探索傳統 JavaScript 基準測試
可以很公平地說,JavaScript 是當下軟體工程中最重要的技術。對於那些深入接觸過編程語言、編譯器和虛擬機的人來說,這仍然有點令人驚訝,因為在語言設計者們看來,JavaScript 不是十分優雅;在編譯器工程師們看來,它沒有多少可優化的地方;甚至還沒有一個偉大的標準庫。這取決於你和誰吐槽,JavaScript 的缺點你花上數周都枚舉不完,而你總會找到一些你從所未知的奇怪的東西。儘管這看起來明顯困難重重,不過 JavaScript 還是成為了當今 web 的核心,並且還(通過 Node.js)成為伺服器端和雲端的主導技術,甚至還開闢了進軍物聯網領域的道路。
那麼問題來了,為什麼 JavaScript 如此受歡迎?或者說如此成功?我知道沒有一個很好的答案。如今我們有許多使用 JavaScript 的好理由,或許最重要的是圍繞其構建的龐大的生態系統,以及現今大量可用的資源。但所有這一切實際上是發展到一定程度的後果。為什麼 JavaScript 變得流行起來了?嗯,你或許會說,這是 web 多年來的通用語了。但是在很長一段時間裡,人們極其討厭 JavaScript。回顧過去,似乎第一波 JavaScript 浪潮爆發在上個年代的後半段。那個時候 JavaScript 引擎加速了各種不同的任務的執行,很自然的,這可能讓很多人對 JavaScript 刮目相看。
回到過去那些日子,這些加速使用了現在所謂的傳統 JavaScript 基準進行測試——從蘋果的 SunSpider 基準(JavaScript 微基準之母)到 Mozilla 的 Kraken 基準 和谷歌的 V8 基準。後來,V8 基準被 Octane 基準 取代,而蘋果發布了新的 JetStream 基準。這些傳統的 JavaScript 基準測試驅動了無數人的努力,使 JavaScript 的性能達到了本世紀初沒人能預料到的水平。據報道其性能加速達到了 1000 倍,一夜之間在網站使用 <script> 標籤不再是與魔鬼共舞,做客戶端不再僅僅是可能的了,甚至是被鼓勵的。
(來源: Advanced JS performance with V8 and Web Assembly, Chrome Developer Summit 2016, @s3ththompson。)
現在是 2016 年,所有(相關的)JavaScript 引擎的性能都達到了一個令人難以置信的水平,web 應用像原生應用一樣快(或者能夠像原生應用一樣快)。引擎配有複雜的優化編譯器,通過收集之前的關於類型/形狀的反饋來推測某些操作(例如屬性訪問、二進位操作、比較、調用等),生成高度優化的機器代碼的短序列。大多數優化是由 SunSpider 或 Kraken 等微基準以及 Octane 和 JetStream 等靜態測試套件驅動的。由於有像 asm.js 和 Emscripten 這樣的 JavaScript 技術,我們甚至可以將大型 C++ 應用程序編譯成 JavaScript,並在你的瀏覽器上運行,而無需下載或安裝任何東西。例如,現在你可以在 web 上玩 AngryBots,無需沙盒,而過去的 web 遊戲需要安裝一堆諸如 Adobe Flash 或 Chrome PNaCl 的特殊插件。
這些成就絕大多數都要歸功於這些微基準和靜態性能測試套件的出現,以及與這些傳統的 JavaScript 基準間的競爭的結果。你可以對 SunSpider 表示不滿,但很顯然,沒有 SunSpider,JavaScript 的性能可能達不到今天的高度。好吧,讚美到此為止。現在看看另一方面,所有的靜態性能測試——無論是 微基準 還是大型應用的 宏基準 ,都註定要隨著時間的推移變成噩夢!為什麼?因為在開始擺弄它之前,基準只能教你這麼多。一旦達到某個闊值以上(或以下),那麼有益於特定基準的優化的一般適用性將呈指數級下降。例如,我們將 Octane 作為現實世界中 web 應用性能的代表,並且在相當長的一段時間裡,它可能做得很不錯,但是現在,Octane 與現實場景中的時間分布是截然不同的,因此即使眼下再優化 Octane 乃至超越自身,可能在現實世界中還是得不到任何顯著的改進(無論是通用 web 還是 Node.js 的工作負載)。
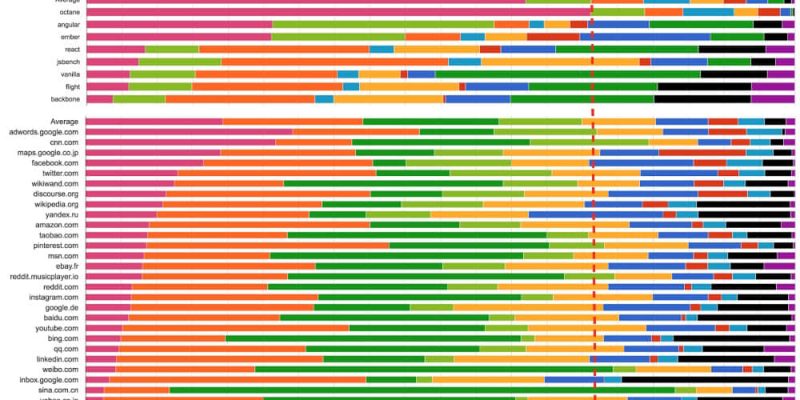
(來源:Real-World JavaScript Performance,BlinkOn 6 conference,@tverwaes)
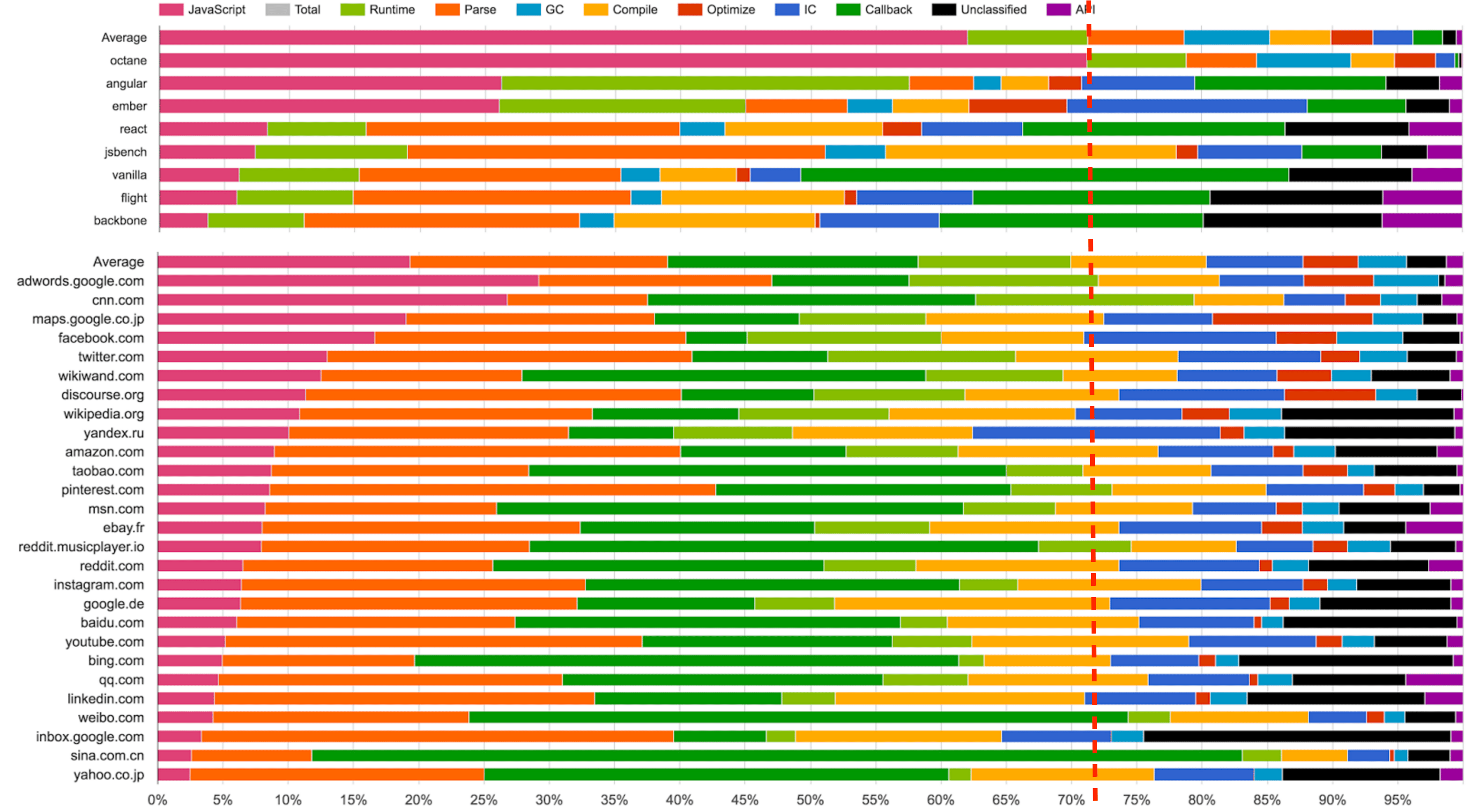
由於傳統 JavaScript 基準(包括最新版的 JetStream 和 Octane)可能已經背離其有用性變得越來越遠,我們開始在 2016 年初尋找新的方法來測量現實場景的性能,為 V8 和 Chrome 添加了大量新的性能追蹤鉤子。我們還特意添加一些機制來查看我們在瀏覽 web 時的時間究竟開銷在哪裡,例如,是腳本執行、垃圾回收、編譯,還是什麼地方?而這些調查的結果非常有趣和令人驚訝。從上面的幻燈片可以看出,運行 Octane 花費了 70% 以上的時間去執行 JavaScript 和垃圾回收,而瀏覽 web 的時候,通常執行 JavaScript 花費的時間不到 30%,垃圾回收佔用的時間永遠不會超過 5%。在 Octane 中並沒有體現出它花費了大量時間來解析和編譯。因此,將更多的時間用在優化 JavaScript 執行上將提高你的 Octane 跑分,但不會對載入 youtube.com 有任何積極的影響。事實上,花費更多的時間來優化 JavaScript 執行甚至可能有損你現實場景的性能,因為編譯器需要更多的時間,或者你需要跟蹤更多的反饋,最終在編譯、垃圾回收和 運行時桶 等方面開銷了更多的時間。
還有另外一組基準測試用於測量瀏覽器整體性能(包括 JavaScript 和 DOM 性能),最新推出的是 Speedometer 基準。該基準試圖通過運行一個用不同的主流 web 框架實現的簡單的 TodoMVC 應用(現在看來有點過時了,不過新版本正在研發中)以捕獲更真實的現實場景的性能。上述幻燈片中的各種測試 (Angular、Ember、React、Vanilla、Flight 和 Backbone)挨著放在 Octane 之後,你可以看到,此時此刻這些測試似乎更好地代表了現實世界的性能指標。但是請注意,這些數據收集在本文撰寫將近 6 個月以前,而且我們優化了更多的現實場景模式(例如我們正在重構垃圾回收系統以顯著地降低開銷,並且 解析器也正在重新設計)。還要注意的是,雖然這看起來像是只和瀏覽器相關,但我們有非常強有力的證據表明傳統的峰值性能基準也不能很好的代表現實場景中 Node.js 應用性能。
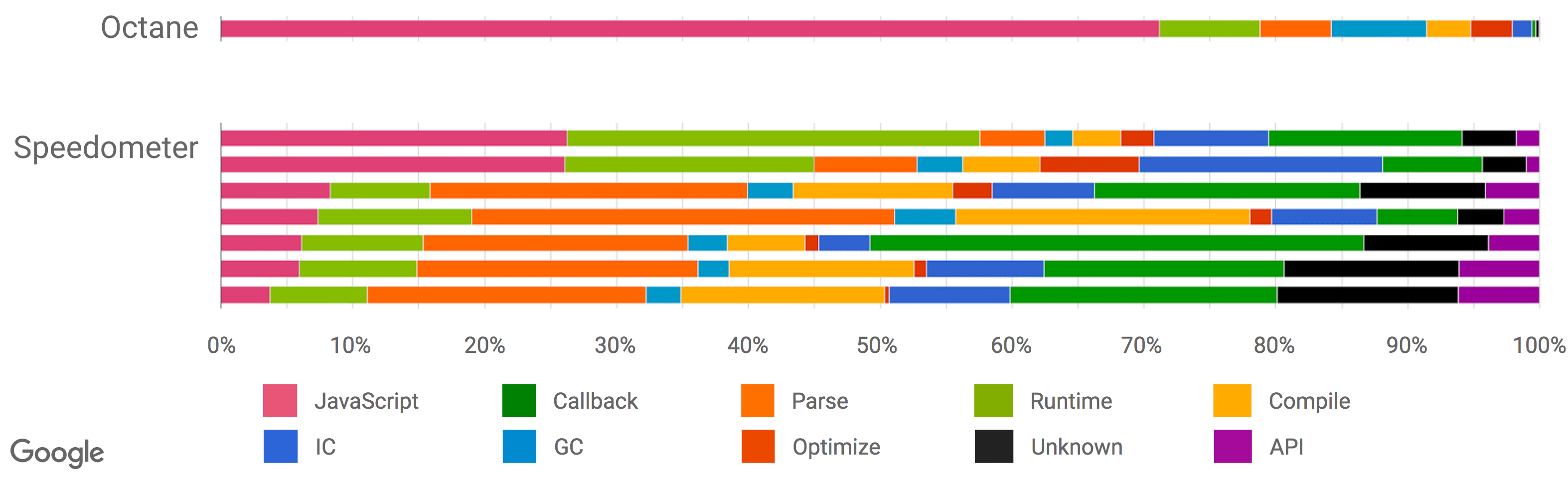
(來源: Real-World JavaScript Performance, BlinkOn 6 conference, @tverwaes.)
所有這一切可能已經路人皆知了,因此我將用本文剩下的部分強調一些具體案例,它們對關於我為什麼認為這不僅有用,而且必須停止關注某一閾值的靜態峰值性能基準測試對於 JavaScript 社區的健康是很關鍵的。讓我通過一些例子說明 JavaScript 引擎怎樣來玩弄基準的。
臭名昭著的 SunSpider 案例
一篇關於傳統 JavaScript 基準測試的博客如果沒有指出 SunSpider 那個明顯的問題是不完整的。讓我們從性能測試的最佳實踐開始,它在現實場景中不是很適用:bitops-bitwise-and.js 性能測試。
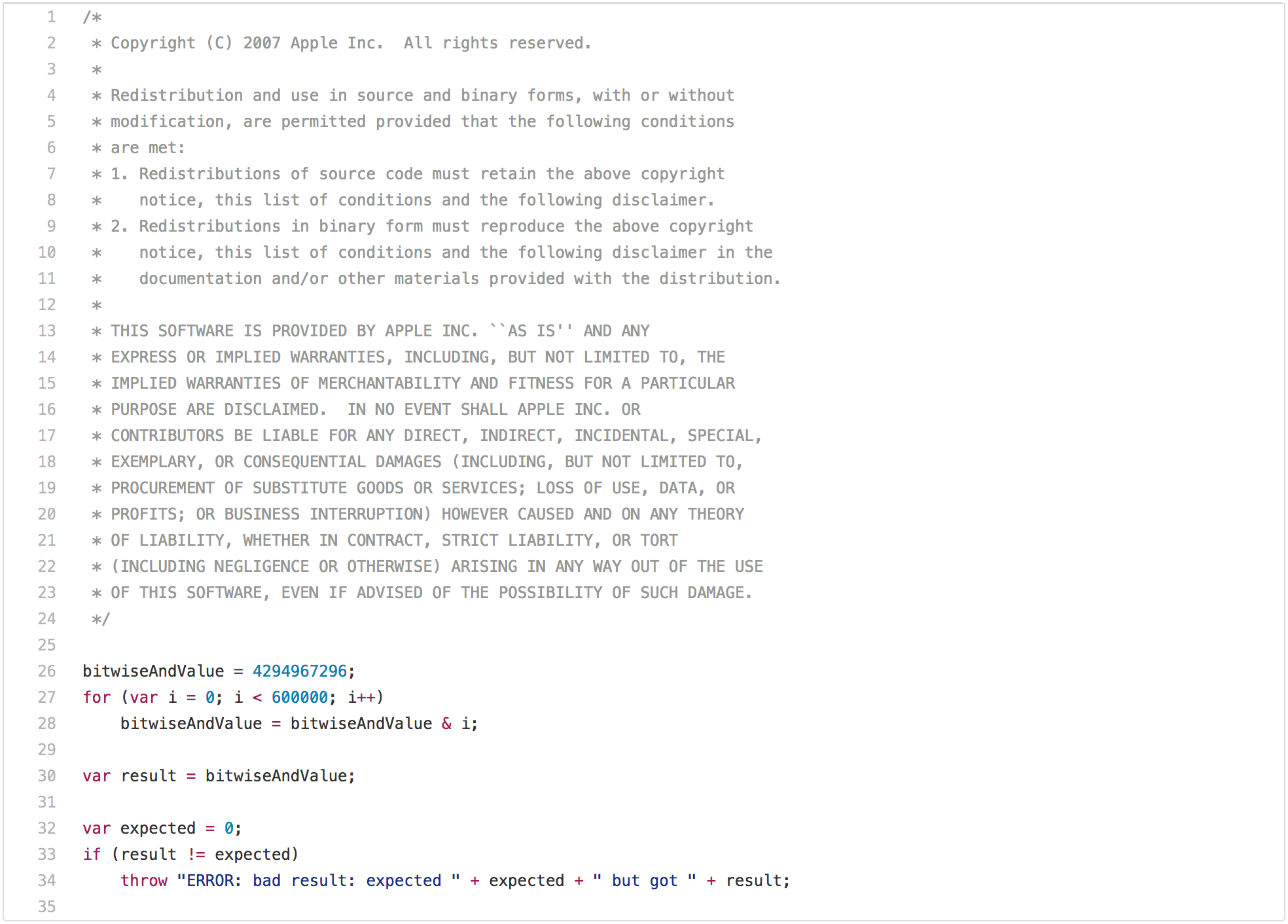
有一些演算法需要進行快速的 AND 位運算,特別是從 C/C++ 轉譯成 JavaScript 的地方,所以快速執行該操作確實有點意義。然而,現實場景中的網頁可能不關心引擎在循環中執行 AND 位運算是否比另一個引擎快兩倍。但是再盯著這段代碼幾秒鐘後,你可能會注意到在第一次循環迭代之後 bitwiseAndValue 將變成 0,並且在接下來的 599999 次迭代中將保持為 0。所以一旦你讓此獲得了好的性能,比如在差不多的硬體上所有測試均低於 5ms,在經過嘗試之後你會意識到,只有循環的第一次是必要的,而剩餘的迭代只是在浪費時間(例如 loop peeling 後面的死代碼),那你現在就可以開始玩弄這個基準測試了。這需要 JavaScript 中的一些機制來執行這種轉換,即你需要檢查 bitwiseAndValue 是全局對象的常規屬性還是在執行腳本之前不存在,全局對象或者它的原型上必須沒有攔截器。但如果你真的想要贏得這個基準測試,並且你願意全力以赴,那麼你可以在不到 1ms 的時間內完成這個測試。然而,這種優化將局限於這種特殊情況,並且測試的輕微修改可能不再觸發它。
好吧,那麼 bitops-bitwise-and.js 測試徹底肯定是微基準最失敗的案例。讓我們繼續轉移到 SunSpider 中更逼真的場景——string-tagcloud.js 測試,它基本上是運行一個較早版本的 json.js polyfill。該測試可以說看起來比位運算測試更合理,但是花點時間查看基準的配置之後立刻會發現:大量的時間浪費在一條 eval 表達式(高達 20% 的總執行時間被用於解析和編譯,再加上實際執行編譯後代碼的 10% 的時間)。
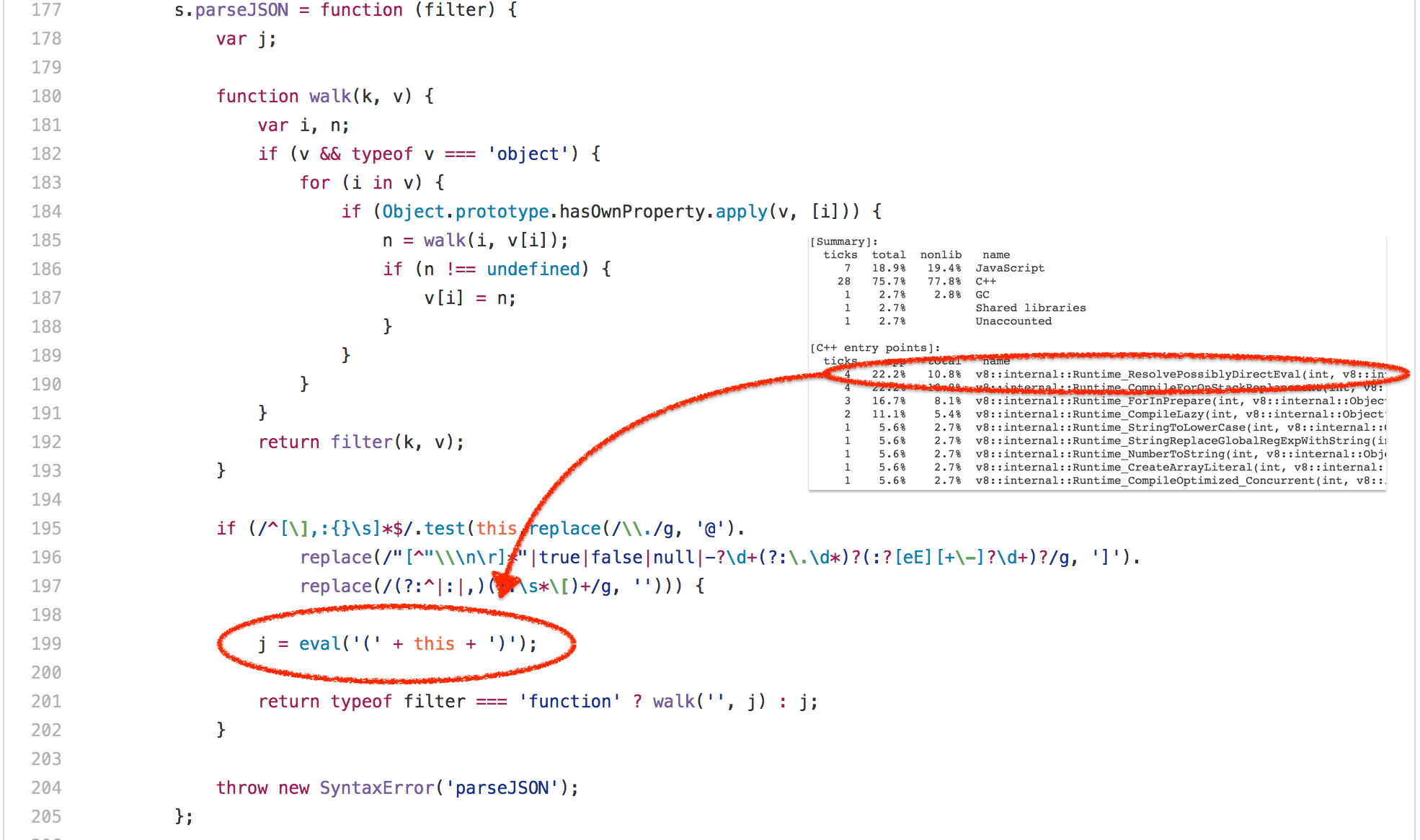
仔細看看,這個 eval 只執行了一次,並傳遞一個 JSON 格式的字元串,它包含一個由 2501 個含有 tag 和 popularity 屬性的對象組成的數組:
([
{
"tag": "titillation",
"popularity": 4294967296
},
{
"tag": "foamless",
"popularity": 1257718401
},
{
"tag": "snarler",
"popularity": 613166183
},
{
"tag": "multangularness",
"popularity": 368304452任何
},
{
"tag": "Fesapo unventurous",
"popularity": 248026512
},
{
"tag": "esthesioblast",
"popularity": 179556755
},
{
"tag": "echeneidoid",
"popularity": 136641578
},
{
"tag": "embryoctony",
"popularity": 107852576
},
...
])
顯然,解析這些對象字面量,為其生成本地代碼,然後執行該代碼的成本很高。將輸入的字元串解析為 JSON 並生成適當的對象圖的開銷將更加低廉。所以,加快這個基準測試的一個小把戲就是模擬 eval,並嘗試總是將數據首先作為 JSON 解析,如果以 JSON 方式讀取失敗,才回退進行真實的解析、編譯、執行(儘管需要一些額外的黑魔法來跳過括弧)。早在 2007 年,這甚至不算是一個壞點子,因為沒有 JSON.parse,不過在 2017 年這只是 JavaScript 引擎的技術債,可能會讓 eval 的合法使用遙遙無期。
--- string-tagcloud.js.ORIG 2016-12-14 09:00:52.869887104 +0100
+++ string-tagcloud.js 2016-12-14 09:01:01.033944051 +0100
@@ -198,7 +198,7 @@
replace(/"[^"\nr]*"|true|false|null|-?d+(?:.d*)?(:?[eE][+-]?d+)?/g, ']').
replace(/(?:^|:|,)(?:s*[)+/g, ''))) {
- j = eval('(' + this + ')');
+ j = JSON.parse(this);
return typeof filter === 'function' ? walk('', j) : j;
}
事實上,將基準測試更新到現代 JavaScript 會立刻會性能暴增,正如今天的 V8 LKGR 從 36ms 降到了 26ms,性能足足提升了 30%!
$ node string-tagcloud.js.ORIG
Time (string-tagcloud): 36 ms.
$ node string-tagcloud.js
Time (string-tagcloud): 26 ms.
$ node -v
v8.0.0-pre
$
這是靜態基準和性能測試套件常見的一個問題。今天,沒有人會正兒八經地用 eval 解析 JSON 數據(不僅是因為性能問題,還出於嚴重的安全性考慮),而是堅持為最近五年寫的代碼使用 JSON.parse。事實上,使用 eval 解析 JSON 可能會被視作產品級代碼的的一個漏洞!所以引擎作者致力於新代碼的性能所作的努力並沒有反映在這個古老的基準中,相反地,而是使得 eval 不必要地更智能複雜化,從而贏得 string-tagcloud.js 測試。
好吧,讓我們看看另一個例子:3d-cube.js。這個基準測試做了很多矩陣運算,即便是最聰明的編譯器對此也無可奈何,只能說執行而已。基本上,該基準測試花了大量的時間執行 Loop 函數及其調用的函數。
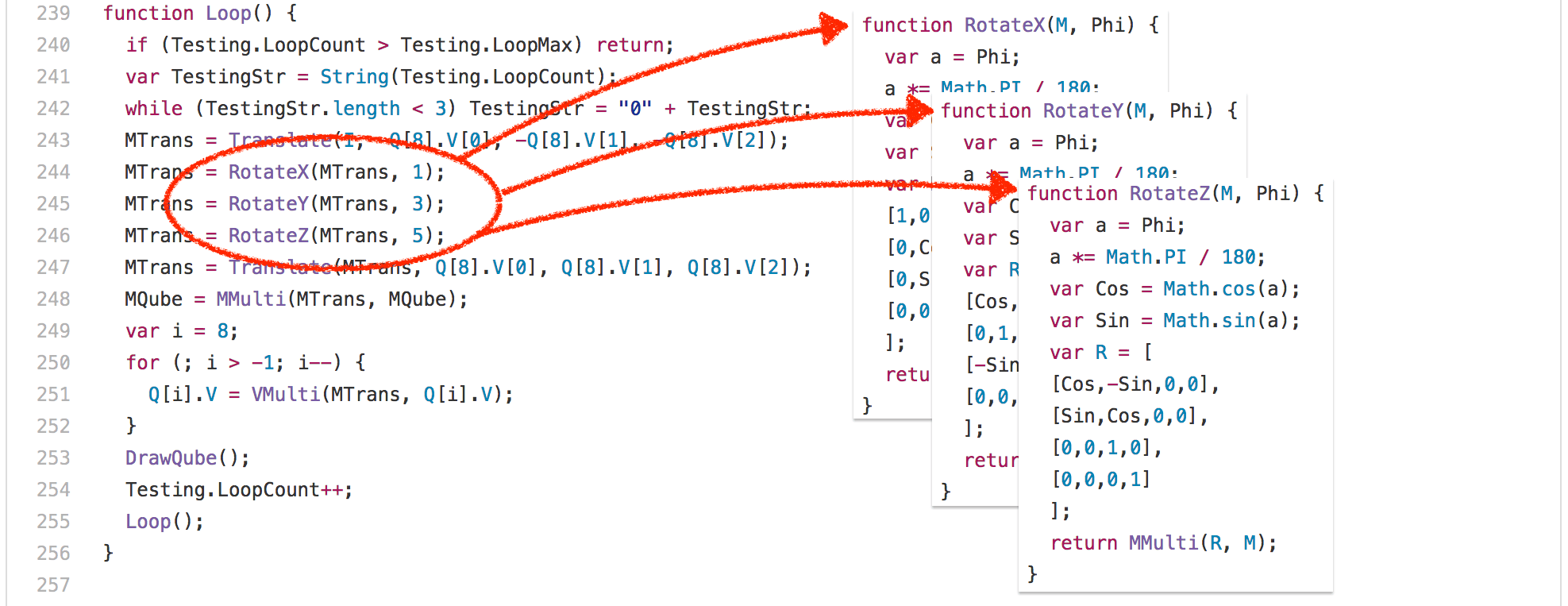
一個有趣的發現是:RotateX、RotateY 和 RotateZ 函數總是調用相同的常量參數 Phi。
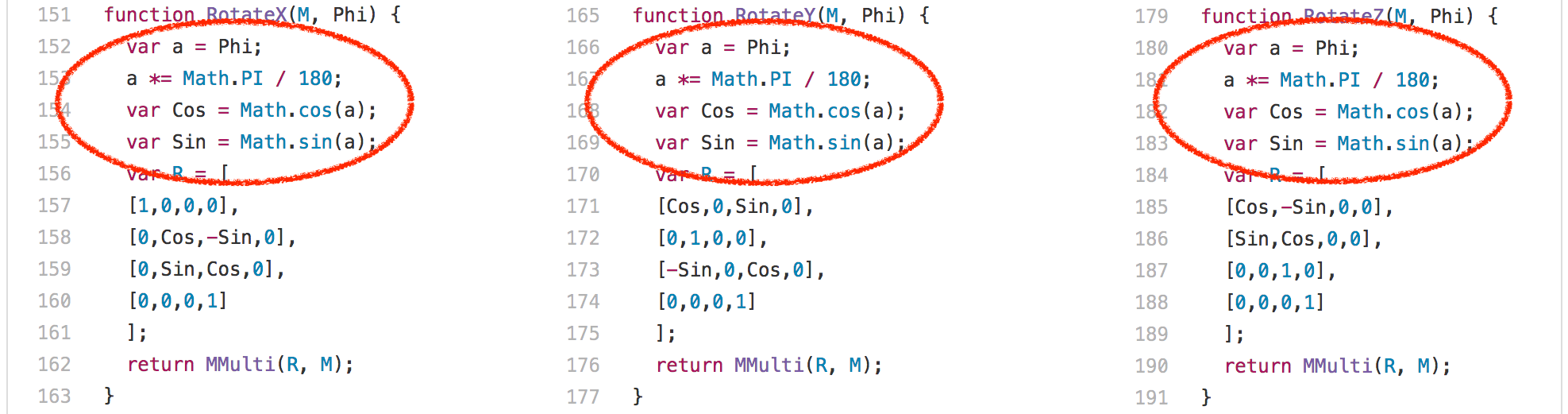
這意味著我們基本上總是為 Math.sin 和 Math.cos 計算相同的值,每次執行都要計算 204 次。只有 3 個不同的輸入值:
- 0.017453292519943295
- 0.05235987755982989
- 0.08726646259971647
顯然,你可以在這裡做的一件事情就是通過緩存以前的計算值來避免重複計算相同的正弦值和餘弦值。事實上,這是 V8 以前的做法,而其它引擎例如 SpiderMonkey 目前仍然在這樣做。我們從 V8 中刪除了所謂的 超載緩存 ,因為緩存的開銷在實際的工作負載中是不可忽視的,你不可能總是在一行代碼中計算相同的值,這在其它地方倒不稀奇。當我們在 2013 和 2014 年移除這個特定的基準優化時,我們對 SunSpider 基準產生了強烈的衝擊,但我們完全相信,為基準而優化並沒有任何意義,並同時以這種方式批判了現實場景中的使用案例。
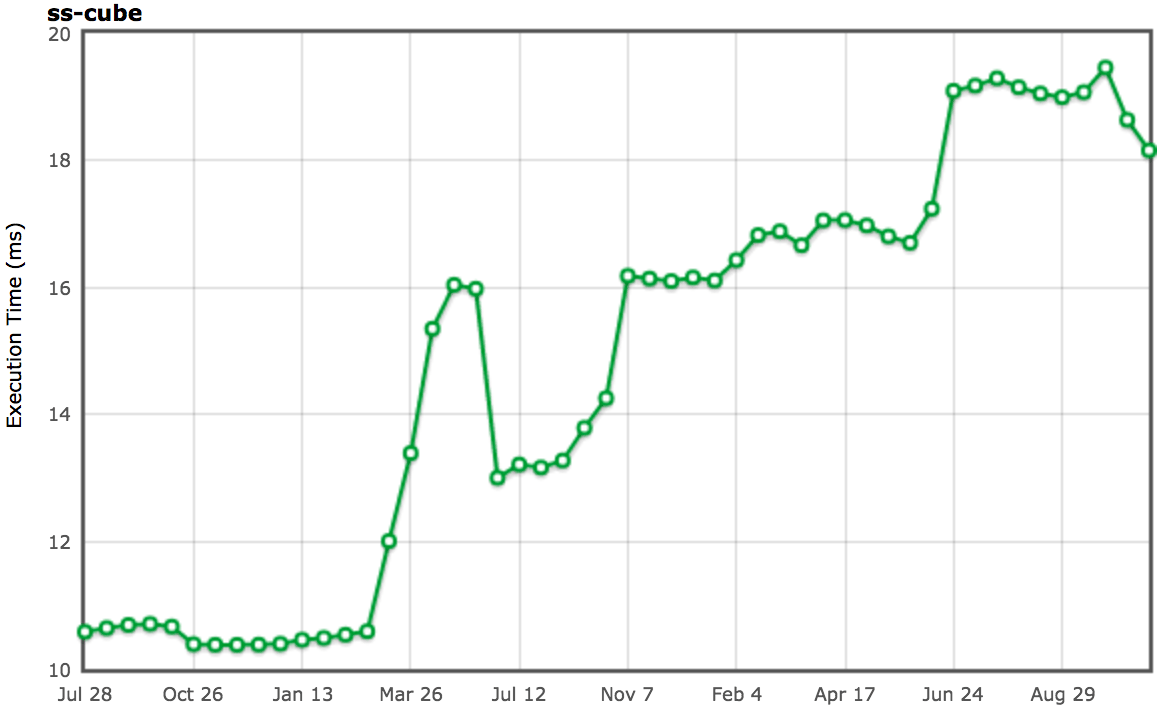
(來源:arewefastyet.com)
顯然,處理恆定正弦/餘弦輸入的更好的方法是一個內聯的啟發式演算法,它試圖平衡內聯因素與其它不同的因素,例如在調用位置優先選擇內聯,其中 常量疊算 可以是有益的,例如在 RotateX、RotateY 和 RotateZ 調用位置的案例中。但是出於各種原因,這對於 Crankshaft 編譯器並不可行。使用 Ignition 和 TurboFan 倒是一個明智的選擇,我們已經在開發更好的內聯啟發式演算法。
垃圾回收(GC)是有害的
除了這些非常具體的測試問題,SunSpider 基準測試還有一個根本性的問題:總體執行時間。目前 V8 在適當的英特爾硬體上運行整個基準測試大概只需要 200ms(使用默認配置)。 次垃圾回收 在 1ms 到 25ms 之間(取決於新空間中的存活對象和舊空間的碎片),而 主垃圾回收 暫停的話可以輕鬆減掉 30ms(甚至不考慮增量標記的開銷),這超過了 SunSpider 套件總體執行時間的 10%!因此,任何不想因垃圾回收循環而造成減速 10-20% 的引擎,必須用某種方式確保它在運行 SunSpider 時不會觸發垃圾回收。
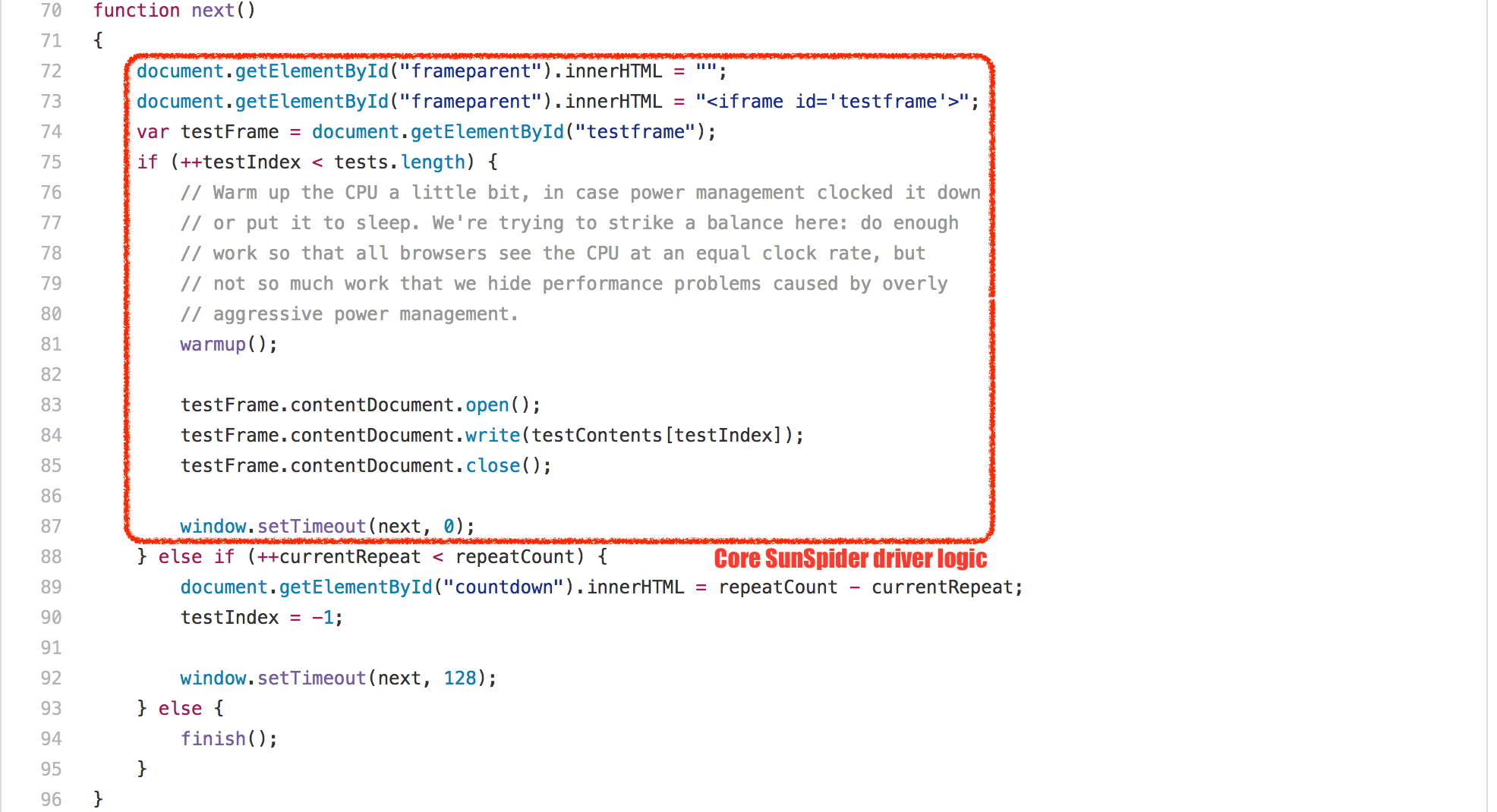
就實現而言,有不同的方案,不過就我所知,沒有一個在現實場景中產生了任何積極的影響。V8 使用了一個相當簡單的技巧:由於每個 SunSpider 套件都運行在一個新的 <iframe> 中,這對應於 V8 中一個新的本地上下文,我們只需檢測快速的 <iframe> 創建和處理(所有的 SunSpider 測試每個花費的時間小於 50ms),在這種情況下,在處理和創建之間執行垃圾回收,以確保我們在實際運行測試的時候不會觸發垃圾回收。這個技巧運行的很好,在 99.9% 的案例中沒有與實際用途衝突;除了時不時的你可能會受到打擊,不管出於什麼原因,如果你做的事情讓你看起來像是 V8 的 SunSpider 測試驅動程序,你就可能被強制的垃圾回收打擊到,這有可能對你的應用導致負面影響。所以謹記一點:不要讓你的應用看起來像 SunSpider!
我可以繼續展示更多 SunSpider 示例,但我不認為這非常有用。到目前為止,應該清楚的是,為刷新 SunSpider 評分而做的進一步優化在現實場景中沒有帶來任何好處。事實上,世界可能會因為沒有 SunSpider 而更美好,因為引擎可以放棄只是用於 SunSpider 的奇淫技巧,或者甚至可以傷害到現實中的用例。不幸的是,SunSpider 仍然被(科技)媒體大量地用來比較他們眼中的瀏覽器性能,或者甚至用來比較手機!所以手機製造商和安卓製造商對於讓 SunSpider(以及其它現在毫無意義的基準 FWIW) 上的 Chrome 看起來比較體面自然有一定的興趣。手機製造商通過銷售手機來賺錢,所以獲得良好的評價對於電話部門甚至整間公司的成功至關重要。其中一些部門甚至在其手機中配置在 SunSpider 中得分較高的舊版 V8,將他們的用戶置於各種未修復的安全漏洞之下(在新版中早已被修復),而讓用戶被最新版本的 V8 帶來的任何現實場景的性能優勢拒之門外!
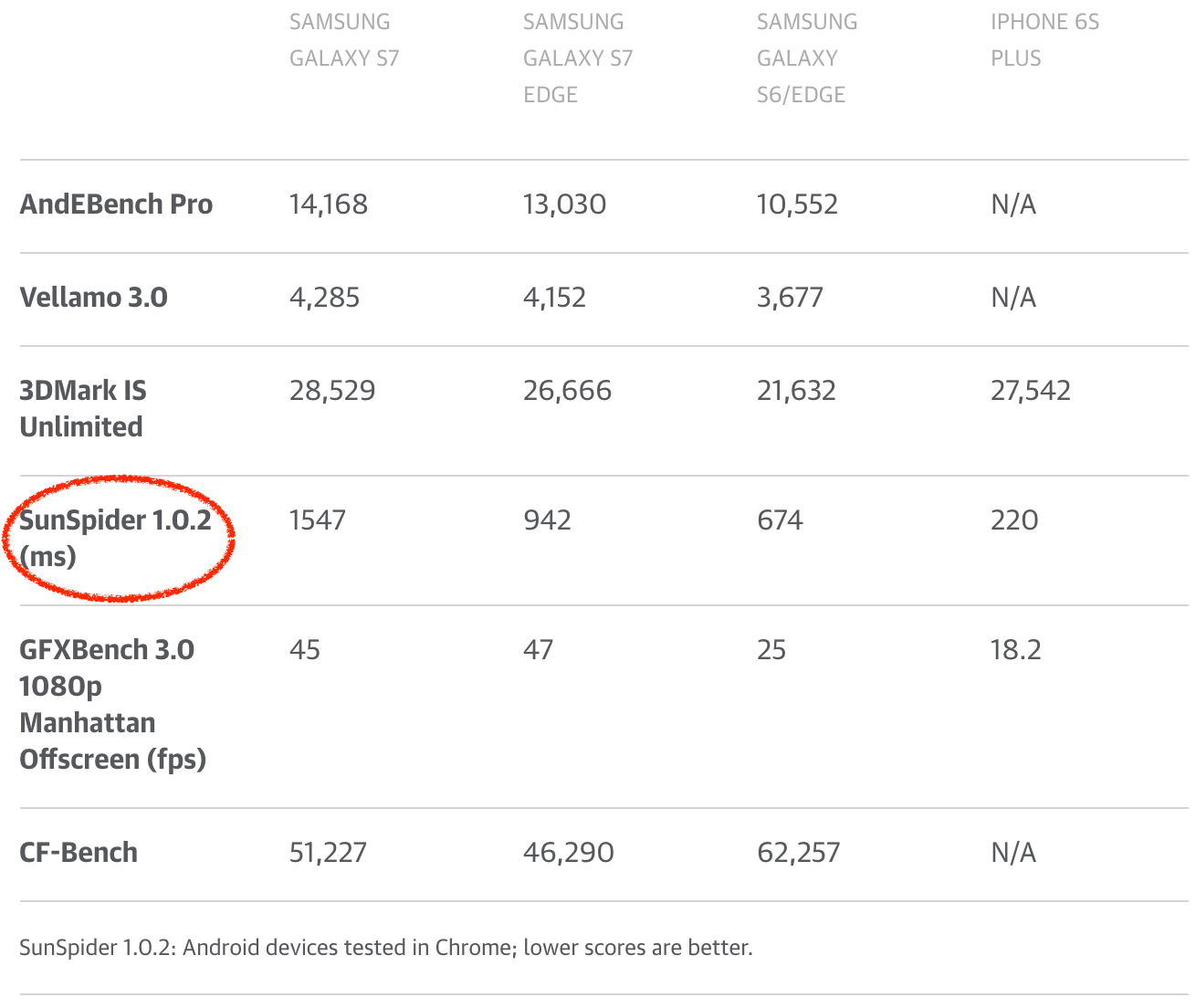
(來源:www.engadget.com)
作為 JavaScript 社區的一員,如果我們真的想認真對待 JavaScript 領域的現實場景的性能,我們需要讓各大技術媒體停止使用傳統的 JavaScript 基準來比較瀏覽器或手機。能夠在每個瀏覽器中運行一個基準測試,並比較它的得分自然是好的,但是請使用一個與當今世界相關的基準,例如真實的 web 頁面;如果你覺得需要通過瀏覽器基準來比較兩部手機,請至少考慮使用 Speedometer。
輕鬆一刻

我一直很喜歡這個 Myles Borins 談話,所以我不得不無恥地向他偷師。現在我們從 SunSpider 的譴責中回過頭來,讓我們繼續檢查其它經典基準。
不是那麼顯眼的 Kraken 案例
Kraken 基準是 Mozilla 於 2010 年 9 月 發布的,據說它包含了現實場景應用的片段/內核,並且與 SunSpider 相比少了一個微基準。我不想在 Kraken 上花太多口舌,因為我認為它不像 SunSpider 和 Octane 一樣對 JavaScript 性能有著深遠的影響,所以我將強調一個特別的案例——audio-oscillator.js 測試。
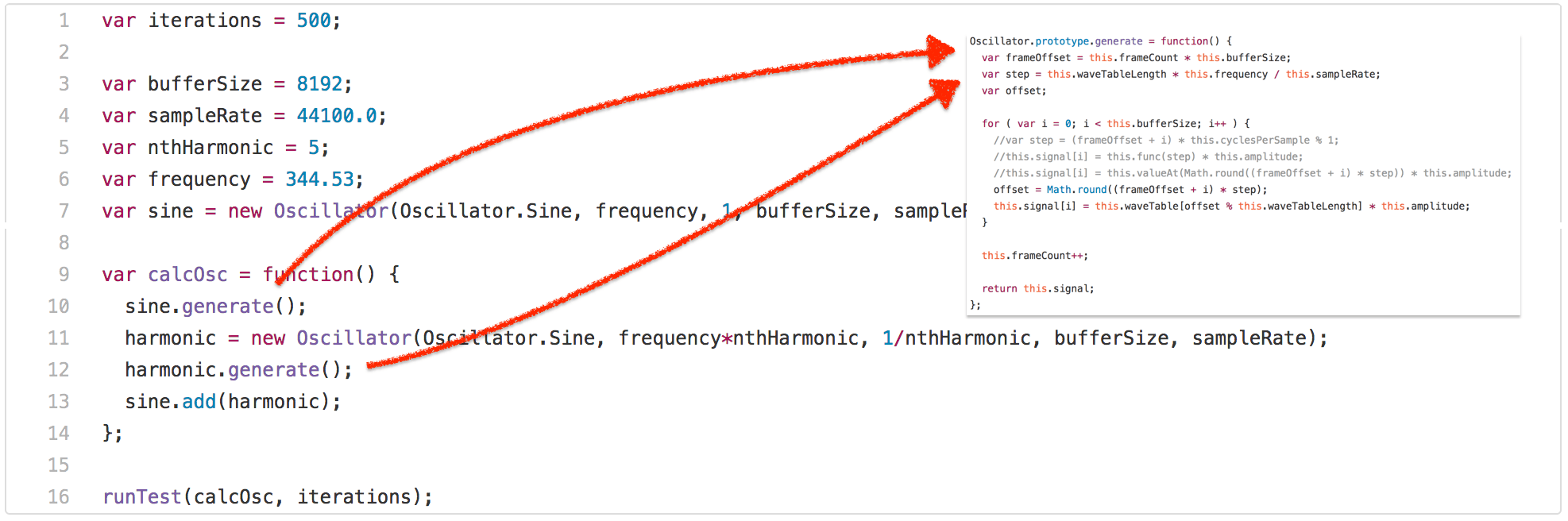
正如你所見,測試調用了 calcOsc 函數 500 次。calcOsc 首先在全局的 sine Oscillator 上調用 generate,然後創建一個新的 Oscillator,調用它的 generate 方法並將其添加到全局的 sine Oscillator 里。沒有詳細說明測試為什麼是這樣做的,讓我們看看 Oscillator 原型上的 generate 方法。
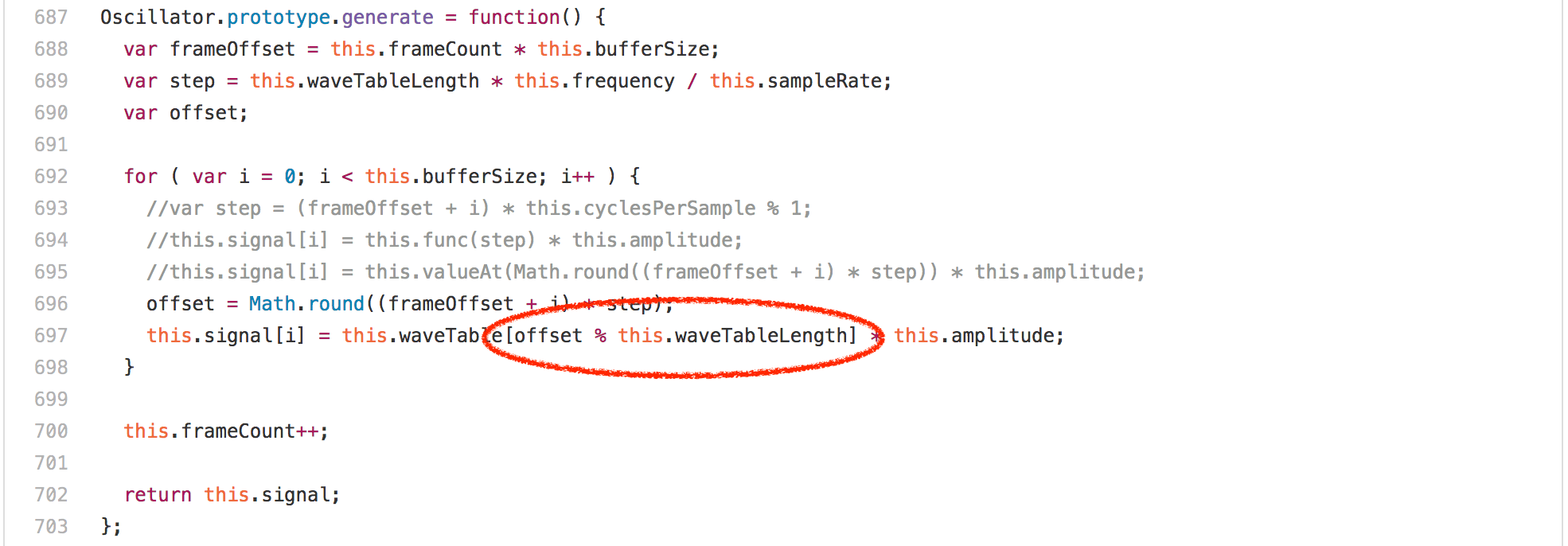
讓我們看看代碼,你也許會覺得這裡主要是循環中的數組訪問或者乘法或者 Math.round 調用,但令人驚訝的是 offset % this.waveTableLength 表達式完全支配了 Oscillator.prototype.generate 的運行。在任何的英特爾機器上的分析器中運行此基準測試顯示,超過 20% 的時間佔用都屬於我們為模數生成的 idiv 指令。然而一個有趣的發現是,Oscillator 實例的 waveTableLength 欄位總是包含相同的值——2048,因為它在 Oscillator 構造器中只分配一次。
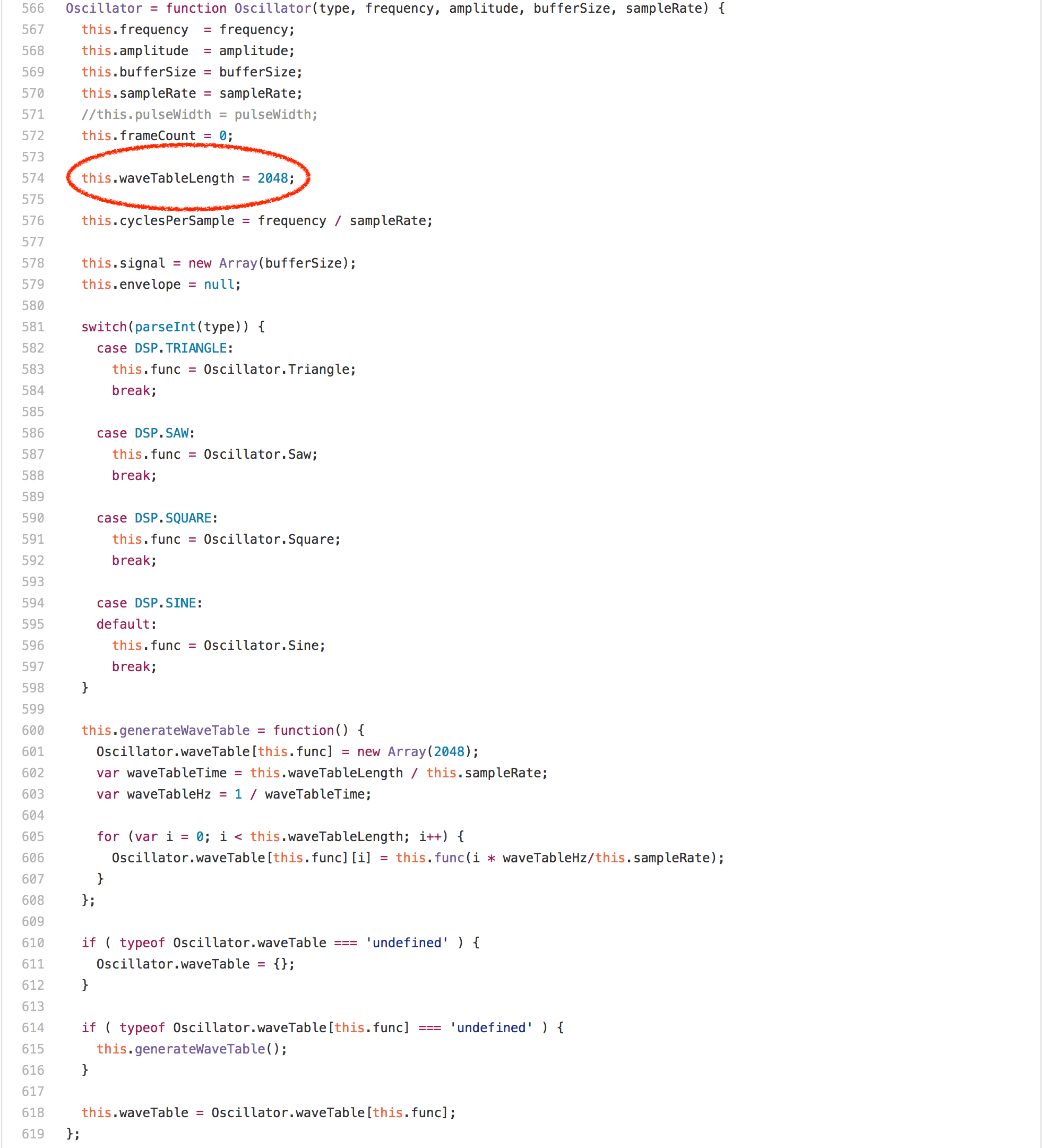
如果我們知道整數模數運算的右邊是 2 的冪,我們顯然可以生成更好的代碼,完全避免了英特爾上的 idiv 指令。所以我們需要獲取一種信息使 this.waveTableLength 從 Oscillator 構造器到 Oscillator.prototype.generate 中的模運算都是 2048。一個顯而易見的方法是嘗試依賴於將所有內容內嵌到 calcOsc 函數,並讓 load/store 消除為我們進行的常量傳播,但這對於在 calcOsc 函數之外分配的 sine oscillator 無效。
因此,我們所做的就是添加支持跟蹤某些常數值作為模運算符的右側反饋。這在 V8 中是有意義的,因為我們為諸如 +、* 和 % 的二進位操作跟蹤類型反饋,這意味著操作者跟蹤輸入的類型和產生的輸出類型(參見最近的圓桌討論中關於動態語言的快速運算的幻燈片)。當然,用 fullcodegen 和 Crankshaft 掛接起來也是相當容易的,MOD 的 BinaryOpIC 也可以跟蹤右邊已知的 2 的冥。
$ ~/Projects/v8/out/Release/d8 --trace-ic audio-oscillator.js
[...SNIP...]
[BinaryOpIC(MOD:None*None->None) => (MOD:Smi*2048->Smi) @ ~Oscillator.generate+598 at audio-oscillator.js:697]
[...SNIP...]
$
事實上,以默認配置運行的 V8 (帶有 Crankshaft 和 fullcodegen)表明 BinaryOpIC 正在為模數的右側拾取適當的恆定反饋,並正確跟蹤左側始終是一個小整數(以 V8 的話叫做 Smi),我們也總是產生一個小整數結果。 使用 --print-opt-code -code-comments 查看生成的代碼,很快就顯示出,Crankshaft 利用反饋在 Oscillator.prototype.generate 中為整數模數生成一個有效的代碼序列:
[...SNIP...]
;;; <@80,#84> load-named-field
0x133a0bdacc4a 330 8b4343 movl rax,[rbx+0x43]
;;; <@83,#86> compare-numeric-and-branch
0x133a0bdacc4d 333 3d00080000 cmp rax,0x800
0x133a0bdacc52 338 0f85ff000000 jnz 599 (0x133a0bdacd57)
[...SNIP...]
;;; <@90,#94> mod-by-power-of-2-i
0x133a0bdacc5b 347 4585db testl r11,r11
0x133a0bdacc5e 350 790f jns 367 (0x133a0bdacc6f)
0x133a0bdacc60 352 41f7db negl r11
0x133a0bdacc63 355 4181e3ff070000 andl r11,0x7ff
0x133a0bdacc6a 362 41f7db negl r11
0x133a0bdacc6d 365 eb07 jmp 374 (0x133a0bdacc76)
0x133a0bdacc6f 367 4181e3ff070000 andl r11,0x7ff
[...SNIP...]
;;; <@127,#88> deoptimize
0x133a0bdacd57 599 e81273cdff call 0x133a0ba8406e
[...SNIP...]
所以你看到我們載入 this.waveTableLength(rbx 持有 this 的引用)的值,檢查它仍然是 2048(十六進位的 0x800),如果是這樣,就只用適當的掩碼 0x7ff(r11 包含循環感應變數 i 的值)執行一個位操作 AND ,而不是使用 idiv 指令(注意保留左側的符號)。
過度特定的問題
所以這個技巧酷斃了,但正如許多基準關注的技巧都有一個主要的缺點:太過於特定了!一旦右側發生變化,所有優化過的代碼就失去了優化(假設右手始終是不再處理的 2 的冥),任何進一步的優化嘗試都必須再次使用 idiv,因為 BinaryOpIC 很可能以 Smi * Smi -> Smi 的形式報告反饋。例如,假設我們實例化另一個 Oscillator,在其上設置不同的 waveTableLength,並為 Oscillator 調用 generate,那麼即使我們實際上感興趣的 Oscillator 不受影響,我們也會損失 20% 的性能(例如,引擎在這裡實行非局部懲罰)。
--- audio-oscillator.js.ORIG 2016-12-15 22:01:43.897033156 +0100
+++ audio-oscillator.js 2016-12-15 22:02:26.397326067 +0100
@@ -1931,6 +1931,10 @@
var frequency = 344.53;
var sine = new Oscillator(Oscillator.Sine, frequency, 1, bufferSize, sampleRate);
+var unused = new Oscillator(Oscillator.Sine, frequency, 1, bufferSize, sampleRate);
+unused.waveTableLength = 1024;
+unused.generate();
+
var calcOsc = function() {
sine.generate();
將原始的 audio-oscillator.js 執行時間與包含額外未使用的 Oscillator 實例與修改的 waveTableLength 的版本進行比較,顯示的是預期的結果:
$ ~/Projects/v8/out/Release/d8 audio-oscillator.js.ORIG
Time (audio-oscillator-once): 64 ms.
$ ~/Projects/v8/out/Release/d8 audio-oscillator.js
Time (audio-oscillator-once): 81 ms.
$
這是一個非常可怕的性能懸崖的例子:假設開發人員編寫代碼庫,並使用某些樣本輸入值進行仔細的調整和優化,性能是體面的。現在,用戶讀過了性能說明開始使用該庫,但不知何故從性能懸崖下降,因為她/他正在以一種稍微不同的方式使用庫,即特定的 BinaryOpIC 的某種污染方式的類型反饋,並且遭受 20% 的減速(與該庫作者的測量相比),該庫的作者和用戶都無法解釋,這似乎是隨機的。
現在這種情況在 JavaScript 領域並不少見,不幸的是,這些懸崖中有幾個是不可避免的,因為它們是由於 JavaScript 的性能是基於樂觀的假設和猜測。我們已經花了 大量 時間和精力來試圖找到避免這些性能懸崖的方法,而仍提供了(幾乎)相同的性能。事實證明,儘可能避免 idiv 是很有意義的,即使你不一定知道右邊總是一個 2 的冪(通過動態反饋),所以為什麼 TurboFan 的做法有異於 Crankshaft 的做法,因為它總是在運行時檢查輸入是否是 2 的冪,所以一般情況下,對於有符整數模數,優化右手側的(未知的) 2 的冥看起來像這樣(偽代碼):
if 0 < rhs then
msk = rhs - 1
if rhs & msk != 0 then
lhs % rhs
else
if lhs < 0 then
-(-lhs & msk)
else
lhs & msk
else
if rhs < -1 then
lhs % rhs
else
zero
這產生更加一致和可預測的性能(使用 TurboFan):
$ ~/Projects/v8/out/Release/d8 --turbo audio-oscillator.js.ORIG
Time (audio-oscillator-once): 69 ms.
$ ~/Projects/v8/out/Release/d8 --turbo audio-oscillator.js
Time (audio-oscillator-once): 69 ms.
$
基準和過度特定化的問題在於基準可以給你提示可以看看哪裡以及該怎麼做,但它不告訴你應該做到什麼程度,不能保護合理優化。例如,所有 JavaScript 引擎都使用基準來防止性能回退,但是運行 Kraken 不能保護我們在 TurboFan 中使用的常規方法,即我們可以將 TurboFan 中的模優化降級到過度特定的版本的 Crankshaft,而基準不會告訴我們性能回退的事實,因為從基準的角度來看這很好!現在你可以擴展基準,也許以上面我們相同的方式,並試圖用基準覆蓋一切,這是引擎實現者在一定程度上做的事情,但這種方法不能任意縮放。即使基準測試方便,易於用來溝通和競爭,以常識所見你還是需要留下空間,否則過度特定化將支配一切,你會有一個真正的、非常好的可接受的性能,以及巨大的性能懸崖線。
Kraken 測試還有許多其它的問題,不過現在讓我們繼續討論過去五年中最有影響力的 JavaScript 基準測試—— Octane 測試。
深入接觸 Octane
Octane 基準是 V8 基準的繼承者,最初由谷歌於 2012 年中期發布,目前的版本 Octane 2.0 於 2013 年年底發布。這個版本包含 15 個獨立測試,其中對於 Splay 和 Mandreel,我們用來測試吞吐量和延遲。這些測試範圍從 微軟 TypeScript 編譯器 編譯自身到 zlib 測試測量原生的 asm.js 性能,再到 RegExp 引擎的性能測試、光線追蹤器、2D 物理引擎等。有關各個基準測試項的詳細概述,請參閱說明書。所有這些測試項目都經過仔細的篩選,以反映 JavaScript 性能的方方面面,我們認為這在 2012 年非常重要,或許預計在不久的將來會變得更加重要。
在很大程度上 Octane 在實現其將 JavaScript 性能提高到更高水平的目標方面無比的成功,它在 2012 年和 2013 年引導了良性的競爭,Octane 創造了巨大的業績和成就。但是現在將近 2017 年了,世界看起來與 2012 年真的迥然不同了。除了通常和經常被引用的批評,Octane 中的大多數項目基本上已經過時(例如,老版本的 TypeScript,zlib 通過老版本的 Emscripten 編譯而成,Mandreel 甚至不再可用等等),某種更重要的方式影響了 Octane 的用途:
我們看到大型 web 框架贏得了 web 種族之爭,尤其是像 Ember 和 AngularJS 這樣的重型框架,它們使用了 JavaScript 執行模式,不過根本沒有被 Octane 所反映,並且經常受到(我們)Octane 具體優化的損害。我們還看到 JavaScript 在伺服器和工具前端獲勝,這意味著有大規模的 JavaScript 應用現在通常運行上數星期,如果不是運行上數年都不會被 Octane 捕獲。正如開篇所述,我們有硬數據表明 Octane 的執行和內存配置文件與我們每天在 web 上看到的截然不同。
讓我們來看看今天一些玩弄 Octane 基準的具體例子,其中優化不再反映在現實場景。請注意,即使這可能聽起來有點負面回顧,它絕對不意味著這樣!正如我已經說過好幾遍,Octane 是 JavaScript 性能故事中的重要一章,它發揮了至關重要的作用。在過去由 Octane 驅動的 JavaScript 引擎中的所有優化都是善意地添加的,因為 Octane 是現實場景性能的好代理!每個年代都有它的基準,而對於每一個基準都有一段時間你必須要放手!
話雖如此,讓我們在路上看這個節目,首先看看 Box2D 測試,它是基於 Box2DWeb (一個最初由 Erin Catto 編寫的移植到 JavaScript 的流行的 2D 物理引擎)的。總的來說,很多浮點數學驅動了很多 JavaScript 引擎下很好的優化,但是,事實證明它包含一個可以肆意玩弄基準的漏洞(怪我,我發現了漏洞,並添加在這種情況下的漏洞)。在基準中有一個函數 D.prototype.UpdatePairs,看起來像這樣:
D.prototype.UpdatePairs = function(b) {
var e = this;
var f = e.m_pairCount = 0,
m;
for (f = 0; f < e.m_moveBuffer.length; ++f) {
m = e.m_moveBuffer[f];
var r = e.m_tree.GetFatAABB(m);
e.m_tree.Query(function(t) {
if (t == m) return true;
if (e.m_pairCount == e.m_pairBuffer.length) e.m_pairBuffer[e.m_pairCount] = new O;
var x = e.m_pairBuffer[e.m_pairCount];
x.proxyA = t < m ? t : m;
x.proxyB = t >= m ? t : m;
++e.m_pairCount;
return true
},
r)
}
for (f = e.m_moveBuffer.length = 0; f < e.m_pairCount;) {
r = e.m_pairBuffer[f];
var s = e.m_tree.GetUserData(r.proxyA),
v = e.m_tree.GetUserData(r.proxyB);
b(s, v);
for (++f; f < e.m_pairCount;) {
s = e.m_pairBuffer[f];
if (s.proxyA != r.proxyA || s.proxyB != r.proxyB) break;
++f
}
}
};
一些分析顯示,在第一個循環中傳遞給 e.m_tree.Query 的無辜的內部函數花費了大量的時間:
function(t) {
if (t == m) return true;
if (e.m_pairCount == e.m_pairBuffer.length) e.m_pairBuffer[e.m_pairCount] = new O;
var x = e.m_pairBuffer[e.m_pairCount];
x.proxyA = t < m ? t : m;
x.proxyB = t >= m ? t : m;
++e.m_pairCount;
return true
}
更準確地說,時間並不是開銷在這個函數本身,而是由此觸發的操作和內置庫函數。結果,我們花費了基準調用的總體執行時間的 4-7% 在 Compare` 運行時函數上,它實現了抽象關係比較的一般情況。
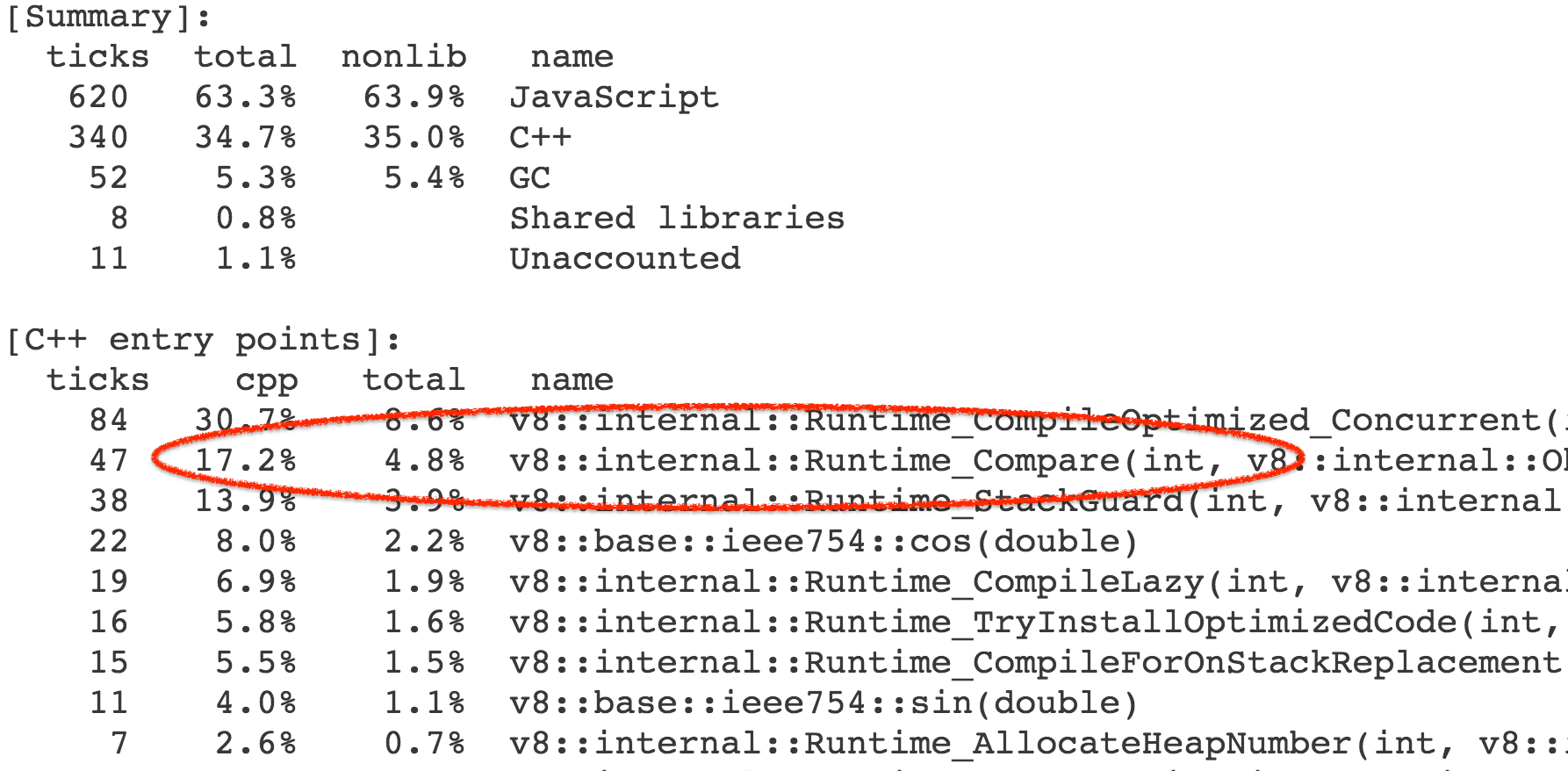
幾乎所有對運行時函數的調用都來自 CompareICStub,它用於內部函數中的兩個關係比較:
x.proxyA = t < m ? t : m;
x.proxyB = t >= m ? t : m;
所以這兩行無辜的代碼要負起 99% 的時間開銷的責任!這怎麼來的?好吧,與 JavaScript 中的許多東西一樣,抽象關係比較 的直觀用法不一定是正確的。在這個函數中,t 和 m 都是 L 的實例,它是這個應用的一個中心類,但不會覆蓋 Symbol.toPrimitive、「toString」、「valueOf」 或 Symbol.toStringTag 屬性,它們與抽象關係比較相關。所以如果你寫 t < m 會發生什麼呢?
- 調用 ToPrimitive(
t,hint Number)。 - 運行 OrdinaryToPrimitive(
t,"number"),因為這裡沒有Symbol.toPrimitive。 - 執行
t.valueOf(),這會獲得t自身的值,因為它調用了默認的 Object.prototype.valueOf。 - 接著執行
t.toString(),這會生成"[object Object]",因為調用了默認的 Object.prototype.toString,並且沒有找到L的 Symbol.toStringTag。 - 調用 ToPrimitive(
m,hint Number)。 - 運行 OrdinaryToPrimitive(
m,"number"),因為這裡沒有Symbol.toPrimitive。 - 執行
m.valueOf(),這會獲得m自身的值,因為它調用了默認的 Object.prototype.valueOf。 - 接著執行
m.toString(),這會生成"[object Object]",因為調用了默認的 Object.prototype.toString,並且沒有找到L的 Symbol.toStringTag。 - 執行比較
"[object Object]" < "[object Object]",結果是false。
至於 t >= m 亦復如是,它總會輸出 true。所以這裡是一個漏洞——使用抽象關係比較這種方法沒有意義。而利用它的方法是使編譯器常數摺疊,即給基準打補丁:
--- octane-box2d.js.ORIG 2016-12-16 07:28:58.442977631 +0100
+++ octane-box2d.js 2016-12-16 07:29:05.615028272 +0100
@@ -2021,8 +2021,8 @@
if (t == m) return true;
if (e.m_pairCount == e.m_pairBuffer.length) e.m_pairBuffer[e.m_pairCount] = new O;
var x = e.m_pairBuffer[e.m_pairCount];
- x.proxyA = t < m ? t : m;
- x.proxyB = t >= m ? t : m;
+ x.proxyA = m;
+ x.proxyB = t;
++e.m_pairCount;
return true
},
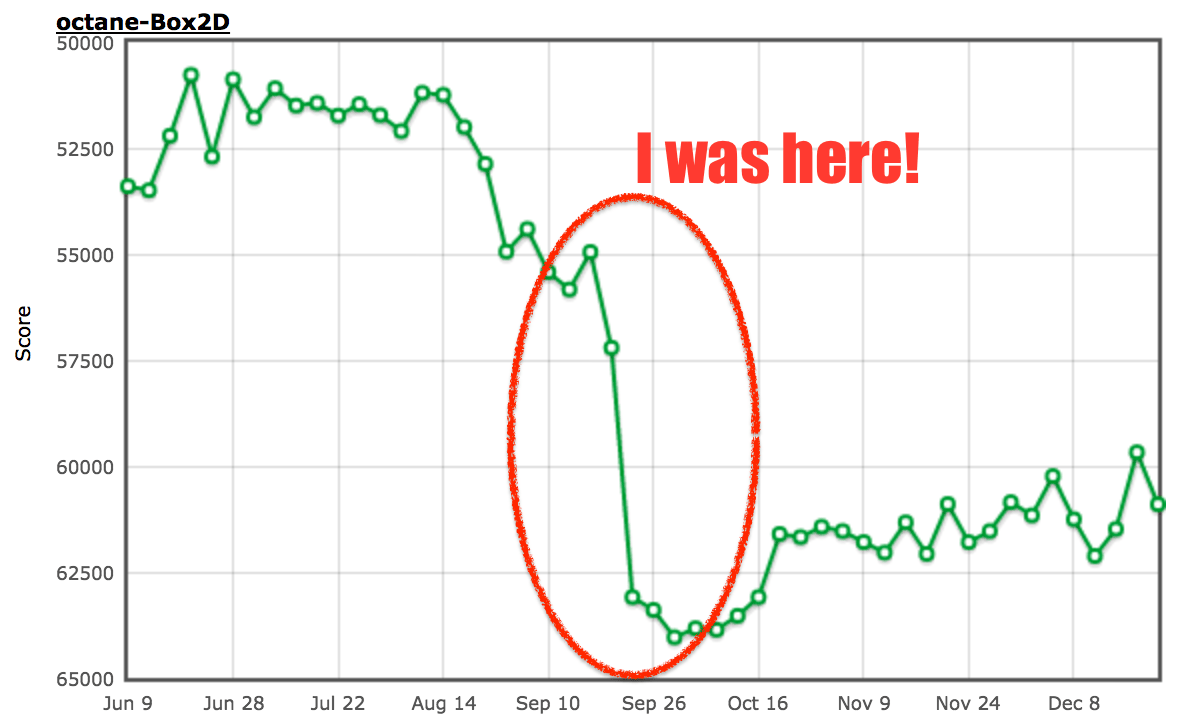
因為這樣做會跳過比較以達到 13% 的驚人的性能提升,並且所有的屬性查找和內置函數的調用都會被它觸發。
$ ~/Projects/v8/out/Release/d8 octane-box2d.js.ORIG
Score (Box2D): 48063
$ ~/Projects/v8/out/Release/d8 octane-box2d.js
Score (Box2D): 55359
$
那麼我們是怎麼做呢?事實證明,我們已經有一種用於跟蹤比較對象的形狀的機制,比較發生於 CompareIC,即所謂的已知接收器映射跟蹤(其中的映射是 V8 的對象形狀+原型),不過這是有限的抽象和嚴格相等比較。但是我可以很容易地擴展跟蹤,並且收集反饋進行抽象的關係比較:
$ ~/Projects/v8/out/Release/d8 --trace-ic octane-box2d.js
[...SNIP...]
[CompareIC in ~+557 at octane-box2d.js:2024 ((UNINITIALIZED+UNINITIALIZED=UNINITIALIZED)->(RECEIVER+RECEIVER=KNOWN_RECEIVER))#LT @ 0x1d5a860493a1]
[CompareIC in ~+649 at octane-box2d.js:2025 ((UNINITIALIZED+UNINITIALIZED=UNINITIALIZED)->(RECEIVER+RECEIVER=KNOWN_RECEIVER))#GTE @ 0x1d5a860496e1]
[...SNIP...]
$
這裡基準代碼中使用的 CompareIC 告訴我們,對於我們正在查看的函數中的 LT(小於)和 GTE(大於或等於)比較,到目前為止這隻能看到 RECEIVERs(接收器,V8 的 JavaScript 對象),並且所有這些接收器具有相同的映射 0x1d5a860493a1,其對應於 L 實例的映射。因此,在優化的代碼中,只要我們知道比較的兩側映射的結果都為 0x1d5a860493a1,並且沒人混淆 L 的原型鏈(即 Symbol.toPrimitive、"valueOf" 和 "toString" 這些方法都是默認的,並且沒人賦予過 Symbol.toStringTag 的訪問許可權),我們可以將這些操作分別常量摺疊為 false 和 true。剩下的故事都是關於 Crankshaft 的黑魔法,有很多一部分都是由於初始化的時候忘記正確地檢查 Symbol.toStringTag 屬性:
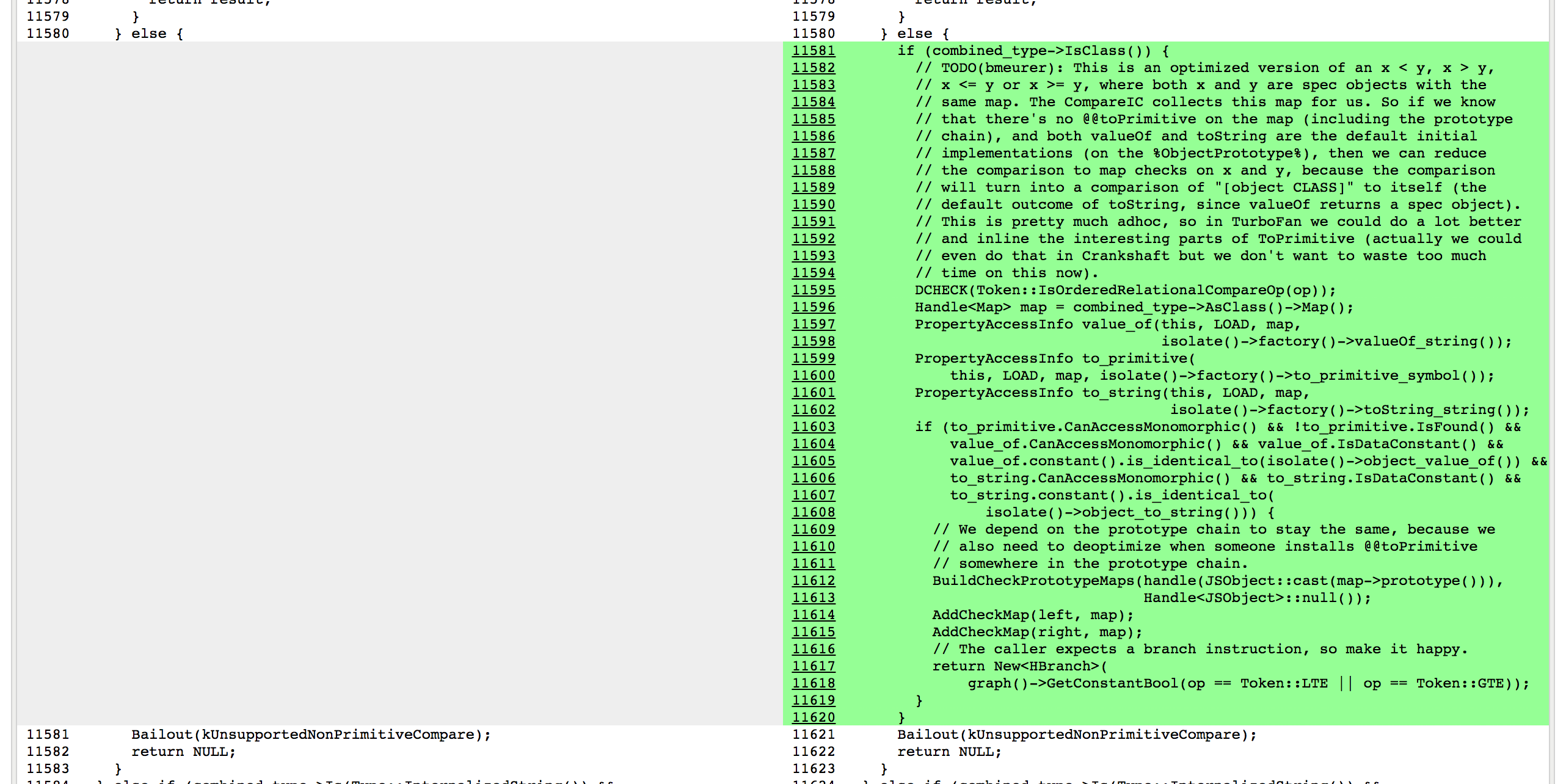
最後,性能在這個特定的基準上有了質的飛躍:
我要聲明一下,當時我並不相信這個特定的行為總是指向源代碼中的漏洞,所以我甚至期望外部代碼經常會遇到這種情況,同時也因為我假設 JavaScript 開發人員不會總是關心這些種類的潛在錯誤。但是,我大錯特錯了,在此我馬上悔改!我不得不承認,這個特殊的優化純粹是一個基準測試的東西,並不會有助於任何真實代碼(除非代碼是為了從這個優化中獲益而寫,不過以後你可以在代碼中直接寫入 true 或 false,而不用再總是使用常量關係比較)。你可能想知道我們為什麼在打補丁後又馬上回滾了一下。這是我們整個團隊投入到 ES2015 實施的非常時期,這才是真正的惡魔之舞,我們需要在沒有嚴格的回歸測試的情況下將所有新特性(ES2015 就是個怪獸)納入傳統基準。
關於 Box2D 點到為止了,讓我們看看 Mandreel 基準。Mandreel 是一個用來將 C/C++ 代碼編譯成 JavaScript 的編譯器,它並沒有用上新一代的 Emscripten 編譯器所使用,並且已經被棄用(或多或少已經從互聯網消失了)大約三年的 JavaScript 子集 asm.js。然而,Octane 仍然有一個通過 Mandreel 編譯的子彈物理引擎。MandreelLatency 測試十分有趣,它測試 Mandreel 基準與頻繁的時間測量檢測點。有一種說法是,由於 Mandreel 強制使用虛擬機編譯器,此測試提供了由編譯器引入的延遲的指示,並且測量檢測點之間的長時間停頓降低了最終得分。這聽起來似乎合情合理,確實有一定的意義。然而,像往常一樣,供應商找到了在這個基準上作弊的方法。

Mandreel 自帶一個重型初始化函數 global_init,光是解析這個函數並為其生成基線代碼就花費了不可思議的時間。因為引擎通常在腳本中多次解析各種函數,一個所謂的預解析步驟用來發現腳本內的函數。然後作為函數第一次被調用完整的解析步驟以生成基線代碼(或者說位元組碼)。這在 V8 中被稱為懶解析。V8 有一些啟發式檢測函數,當預解析浪費時間的時候可以立刻調用,不過對於 Mandreel 基準的 global_init 函數就不太清楚了,於是我們將經歷這個大傢伙「預解析+解析+編譯」的長時間停頓。所以我們添加了一個額外的啟發式函數以避免 global_init 函數的預解析。
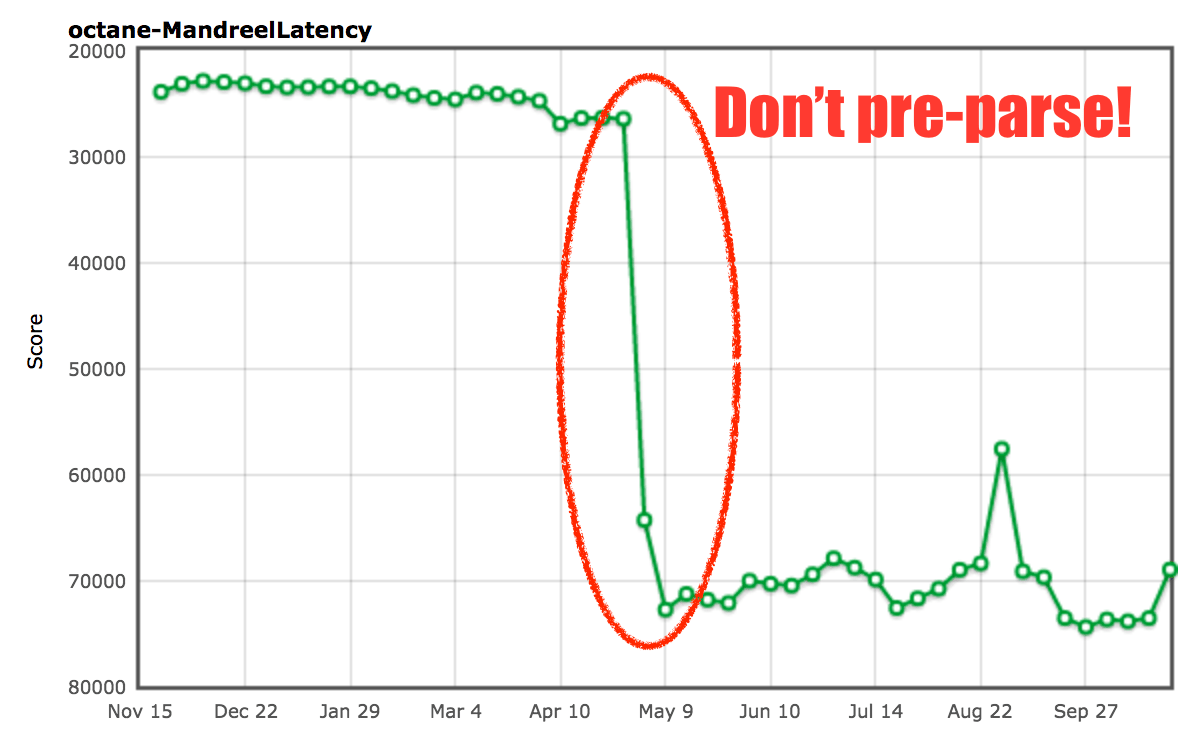
由此可見,在檢測 global_init 和避免昂貴的預解析步驟我們幾乎提升了 2 倍。我們不太確定這是否會對真實用例產生負面影響,不過保證你在預解析大函數的時候將會受益匪淺(因為它們不會立即執行)。
讓我們來看看另一個稍有爭議的基準測試:splay.js 測試,一個用於處理 伸展樹 (二叉查找樹的一種)和練習自動內存管理子系統(也被稱為垃圾回收器)的數據操作基準。它自帶一個延遲測試,這會引導 Splay 代碼通過頻繁的測量檢測點,檢測點之間的長時間停頓表明垃圾回收器的延遲很高。此測試測量延遲暫停的頻率,將它們分類到桶中,並以較低的分數懲罰頻繁的長暫停。這聽起來很棒!沒有 GC 停頓,沒有垃圾。紙上談兵到此為止。讓我們看看這個基準,以下是整個伸展樹業務的核心:

這是伸展樹結構的核心構造,儘管你可能想看完整的基準,不過這基本上是 SplayLatency 得分的重要來源。怎麼回事?實際上,該基準測試是建立巨大的伸展樹,儘可能保留所有節點,從而還原它原本的空間。使用像 V8 這樣的代數垃圾回收器,如果程序違反了代數假設,會導致極端的時間停頓,從本質上看,將所有東西從新空間撤回到舊空間的開銷是非常昂貴的。在舊配置中運行 V8 可以清楚地展示這個問題:
$ out/Release/d8 --trace-gc --noallocation_site_pretenuring octane-splay.js
[20872:0x7f26f24c70d0] 10 ms: Scavenge 2.7 (6.0) -> 2.7 (7.0) MB, 1.1 / 0.0 ms allocation failure
[20872:0x7f26f24c70d0] 12 ms: Scavenge 2.7 (7.0) -> 2.7 (8.0) MB, 1.7 / 0.0 ms allocation failure
[20872:0x7f26f24c70d0] 14 ms: Scavenge 3.7 (8.0) -> 3.6 (10.0) MB, 0.8 / 0.0 ms allocation failure
[20872:0x7f26f24c70d0] 18 ms: Scavenge 4.8 (10.5) -> 4.7 (11.0) MB, 2.5 / 0.0 ms allocation failure
[20872:0x7f26f24c70d0] 22 ms: Scavenge 5.7 (11.0) -> 5.6 (16.0) MB, 2.8 / 0.0 ms allocation failure
[20872:0x7f26f24c70d0] 28 ms: Scavenge 8.7 (16.0) -> 8.6 (17.0) MB, 4.3 / 0.0 ms allocation failure
[20872:0x7f26f24c70d0] 35 ms: Scavenge 9.6 (17.0) -> 9.6 (28.0) MB, 6.9 / 0.0 ms allocation failure
[20872:0x7f26f24c70d0] 49 ms: Scavenge 16.6 (28.5) -> 16.4 (29.0) MB, 8.2 / 0.0 ms allocation failure
[20872:0x7f26f24c70d0] 65 ms: Scavenge 17.5 (29.0) -> 17.5 (52.0) MB, 15.3 / 0.0 ms allocation failure
[20872:0x7f26f24c70d0] 93 ms: Scavenge 32.3 (52.5) -> 32.0 (53.5) MB, 17.6 / 0.0 ms allocation failure
[20872:0x7f26f24c70d0] 126 ms: Scavenge 33.4 (53.5) -> 33.3 (68.0) MB, 31.5 / 0.0 ms allocation failure
[20872:0x7f26f24c70d0] 151 ms: Scavenge 47.9 (68.0) -> 47.6 (69.5) MB, 15.8 / 0.0 ms allocation failure
[20872:0x7f26f24c70d0] 183 ms: Scavenge 49.2 (69.5) -> 49.2 (84.0) MB, 30.9 / 0.0 ms allocation failure
[20872:0x7f26f24c70d0] 210 ms: Scavenge 63.5 (84.0) -> 62.4 (85.0) MB, 14.8 / 0.0 ms allocation failure
[20872:0x7f26f24c70d0] 241 ms: Scavenge 64.7 (85.0) -> 64.6 (99.0) MB, 28.8 / 0.0 ms allocation failure
[20872:0x7f26f24c70d0] 268 ms: Scavenge 78.2 (99.0) -> 77.6 (101.0) MB, 16.1 / 0.0 ms allocation failure
[20872:0x7f26f24c70d0] 298 ms: Scavenge 80.4 (101.0) -> 80.3 (114.5) MB, 28.2 / 0.0 ms allocation failure
[20872:0x7f26f24c70d0] 324 ms: Scavenge 93.5 (114.5) -> 92.9 (117.0) MB, 16.4 / 0.0 ms allocation failure
[20872:0x7f26f24c70d0] 354 ms: Scavenge 96.2 (117.0) -> 96.0 (130.0) MB, 27.6 / 0.0 ms allocation failure
[20872:0x7f26f24c70d0] 383 ms: Scavenge 108.8 (130.0) -> 108.2 (133.0) MB, 16.8 / 0.0 ms allocation failure
[20872:0x7f26f24c70d0] 413 ms: Scavenge 111.9 (133.0) -> 111.7 (145.5) MB, 27.8 / 0.0 ms allocation failure
[20872:0x7f26f24c70d0] 440 ms: Scavenge 124.1 (145.5) -> 123.5 (149.0) MB, 17.4 / 0.0 ms allocation failure
[20872:0x7f26f24c70d0] 473 ms: Scavenge 127.6 (149.0) -> 127.4 (161.0) MB, 29.5 / 0.0 ms allocation failure
[20872:0x7f26f24c70d0] 502 ms: Scavenge 139.4 (161.0) -> 138.8 (165.0) MB, 18.7 / 0.0 ms allocation failure
[20872:0x7f26f24c70d0] 534 ms: Scavenge 143.3 (165.0) -> 143.1 (176.5) MB, 28.5 / 0.0 ms allocation failure
[20872:0x7f26f24c70d0] 561 ms: Scavenge 154.7 (176.5) -> 154.2 (181.0) MB, 19.0 / 0.0 ms allocation failure
[20872:0x7f26f24c70d0] 594 ms: Scavenge 158.9 (181.0) -> 158.7 (192.0) MB, 29.2 / 0.0 ms allocation failure
[20872:0x7f26f24c70d0] 622 ms: Scavenge 170.0 (192.5) -> 169.5 (197.0) MB, 19.5 / 0.0 ms allocation failure
[20872:0x7f26f24c70d0] 655 ms: Scavenge 174.6 (197.0) -> 174.3 (208.0) MB, 28.7 / 0.0 ms allocation failure
[20872:0x7f26f24c70d0] 683 ms: Scavenge 185.4 (208.0) -> 184.9 (212.5) MB, 19.4 / 0.0 ms allocation failure
[20872:0x7f26f24c70d0] 715 ms: Scavenge 190.2 (213.0) -> 190.0 (223.5) MB, 27.7 / 0.0 ms allocation failure
[20872:0x7f26f24c70d0] 743 ms: Scavenge 200.7 (223.5) -> 200.3 (228.5) MB, 19.7 / 0.0 ms allocation failure
[20872:0x7f26f24c70d0] 774 ms: Scavenge 205.8 (228.5) -> 205.6 (239.0) MB, 27.1 / 0.0 ms allocation failure
[20872:0x7f26f24c70d0] 802 ms: Scavenge 216.1 (239.0) -> 215.7 (244.5) MB, 19.8 / 0.0 ms allocation failure
[20872:0x7f26f24c70d0] 833 ms: Scavenge 221.4 (244.5) -> 221.2 (254.5) MB, 26.2 / 0.0 ms allocation failure
[20872:0x7f26f24c70d0] 861 ms: Scavenge 231.5 (255.0) -> 231.1 (260.5) MB, 19.9 / 0.0 ms allocation failure
[20872:0x7f26f24c70d0] 892 ms: Scavenge 237.0 (260.5) -> 236.7 (270.5) MB, 26.3 / 0.0 ms allocation failure
[20872:0x7f26f24c70d0] 920 ms: Scavenge 246.9 (270.5) -> 246.5 (276.0) MB, 20.1 / 0.0 ms allocation failure
[20872:0x7f26f24c70d0] 951 ms: Scavenge 252.6 (276.0) -> 252.3 (286.0) MB, 25.8 / 0.0 ms allocation failure
[20872:0x7f26f24c70d0] 979 ms: Scavenge 262.3 (286.0) -> 261.9 (292.0) MB, 20.3 / 0.0 ms allocation failure
[20872:0x7f26f24c70d0] 1014 ms: Scavenge 268.2 (292.0) -> 267.9 (301.5) MB, 29.8 / 0.0 ms allocation failure
[20872:0x7f26f24c70d0] 1046 ms: Scavenge 277.7 (302.0) -> 277.3 (308.0) MB, 22.4 / 0.0 ms allocation failure
[20872:0x7f26f24c70d0] 1077 ms: Scavenge 283.8 (308.0) -> 283.5 (317.5) MB, 25.1 / 0.0 ms allocation failure
[20872:0x7f26f24c70d0] 1105 ms: Scavenge 293.1 (317.5) -> 292.7 (323.5) MB, 20.7 / 0.0 ms allocation failure
[20872:0x7f26f24c70d0] 1135 ms: Scavenge 299.3 (323.5) -> 299.0 (333.0) MB, 24.9 / 0.0 ms allocation failure
[20872:0x7f26f24c70d0] 1164 ms: Scavenge 308.6 (333.0) -> 308.1 (339.5) MB, 20.9 / 0.0 ms allocation failure
[20872:0x7f26f24c70d0] 1194 ms: Scavenge 314.9 (339.5) -> 314.6 (349.0) MB, 25.0 / 0.0 ms allocation failure
[20872:0x7f26f24c70d0] 1222 ms: Scavenge 324.0 (349.0) -> 323.6 (355.5) MB, 21.1 / 0.0 ms allocation failure
[20872:0x7f26f24c70d0] 1253 ms: Scavenge 330.4 (355.5) -> 330.1 (364.5) MB, 25.1 / 0.0 ms allocation failure
[20872:0x7f26f24c70d0] 1282 ms: Scavenge 339.4 (364.5) -> 339.0 (371.0) MB, 22.2 / 0.0 ms allocation failure
[20872:0x7f26f24c70d0] 1315 ms: Scavenge 346.0 (371.0) -> 345.6 (380.0) MB, 25.8 / 0.0 ms allocation failure
[20872:0x7f26f24c70d0] 1413 ms: Mark-sweep 349.9 (380.0) -> 54.2 (305.0) MB, 5.8 / 0.0 ms (+ 87.5 ms in 73 steps since start of marking, biggest step 8.2 ms, walltime since start of marking 131 ms) finalize incremental marking via stack guard GC in old space requested
[20872:0x7f26f24c70d0] 1457 ms: Scavenge 65.8 (305.0) -> 65.1 (305.0) MB, 31.0 / 0.0 ms allocation failure
[20872:0x7f26f24c70d0] 1489 ms: Scavenge 69.9 (305.0) -> 69.7 (305.0) MB, 27.1 / 0.0 ms allocation failure
[20872:0x7f26f24c70d0] 1523 ms: Scavenge 80.9 (305.0) -> 80.4 (305.0) MB, 22.9 / 0.0 ms allocation failure
[20872:0x7f26f24c70d0] 1553 ms: Scavenge 85.5 (305.0) -> 85.3 (305.0) MB, 24.2 / 0.0 ms allocation failure
[20872:0x7f26f24c70d0] 1581 ms: Scavenge 96.3 (305.0) -> 95.7 (305.0) MB, 18.8 / 0.0 ms allocation failure
[20872:0x7f26f24c70d0] 1616 ms: Scavenge 101.1 (305.0) -> 100.9 (305.0) MB, 29.2 / 0.0 ms allocation failure
[20872:0x7f26f24c70d0] 1648 ms: Scavenge 111.6 (305.0) -> 111.1 (305.0) MB, 22.5 / 0.0 ms allocation failure
[20872:0x7f26f24c70d0] 1678 ms: Scavenge 116.7 (305.0) -> 116.5 (305.0) MB, 25.0 / 0.0 ms allocation failure
[20872:0x7f26f24c70d0] 1709 ms: Scavenge 127.0 (305.0) -> 126.5 (305.0) MB, 20.7 / 0.0 ms allocation failure
[20872:0x7f26f24c70d0] 1738 ms: Scavenge 132.3 (305.0) -> 132.1 (305.0) MB, 23.9 / 0.0 ms allocation failure
[20872:0x7f26f24c70d0] 1767 ms: Scavenge 142.4 (305.0) -> 141.9 (305.0) MB, 19.6 / 0.0 ms allocation failure
[20872:0x7f26f24c70d0] 1796 ms: Scavenge 147.9 (305.0) -> 147.7 (305.0) MB, 23.8 / 0.0 ms allocation failure
[20872:0x7f26f24c70d0] 1825 ms: Scavenge 157.8 (305.0) -> 157.3 (305.0) MB, 19.9 / 0.0 ms allocation failure
[20872:0x7f26f24c70d0] 1853 ms: Scavenge 163.5 (305.0) -> 163.2 (305.0) MB, 22.2 / 0.0 ms allocation failure
[20872:0x7f26f24c70d0] 1881 ms: Scavenge 173.2 (305.0) -> 172.7 (305.0) MB, 19.1 / 0.0 ms allocation failure
[20872:0x7f26f24c70d0] 1910 ms: Scavenge 179.1 (305.0) -> 178.8 (305.0) MB, 23.0 / 0.0 ms allocation failure
[20872:0x7f26f24c70d0] 1944 ms: Scavenge 188.6 (305.0) -> 188.1 (305.0) MB, 25.1 / 0.0 ms allocation failure
[20872:0x7f26f24c70d0] 1979 ms: Scavenge 194.7 (305.0) -> 194.4 (305.0) MB, 28.4 / 0.0 ms allocation failure
[20872:0x7f26f24c70d0] 2011 ms: Scavenge 204.0 (305.0) -> 203.6 (305.0) MB, 23.4 / 0.0 ms allocation failure
[20872:0x7f26f24c70d0] 2041 ms: Scavenge 210.2 (305.0) -> 209.9 (305.0) MB, 23.8 / 0.0 ms allocation failure
[20872:0x7f26f24c70d0] 2074 ms: Scavenge 219.4 (305.0) -> 219.0 (305.0) MB, 24.5 / 0.0 ms allocation failure
[20872:0x7f26f24c70d0] 2105 ms: Scavenge 225.8 (305.0) -> 225.4 (305.0) MB, 24.7 / 0.0 ms allocation failure
[20872:0x7f26f24c70d0] 2138 ms: Scavenge 234.8 (305.0) -> 234.4 (305.0) MB, 23.1 / 0.0 ms allocation failure
[...SNIP...]
$
因此這裡關鍵的發現是直接在舊空間中分配伸展樹節點可基本避免在周圍複製對象的所有開銷,並且將次要 GC 周期的數量減少到最小(從而減少 GC 引起的停頓時間)。我們想出了一種稱為 分配場所預占 的機制,當運行到基線代碼時,將嘗試動態收集分配場所的反饋,以決定在此分配的對象的確切部分是否存在,如果是,則優化代碼以直接在舊空間分配對象——即預占對象。
$ out/Release/d8 --trace-gc octane-splay.js
[20885:0x7ff4d7c220a0] 8 ms: Scavenge 2.7 (6.0) -> 2.6 (7.0) MB, 1.2 / 0.0 ms allocation failure
[20885:0x7ff4d7c220a0] 10 ms: Scavenge 2.7 (7.0) -> 2.7 (8.0) MB, 1.6 / 0.0 ms allocation failure
[20885:0x7ff4d7c220a0] 11 ms: Scavenge 3.6 (8.0) -> 3.6 (10.0) MB, 0.9 / 0.0 ms allocation failure
[20885:0x7ff4d7c220a0] 17 ms: Scavenge 4.8 (10.5) -> 4.7 (11.0) MB, 2.9 / 0.0 ms allocation failure
[20885:0x7ff4d7c220a0] 20 ms: Scavenge 5.6 (11.0) -> 5.6 (16.0) MB, 2.8 / 0.0 ms allocation failure
[20885:0x7ff4d7c220a0] 26 ms: Scavenge 8.7 (16.0) -> 8.6 (17.0) MB, 4.5 / 0.0 ms allocation failure
[20885:0x7ff4d7c220a0] 34 ms: Scavenge 9.6 (17.0) -> 9.5 (28.0) MB, 6.8 / 0.0 ms allocation failure
[20885:0x7ff4d7c220a0] 48 ms: Scavenge 16.6 (28.5) -> 16.4 (29.0) MB, 8.6 / 0.0 ms allocation failure
[20885:0x7ff4d7c220a0] 64 ms: Scavenge 17.5 (29.0) -> 17.5 (52.0) MB, 15.2 / 0.0 ms allocation failure
[20885:0x7ff4d7c220a0] 96 ms: Scavenge 32.3 (52.5) -> 32.0 (53.5) MB, 19.6 / 0.0 ms allocation failure
[20885:0x7ff4d7c220a0] 153 ms: Scavenge 61.3 (81.5) -> 57.4 (93.5) MB, 27.9 / 0.0 ms allocation failure
[20885:0x7ff4d7c220a0] 432 ms: Scavenge 339.3 (364.5) -> 326.6 (364.5) MB, 12.7 / 0.0 ms allocation failure
[20885:0x7ff4d7c220a0] 666 ms: Scavenge 563.7 (592.5) -> 553.3 (595.5) MB, 20.5 / 0.0 ms allocation failure
[20885:0x7ff4d7c220a0] 825 ms: Mark-sweep 603.9 (644.0) -> 96.0 (528.0) MB, 4.0 / 0.0 ms (+ 92.5 ms in 51 steps since start of marking, biggest step 4.6 ms, walltime since start of marking 160 ms) finalize incremental marking via stack guard GC in old space requested
[20885:0x7ff4d7c220a0] 1068 ms: Scavenge 374.8 (528.0) -> 362.6 (528.0) MB, 19.1 / 0.0 ms allocation failure
[20885:0x7ff4d7c220a0] 1304 ms: Mark-sweep 460.1 (528.0) -> 102.5 (444.5) MB, 10.3 / 0.0 ms (+ 117.1 ms in 59 steps since start of marking, biggest step 7.3 ms, walltime since start of marking 200 ms) finalize incremental marking via stack guard GC in old space requested
[20885:0x7ff4d7c220a0] 1587 ms: Scavenge 374.2 (444.5) -> 361.6 (444.5) MB, 13.6 / 0.0 ms allocation failure
[20885:0x7ff4d7c220a0] 1828 ms: Mark-sweep 485.2 (520.0) -> 101.5 (519.5) MB, 3.4 / 0.0 ms (+ 102.8 ms in 58 steps since start of marking, biggest step 4.5 ms, walltime since start of marking 183 ms) finalize incremental marking via stack guard GC in old space requested
[20885:0x7ff4d7c220a0] 2028 ms: Scavenge 371.4 (519.5) -> 358.5 (519.5) MB, 12.1 / 0.0 ms allocation failure
[...SNIP...]
$
事實上,這完全解決了 SplayLatency 基準的問題,並提高我們的得分至超過 250%!
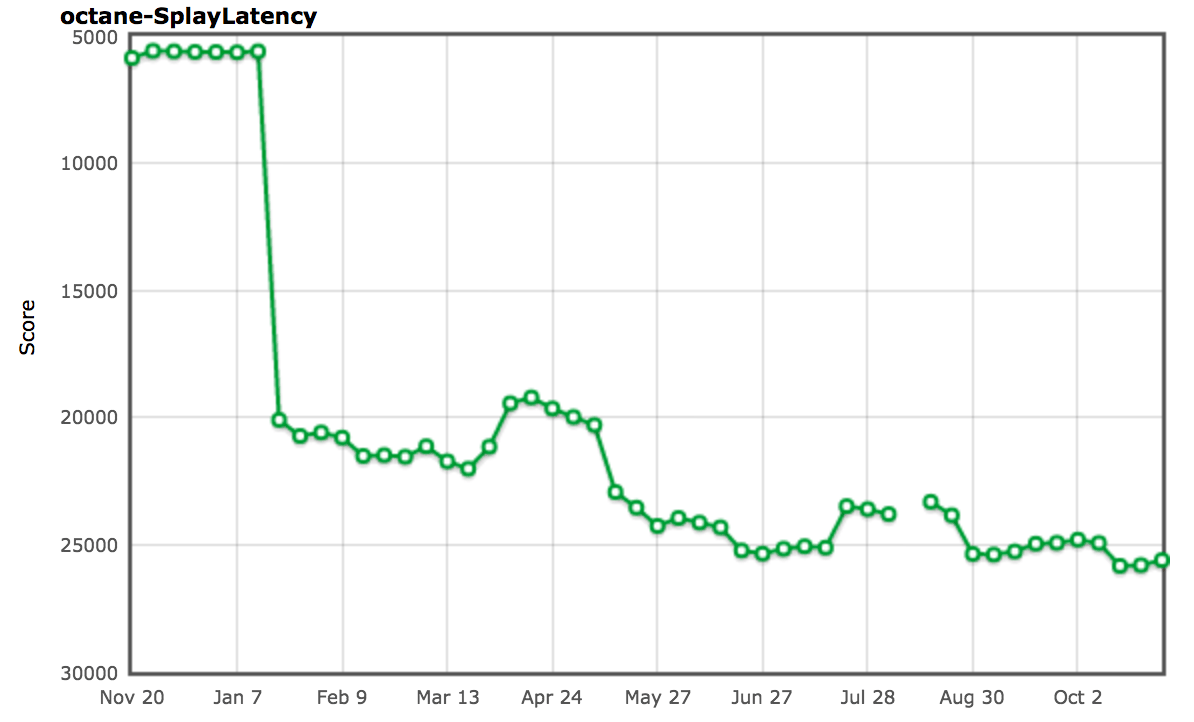
正如 SIGPLAN 論文 中所提及的,我們有充分的理由相信,分配場所預占機制可能真的贏得了真實世界應用的歡心,並真正期待看到改進和擴展後的機制,那時將不僅僅是對象和數組字面量。但是不久後我們意識到分配場所預占機制對真實世界應用產生了相當嚴重的負面影響。我們實際上聽到很多負面報道,包括 Ember.js 開發者和用戶的唇槍舌戰,雖然不僅是因為分配場所預占機制,不過它是事故的罪魁禍首。
分配場所預占機制的基本問題數之不盡,這在今天的應用中非常常見(主要是由於框架,同時還有其它原因),假設你的對象工廠最初是用於創建構成你的對象模型和視圖的長周期對象的,它將你的工廠方法中的分配場所轉換為永久狀態,並且從工廠分配的所有內容都立即轉到舊空間。現在初始設置完成後,你的應用開始工作,作為其中的一部分,從工廠分配臨時對象會污染舊空間,最終導致開銷昂貴的垃圾回收周期以及其它負面的副作用,例如過早觸發增量標記。
我們開始重新考慮基準驅動的工作,並開始尋找現實場景驅動的替代方案,這導致了 Orinoco 的誕生,它的目標是逐步改進垃圾回收器;這個努力的一部分是一個稱為「 統一堆 」的項目,如果頁面中所有內容基本都存在,它將嘗試避免複製對象。也就是說站在更高的層面看:如果新空間充滿活動對象,只需將所有新空間頁面標記為屬於舊空間,然後從空白頁面創建一個新空間。這可能不會在 SplayLatency 基準測試中得到相同的分數,但是這對於真實用例更友好,它可以自動適配具體的用例。我們還考慮 並發標記 ,將標記工作卸載到單獨的線程,從而進一步減少增量標記對延遲和吞吐量的負面影響。
輕鬆一刻

喘口氣。
好吧,我想這足以強調我的觀點了。我可以繼續指出更多的例子,其中 Octane 驅動的改進後來變成了一個壞主意,也許改天我會接著寫下去。但是今天就到此為止了吧。
結論
我希望現在應該清楚為什麼基準測試通常是一個好主意,但是只對某個特定的級別有用,一旦你跨越了 有用競爭 的界限,你就會開始浪費你們工程師的時間,甚至開始損害到你的真實世界的性能!如果我們認真考慮 web 的性能,我們需要根據真實世界的性能來測評瀏覽器,而不是它們玩弄一個四年前的基準的能力。我們需要開始教育(技術)媒體,可能這沒用,但至少請忽略他們。
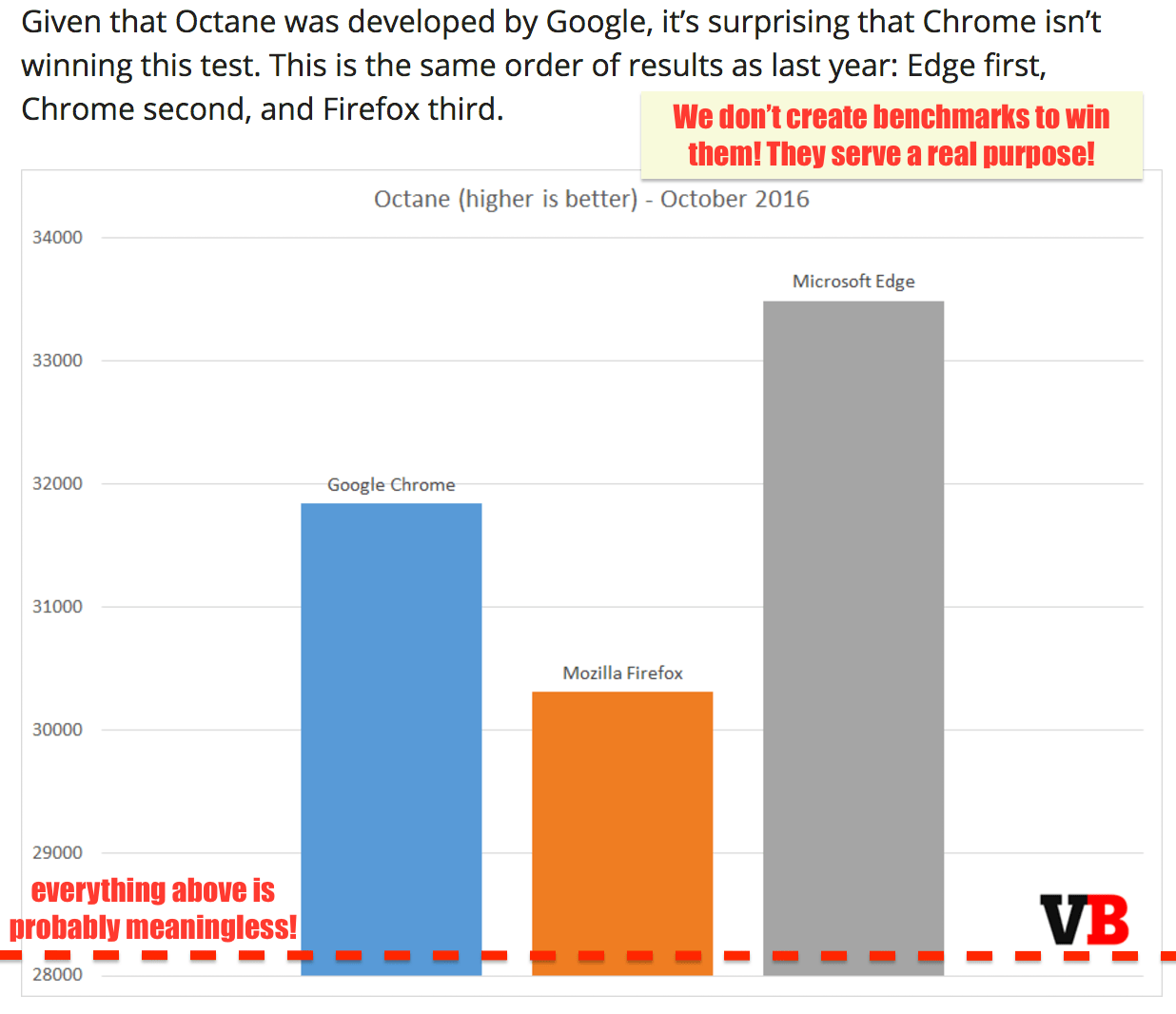
沒人害怕競爭,但是玩弄可能已經壞掉的基準不像是在合理使用工程時間。我們可以盡更大的努力,並把 JavaScript 提高到更高的水平。讓我們開展有意義的性能測試,以便為最終用戶和開發者帶來有意思的領域競爭。此外,讓我們再對運行在 Node.js( V8 或 ChakraCore)中的伺服器端和工具端代碼做一些有意義的改進!

結束語:不要用傳統的 JavaScript 基準來比較手機。這是真正最沒用的事情,因為 JavaScript 的性能通常取決於軟體,而不一定是硬體,並且 Chrome 每 6 周發布一個新版本,所以你在三月份的測試結果到了四月份就已經毫不相關了。如果為手機中的瀏覽器做個排名不可避免,那麼至少請使用一個現代健全的瀏覽器基準來測試,至少這個基準要知道人們會用瀏覽器來幹什麼,比如 Speedometer 基準。
感謝你花時間閱讀!
作者簡介:
我是 Benedikt Meurer,住在 Ottobrunn(德國巴伐利亞州慕尼黑東南部的一個市鎮)的一名軟體工程師。我於 2007 年在錫根大學獲得應用計算機科學與電氣工程的文憑,打那以後的 5 年裡我在編譯器和軟體分析領域擔任研究員(2007 至 2008 年間還研究過微系統設計)。2013 年我加入了谷歌的慕尼黑辦公室,我的工作目標主要是 V8 JavaScript 引擎,目前是 JavaScript 執行性能優化團隊的一名技術領導。
via: http://benediktmeurer.de/2016/12/16/the-truth-about-traditional-javascript-benchmarks
作者:Benedikt Meurer 譯者:OneNewLife 校對:OneNewLife, wxy
本文轉載來自 Linux 中國: https://github.com/Linux-CN/archive
對這篇文章感覺如何?
You may also like






More in:Linux中國

捐贈 Let's Encrypt,共建安全的互聯網

Let's Encrypt 正式發布,已經保護 380 萬個域名

關於Linux防火牆iptables的面試問答

Lets Encrypt 已被所有主流瀏覽器所信任









