Reddit 如何實現大規模的帖子瀏覽計數
我們希望更好地將 Reddit 的規模傳達給我們的用戶。到目前為止,投票得分和評論數量是特定的帖子活動的主要指標。然而,Reddit 有許多訪問者在沒有投票或評論的情況下閱讀內容。我們希望建立一個能夠捕捉到帖子閱讀數量的系統。然後將該數量展示給內容創建者和版主,以便他們更好地了解特定帖子上的活動。

在這篇文章中,我們將討論我們如何大規模地實現計數。
計數方法
對瀏覽計數有四個主要要求:
- 計數必須是實時的或接近實時的。不是每天或每小時的總量。
- 每個用戶在短時間內只能計數一次。
- 顯示的數量與實際的誤差在百分之幾。
- 系統必須能夠在生產環境運行,並在事件發生後幾秒內處理事件。
滿足這四項要求比聽起來要複雜得多。為了實時保持準確的計數,我們需要知道某個特定的用戶是否曾經訪問過這個帖子。要知道這些信息,我們需要存儲先前訪問過每個帖子的用戶組,然後在每次處理對該帖子的新訪問時查看該組。這個解決方案的一個原始實現是將這個唯一用戶的集合作為散列表存儲在內存中,並且以帖子 ID 作為鍵名。
這種方法適用於瀏覽量較少的文章,但一旦文章流行,閱讀人數迅速增加,這種方法很難擴展。有幾個熱門的帖子有超過一百萬的唯一讀者!對於這種帖子,對於內存和 CPU 來說影響都很大,因為要存儲所有的 ID,並頻繁地查找集合,看看是否有人已經訪問過。
由於我們不能提供精確的計數,我們研究了幾個不同的基數估計演算法。我們考慮了兩個非常符合我們期望的選擇:
- 線性概率計數方法,非常準確,但要計數的集合越大,則線性地需要更多的內存。
- 基於 HyperLogLog(HLL)的計數方法。HLL 隨集合大小 次線性 增長,但不能提供與線性計數器相同的準確度。
要了解 HLL 真正節省的空間大小,看一下這篇文章頂部包括的 r/pics 帖子。它有超過 100 萬的唯一用戶。如果我們存儲 100 萬個唯一用戶 ID,並且每個用戶 ID 是 8 個位元組長,那麼我們需要 8 兆內存來計算單個帖子的唯一用戶數!相比之下,使用 HLL 進行計數會佔用更少的內存。每個實現的內存量是不一樣的,但是對於這個實現,我們可以使用僅僅 12 千位元組的空間計算超過一百萬個 ID,這將是原始空間使用量的 0.15%!
(這篇關於高可伸縮性的文章很好地概述了上述兩種演算法。)
許多 HLL 實現使用了上述兩種方法的組合,即對於小集合以線性計數開始,並且一旦大小達到特定點就切換到 HLL。前者通常被稱為 「稀疏」 HLL 表達,而後者被稱為「密集」 HLL 表達。混合的方法是非常有利的,因為它可以提供準確的結果,同時保留適度的內存佔用量。這個方法在 Google 的 HyperLogLog++ 論文中有更詳細的描述。
雖然 HLL 演算法是相當標準的,但在我們的實現中我們考慮使用三種變體。請注意,對於內存中的 HLL 實現,我們只關注 Java 和 Scala 實現,因為我們主要在數據工程團隊中使用 Java 和 Scala。
- Twitter 的 Algebird 庫,用 Scala 實現。Algebird 有很好的使用文檔,但是稀疏和密集的 HLL 表達的實現細節不容易理解。
- 在 stream-lib 中的 HyperLogLog++ 的實現,用 Java 實現。stream-lib 中的代碼有很好的文檔,但是要理解如何正確使用這個庫並且調整它以滿足我們的需求是有些困難的。
- Redis 的 HLL 實現(我們選擇的)。我們認為,Redis 的 HLL 實施方案有很好的文檔並且易於配置,所提供的 HLL 相關的 API 易於集成。作為一個額外的好處,使用 Redis 通過將計數應用程序(HLL 計算)的 CPU 和內存密集型部分移出並將其移至專用伺服器上,從而緩解了我們的許多性能問題。

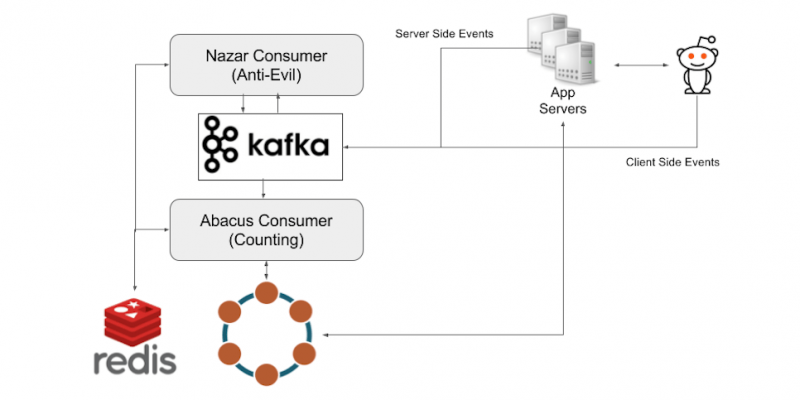
Reddit 的數據管道主要圍繞 Apache Kafka。當用戶查看帖子時,事件被激發並發送到事件收集器伺服器,該伺服器批量處理事件並將其保存到 Kafka 中。
從這裡,瀏覽計數系統有兩個按順序運行的組件。我們的計數架構的第一部分是一個名為 Nazar 的 Kafka 消費者,它將讀取來自 Kafka 的每個事件,並通過我們編製的一組規則來確定是否應該計算一個事件。我們給它起了這個名字是因為 Nazar 是一個保護你免受邪惡的眼形護身符,Nazar 系統是一個「眼睛」,它可以保護我們免受不良因素的影響。Nazar 使用 Redis 保持狀態,並跟蹤不應計算瀏覽的潛在原因。我們可能無法統計事件的一個原因是,由於同一用戶在短時間內重複瀏覽的結果。Nazar 接著將改變事件,添加一個布爾標誌表明是否應該被計數,然後再發回 Kafka 事件。
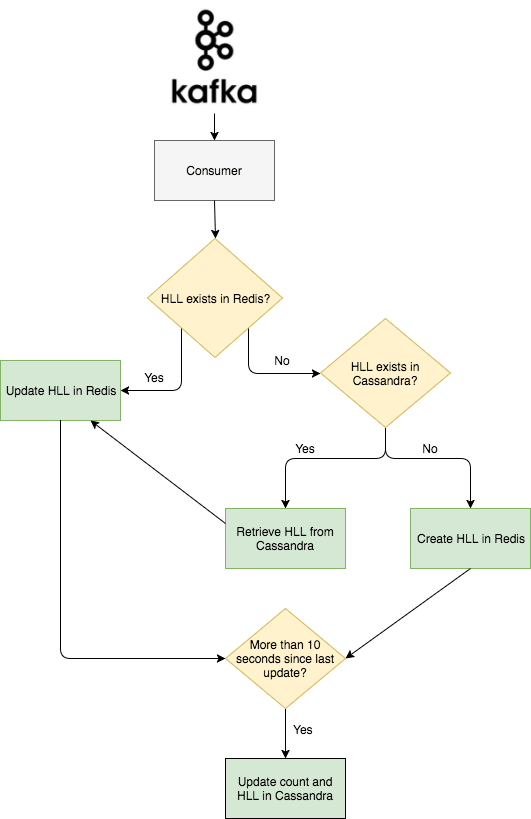
這是這個項目要說的第二部分。我們有第二個叫做 Abacus 的 Kafka 消費者,它實際上對瀏覽進行計數,並使計數在網站和客戶端可見。Abacus 讀取 Nazar 輸出的 Kafka 事件。接著,根據 Nazar 的決定,它將計算或跳過本次瀏覽。如果事件被標記為計數,那麼 Abacus 首先檢查 Redis 中是否存在已經存在與事件對應的帖子的 HLL 計數器。如果計數器已經在 Redis 中,那麼 Abacus 向 Redis 發出一個 PFADD 的請求。如果計數器還沒有在 Redis 中,那麼 Abacus 向 Cassandra 集群發出請求,我們用這個集群來持久化 HLL 計數器和原始計數,並向 Redis 發出一個 SET 請求來添加過濾器。這種情況通常發生在人們查看已經被 Redis 刪除的舊帖的時候。
為了保持對可能從 Redis 刪除的舊帖子的維護,Abacus 定期將 Redis 的完整 HLL 過濾器以及每個帖子的計數記錄到 Cassandra 集群中。 Cassandra 的寫入以 10 秒一組分批寫入,以避免超載。下面是一個高層的事件流程圖。
總結
我們希望瀏覽量計數器能夠更好地幫助內容創作者了解每篇文章的情況,並幫助版主快速確定哪些帖子在其社區擁有大量流量。未來,我們計劃利用數據管道的實時潛力向更多的人提供更多有用的反饋。
如果你有興趣解決這樣的問題,請查看我們的職位頁面。
via: https://redditblog.com/2017/05/24/view-counting-at-reddit/
作者:Krishnan Chandra 譯者:geekpi 校對:wxy
本文轉載來自 Linux 中國: https://github.com/Linux-CN/archive
對這篇文章感覺如何?
You may also like






More in:Linux中國

捐贈 Let's Encrypt,共建安全的互聯網

Let's Encrypt 正式發布,已經保護 380 萬個域名

關於Linux防火牆iptables的面試問答

Lets Encrypt 已被所有主流瀏覽器所信任









