Linux 的 EXT4 文件系統的歷史、特性以及最佳實踐

在之前關於 Linux 文件系統的文章里,我寫過一篇 Linux 文件系統介紹 和一些更高級的概念例如 一切都是文件。現在我想要更深入地了解 EXT 文件系統的特性的詳細內容,但是首先讓我們來回答一個問題,「什麼樣才算是一個文件系統 ?」 一個文件系統應該涵蓋以下所有特點:
- 數據存儲: 對於任何一個文件系統來說,一個最主要的功能就是能夠被當作一個結構化的容器來存儲和獲取數據。
- 命名空間: 命名空間是一個提供了用於命名與組織數據的命名規則和數據結構的方法學。
- 安全模型: 一個用於定義訪問許可權的策略。
- API: 操作這個系統的對象的系統功能調用,這些對象諸如目錄和文件。
- 實現: 能夠實現以上幾點的軟體。
本文內容的討論主要集中於上述幾點中的第一項,並探索為一個 EXT 文件系統的數據存儲提供邏輯框架的元數據結構。
EXT 文件系統歷史
雖然 EXT 文件系統是為 Linux 編寫的,但其真正起源於 Minix 操作系統和 Minix 文件系統,而 Minix 最早發佈於 1987,早於 Linux 5 年。如果我們從 EXT 文件系統大家族的 Minix 起源來觀察其歷史與技術發展那麼理解 EXT4 文件系統就會簡單得多。
Minix
當 Linux Torvalds 在寫最初的 Linux 內核的時候,他需要一個文件系統但是他又不想自己寫一個。於是他簡單地把 Minix 文件系統 加了進去,這個 Minix 文件系統是由 Andrew S. Tanenbaum 寫的,同時它也是 Tanenbaum 的 Minix 操作系統的一部分。Minix 是一個類 Unix 風格的操作系統,最初編寫它的原因是用於教育用途。Minix 的代碼是自由可用的並有適當的許可協議,所以 Torvalds 可以把它用 Linux 的最初版本里。
Minix 有以下這些結構,其中的大部分位於生成文件系統的分區中:
- 引導扇區 是硬碟安裝後的第一個扇區。這個引導塊包含了一個非常小的引導記錄和一個分區表。
- 每一個分區的第一個塊都是一個包含了元數據的 超級塊 ,這些元數據定義了其他的文件系統結構並將其定位於物理硬碟的具體分區上。
- 一個 inode 點陣圖塊 決定了哪些 inode 是在使用中的,哪一些是未使用的。
- inode 在硬碟上有它們自己的空間。每一個 inode 都包含了一個文件的信息,包括其所處的數據塊的位置,也就是該文件所處的區域。
- 一個 區點陣圖 用於保持追蹤數據區域的使用和未使用情況。
- 一個 數據區, 這裡是數據存儲的地方。
對上述了兩種點陣圖類型來說,一個 位 表示一個指定的數據區或者一個指定的 inode。 如果這個位是 0 則表示這個數據區或者這個 inode 是未使用的,如果是 1 則表示正在使用中。
那麼,inode 又是什麼呢 ? 就是 index-node(索引節點)的簡寫。 inode 是位於磁碟上的一個 256 位元組的塊,用於存儲和該 inode 對應的文件的相關數據。這些數據包含了文件的大小、文件的所有者和所屬組的用戶 ID、文件模式(即訪問許可權)以及三個時間戳用於指定:該文件最後的訪問時間、該文件的最後修改時間和該 inode 中的數據的最後修改時間。
同時,這個 inode 還包含了位置數據,指向了其所對應的文件數據在硬碟中的位置。在 Minix 和 EXT 1-3 文件系統中,這是一個數據區和塊的列表。Minix 文件系統的 inode 支持 9 個數據塊,包括 7 個直接數據塊和 2 個間接數據塊。如果你想要更深入的了解,這裡有一個優秀的 PDF 詳細地描述了 Minix 文件系統結構 。同時你也可以在維基百科上對 inode 指針結構 做一個快速了解。
EXT
原生的 EXT 文件系統 (意即 擴展的 ) 是由 Rémy Card 編寫並於 1992 年與 Linux 一同發行。主要是為了克服 Minix 文件系統中的一些文件大小限制的問題。其中,最主要的結構變化就是文件系統中的元數據。它基於 Unix 文件系統 (UFS),其也被稱為伯克利快速文件系統(FFS)。我發現只有很少一部分關於 EXT 文件系統的發行信息是可以被確證的,顯然這是因為其存在著嚴重的問題,並且它很快地被 EXT2 文件系統取代了。
EXT2
EXT2 文件系統 就相當地成功,它在 Linux 發行版中存活了多年。它是我在 1997 年開始使用 Red Hat Linux 5.0 時接觸的第一個文件系統。實際上,EXT2 文件系統有著和 EXT 文件系統基本相同的元數據結構。然而 EXT2 更高瞻遠矚,因為其元數據結構之間留有很多供將來使用的磁碟空間。
和 Minix 類似,EXT2 也有一個引導扇區 ,它是硬碟安裝後的第一個扇區。它包含了非常小的引導記錄和一個分區表。接著引導扇區之後是一些保留的空間,它填充了引導記錄和硬碟驅動器上的第一個分區(通常位於下一個柱面)之間的空間。GRUB2 - 也可能是 GRUB1 - 將此空間用於其部分引導代碼。
每個 EXT2 分區中的空間被分為 柱面組 ,它允許更精細地管理數據空間。 根據我的經驗,每一組大小通常約為 8MB。 下面的圖 1 顯示了一個柱面組的基本結構。 柱面中的數據分配單元是塊,通常大小為 4K。

圖 1: EXT 文件系統中的柱面組的結構
柱面組中的第一個塊是一個 超級塊 ,它包含了元數據,定義了其它文件系統的結構並將其定位於物理硬碟的具體分區上。分區中有一些柱面組還會有備用超級塊,但並不是所有的柱面組都有。我們可以使用例如 dd 等磁碟工具來拷貝備用超級塊的內容到主超級塊上,以達到修復損壞的超級塊的目的。雖然這種情況不會經常發生,但是在幾年前我的一個超級塊損壞了,我就是用這種方法來修復的。幸好,我很有先見之明地使用了 dumpe2fs 命令來備份了我的系統上的分區描述符信息。
以下是 dumpe2fs 命令的一部分輸出。這部分輸出主要是超級塊上包含的一些元數據,同時也是文件系統上的前兩個柱面組的數據。
# dumpe2fs /dev/sda1
Filesystem volume name: boot
Last mounted on: /boot
Filesystem UUID: 79fc5ed8-5bbc-4dfe-8359-b7b36be6eed3
Filesystem magic number: 0xEF53
Filesystem revision #: 1 (dynamic)
Filesystem features: has_journal ext_attr resize_inode dir_index filetype needs_recovery extent 64bit flex_bg sparse_super large_file huge_file dir nlink extra_isize
Filesystem flags: signed_directory_hash
Default mount options: user_xattr acl
Filesystem state: clean
Errors behavior: Continue
Filesystem OS type: Linux
Inode count: 122160
Block count: 488192
Reserved block count: 24409
Free blocks: 376512
Free inodes: 121690
First block: 0
Block size: 4096
Fragment size: 4096
Group descriptor size: 64
Reserved GDT blocks: 238
Blocks per group: 32768
Fragments per group: 32768
Inodes per group: 8144
Inode blocks per group: 509
Flex block group size: 16
Filesystem created: Tue Feb 7 09:33:34 2017
Last mount time: Sat Apr 29 21:42:01 2017
Last write time: Sat Apr 29 21:42:01 2017
Mount count: 25
Maximum mount count: -1
Last checked: Tue Feb 7 09:33:34 2017
Check interval: 0 (<none>)
Lifetime writes: 594 MB
Reserved blocks uid: 0 (user root)
Reserved blocks gid: 0 (group root)
First inode: 11
Inode size: 256
Required extra isize: 32
Desired extra isize: 32
Journal inode: 8
Default directory hash: half_md4
Directory Hash Seed: c780bac9-d4bf-4f35-b695-0fe35e8d2d60
Journal backup: inode blocks
Journal features: journal_64bit
Journal size: 32M
Journal length: 8192
Journal sequence: 0x00000213
Journal start: 0
Group 0: (Blocks 0-32767)
Primary superblock at 0, Group descriptors at 1-1
Reserved GDT blocks at 2-239
Block bitmap at 240 (+240)
Inode bitmap at 255 (+255)
Inode table at 270-778 (+270)
24839 free blocks, 7676 free inodes, 16 directories
Free blocks: 7929-32767
Free inodes: 440, 470-8144
Group 1: (Blocks 32768-65535)
Backup superblock at 32768, Group descriptors at 32769-32769
Reserved GDT blocks at 32770-33007
Block bitmap at 241 (bg #0 + 241)
Inode bitmap at 256 (bg #0 + 256)
Inode table at 779-1287 (bg #0 + 779)
8668 free blocks, 8142 free inodes, 2 directories
Free blocks: 33008-33283, 33332-33791, 33974-33975, 34023-34092, 34094-34104, 34526-34687, 34706-34723, 34817-35374, 35421-35844, 35935-36355, 36357-36863, 38912-39935, 39940-40570, 42620-42623, 42655, 42674-42687, 42721-42751, 42798-42815, 42847, 42875-42879, 42918-42943, 42975, 43000-43007, 43519, 43559-44031, 44042-44543, 44545-45055, 45116-45567, 45601-45631, 45658-45663, 45689-45695, 45736-45759, 45802-45823, 45857-45887, 45919, 45950-45951, 45972-45983, 46014-46015, 46057-46079, 46112-46591, 46921-47103, 49152-49395, 50027-50355, 52237-52255, 52285-52287, 52323-52351, 52383, 52450-52479, 52518-52543, 52584-52607, 52652-52671, 52734-52735, 52743-53247
Free inodes: 8147-16288
Group 2: (Blocks 65536-98303)
Block bitmap at 242 (bg #0 + 242)
Inode bitmap at 257 (bg #0 + 257)
Inode table at 1288-1796 (bg #0 + 1288)
6326 free blocks, 8144 free inodes, 0 directories
Free blocks: 67042-67583, 72201-72994, 80185-80349, 81191-81919, 90112-94207
Free inodes: 16289-24432
Group 3: (Blocks 98304-131071)
<截斷>
每一個柱面組都有自己的 inode 點陣圖,用於判定該柱面組中的哪些 inode 是使用中的而哪些又是未被使用的。每一個柱面組的 inode 都有它們自己的空間。每一個 inode 都包含了一個文件的相關信息,包括屬於該文件的數據塊的位置。而塊點陣圖紀錄了文件系統中的使用中和非使用中的數據塊。請注意,在上面的輸出中有大量關於文件系統的數據。在非常大的文件系統上,柱面組的數據可以多達數百頁的長度。柱面組的元數據包括組中所有空閑數據塊的列表。
EXT 文件系統實現了數據分配策略以確保產生最少的文件碎片。減少文件碎片可以提高文件系統的性能。這些策略會在下面的 EXT4 中描述到。
我所遇見的關於 EXT2 文件系統最大的問題是 fsck (文件系統檢查) 程序這一環節佔用了很長一段時間來定位和校準文件系統中的所有的不一致性,從而導致在系統 崩潰 後其會花費了數個小時來修復。有一次我的其中一台電腦在崩潰後重新啟動時共花費了 28 個小時恢復磁碟,而且並且是在磁碟被檢測量只有幾百兆位元組大小的情況下。
EXT3
EXT3 文件系統是應一個目標而生的,就是克服 fsck 程序需要完全恢復在文件更新操作期間發生的不正確關機而損壞的磁碟結構所需的大量時間。它對 EXT 文件系統的唯一新增功能就是 日誌,它將提前記錄將對文件系統執行的更改。 EXT3 的磁碟結構的其餘部分與 EXT2 中的相同。
除了同先前的版本一樣直接寫入數據到磁碟的數據區域外,EXT3 上的日誌會將文件數據隨同元數據寫入到磁碟上的一個指定數據區域。一旦這些(日誌)數據安全地到達硬碟,它就可以幾乎零丟失率地被合併或被追加到目標文件上。當這些數據被提交到磁碟上的數據區域上,這些日誌就會隨即更新,這樣在日誌中的所有數據提交之前,系統發生故障時文件系統將保持一致狀態。在下次啟動時,將檢查文件系統的不一致性,然後將仍保留在日誌中的數據提交到磁碟的數據區,以完成對目標文件的更新。
日誌功能確實降低了數據寫入性能,但是有三個可用於日誌的選項,允許用戶在性能和數據完整性、安全性之間進行選擇。 我的個人更偏向於選擇安全性,因為我的環境不需要大量的磁碟寫入活動。
日誌功能將失敗後檢查硬碟驅動器所需的時間從幾小時(甚至幾天)減少到了幾分鐘。 多年來,我遇到了很多導致我的系統崩潰的問題。要詳細說的話恐怕還得再寫一篇文章,但這裡需要說明的是大多數是我自己造成的,就比如不小心踢掉電源插頭。 幸運的是,EXT 日誌文件系統將啟動恢復時間縮短到兩三分鐘。此外,自從我開始使用帶日誌記錄的 EXT3,我從來沒有遇到丟失數據的問題。
EXT3 的日誌功能可以關閉,然後其功能就等同於 EXT2 文件系統了。 該日誌本身仍然是存在的,只是狀態為空且未使用。 只需在 mount 命令中使用文件系統類型參數來重新掛載即可指定為 EXT2。 你可以從命令行執行此操作,但是具體還是取決於你正在使用的文件系統,不過你也可以更改 /etc/fstab 文件中的類型說明符,然後重新啟動。 我強烈建議不要將 EXT3 文件系統掛載為 EXT2 ,因為這會有丟失數據和增加恢復時間的潛在可能性。
EXT2 文件系統可以使用如下命令來通過日誌升級到 EXT3 。
tune2fs -j /dev/sda1
/dev/sda1 表示驅動器和分區的標識符。同時要注意修改 /etc/fstab 中的文件系統類型標識符並重新掛載分區,或者重啟系統以確保修改生效。
EXT4
EXT4 文件系統主要提高了性能、可靠性和容量。為了提高可靠性,它新增了元數據和日誌校驗和。同時為了滿足各種關鍵任務要求,文件系統新增了納秒級別的時間戳,並在時間戳欄位中添加了兩個高位來延緩時間戳的 2038 年問題 ,這樣 EXT4 文件系統至少可用到 2446 年。
在 EXT4 中,數據分配從固定塊改為 擴展盤區 方式,擴展盤區由硬碟驅動器上的開始和結束位置來描述。這使得可以在單個 inode 指針條目中描述非常長的物理上連續的文件,這可以顯著減少描述大文件中所有數據的位置所需的指針數。其它在 EXT4 中已經實施的分配策略可以進一步減少碎片化。
EXT4 通過將新創建的文件散布在磁碟上,使其不會像早期的 PC 文件系統一樣全部聚集在磁碟起始位置,從而減少了碎片。文件分配演算法嘗試在柱面組中儘可能均勻地散布文件,並且當文件(由於太大)需要分段存儲時,使不連續的文件擴展盤區儘可能靠近同一文件中的其他部分,以儘可能減少磁頭尋道和電機旋轉等待時間。當創建新文件或擴展現有文件時,使用其它策略來預先分配額外的磁碟空間。這有助於確保擴展文件時不會自動導致其分段。新文件不會緊挨這現有文件立即分配空間,這也可以防止現有文件的碎片化。
除了磁碟上數據的實際位置外,EXT4 使用諸如延遲分配的功能策略,以允許文件系統在分配空間之前收集到所有正在寫入磁碟的數據,這可以提高數據空間連續的可能性。
較舊的 EXT 文件系統(如 EXT2 和 EXT3)可以作為 EXT4 進行 mount ,以使其性能獲得較小的提升。但不幸的是,這需要關閉 EXT4 的一些重要的新功能,所以我建議不要這樣做。
自 Fedora 14 以來,EXT4 一直是 Fedora 的默認文件系統。我們可以使用 Fedora 文檔中描述的 流程 將 EXT3 文件系統升級到 EXT4,但是由於仍然存留的之前的 EXT3 元數據結構,它的性能仍將受到影響。從 EXT3 升級到 EXT4 的最佳方法是備份目標文件系統分區上的所有數據,使用 mkfs 命令將空 EXT4 文件系統寫入分區,然後從備份中恢復所有數據。
Inode
之前介紹過的 inode 是 EXT 文件系統中的元數據的關鍵組件。 圖 2 顯示了 inode 和存儲在硬碟驅動器上的數據之間的關係。 該圖是單個文件的目錄和 inode,在這種情況下,可能會產生高度碎片化。 EXT 文件系統可以主動地減少碎片,所以不太可能會看到有這麼多間接數據塊或擴展盤區的文件。 實際上,你在下面將會看到,EXT 文件系統中的碎片非常低,所以大多數 inode 只使用一個或兩個直接數據指針,而不使用間接指針。
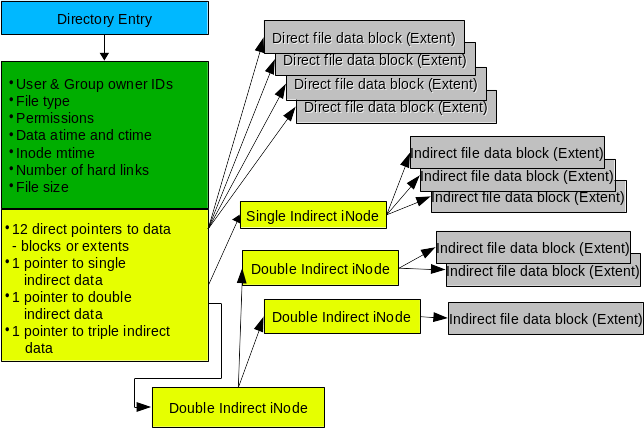
圖 2 :inode 存儲有關每個文件的信息,並使 EXT 文件系統能夠查找屬於它的所有數據。
inode 不包含文件的名稱。通過目錄項訪問文件,目錄項本身就是文件的名稱,並包含指向 inode 的指針。該指針的值是 inode 號。文件系統中的每個 inode 都具有唯一的 ID 號,但同一台計算機上的其它文件系統(甚至是相同的硬碟驅動器)中的 inode 可以具有相同的 inode 號。這對 硬鏈接 存在影響,但是這個討論超出了本文的範圍。
inode 包含有關該文件的元數據,包括其類型和許可權以及其大小。 inode 還包含 15 個指針的空位,用於描述柱面組數據部分中數據塊或擴展盤區的位置和長度。12 個指針提供對數據擴展盤區的直接訪問,應該足以滿足大多數文件的需求。然而,對於具有明顯分段的文件,需要以間接 節點 的形式提供一些額外的容量——從技術上講,這些不是真正的「inode」,所以為了方便起見我在這裡使用這個術語「 節點 」。
間接節點是文件系統中的正常數據塊,它僅用於描述數據而不用於存儲元數據,因此可以支持超過 15 個條目。例如,4K 的塊大小可以支持 512 個 4 位元組的間接節點,允許單個文件有 12(直接)+ 512(間接)= 524 個擴展盤區。還支持雙重和三重間接節點,但我們大多數人不太可能遇到需要那麼多擴展盤區的文件。
數據碎片
對於許多較舊的 PC 文件系統,如 FAT(及其所有變體)和 NTFS,碎片一直是導致磁碟性能下降的重大問題。 碎片整理本身就成為一個行業,有各種品牌的整理軟體,其效果範圍從非常有效到僅僅是微乎其微。
Linux 的擴展文件系統使用數據分配策略,有助於最小化硬碟驅動器上的文件碎片,並在發生碎片時減少碎片的影響。 你可以使用 EXT 文件系統上的 fsck 命令檢查整個文件系統的碎片。 以下示例檢查我的主工作站的家目錄,只有 1.5% 的碎片。 確保使用 -n 參數,因為它會防止 fsck 對掃描的文件系統採取任何操作。
fsck -fn /dev/mapper/vg_01-home
我曾經進行過一些理論計算,以確定磁碟碎片整理是否會產生任何明顯的性能提升。 我做了一些假設條件,我使用的磁碟性能數據來自一個新的 300GB 的西部數字硬碟驅動器,具有 2.0ms 的軌到軌尋道時間。 此示例中的文件數是我在計算的當天的文件系統中存在的實際數。 我假設每天有相當大量的碎片化文件(約 20%)會被用到。
| 全部文件 | 271,794 |
|---|---|
| 碎片率 % | 5.00% |
| 不連續數 | 13,590 |
| % 每天用到的碎片化文件 | 20% (假設) |
| 額外尋道次數 | 2,718 |
| 平均尋道時間 | 10.90 ms |
| 每天全部的額外尋道時間 | 29.63 sec |
| 0.49 min | |
| 軌到軌尋道時間 | 2.00 ms |
| 每天全部的額外尋道時間 | 5.44 sec |
| 0.091 min |
表 1: 碎片對磁碟性能的理論影響
我對每天的全部的額外尋道時間進行了兩次計算,一次是軌到軌尋道時間,這是由於 EXT 文件分配策略而導致大多數文件最可能的情況,一個是平均尋道時間,我假設這是一個合理的最壞情況。
從表 1 可以看出,對絕大多數應用程序而言,碎片化甚至對性能適中的硬碟驅動器上的現代 EXT 文件系統的影響是微乎其微的。您可以將您的環境中的數字插入到您自己的類似電子表格中,以了解你對性能影響的期望。這種類型的計算不一定能夠代表實際的性能,但它可以提供一些對碎片化及其對系統的理論影響的洞察。
我的大部分分區的碎片率都在 1.5% 左右或 1.6%,我有一個分區有 3.3% 的碎片,但是這是一個大約 128GB 文件系統,具有不到 100 個非常大的 ISO 映像文件;多年來,我擴展過該分區幾次,因為它已經太滿了。
這並不是說一些應用的環境並不需要更少的碎片的環境。 EXT 文件系統可以由有經驗和知識的管理員小心調整,管理員可以針對特定的工作負載類型調整參數。這個工作可以在文件系統創建的時候或稍後使用 tune2fs 命令時完成。每一次調整變化的結果應進行測試,精心的記錄和分析,以確保目標環境的最佳性能。在最壞的情況下,如果性能不能提高到期望的水平,則其他文件系統類型可能更適合特定的工作負載。並記住,在單個主機系統上混用文件系統類型以匹配每個文件系統上的不同負載是常見的。
由於大多數 EXT 文件系統的碎片數量較少,因此無需進行碎片整理。目前,EXT 文件系統沒有安全的碎片整理工具。有幾個工具允許你檢查單個文件的碎片程度或文件系統中剩餘可用空間的碎片程度。有一個工具,e4defrag,它可以對允許使用的剩餘可用空間、目錄或文件系統進行碎片整理。顧名思義,它只適用於 EXT4 文件系統中的文件,並且它還有一其它的些限制。
如果有必要在 EXT 文件系統上執行完整的碎片整理,則只有一種方法能夠可靠地工作。你必須將文件系統中的所有要進行碎片整理的文件移動從而進行碎片整理,並在確保安全複製到其他位置後將其刪除。如果可能,你可以增加文件系統的大小,以幫助減少將來的碎片。然後將文件複製回目標文件系統。但是其實即使這樣也不能保證所有文件都被完全去碎片化。
總結
EXT 文件系統在一些 Linux 發行版本上作為默認文件系統已經超過二十多年了。它們用最少的維護代價提供了穩定性、高可用性、可靠性和性能。我嘗試過一些其它的文件系統但最終都還是回歸到 EXT。每一個我在工作中使用到 Linux 的地方都使用到了 EXT 文件系統,同時我發現了它們適用於任何主流負載。毫無疑問,EXT4 文件系統應該被用於大部分的 Linux 文件系統上,除非我們有明顯需要使用其它文件系統的理由。
作者簡介:
David Both - David Both 是一名 Linux 於開源的貢獻者,目前居住在北卡羅萊納州的羅利。他從事 IT 行業有 40 余年並在 IBM 中從事 OS/2 培訓約 20 余年。在 IBM 就職期間,他在 1981 年為最早的 IBM PC 寫了一個培訓課程。他已經為紅帽教授了 RHCE 課程,曾在 MCI Worldcom,思科和北卡羅來納州工作。 他使用 Linux 和開源軟體工作了近 20 年。
via: https://opensource.com/article/17/5/introduction-ext4-filesystem
作者:David Both 譯者:chenxinlong 校對:wxy
本文轉載來自 Linux 中國: https://github.com/Linux-CN/archive
對這篇文章感覺如何?
You may also like






More in:Linux中國

捐贈 Let's Encrypt,共建安全的互聯網

Let's Encrypt 正式發布,已經保護 380 萬個域名

關於Linux防火牆iptables的面試問答

Lets Encrypt 已被所有主流瀏覽器所信任









