Gitbase:使用 SQL 探索 Git 倉庫

Git 已經成為了代碼版本控制的事實標準。雖然 Git 已經很流行了,但想用它來對源代碼倉庫的歷史和內容進行深度分析,仍然是一件複雜的事情。
另一方面,SQL 則是一個經過實際檢驗、適合查詢大型代碼庫的的語言,畢竟 Spark 和 BigQuery 等項目都採用了 SQL 作為查詢語言。
因此,在 source{d} 公司,我們順理成章地結合了這兩種技術來創建了 Gitbase:這是一個用 SQL 對 Git 倉庫進行大規模分析的「代碼即數據」解決方案。
Gitbase 是一個完全開源的項目,它站在一系列巨人的肩膀上,是它們使 Gitbase 的發展成為可能。本文旨在指出其中的主要部分。
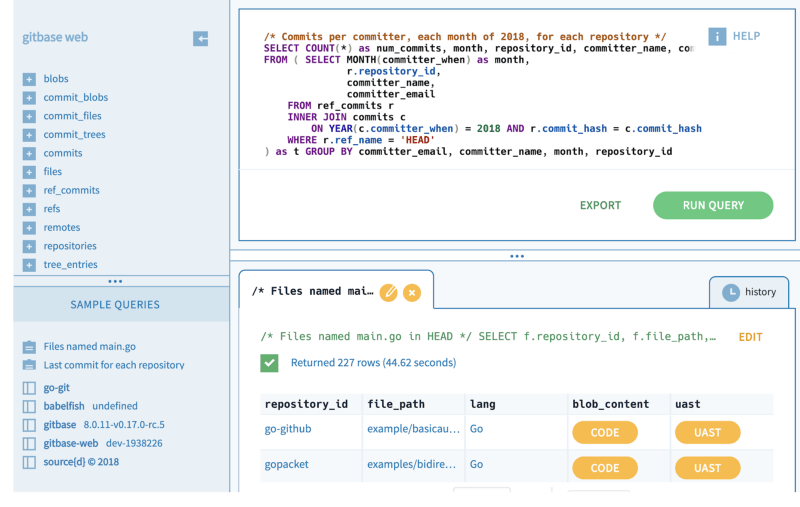
Gitbase 試驗場 提供了一種使用 Gitbase 的可視化方式。
使用 Vitess 解析 SQL
Gitbase 將 SQL 作為用戶介面。這意味著我們需要解析基於 MySQL 協議傳輸的 SQL 請求,並理解它們。幸運的是,我們在 YouTube 的朋友和他們的 Vitess 項目已經實現了這一點。Vitess 是一個資料庫集群系統,用於 MySQL 的水平擴展。
我們直接截取一些重要的代碼片段,並把它做成了一個 開源項目。這個項目允許任何人在幾分鐘內編寫一個 MySQL 伺服器(正如我在 justforfunc 的專題:CSVQL - 用 SQL 處理 CSV 中所展示的那樣)。
用 go-git 讀取 Git 儲存庫
當成功解析了一個請求,我們還需要讀取數據集里的 Git 倉庫,才能夠知道該如何回復它。為此,我們集成了 source{d} 最成功的倉庫 go-git。go-git 是一個高度可擴展的純 Go 語言的 Git 實現。
這使得我們能夠輕鬆地分析以 siva 文件格式存儲在磁碟上的源代碼倉庫(siva 也是一個 source{d} 的開源項目),或是直接使用 git clone 克隆的倉庫。
使用 Enry 檢測編程語言,使用 Babelfish 解析文件
Gitbase 並沒有將其分析能力局限於 Git 歷史記錄上。它還使用(顯然也是)我們的開源項目 Enry 集成了語言檢測功能,並使用 Babelfish 實現了程序解析的功能。Babelfish 是一個用於通用源代碼解析的自託管伺服器,它可以將代碼文件轉化為 通用抽象語法樹 (UAST)。
這兩個功能在 Gitbase 中呈現為用戶函數 LANGUAGE 和 UAST。結合使用兩個函數,許多查詢請求都成為了可能,比如「找到上個月修改次數最多的函數名稱」。
讓它快速運行
Gitbase 經常要分析非常大的數據集,比如公共 Git 檔案,其中有來自 GitHub 的 3TB 源代碼(見 公告)。為了做到這一點,每份 CPU 處理能力都很重要。
這就是為什麼我們又集成了另外兩個項目:Rubex 和 Pilosa。
使用 Rubex 和 Oniguruma 加快正則表達式的速度
Rubex 是 Go 的 regexp 標準庫包的一個準替代品。之所以還不能完成替代,是因為他們沒有在 regexp.Regexp 類型上實現 LiteralPrefix 方法,不過我也是直到現在才聽說這個方法。
Rubex 的高性能得歸功於高度優化的 C 語言庫 Oniguruma,它使用 cgo 來調用這個庫。
使用 Pilosa 索引加快查詢速度
索引基本上是每個關係型資料庫的眾所周知的特性,但 Vitess 卻沒有實現索引,因為它不是真正需要。
還好開源的 Pilosa 再一次拯救了我們,它是一個用 Go 實現的分散式點陣圖索引,使得 Gitbase 可以用於大規模的數據集。Pilosa 是開源的,它極大地加快了對多個海量數據集的查詢。
總結
我想通過這篇博文,親自感謝開源社區,是他們讓我們在如此短的時間內創建了 Gitbase,這是誰也沒想到的。在 source{d} 公司,我們是開源的堅定信仰者,github.com/src-d 下的每一行代碼(包括我們的 OKR 和投資者委員會)都可以證明這一點。
你想嘗試一下 Gitbase 嗎?最快、最簡單的方法就是使用 source{d} 引擎。從 sourced.tech/engine 下載它,只需一個命令就能讓 Gitbase 運行起來。
想了解更多嗎?請查看我在 Go SF meetup 的演講錄音。
這篇文章 最初發表在 Medium 上,經授權後在此重新發布。
via: https://opensource.com/article/18/11/gitbase
作者:Francesc Campoy 選題:lkxed 譯者:lkxed 校對:wxy
本文轉載來自 Linux 中國: https://github.com/Linux-CN/archive
對這篇文章感覺如何?
You may also like






More in:Linux中國

捐贈 Let's Encrypt,共建安全的互聯網

Let's Encrypt 正式發布,已經保護 380 萬個域名

關於Linux防火牆iptables的面試問答

Lets Encrypt 已被所有主流瀏覽器所信任









