳遞給多個日誌分析服務;你也可以使用自由開源工具,比如 logstash 來收集和分析日誌;或者你可以使用一個統一日誌記錄層,如 Fluentd 來收集和解析你的 NGINX 日誌。
結論
監視 NGINX 的哪一項指標將取決於你可用的工具,以及監控指標所提供的信息是否滿足你們的需要。舉例來說,錯誤率的收集是否足夠重要到需要你們購買 NGINX Plus ,還是架設一個可以捕獲和分析日誌的系統就夠了?
在 Datadog 中,我們已經集成了 NGINX 和 NGINX Plus,這樣你就可以以最小的設置來收集和監控所有 Web 伺服器的指標。在本文中了解如何用 NGINX Datadog 來監控 ,並開始 Datadog 的免費試用吧。
via: https://www.datadoghq.com/blog/how-to-collect-nginx-metrics/
作者:K Young 譯者:strugglingyouth 校對:wxy
本文轉載來自 Linux 中國: https://github.com/Linux-CN/archive
對這篇文章感覺如何?
You may also like





More in:Linux中國
捐贈 Let's Encrypt,共建安全的互聯網
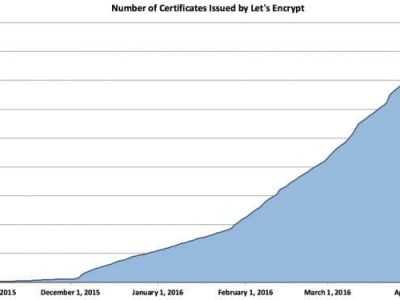
Let's Encrypt 正式發布,已經保護 380 萬個域名
關於Linux防火牆iptables的面試問答
Lets Encrypt 已被所有主流瀏覽器所信任








