GitHub 的 MySQL 基礎架構自動化測試

我們 MySQL 資料庫基礎架構是 Github 關鍵組件。 MySQL 提供 Github.com、 GitHub 的 API 和驗證等等的服務。每一次的 git 請求都以某種方式觸及 MySQL。我們的任務是保持數據的可用性,並保持其完整性。即使我們 MySQL 集群是按流量分配的,但是我們還是需要執行深度清理、即時更新、在線 模式 遷移、集群拓撲重構、 連接池化 和負載平衡等任務。 我們建有基礎架構來自動化測試這些操作,在這篇文章中,我們將分享幾個例子,來說明我們是如何通過持續測試打造我們的基礎架構的。這是讓我們一夢到天亮的根本保障。
備份
沒有比備份數據更重要的了,如果您沒有備份資料庫,在它出事前這可能並不是什麼問題。Percona 的 Xtrabackup 是我們一直用來完整備份 MySQL 資料庫的工具。如果有專門需要備份的數據,我們就會備份到另一個專門備份數據的伺服器上。
除了完整的二進位備份外,我們每天還會多次運行邏輯備份。這些備份數據可以讓我們的工程師獲取到最新的數據副本。有時候,他們希望從表中獲取一整套數據,以便他們可以在一個生產級規模的表上測試索引的修改,或查看特定時間以來的數據。Hubot 可以讓我們恢復備份的表,並且當表準備好使用時會通知我們。
tomkrouper
.mysql backup-list locations
Hubot
+-----------+------------+---------------+---------------------+---------------------+----------------------------------------------+
| Backup ID | Table Name | Donor Host | Backup Start | Backup End | File Name |
+-----------+------------+---------------+---------------------+---------------------+----------------------------------------------+
| 1699494 | locations | db-mysql-0903 | 2017-07-01 22:09:17 | 2017-07-01 22:09:17 | backup-mycluster-locations-1498593122.sql.gz |
| 1699133 | locations | db-mysql-0903 | 2017-07-01 16:11:37 | 2017-07-01 16:11:39 | backup-mycluster-locations-1498571521.sql.gz |
| 1698772 | locations | db-mysql-0903 | 2017-07-01 10:09:21 | 2017-07-01 10:09:22 | backup-mycluster-locations-1498549921.sql.gz |
| 1698411 | locations | db-mysql-0903 | 2017-07-01 04:12:32 | 2017-07-01 04:12:32 | backup-mycluster-locations-1498528321.sql.gz |
| 1698050 | locations | db-mysql-0903 | 2017-06-30 22:18:23 | 2017-06-30 22:18:23 | backup-mycluster-locations-1498506721.sql.gz |
| ...
| 1262253 | locations | db-mysql-0088 | 2016-08-01 01:58:51 | 2016-08-01 01:58:54 | backup-mycluster-locations-1470034801.sql.gz |
| 1064984 | locations | db-mysql-0088 | 2016-04-04 13:07:40 | 2016-04-04 13:07:43 | backup-mycluster-locations-1459494001.sql.gz |
+-----------+------------+---------------+---------------------+---------------------+----------------------------------------------+
tomkrouper
.mysql restore 1699133
Hubot
A restore job has been created for the backup job 1699133. You will be notified in #database-ops when the restore is complete.
Hubot
@tomkrouper: the locations table has been restored as locations_2017_07_01_16_11 in the restores database on db-mysql-0482
數據被載入到非生產環境的資料庫,該資料庫可供請求該次恢復的工程師訪問。
我們保留數據的「備份」的最後一個方法是使用 延遲副本 。這與其說是備份,不如說是保護。對於每個生產集群,我們有一個延遲 4 個小時複製的主機。如果運行了一個不該運行的請求,我們可以在 chatops 中運行 mysql panic 。這將導致我們所有的延遲副本立即停止複製。這也將給值班 DBA 發送消息。從而我們可以使用延遲副本來驗證是否有問題,並快速前進到二進位日誌的錯誤發生之前的位置。然後,我們可以將此數據恢復到主伺服器,從而恢複數據到該時間點。
備份固然好,但如果發生了一些未知或未捕獲的錯誤破壞它們,它們就沒有價值了。讓腳本恢復備份的好處是它允許我們通過 cron 自動執行備份驗證。我們為每個集群設置了一個專用的主機,用於運行最新備份的恢復。這樣可以確保備份運行正常,並且我們能夠從備份中檢索數據。
根據數據集大小,我們每天運行幾次恢復。恢復的伺服器被加入到複製工作流,並通過複製保持數據更新。這測試不僅讓我們得到了可恢復的備份,而且也讓我們得以正確地確定備份的時間點,並且可以從該時間點進一步應用更改。如果恢復過程中出現問題,我們會收到通知。
我們還追蹤恢復所需的時間,所以我們知道在緊急情況下建立新的副本或還原需要多長時間。
以下是由 Hubot 在我們的機器人聊天室中輸出的自動恢復過程。
Hubot
gh-mysql-backup-restore: db-mysql-0752: restore_log.id = 4447
gh-mysql-backup-restore: db-mysql-0752: Determining backup to restore for cluster 'prodcluster'.
gh-mysql-backup-restore: db-mysql-0752: Enabling maintenance mode
gh-mysql-backup-restore: db-mysql-0752: Setting orchestrator downtime
gh-mysql-backup-restore: db-mysql-0752: Disabling Puppet
gh-mysql-backup-restore: db-mysql-0752: Stopping MySQL
gh-mysql-backup-restore: db-mysql-0752: Removing MySQL files
gh-mysql-backup-restore: db-mysql-0752: Running gh-xtrabackup-restore
gh-mysql-backup-restore: db-mysql-0752: Restore file: xtrabackup-notify-2017-07-02_0000.xbstream
gh-mysql-backup-restore: db-mysql-0752: Running gh-xtrabackup-prepare
gh-mysql-backup-restore: db-mysql-0752: Starting MySQL
gh-mysql-backup-restore: db-mysql-0752: Update file ownership
gh-mysql-backup-restore: db-mysql-0752: Upgrade MySQL
gh-mysql-backup-restore: db-mysql-0752: Stopping MySQL
gh-mysql-backup-restore: db-mysql-0752: Starting MySQL
gh-mysql-backup-restore: db-mysql-0752: Backup Host: db-mysql-0034
gh-mysql-backup-restore: db-mysql-0752: Setting up replication
gh-mysql-backup-restore: db-mysql-0752: Starting replication
gh-mysql-backup-restore: db-mysql-0752: Replication catch-up
gh-mysql-backup-restore: db-mysql-0752: Restore complete (replication running)
gh-mysql-backup-restore: db-mysql-0752: Enabling Puppet
gh-mysql-backup-restore: db-mysql-0752: Disabling maintenance mode
gh-mysql-backup-restore: db-mysql-0752: Setting orchestrator downtime
gh-mysql-backup-restore: db-mysql-0752: Restore process complete.
還有一件我們可以使用備份做的事情是向一組現有的 MySQL 伺服器添加一個新的副本。我們初始化一個新的伺服器,一旦我們得知它準備就緒,我們就可以開始恢復該特定集群的最新備份。我們有一個腳本,可以運行所有需要手動執行的恢復命令。我們的自動恢復系統基本上使用的是相同的腳本。這簡化了系統構建過程,並允許我們在一個啟動運行的主機上使用幾個對話命令(chatops)來替代一堆手動執行命令。下面顯示的是在該對話(chatops)中手動執行的恢復:
jessbreckenridge
.mysql backup-restore -H db-mysql-0007 -o -r magic_word=daily_rotating_word
Hubot
@jessbreckenridge gh-mysql-backup-restore: db-mysql-0007: Determining backup to restore for cluster 'mycluster'.
@jessbreckenridge gh-mysql-backup-restore: db-mysql-0007: restore_log.id = 4449
@jessbreckenridge gh-mysql-backup-restore: db-mysql-0007: Enabling maintenance mode
@jessbreckenridge gh-mysql-backup-restore: db-mysql-0007: Setting orchestrator downtime
@jessbreckenridge gh-mysql-backup-restore: db-mysql-0007: Disabling Puppet
@jessbreckenridge gh-mysql-backup-restore: db-mysql-0007: Stopping MySQL
@jessbreckenridge gh-mysql-backup-restore: db-mysql-0007: Removing MySQL files
@jessbreckenridge gh-mysql-backup-restore: db-mysql-0007: Running gh-xtrabackup-restore
@jessbreckenridge gh-mysql-backup-restore: db-mysql-0007: Restore file: xtrabackup-mycluster-2017-07-02_0015.xbstream
@jessbreckenridge gh-mysql-backup-restore: db-mysql-0007: Running gh-xtrabackup-prepare
@jessbreckenridge gh-mysql-backup-restore: db-mysql-0007: Update file ownership
@jessbreckenridge gh-mysql-backup-restore: db-mysql-0007: Starting MySQL
@jessbreckenridge gh-mysql-backup-restore: db-mysql-0007: Upgrade MySQL
@jessbreckenridge gh-mysql-backup-restore: db-mysql-0007: Stopping MySQL
@jessbreckenridge gh-mysql-backup-restore: db-mysql-0007: Starting MySQL
@jessbreckenridge gh-mysql-backup-restore: db-mysql-0007: Setting up replication
@jessbreckenridge gh-mysql-backup-restore: db-mysql-0007: Starting replication
@jessbreckenridge gh-mysql-backup-restore: db-mysql-0007: Backup Host: db-mysql-0201
@jessbreckenridge gh-mysql-backup-restore: db-mysql-0007: Replication catch-up
@jessbreckenridge gh-mysql-backup-restore: db-mysql-0007: Replication behind by 4589 seconds, waiting 1800 seconds before next check.
@jessbreckenridge gh-mysql-backup-restore: db-mysql-0007: Restore complete (replication running)
@jessbreckenridge gh-mysql-backup-restore: db-mysql-0007: Enabling puppet
@jessbreckenridge gh-mysql-backup-restore: db-mysql-0007: Disabling maintenance mode
故障轉移
我們使用協調器 來為 主伺服器 和 中間伺服器 執行自動化故障切換。我們期望 協調器 能夠正確檢測主伺服器故障,指定一個副本進行晉陞,在所指定的副本下修復拓撲,完成晉陞。我們預期 VIP(虛擬 IP)、連接池可以相應地進行變化、客戶端進行重連、puppet 在晉陞後的主伺服器上運行基本組件等等。故障轉移是一項複雜的任務,涉及到我們基礎架構的許多方面。
為了建立對我們的故障轉移的信賴,我們建立了一個類生產環境的測試集群,並且我們不斷地崩潰它來觀察故障轉移情況。
這個類生產環境的測試集群是一套複製環境,與我們的生產集群的各個方面都相同:硬體類型、操作系統、MySQL 版本、網路環境、VIP、puppet 配置、haproxy 設置 等。與生產集群唯一不同的是它不發送/接收生產流量。
我們在測試集群上模擬寫入負載,同時避免複製滯後。寫入負載不會太大,但是有一些有意地寫入相同數據集的競爭請求。這在正常情況下並不是很有用,但是事實證明這在故障轉移中是有用的,我們將會稍後簡要描述它。
我們的測試集群有來自三個數據中心的典型的伺服器。我們希望故障轉移能夠從同一個數據中心內晉陞替代副本。我們希望在這樣的限制下儘可能多地恢復副本。我們要求儘可能地實現這兩者。協調器對拓撲結構沒有 先驗假定 ;它必須依據崩潰時的狀態作出反應。
然而,我們有興趣創建各種複雜而多變的故障恢復場景。我們的故障轉移測試腳本為故障轉移提供了基礎:
- 它能夠識別現有的主伺服器
- 它能夠重構拓撲結構,來代表主伺服器下的所有的三個數據中心。不同的數據中心具有不同的網路延遲,並且預期會在不同的時間對主機崩潰做出反應。
- 能夠選擇崩潰方式。可以選擇幹掉主伺服器(
kill -9)或網路隔離(比較好的方式:iptables -j REJECT或無響應的方式:iptables -j DROP)方式。
腳本通過選擇的方法使主機崩潰,並等待協調器可靠地檢測到崩潰然後執行故障轉移。雖然我們期望檢測和晉陞在 30 秒鐘內完成,但腳本會稍微放寬這一期望,並在查找故障轉移結果之前休眠一段指定的時間。然後它將檢查:
- 一個新的(不同的)主伺服器是否到位
- 集群中有足夠的副本
- 主伺服器是可寫的
- 對主伺服器的寫入在副本上可見
- 內部服務發現項已更新(如預期般識別到新的主伺服器;移除舊的主伺服器)
- 其他內部檢查
這些測試可以證實故障轉移是成功的,不僅是 MySQL 級別的,而是在更大的基礎設施範圍內成功的。VIP 被賦予;特定的服務已經啟動;信息到達了應該去的地方。
該腳本進一步繼續恢復那個失敗的伺服器:
- 從備份恢復它,從而隱含地測試了我們的備份/恢復過程
- 驗證伺服器配置是否符合預期(該伺服器不再認為其是主伺服器)
- 將其加入到複製集群,期望找到在主伺服器上寫入的數據
看一下以下可視化的計劃的故障轉移測試:從運行良好的群集,到在某些副本上發現問題,診斷主伺服器(7136)是否死機,選擇一個伺服器(a79d)來晉陞,重構該伺服器下的拓撲,晉陞它(故障切換成功),恢復失敗的(原)主伺服器並將其放回群集。
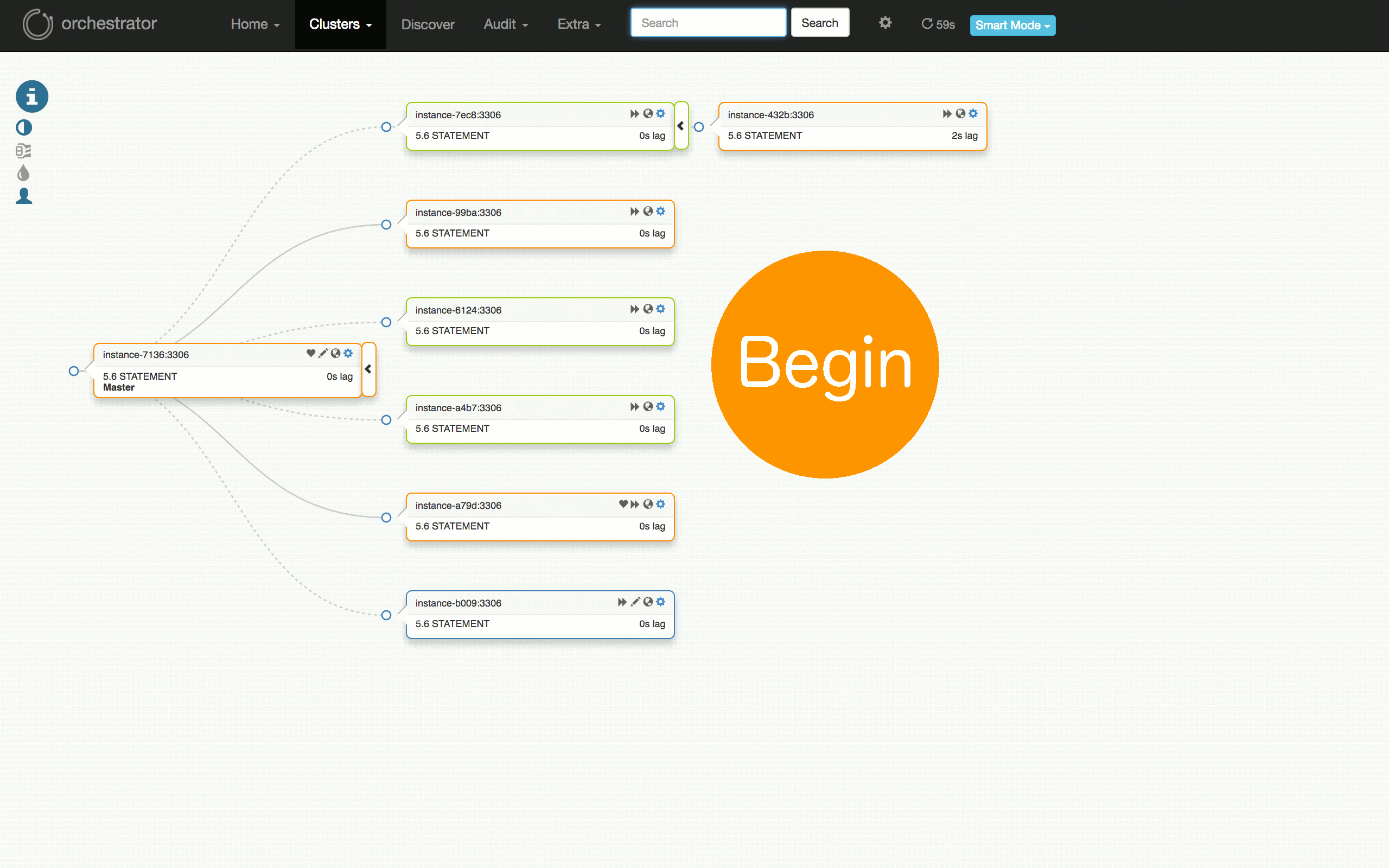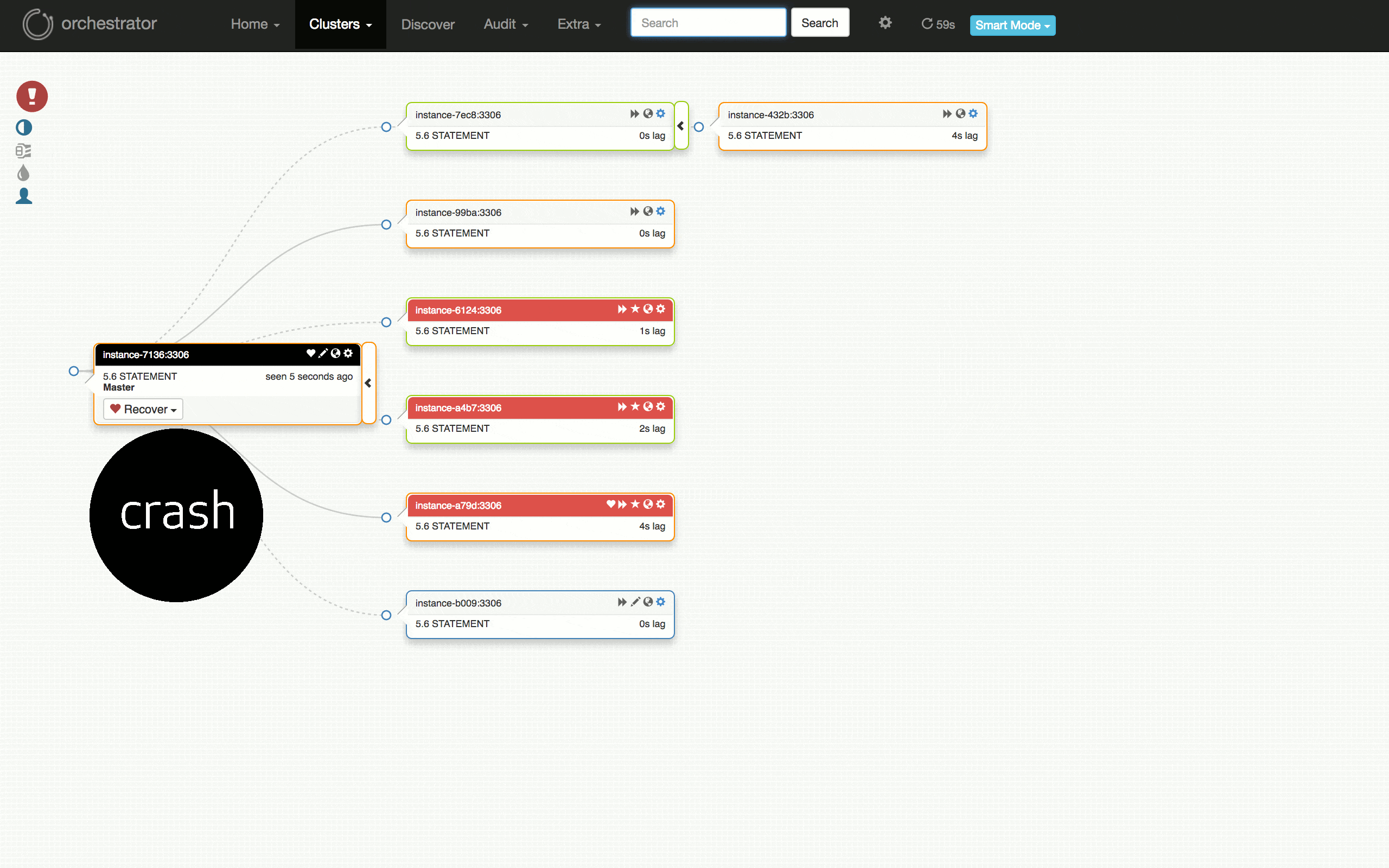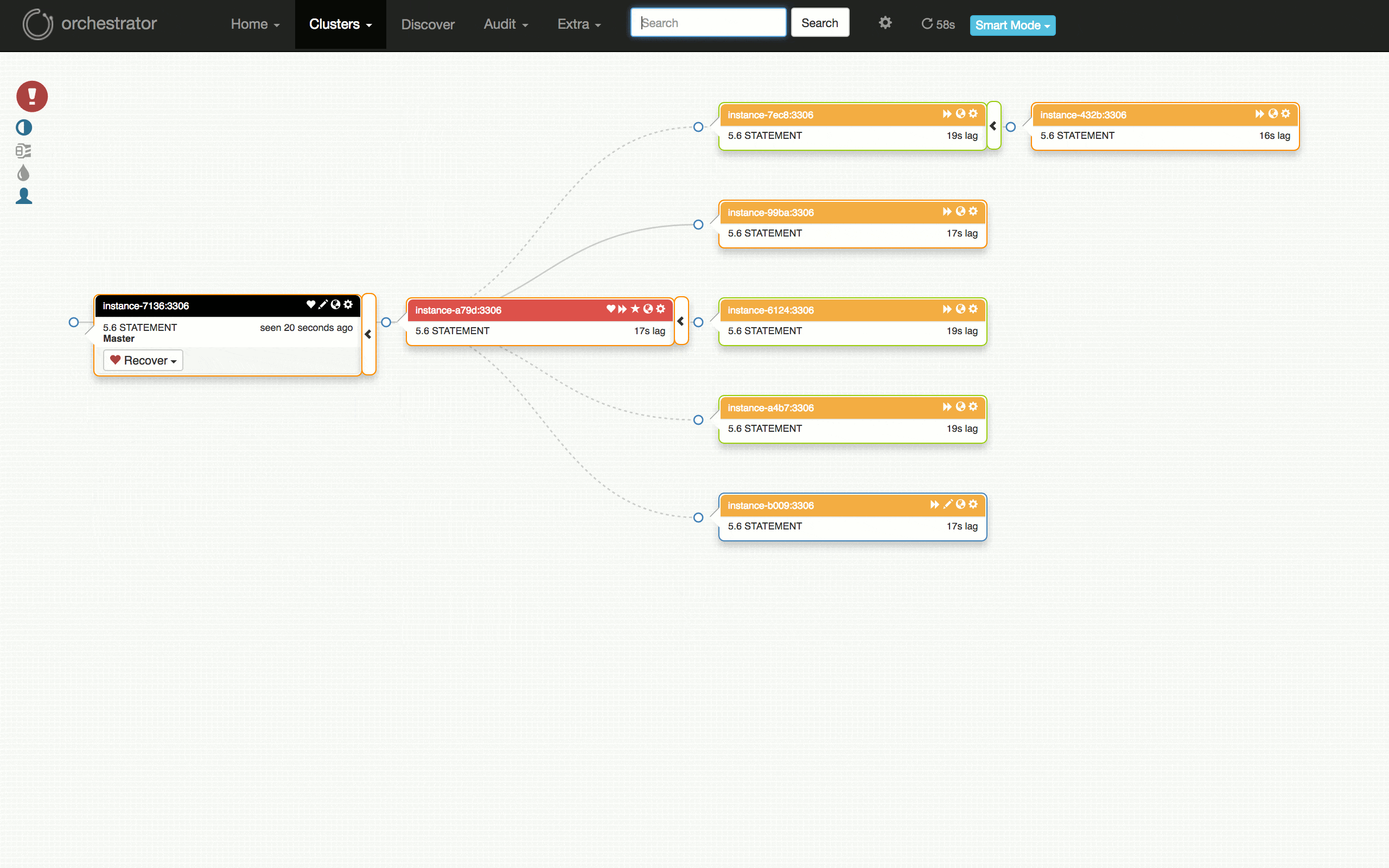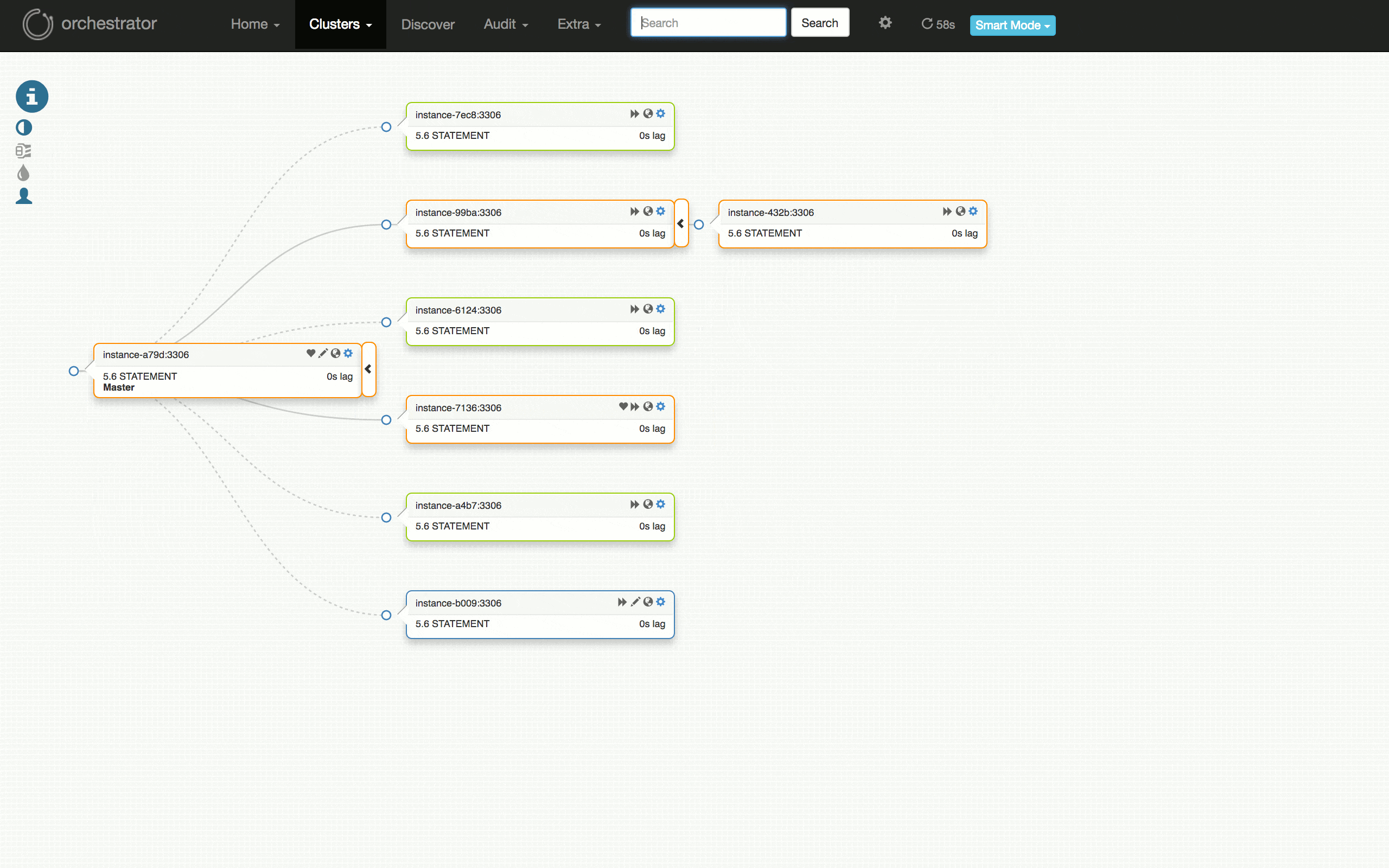
測試失敗怎麼樣?
我們的測試腳本使用了一種「停止世界」的方法。任何故障切換組件中的單個故障都將導致整個測試失敗,因此在有人解決該問題之前,無法進行任何進一步的自動化測試。我們會得到警報,並檢查狀態和日誌進行處理。
腳本將各種情況下失敗,如不可接受的檢測或故障轉移時間;備份/還原出現問題;失去太多伺服器;在故障切換後的意外配置等等。
我們需要確保協調器正確地連接伺服器。這是競爭性寫入負載有用的地方:如果設置不正確,複製很容易中斷。我們會得到 DUPLICATE KEY 或其他錯誤提示出錯。
這是特別重要的,因此我們改進協調器並引入新的行為,以允許我們在安全的環境中測試這些變化。
出現:混亂測試
上面所示的測試程序將捕獲(並已經捕獲)我們基礎設施許多部分的問題。這些夠了嗎?
在生產環境中總是有其他的東西。有些特定測試方法不適用於我們的生產集群。它們不具有相同的流量和流量方式,也不具有完全相同的伺服器集。故障類型可能有所不同。
我們正在為我們的生產集群設計混亂測試。 混亂測試將會在我們的生產中,但是按照預期的時間表和充分控制的方式來逐個破壞我們的部分生產環境。 混亂測試在恢復機制中引入更高層次的信賴,並影響(因此測試)我們的基礎設施和應用程序的更大部分。
這是微妙的工作:當我們承認需要混亂測試時,我們也希望可以避免對我們的服務造成不必要的影響。不同的測試將在風險級別和影響方面有所不同,我們將努力確保我們的服務的可用性。
模式遷移
我們使用 gh-ost來運行實時 模式遷移 。gh-ost 是穩定的,但也處於活躍開發中,重大新功能正在不斷開發和計劃中。
gh-ost 通過將數據複製到 ghost 表來遷移,將由二進位日誌攔截的進一步更改應用到 ghost 表中,就如其正在寫入原始表。然後它將 ghost 表交換代替原始表。遷移完成時,GitHub 繼續使用由 gh-ost 生成和填充的表。
在這個時候,幾乎所有的 GitHub 的 MySQL 數據都被 gh-ost 重新創建,其中大部分重新創建多次。我們必須高度信賴 gh-ost,讓它一遍遍地操弄我們的數據,即使它還處於活躍開發中。下面是我們如何獲得這種信賴的。
gh-ost 提供生產環境測試能力。它支持在副本上運行遷移,其方式與在主伺服器上運行的方式大致相同: gh-ost 將連接到副本,並將其視為主伺服器。它將採用與實際主機遷移相同的方式解析其二進位日誌。但是,它將複製行並將二進位日誌事件應用於副本,並避免對主伺服器進行寫入。
我們在生產環境中給 gh-ost 提供專用的副本。這些副本並不為生產環境提供服務。每個這樣的副本將檢索生產表的當前列表,並以隨機順序對其進行迭代。一個接一個地選擇一個表並在該表上執行複製遷移。遷移實際上並不修改表結構,而是運行一個微不足道的 ENGINE=InnoDB 更改。該測試運行遷移時,如果表正在生產環境中使用,會複製實際的生產數據,並接受二進位日誌之外的真實的生產環境流量。
這些遷移可以被審計。以下是我們如何從對話中(chatops)檢查運行中的測試狀態:
ggunson
.migration test-status
Hubot
# Migrating `prod`.`pull_requests`; Ghost table is `prod`.`_pull_requests_gho`
# Migrating ghost-db-mysql-0007:3306; inspecting ghost-db-mysql-0007:3306; executing on ghost-db-mysql-0007
# Migration started at Mon Jan 30 02:13:39 -0800 2017
# chunk-size: 2500; max-lag-millis: 1500ms; max-load: Threads_running=30; critical-load: Threads_running=1000; nice-ratio: 0.000000
# throttle-additional-flag-file: /tmp/gh-ost.throttle
# panic-flag-file: /tmp/ghost-test-panic.flag
# Serving on unix socket: /tmp/gh-ost.test.sock
Copy: 57992500/86684838 66.9%; Applied: 57708; Backlog: 1/100; Time: 3h28m38s(total), 3h28m36s(copy); streamer: mysql-bin.000576:142993938; State: migrating; ETA: 1h43m12s
當測試遷移完成表數據的複製時,它將停止複製並執行切換,使用 ghost 表替換原始表,然後交換回來。我們對實際替換數據並不感興趣。相反,我們將留下原始的表和 ghost 表,它們應該是相同的。我們通過校驗兩個表的整個表數據來驗證。
測試能以下列方式完成:
- 成功 :一切順利,校驗和相同。我們期待看到這一結果。
- 失敗 :執行問題。這可能偶爾發生,因為遷移進程被殺死、複製問題等,並且通常與 gh-ost 自身無關。
- 校驗失敗 :表數據不一致。對於被測試的分支,這個需要修復。對於正在進行的 master 分支測試,這意味著立即阻止生產遷移。我們不會遇到後者。
測試結果經過審核,發送到機器人聊天室,作為事件發送到我們的度量系統。下圖中的每條垂直線代表成功的遷移測試:
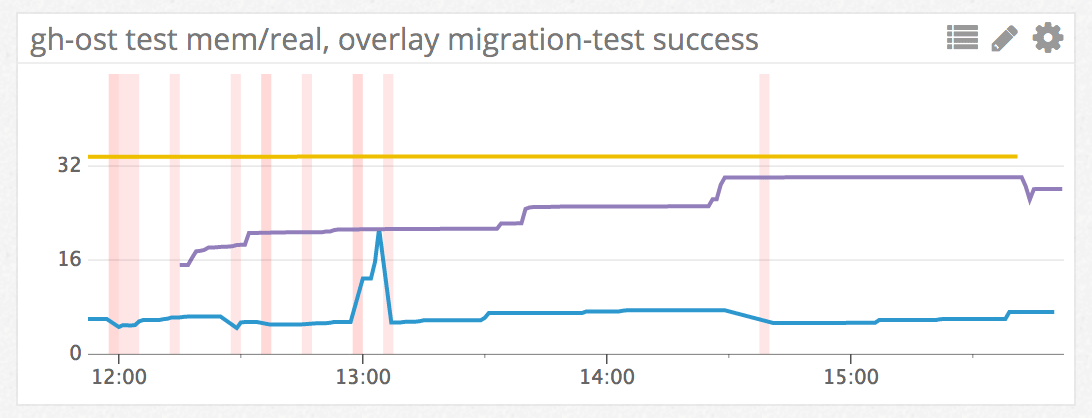
這些測試不斷運行。如果發生故障,我們會收到通知。當然,我們可以隨時訪問機器人聊天室(chatops),了解發生了什麼。
測試新版本
我們不斷改進 gh-ost。我們的開發流程基於 git 分支,然後我們通過拉取請求(PR)來提供合併。
提交的 gh-ost 拉取請求(PR)通過持續集成(CI)進行基本的編譯和單元測試。一旦通過,該 PR 在技術上就有資格合併,但更好的是它有資格通過 Heaven 進行部署。作為我們基礎架構中的敏感組件,在其進入 master 分支前,我們會小心部署分支進行密集測試。
shlomi-noach
.deploy gh-ost/fix-reappearing-throttled-reasons to prod/ghost-db-mysql-0007
Hubot
@shlomi-noach is deploying gh-ost/fix-reappearing-throttled-reasons (baee4f6) to production (ghost-db-mysql-0007).
@shlomi-noach's production deployment of gh-ost/fix-reappearing-throttled-reasons (baee4f6) is done! (2s)
@shlomi-noach, make sure you watch for exceptions in haystack
jonahberquist
.deploy gh-ost/interactive-command-question to prod/ghost-db-mysql-0012
Hubot
@jonahberquist is deploying gh-ost/interactive-command-question (be1ab17) to production (ghost-db-mysql-0012).
@jonahberquist's production deployment of gh-ost/interactive-command-question (be1ab17) is done! (2s)
@jonahberquist, make sure you watch for exceptions in haystack
shlomi-noach
.wcid gh-ost
Hubot
shlomi-noach testing fix-reappearing-throttled-reasons 41 seconds ago: ghost-db-mysql-0007
jonahberquist testing interactive-command-question 7 seconds ago: ghost-db-mysql-0012
Nobody is in the queue.
一些 PR 很小,不影響數據本身。對狀態消息,互動式命令等的更改對 gh-ost 應用程序的影響較小。而其他的 PR 對遷移邏輯和操作會造成重大變化,我們將嚴格測試這些,通過我們的生產表車隊運行這些,直到其滿足了這些改變不會造成數據損壞威脅的程度。
總結
在整個測試過程中,我們建立對我們的系統的信賴。通過自動化這些測試,在生產環境中,我們得到了一切都按預期工作的反覆確認。隨著我們繼續發展我們的基礎設施,我們還通過調整測試來覆蓋最新的變化。
產品總會有令你意想不到的未被測試覆蓋的場景。我們對生產環境的測試越多,我們對應用程序的期望越多,基礎設施的能力就越強。
via: https://githubengineering.com/mysql-testing-automation-at-github/
作者:tomkrouper, Shlomi Noach 譯者:MonkeyDEcho 校對:wxy
本文轉載來自 Linux 中國: https://github.com/Linux-CN/archive
對這篇文章感覺如何?
You may also like






More in:Linux中國

捐贈 Let's Encrypt,共建安全的互聯網

Let's Encrypt 正式發布,已經保護 380 萬個域名

關於Linux防火牆iptables的面試問答

Lets Encrypt 已被所有主流瀏覽器所信任









