並發伺服器(四):libuv

這是並發網路伺服器系列文章的第四部分。在這一部分中,我們將使用 libuv 再次重寫我們的伺服器,並且也會討論關於使用一個線程池在回調中去處理耗時任務。最終,我們去看一下底層的 libuv,花一點時間去學習如何用非同步 API 對文件系統阻塞操作進行封裝。
本系列的所有文章:
使用 libuv 抽象出事件驅動循環
在 第三節 中,我們看到了基於 select 和 epoll 的伺服器的相似之處,並且,我說過,在它們之間抽象出細微的差別是件很有吸引力的事。許多庫已經做到了這些,所以在這一部分中我將去選一個並使用它。我選的這個庫是 libuv,它最初設計用於 Node.js 底層的可移植平台層,並且,後來發現在其它的項目中也有使用。libuv 是用 C 寫的,因此,它具有很高的可移植性,非常適用嵌入到像 JavaScript 和 Python 這樣的高級語言中。
雖然 libuv 為了抽象出底層平台細節已經變成了一個相當大的框架,但它仍然是以 事件循環 思想為中心的。在我們第三部分的事件驅動伺服器中,事件循環是顯式定義在 main 函數中的;當使用 libuv 時,該循環通常隱藏在庫自身中,而用戶代碼僅需要註冊事件句柄(作為一個回調函數)和運行這個循環。此外,libuv 會在給定的平台上使用更快的事件循環實現,對於 Linux 它是 epoll,等等。
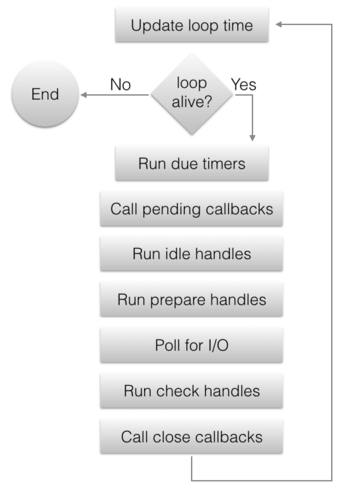
libuv 支持多路事件循環,因此事件循環在庫中是非常重要的;它有一個句柄 —— uv_loop_t,以及創建/殺死/啟動/停止循環的函數。也就是說,在這篇文章中,我將僅需要使用 「默認的」 循環,libuv 可通過 uv_default_loop() 提供它;多路循環大多用於多線程事件驅動的伺服器,這是一個更高級別的話題,我將留在這一系列文章的以後部分。
使用 libuv 的並發伺服器
為了對 libuv 有一個更深的印象,讓我們跳轉到我們的可靠協議的伺服器,它通過我們的這個系列已經有了一個強大的重新實現。這個伺服器的結構與第三部分中的基於 select 和 epoll 的伺服器有一些相似之處,因為,它也依賴回調。完整的 示例代碼在這裡;我們開始設置這個伺服器的套接字綁定到一個本地埠:
int portnum = 9090;
if (argc >= 2) {
portnum = atoi(argv[1]);
}
printf("Serving on port %dn", portnum);
int rc;
uv_tcp_t server_stream;
if ((rc = uv_tcp_init(uv_default_loop(), &server_stream)) < 0) {
die("uv_tcp_init failed: %s", uv_strerror(rc));
}
struct sockaddr_in server_address;
if ((rc = uv_ip4_addr("0.0.0.0", portnum, &server_address)) < 0) {
die("uv_ip4_addr failed: %s", uv_strerror(rc));
}
if ((rc = uv_tcp_bind(&server_stream, (const struct sockaddr*)&server_address, 0)) < 0) {
die("uv_tcp_bind failed: %s", uv_strerror(rc));
}
除了它被封裝進 libuv API 中之外,你看到的是一個相當標準的套接字。在它的返回中,我們取得了一個可工作於任何 libuv 支持的平台上的可移植介面。
這些代碼也展示了很認真負責的錯誤處理;多數的 libuv 函數返回一個整數狀態,返回一個負數意味著出現了一個錯誤。在我們的伺服器中,我們把這些錯誤看做致命問題進行處理,但也可以設想一個更優雅的錯誤恢復。
現在,那個套接字已經綁定,是時候去監聽它了。這裡我們運行首個回調註冊:
// Listen on the socket for new peers to connect. When a new peer connects,
// the on_peer_connected callback will be invoked.
if ((rc = uv_listen((uv_stream_t*)&server_stream, N_BACKLOG, on_peer_connected)) < 0) {
die("uv_listen failed: %s", uv_strerror(rc));
}
uv_listen 註冊一個事件回調,當新的對端連接到這個套接字時將會調用事件循環。我們的回調在這裡被稱為 on_peer_connected,我們一會兒將去查看它。
最終,main 運行這個 libuv 循環,直到它被停止(uv_run 僅在循環被停止或者發生錯誤時返回)。
// Run the libuv event loop.
uv_run(uv_default_loop(), UV_RUN_DEFAULT);
// If uv_run returned, close the default loop before exiting.
return uv_loop_close(uv_default_loop());
注意,在運行事件循環之前,只有一個回調是通過 main 註冊的;我們稍後將看到怎麼去添加更多的回調。在事件循環的整個運行過程中,添加和刪除回調並不是一個問題 —— 事實上,大多數伺服器就是這麼寫的。
這是一個 on_peer_connected,它處理到伺服器的新的客戶端連接:
void on_peer_connected(uv_stream_t* server_stream, int status) {
if (status < 0) {
fprintf(stderr, "Peer connection error: %sn", uv_strerror(status));
return;
}
// client will represent this peer; it's allocated on the heap and only
// released when the client disconnects. The client holds a pointer to
// peer_state_t in its data field; this peer state tracks the protocol state
// with this client throughout interaction.
uv_tcp_t* client = (uv_tcp_t*)xmalloc(sizeof(*client));
int rc;
if ((rc = uv_tcp_init(uv_default_loop(), client)) < 0) {
die("uv_tcp_init failed: %s", uv_strerror(rc));
}
client->data = NULL;
if (uv_accept(server_stream, (uv_stream_t*)client) == 0) {
struct sockaddr_storage peername;
int namelen = sizeof(peername);
if ((rc = uv_tcp_getpeername(client, (struct sockaddr*)&peername,
&namelen)) < 0) {
die("uv_tcp_getpeername failed: %s", uv_strerror(rc));
}
report_peer_connected((const struct sockaddr_in*)&peername, namelen);
// Initialize the peer state for a new client: we start by sending the peer
// the initial '*' ack.
peer_state_t* peerstate = (peer_state_t*)xmalloc(sizeof(*peerstate));
peerstate->state = INITIAL_ACK;
peerstate->sendbuf[0] = '*';
peerstate->sendbuf_end = 1;
peerstate->client = client;
client->data = peerstate;
// Enqueue the write request to send the ack; when it's done,
// on_wrote_init_ack will be called. The peer state is passed to the write
// request via the data pointer; the write request does not own this peer
// state - it's owned by the client handle.
uv_buf_t writebuf = uv_buf_init(peerstate->sendbuf, peerstate->sendbuf_end);
uv_write_t* req = (uv_write_t*)xmalloc(sizeof(*req));
req->data = peerstate;
if ((rc = uv_write(req, (uv_stream_t*)client, &writebuf, 1,
on_wrote_init_ack)) < 0) {
die("uv_write failed: %s", uv_strerror(rc));
}
} else {
uv_close((uv_handle_t*)client, on_client_closed);
}
}
這些代碼都有很好的注釋,但是,這裡有一些重要的 libuv 語法我想去強調一下:
- 傳入自定義數據到回調中:因為 C 語言還沒有閉包,這可能是個挑戰,libuv 在它的所有的處理類型中有一個
void* data欄位;這些欄位可以被用於傳遞用戶數據。例如,注意client->data是如何指向到一個peer_state_t結構上,以便於uv_write和uv_read_start註冊的回調可以知道它們正在處理的是哪個客戶端的數據。 - 內存管理:在帶有垃圾回收的語言中進行事件驅動編程是非常容易的,因為,回調通常運行在一個與它們註冊的地方完全不同的棧幀中,使得基於棧的內存管理很困難。它總是需要傳遞堆分配的數據到 libuv 回調中(當所有回調運行時,除了
main,其它的都運行在棧上),並且,為了避免泄漏,許多情況下都要求這些數據去安全釋放(free())。這些都是些需要實踐的內容 注1 。
這個伺服器上對端的狀態如下:
typedef struct {
ProcessingState state;
char sendbuf[SENDBUF_SIZE];
int sendbuf_end;
uv_tcp_t* client;
} peer_state_t;
它與第三部分中的狀態非常類似;我們不再需要 sendptr,因為,在調用 「done writing」 回調之前,uv_write 將確保發送它提供的整個緩衝。我們也為其它的回調使用保持了一個到客戶端的指針。這裡是 on_wrote_init_ack:
void on_wrote_init_ack(uv_write_t* req, int status) {
if (status) {
die("Write error: %sn", uv_strerror(status));
}
peer_state_t* peerstate = (peer_state_t*)req->data;
// Flip the peer state to WAIT_FOR_MSG, and start listening for incoming data
// from this peer.
peerstate->state = WAIT_FOR_MSG;
peerstate->sendbuf_end = 0;
int rc;
if ((rc = uv_read_start((uv_stream_t*)peerstate->client, on_alloc_buffer,
on_peer_read)) < 0) {
die("uv_read_start failed: %s", uv_strerror(rc));
}
// Note: the write request doesn't own the peer state, hence we only free the
// request itself, not the state.
free(req);
}
然後,我們確信知道了這個初始的 '*' 已經被發送到對端,我們通過調用 uv_read_start 去監聽從這個對端來的入站數據,它註冊一個將被事件循環調用的回調(on_peer_read),不論什麼時候,事件循環都在套接字上接收來自客戶端的調用:
void on_peer_read(uv_stream_t* client, ssize_t nread, const uv_buf_t* buf) {
if (nread < 0) {
if (nread != uv_eof) {
fprintf(stderr, "read error: %sn", uv_strerror(nread));
}
uv_close((uv_handle_t*)client, on_client_closed);
} else if (nread == 0) {
// from the documentation of uv_read_cb: nread might be 0, which does not
// indicate an error or eof. this is equivalent to eagain or ewouldblock
// under read(2).
} else {
// nread > 0
assert(buf->len >= nread);
peer_state_t* peerstate = (peer_state_t*)client->data;
if (peerstate->state == initial_ack) {
// if the initial ack hasn't been sent for some reason, ignore whatever
// the client sends in.
free(buf->base);
return;
}
// run the protocol state machine.
for (int i = 0; i < nread; ++i) {
switch (peerstate->state) {
case initial_ack:
assert(0 && "can't reach here");
break;
case wait_for_msg:
if (buf->base[i] == '^') {
peerstate->state = in_msg;
}
break;
case in_msg:
if (buf->base[i] == '$') {
peerstate->state = wait_for_msg;
} else {
assert(peerstate->sendbuf_end < sendbuf_size);
peerstate->sendbuf[peerstate->sendbuf_end++] = buf->base[i] + 1;
}
break;
}
}
if (peerstate->sendbuf_end > 0) {
// we have data to send. the write buffer will point to the buffer stored
// in the peer state for this client.
uv_buf_t writebuf =
uv_buf_init(peerstate->sendbuf, peerstate->sendbuf_end);
uv_write_t* writereq = (uv_write_t*)xmalloc(sizeof(*writereq));
writereq->data = peerstate;
int rc;
if ((rc = uv_write(writereq, (uv_stream_t*)client, &writebuf, 1,
on_wrote_buf)) < 0) {
die("uv_write failed: %s", uv_strerror(rc));
}
}
}
free(buf->base);
}
這個伺服器的運行時行為非常類似於第三部分的事件驅動伺服器:所有的客戶端都在一個單個的線程中並發處理。並且類似的,一些特定的行為必須在伺服器代碼中維護:伺服器的邏輯實現為一個集成的回調,並且長周期運行是禁止的,因為它會阻塞事件循環。這一點也很類似。讓我們進一步探索這個問題。
在事件驅動循環中的長周期運行的操作
單線程的事件驅動代碼使它先天就容易受到一些常見問題的影響:長周期運行的代碼會阻塞整個循環。參見如下的程序:
void on_timer(uv_timer_t* timer) {
uint64_t timestamp = uv_hrtime();
printf("on_timer [%" PRIu64 " ms]n", (timestamp / 1000000) % 100000);
// "Work"
if (random() % 5 == 0) {
printf("Sleeping...n");
sleep(3);
}
}
int main(int argc, const char** argv) {
uv_timer_t timer;
uv_timer_init(uv_default_loop(), &timer);
uv_timer_start(&timer, on_timer, 0, 1000);
return uv_run(uv_default_loop(), UV_RUN_DEFAULT);
}
它用一個單個註冊的回調運行一個 libuv 事件循環:on_timer,它被每秒鐘循環調用一次。回調報告一個時間戳,並且,偶爾通過睡眠 3 秒去模擬一個長周期運行。這是運行示例:
$ ./uv-timer-sleep-demo
on_timer [4840 ms]
on_timer [5842 ms]
on_timer [6843 ms]
on_timer [7844 ms]
Sleeping...
on_timer [11845 ms]
on_timer [12846 ms]
Sleeping...
on_timer [16847 ms]
on_timer [17849 ms]
on_timer [18850 ms]
...
on_timer 忠實地每秒執行一次,直到隨機出現的睡眠為止。在那個時間點,on_timer 不再被調用,直到睡眠時間結束;事實上,沒有其它的回調 會在這個時間幀中被調用。這個睡眠調用阻塞了當前線程,它正是被調用的線程,並且也是事件循環使用的線程。當這個線程被阻塞後,事件循環也被阻塞。
這個示例演示了在事件驅動的調用中為什麼回調不能被阻塞是多少的重要。並且,同樣適用於 Node.js 伺服器、客戶端側的 Javascript、大多數的 GUI 編程框架、以及許多其它的非同步編程模型。
但是,有時候運行耗時的任務是不可避免的。並不是所有任務都有一個非同步 API;例如,我們可能使用一些僅有同步 API 的庫去處理,或者,正在執行一個可能的長周期計算。我們如何用事件驅動編程去結合這些代碼?線程可以幫到你!
「轉換」 阻塞調用為非同步調用的線程
一個線程池可以用於轉換阻塞調用為非同步調用,通過與事件循環並行運行,並且當任務完成時去由它去公布事件。以阻塞函數 do_work() 為例,這裡介紹了它是怎麼運行的:
- 不在一個回調中直接調用
do_work(),而是將它打包進一個 「任務」,讓線程池去運行這個任務。當任務完成時,我們也為循環去調用它註冊一個回調;我們稱它為on_work_done()。 - 在這個時間點,我們的回調就可以返回了,而事件循環保持運行;在同一時間點,線程池中的有一個線程運行這個任務。
- 一旦任務運行完成,通知主線程(指正在運行事件循環的線程),並且事件循環調用
on_work_done()。
讓我們看一下,使用 libuv 的工作調度 API,是怎麼去解決我們前面的計時器/睡眠示例中展示的問題的:
void on_after_work(uv_work_t* req, int status) {
free(req);
}
void on_work(uv_work_t* req) {
// "Work"
if (random() % 5 == 0) {
printf("Sleeping...n");
sleep(3);
}
}
void on_timer(uv_timer_t* timer) {
uint64_t timestamp = uv_hrtime();
printf("on_timer [%" PRIu64 " ms]n", (timestamp / 1000000) % 100000);
uv_work_t* work_req = (uv_work_t*)malloc(sizeof(*work_req));
uv_queue_work(uv_default_loop(), work_req, on_work, on_after_work);
}
int main(int argc, const char** argv) {
uv_timer_t timer;
uv_timer_init(uv_default_loop(), &timer);
uv_timer_start(&timer, on_timer, 0, 1000);
return uv_run(uv_default_loop(), UV_RUN_DEFAULT);
}
通過一個 work_req 注2 類型的句柄,我們進入一個任務隊列,代替在 on_timer 上直接調用 sleep,這個函數在任務中(on_work)運行,並且,一旦任務完成(on_after_work),這個函數被調用一次。on_work 是指 「work」(阻塞中的/耗時的操作)進行的地方。注意在這兩個回調傳遞到 uv_queue_work 時的一個關鍵區別:on_work 運行在線程池中,而 on_after_work 運行在事件循環中的主線程上 —— 就好像是其它的回調一樣。
讓我們看一下這種方式的運行:
$ ./uv-timer-work-demo
on_timer [89571 ms]
on_timer [90572 ms]
on_timer [91573 ms]
on_timer [92575 ms]
Sleeping...
on_timer [93576 ms]
on_timer [94577 ms]
Sleeping...
on_timer [95577 ms]
on_timer [96578 ms]
on_timer [97578 ms]
...
即便在 sleep 函數被調用時,定時器也每秒鐘滴答一下,睡眠現在運行在一個單獨的線程中,並且不會阻塞事件循環。
一個用於練習的素數測試伺服器
因為通過睡眠去模擬工作並不是件讓人興奮的事,我有一個事先準備好的更綜合的一個示例 —— 一個基於套接字接受來自客戶端的數字的伺服器,檢查這個數字是否是素數,然後去返回一個 「prime" 或者 「composite」。完整的 伺服器代碼在這裡 —— 我不在這裡粘貼了,因為它太長了,更希望讀者在一些自己的練習中去體會它。
這個伺服器使用了一個原生的素數測試演算法,因此,對於大的素數可能花很長時間才返回一個回答。在我的機器中,對於 2305843009213693951,它花了 ~5 秒鐘去計算,但是,你的方法可能不同。
練習 1:伺服器有一個設置(通過一個名為 MODE 的環境變數)要麼在套接字回調(意味著在主線程上)中運行素數測試,要麼在 libuv 工作隊列中。當多個客戶端同時連接時,使用這個設置來觀察伺服器的行為。當它計算一個大的任務時,在阻塞模式中,伺服器將不回復其它客戶端,而在非阻塞模式中,它會回復。
練習 2:libuv 有一個預設大小的線程池,並且線程池的大小可以通過環境變數配置。你可以通過使用多個客戶端去實驗找出它的預設值是多少?找到線程池預設值後,使用不同的設置去看一下,在重負載下怎麼去影響伺服器的響應能力。
在非阻塞文件系統中使用工作隊列
對於只是呆板的演示和 CPU 密集型的計算來說,將可能的阻塞操作委託給一個線程池並不是明智的;libuv 在它的文件系統 API 中本身就大量使用了這種能力。通過這種方式,libuv 使用一個非同步 API,以一個輕便的方式顯示出它強大的文件系統的處理能力。
讓我們使用 uv_fs_read(),例如,這個函數從一個文件中(表示為一個 uv_fs_t 句柄)讀取一個文件到一個緩衝中 注3,並且當讀取完成後調用一個回調。換句話說, uv_fs_read() 總是立即返回,即使是文件在一個類似 NFS 的系統上,而數據到達緩衝區可能需要一些時間。換句話說,這個 API 與這種方式中其它的 libuv API 是非同步的。這是怎麼工作的呢?
在這一點上,我們看一下 libuv 的底層;內部實際上非常簡單,並且它是一個很好的練習。作為一個可移植的庫,libuv 對於 Windows 和 Unix 系統在它的許多函數上有不同的實現。我們去看一下在 libuv 源樹中的 src/unix/fs.c。
這是 uv_fs_read 的代碼:
int uv_fs_read(uv_loop_t* loop, uv_fs_t* req,
uv_file file,
const uv_buf_t bufs[],
unsigned int nbufs,
int64_t off,
uv_fs_cb cb) {
if (bufs == NULL || nbufs == 0)
return -EINVAL;
INIT(READ);
req->file = file;
req->nbufs = nbufs;
req->bufs = req->bufsml;
if (nbufs > ARRAY_SIZE(req->bufsml))
req->bufs = uv__malloc(nbufs * sizeof(*bufs));
if (req->bufs == NULL) {
if (cb != NULL)
uv__req_unregister(loop, req);
return -ENOMEM;
}
memcpy(req->bufs, bufs, nbufs * sizeof(*bufs));
req->off = off;
POST;
}
第一次看可能覺得很困難,因為它延緩真實的工作到 INIT 和 POST 宏中,以及為 POST 設置了一些本地變數。這樣做可以避免了文件中的許多重複代碼。
這是 INIT 宏:
#define INIT(subtype)
do {
req->type = UV_FS;
if (cb != NULL)
uv__req_init(loop, req, UV_FS);
req->fs_type = UV_FS_ ## subtype;
req->result = 0;
req->ptr = NULL;
req->loop = loop;
req->path = NULL;
req->new_path = NULL;
req->cb = cb;
}
while (0)
它設置了請求,並且更重要的是,設置 req->fs_type 域為真實的 FS 請求類型。因為 uv_fs_read 調用 INIT(READ),它意味著 req->fs_type 被分配一個常數 UV_FS_READ。
這是 POST 宏:
#define POST
do {
if (cb != NULL) {
uv__work_submit(loop, &req->work_req, uv__fs_work, uv__fs_done);
return 0;
}
else {
uv__fs_work(&req->work_req);
return req->result;
}
}
while (0)
它做什麼取決於回調是否為 NULL。在 libuv 文件系統 API 中,一個 NULL 回調意味著我們真實地希望去執行一個 同步 操作。在這種情況下,POST 直接調用 uv__fs_work(我們需要了解一下這個函數的功能),而對於一個非 NULL 回調,它把 uv__fs_work 作為一個工作項提交到工作隊列(指的是線程池),然後,註冊 uv__fs_done 作為回調;該函數執行一些登記並調用用戶提供的回調。
如果我們去看 uv__fs_work 的代碼,我們將看到它使用很多宏按照需求將工作分發到實際的文件系統調用。在我們的案例中,對於 UV_FS_READ 這個調用將被 uv__fs_read 生成,它(最終)使用普通的 POSIX API 去讀取。這個函數可以在一個 阻塞 方式中很安全地實現。因為,它通過非同步 API 調用時被置於一個線程池中。
在 Node.js 中,fs.readFile 函數是映射到 uv_fs_read 上。因此,可以在一個非阻塞模式中讀取文件,甚至是當底層文件系統 API 是阻塞方式時。
- 注1: 為確保伺服器不泄露內存,我在一個啟用泄露檢查的 Valgrind 中運行它。因為伺服器經常是被設計為永久運行,這是一個挑戰;為克服這個問題,我在伺服器上添加了一個 「kill 開關」 —— 一個從客戶端接收的特定序列,以使它可以停止事件循環並退出。這個代碼在
theon_wrote_buf句柄中。 - 注2: 在這裡我們不過多地使用
work_req;討論的素數測試伺服器接下來將展示怎麼被用於去傳遞上下文信息到回調中。 - 注3:
uv_fs_read()提供了一個類似於preadvLinux 系統調用的通用 API:它使用多緩衝區用於排序,並且支持一個到文件中的偏移。基於我們討論的目的可以忽略這些特性。
via: https://eli.thegreenplace.net/2017/concurrent-servers-part-4-libuv/
作者:Eli Bendersky 譯者:qhwdw 校對:wxy
本文轉載來自 Linux 中國: https://github.com/Linux-CN/archive
對這篇文章感覺如何?
You may also like






More in:Linux中國

捐贈 Let's Encrypt,共建安全的互聯網

Let's Encrypt 正式發布,已經保護 380 萬個域名

關於Linux防火牆iptables的面試問答

Lets Encrypt 已被所有主流瀏覽器所信任









