Prometheus 入門

Prometheus 是一個開源的監控和警報系統,它直接從目標主機上運行的代理程序中抓取指標,並將收集的樣本集中存儲在其伺服器上。也可以使用像 collectd_exporter 這樣的插件推送指標,儘管這不是 Promethius 的默認行為,但在主機位於防火牆後面或位於安全策略禁止打開埠的某些環境中它可能很有用。
Prometheus 是雲原生計算基金會(CNCF)的一個項目。它使用 聯合模型 進行擴展,該模型使得一個 Prometheus 伺服器能夠抓取另一個 Prometheus 伺服器的數據。這允許創建分層拓撲,其中中央系統或更高級別的 Prometheus 伺服器可以抓取已從下級實例收集的聚合數據。
除 Prometheus 伺服器外,其最常見的組件是警報管理器及其輸出器。
警報規則可以在 Prometheus 中創建,並配置為向警報管理器發送自定義警報。然後,警報管理器處理和管理這些警報,包括通過電子郵件或第三方服務(如 PagerDuty)等不同機制發送通知。
Prometheus 的輸出器可以是庫、進程、設備或任何其他能將 Prometheus 抓取的指標公開出去的東西。 這些指標可在端點 /metrics 中獲得,它允許 Prometheus 無需代理直接抓取它們。本文中的教程使用 node_exporter 來公開目標主機的硬體和操作系統指標。輸出器的輸出是明文的、高度可讀的,這是 Prometheus 的優勢之一。
此外,你可以將 Prometheus 作為後端,配置 Grafana 來提供數據可視化和儀錶板功能。
理解 Prometheus 的配置文件
抓取 /metrics 的間隔秒數控制了時間序列資料庫的粒度。這在配置文件中定義為 scrape_interval 參數,默認情況下設置為 60 秒。
在 scrape_configs 部分中為每個抓取作業設置了目標。每個作業都有自己的名稱和一組標籤,可以幫助你過濾、分類並更輕鬆地識別目標。一項作業可以有很多目標。
安裝 Prometheus
在本教程中,為簡單起見,我們將使用 Docker 安裝 Prometheus 伺服器和 node_exporter。Docker 應該已經在你的系統上正確安裝和配置。對於更深入、自動化的方法,我推薦 Steve Ovens 的文章《如何使用 Ansible 與 Prometheus 建立系統監控》。
在開始之前,在工作目錄中創建 Prometheus 配置文件 prometheus.yml,如下所示:
global:
scrape_interval: 15s
evaluation_interval: 15s
scrape_configs:
- job_name: 'prometheus'
static_configs:
- targets: ['localhost:9090']
- job_name: 'webservers'
static_configs:
- targets: ['<node exporter node IP>:9100']通過運行以下命令用 Docker 啟動 Prometheus:
$ sudo docker run -d -p 9090:9090 -v
/path/to/prometheus.yml:/etc/prometheus/prometheus.yml
prom/prometheus默認情況下,Prometheus 伺服器將使用埠 9090。如果此埠已在使用,你可以通過在上一個命令的後面添加參數 --web.listen-address="<IP of machine>:<port>" 來更改它。
在要監視的計算機中,使用以下命令下載並運行 node_exporter 容器:
$ sudo docker run -d -v "/proc:/host/proc" -v "/sys:/host/sys" -v
"/:/rootfs" --net="host" prom/node-exporter --path.procfs
/host/proc --path.sysfs /host/sys --collector.filesystem.ignored-
mount-points "^/(sys|proc|dev|host|etc)($|/)"出於本文練習的目的,你可以在同一台機器上安裝 node_exporter 和 Prometheus。請注意,生產環境中在 Docker 下運行 node_exporter 是不明智的 —— 這僅用於測試目的。
要驗證 node_exporter 是否正在運行,請打開瀏覽器並導航到 http://<IP of Node exporter host>:9100/metrics,這將顯示收集到的所有指標;也即是 Prometheus 將要抓取的相同指標。
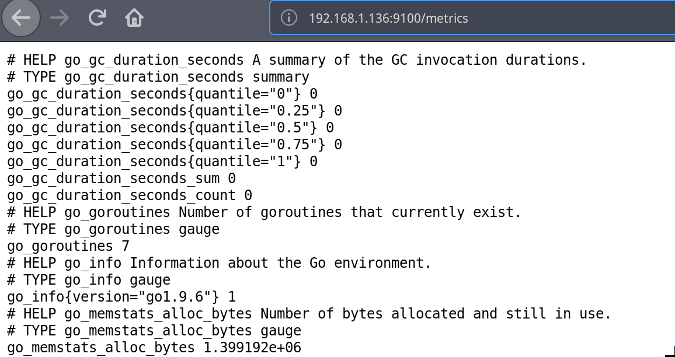
要確認 Prometheus 伺服器安裝成功,打開瀏覽器並導航至:http://localhost:9090。
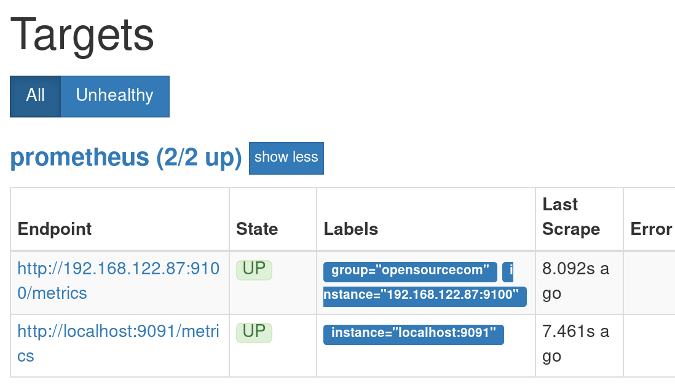
你應該看到了 Prometheus 的界面。單擊「Status」,然後單擊「Targets」。在 「Status」 下,你應該看到你的機器被列為 「UP」。
使用 Prometheus 查詢
現在是時候熟悉一下 PromQL(Prometheus 的查詢語法)及其圖形化 Web 界面了。轉到 Prometheus 伺服器上的 http://localhost:9090/graph。你將看到一個查詢編輯器和兩個選項卡:「Graph」 和 「Console」。
Prometheus 將所有數據存儲為時間序列,使用指標名稱標識每個數據。例如,指標 node_filesystem_avail_bytes 顯示可用的文件系統空間。指標的名稱可以在表達式框中使用,以選擇具有此名稱的所有時間序列並生成即時向量。如果需要,可以使用選擇器和標籤(一組鍵值對)過濾這些時間序列,例如:
node_filesystem_avail_bytes{fstype="ext4"}過濾時,你可以匹配「完全相等」(=)、「不等於」(!=),「正則匹配」(=~)和「正則排除匹配」(!~)。以下示例說明了這一點:
要過濾 node_filesystem_avail_bytes 以顯示 ext4 和 XFS 文件系統:
node_filesystem_avail_bytes{fstype=~"ext4|xfs"}要排除匹配:
node_filesystem_avail_bytes{fstype!="xfs"}你還可以使用方括弧得到從當前時間往回的一系列樣本。你可以使用 s 表示秒,m 表示分鐘,h 表示小時,d 表示天,w 表示周,而 y 表示年。使用時間範圍時,返回的向量將是範圍向量。
例如,以下命令生成從五分鐘前到現在的樣本:
node_memory_MemAvailable_bytes[5m]Prometheus 還包括了高級查詢的功能,例如:
100 * (1 - avg by(instance)(irate(node_cpu_seconds_total{job='webservers',mode='idle'}[5m])))請注意標籤如何用於過濾作業和模式。指標 node_cpu_seconds_total 返回一個計數器,irate()函數根據範圍間隔的最後兩個數據點計算每秒的變化率(意味著該範圍可以小於五分鐘)。要計算 CPU 總體使用率,可以使用 node_cpu_seconds_total 指標的空閑(idle)模式。處理器的空閑比例與繁忙比例相反,因此從 1 中減去 irate 值。要使其為百分比,請將其乘以 100。
了解更多
Prometheus 是一個功能強大、可擴展、輕量級、易於使用和部署的監視工具,對於每個系統管理員和開發人員來說都是必不可少的。出於這些原因和其他原因,許多公司正在將 Prometheus 作為其基礎設施的一部分。
要了解有關 Prometheus 及其功能的更多信息,我建議使用以下資源:
via: https://opensource.com/article/18/12/introduction-prometheus
作者:Michael Zamot 選題:lujun9972 譯者:wxy 校對:wxy
本文轉載來自 Linux 中國: https://github.com/Linux-CN/archive
對這篇文章感覺如何?
You may also like






More in:Linux中國

捐贈 Let's Encrypt,共建安全的互聯網

Let's Encrypt 正式發布,已經保護 380 萬個域名

關於Linux防火牆iptables的面試問答

Lets Encrypt 已被所有主流瀏覽器所信任









