用數據科學搭建一個實時推薦引擎
我在 Neo4j 任職已經兩年了,但實際上我已經使用 Neo4j 和 Cypher 工作三年了。當我首次發現這個特別的 圖資料庫 的時候,我還是一個研究生,那時候我在奧斯丁的德克薩斯大學攻讀關於社交網路的統計學碩士學位。
實時推薦引擎是 Neo4j 中最廣泛的用途之一,也是使它如此強大並且容易使用的原因之一。為了探索這個東西,我將通過使用示例數據集來闡述如何將統計學方法併入這些引擎中。
第一個很簡單 - 將 Cypher 用於社交推薦。接下來,我們將看一看相似性推薦,這涉及到可被計算的相似性度量,最後探索的是集群推薦。
圖資料庫推薦基礎
下面的數據集包含所有達拉斯 Fort Worth 國際機場的餐飲場所,達拉斯 Fort Worth 國際機場是美國主要的機場樞紐之一:
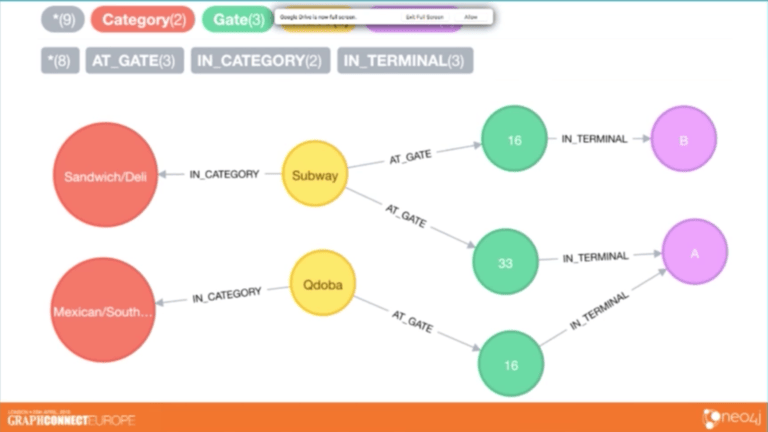
我們把節點標記成黃色並按照出入口和航站樓給它們的位置建模。同時我們也按照食物和飲料的主類別將地點分類,其中一些包括墨西哥食物、三明治、酒吧和烤肉。
讓我們做一個簡單的推薦。我們想要在機場的某一確定地點找到一種特定食物,大括弧中的內容表示是的用戶輸入,它將進入我們的假想應用程序中。

這個英文句子表示成 Cypher 查詢:

這將提取出該類別中用戶所請求的所有地點、航站樓和出入口。然後我們可以計算出用戶所在位置到出入口的準確距離,並以升序返回結果。再次說明,這個非常簡單的 Cypher 推薦僅僅依據的是用戶在機場中的位置。
社交推薦
讓我們來看一下社交推薦。在我們的假想應用程序中,用戶可以登錄並且可以用和 Facebook 類似的方式標記自己「喜好」的地點,也可以在某地簽到。
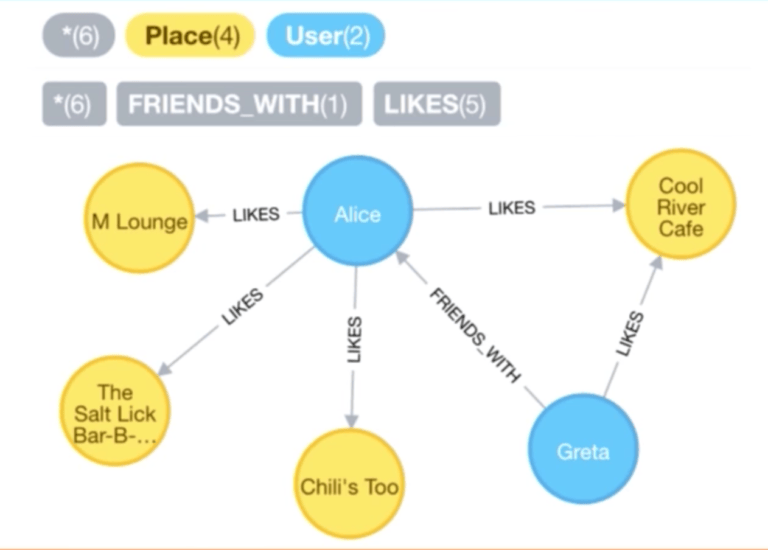
考慮位於我們所研究的第一個模型之上的數據模型,現在讓我們在下面的分類中找到用戶的朋友喜好的航站樓裡面離出入口最近的餐飲場所:

MATCH 子句和我們第一次 Cypher 查詢的 MATCH 子句相似,只是現在我們依據喜好和朋友來匹配:

前三行是完全一樣的,但是現在要考慮的是那些登錄的用戶,我們想要通過 :FRIENDS_WITH 這一關係來找到他們的朋友。僅需通過在 Cypher 中增加一些行內容,我們現在已經把社交層面考慮到了我們的推薦引擎中。
再次說明,我們僅僅顯示了用戶明確請求的類別,並且這些類別中的地點與用戶進入的地方是相同的航站樓。當然,我們希望按照登錄並做出請求的用戶來濾過這些目錄,然後返回地點的名字、位置以及所在目錄。我們也要顯示出有多少朋友已經「喜好」那個地點以及那個地點到出入口的確切距離,然後在 RETURN 子句中同時返回所有這些內容。
相似性推薦
現在,讓我們看一看相似性推薦引擎:
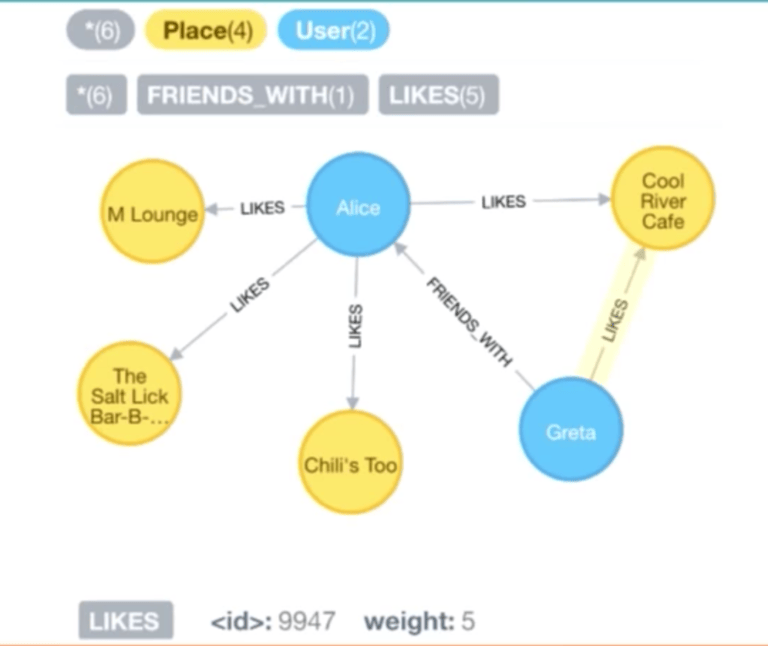
和前面的數據模型相似,用戶可以標記「喜好」的地點,但是這一次他們可以用 1 到 10 的整數給地點評分。這是通過前期在 Neo4j 中增加一些屬性到關係中建模實現的。
這將允許我們找到其他相似的用戶,比如以上面的 Greta 和 Alice 為例,我們已經查詢了他們共同喜好的地點,並且對於每一個地點,我們可以看到他們所設定的權重。大概地,我們可以通過他們的評分來確定他們之間的相似性大小。
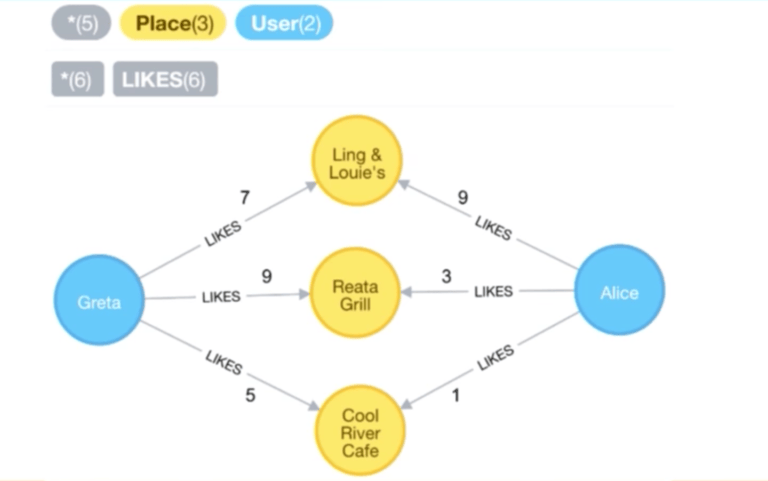
現在我們有兩個向量:

現在讓我們按照 歐幾里得距離 的定義來計算這兩個向量之間的距離:
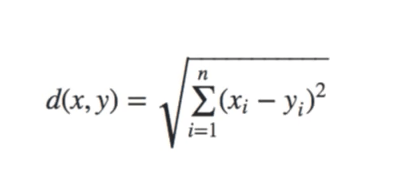
我們把所有的數字帶入公式中計算,然後得到下面的相似度,這就是兩個用戶之間的「距離」:
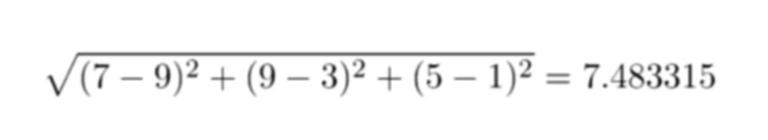
你可以很容易地在 Cypher 中計算兩個特定用戶的「距離」,特別是如果他們僅僅同時「喜好」一個很小的地點子集。再次說明,這兒我們依據兩個用戶 Alice 和 Greta 來進行匹配,並嘗試去找到他們同時「喜好」的地點:

他們都有對最後找到的地點的 :LIKES 關係,然後我們可以在 Cypher 中很容易的計算出他們之間的歐幾里得距離,計算方法為他們對各個地點評分差的平方求和再開平方根。
在兩個特定用戶的例子中上面這個方法或許能夠工作。但是,在實時情況下,當你想要通過和實時資料庫中的其他用戶比較,從而由一架飛機上的一個用戶推斷相似用戶時,這個方法就不一定能夠工作。不用說,至少它不能夠很好的工作。
為了找到解決這個問題的好方法,我們可以預先計算好距離並存入實際關係中:

當遇到一個很大的數據集時,我們需要成批處理這件事,在這個很小的示例數據集中,我們可以按照所有用戶的 迪卡爾乘積 和他們共同「喜好」的地點來進行匹配。當我們使用 WHERE id(u1) < id(u2) 作為 Cypher 詢問的一部分時,它只是來確定我們在左邊和右邊沒有找到相同的對的一個技巧。
通過用戶之間的歐幾里得距離,我們創建了他們之間的一種關係,叫做 :DISTANCE,並且設置了一個叫做 euclidean 的歐幾里得屬性。理論上,我們可以也通過用戶間的一些關係來存儲其他相似度從而獲取不同的相似度,因為在確定的環境下某些相似度可能比其他相似度更有用。
在 Neo4j 中,的確是對關係屬性建模的能力使得完成像這樣的事情無比簡單。然而,實際上,你不會希望存儲每一個可能存在的單一關係,因為你僅僅希望返回離他們「最近」的一些人。
因此你可以根據一些臨界值來存入前幾個,從而你不需要構建完整的連通圖。這允許你完成一些像下面這樣的實時的資料庫查詢,因為我們已經預先計算好了「距離」並存儲在了關係中,在 Cypher 中,我們能夠很快的攫取出數據。

在這個查詢中,我們依據地點和類別來進行匹配:
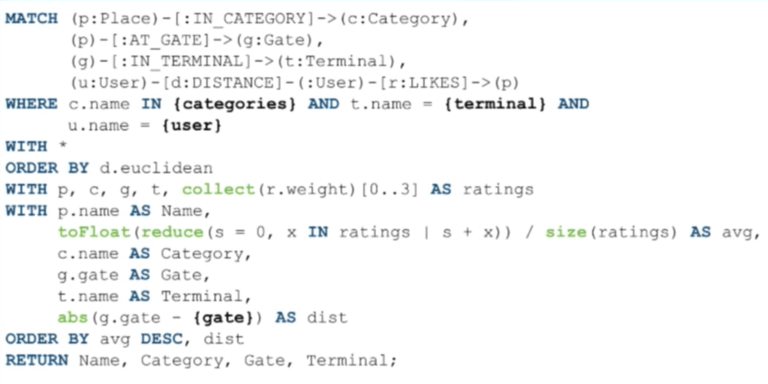
再次說明,前三行是相同的,除了登錄用戶以外,我們找出了和他們有 :DISTANCE 關係的用戶。這是我們前面查看的關係產生的作用 - 實際上,你只需要存儲處於前幾位的相似用戶 :DISTANCE 關係,因此你不需要在 MATCH 子句中攫取大量用戶。相反,我們只攫取和那些用戶「喜好」的地方有 :DISTANCE 關係的用戶。
這允許我們用少許幾行內容表達較為複雜的模型。我們也可以攫取 :LIKES 關係並把它放入到變數中,因為後面我們將使用這些權重來評分。
在這兒重要的是,我們可以依據「距離」大小將用戶按照升序進行排序,因為這是一個距離測度。同時,我們想要找到用戶間的最小距離因為距離越小表明他們的相似度最大。
通過其他按照歐幾里得距離大小排序好的用戶,我們得到用戶評分最高的三個地點並按照用戶的平均評分高低來推薦這些地點。換句話說,我們先找出一個活躍用戶,然後依據其他用戶「喜好」的地點找出和他最相似的其他用戶,接下來按照這些相似用戶的平均評分把那些地點排序在結果的集合中。
本質上,我們通過把所有評分相加然後除以收集的用戶數目來計算出平均分,然後按照平均評分的升序進行排序。其次,我們按照出入口距離排序。假想地,我猜測應該會有交接點,因此你可以按照出入口距離排序然後再返回名字、類別、出入口和航站樓。
集群推薦
我們最後要講的一個例子是集群推薦,在 Cypher 中,這可以被想像成一個作為臨時解決方案的離線計算工作流。這可能完全基於在歐洲 GraphConnect 上宣布的新方法,但是有時你必須進行一些 Cypher 2.3 版本所沒有的演算法逼近。
在這兒你可以使用一些統計軟體,把數據從 Neo4j 取出然後放入像 Apache Spark、R 或者 Python 這樣的軟體中。下面是一段把數據從 Neo4j 中取出的 R 代碼,運行該程序,如果正確,寫下程序返回結果的給 Neo4j,可以是一個屬性、節點、關係或者一個新的標籤。
通過持續把程序運行結果放入到圖表中,你可以在一個和我們剛剛看到的查詢相似的實時查詢中使用它:

下面是用 R 來完成這件事的一些示例代碼,但是你可以使用任何你最喜歡的軟體來做這件事,比如 Python 或 Spark。你需要做的只是登錄並連接到圖表。
在下面的例子中,我基於用戶的相似性把他們聚合起來。每個用戶作為一個觀察點,然後得到他們對每一個目錄評分的平均值。

假定用戶對酒吧類評分的方式和一般的評分方式相似。然後我攫取出喜歡相同類別中的地點的用戶名、類別名、「喜好」關係的平均權重,比如平均權重這些信息,從而我可以得到下面這樣一個表格:
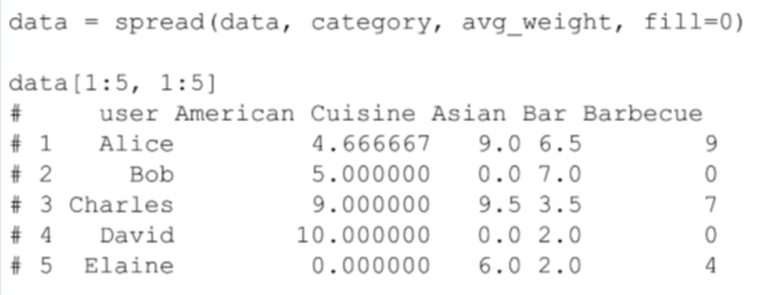
因為我們把每一個用戶都作為一個觀察點,所以我們必須巧妙的處理每一個類別中的數據,這些數據的每一個特性都是用戶對該類中餐廳評分的平均權重。接下來,我們將使用這些數據來確定用戶的相似性,然後我將使用 聚類 演算法來確定在不同集群中的用戶。
在 R 中這很直接:

在這個示例中我們使用 K-均值 聚類演算法,這將使你很容易攫取集群分配。總之,我通過運行聚類演算法然後分別得到每一個用戶的集群分配。
Bob 和 David 在一個相同的集群中 - 他們在集群二中 - 現在我可以實時查看哪些用戶被放在了相同的集群中。
接下來我把集群分配寫入 CSV 文件中,然後存入圖資料庫:

我們只有用戶和集群分配,因此 CSV 文件只有兩列。 LOAD CSV 是 Cypher 中的內建語法,它允許你從一些其他文件路徑或者 URL 調用 CSV ,並給它一個別名。接下來,我們將匹配圖資料庫中存在的用戶,從 CSV 文件中攫取用戶列然後合併到集群中。
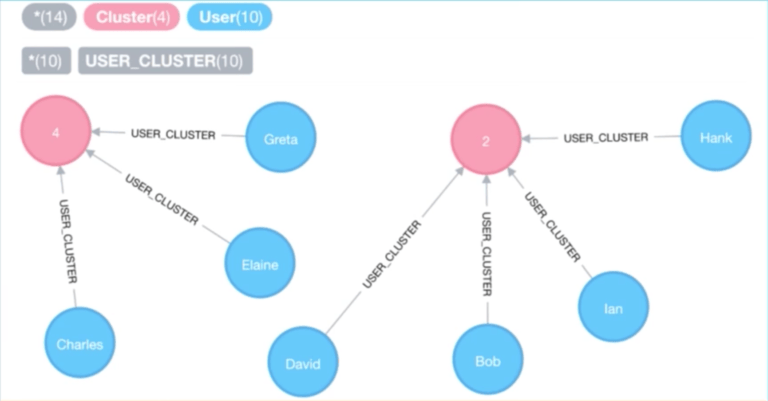
我們在圖表中創建了一個新的標籤節點:Cluster ID, 這是由 K-平均聚類演算法給出的。接下來我們創建用戶和集群間的關係,通過創建這個關係,當我們想要找到在相同集群中的實際推薦用戶時,就會很容易進行查詢。
我們現在有了一個新的集群標籤,在相同集群中的用戶和那個集群存在關係。新的數據模型看起來像下面這樣,它比我們前面探索的其他數據模型要更好:
現在讓我們考慮下面的查詢:

通過這個 Cypher 查詢,我們在更遠處找到了在同一個集群中的相似用戶。由於這個原因,我們刪除了「距離」關係:
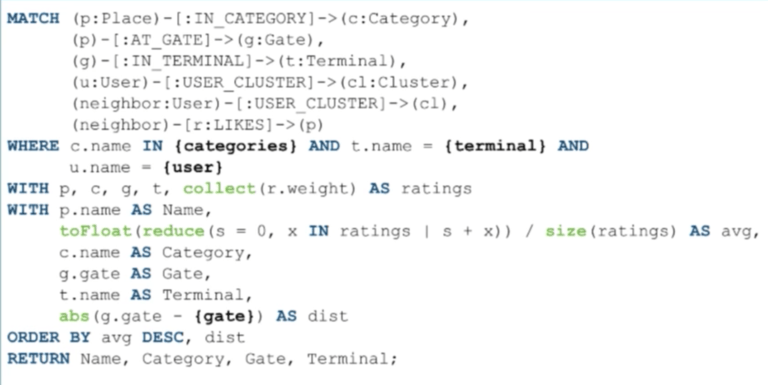
在這個查詢中,我們取出已經登錄的用戶,根據用戶-集群關係找到他們所在的集群,找到他們附近和他們在相同集群中的用戶。
我們把這些用戶分配到變數 c1 中,然後我們得到其他被我取別名為 neighbor 變數的用戶,這些用戶和那個相同集群存在著用戶-集群關係,最後我們得到這些附近用戶「喜好」的地點。再次說明,我把「喜好」放入了變數 r 中,因為我們需要從關係中攫取權重來對結果進行排序。
在這個查詢中,我們所做的改變是,不使用相似性距離,而是攫取在相同集群中的用戶,然後對類別、航站樓以及我們所攫取的登錄用戶進行聲明。我們收集所有的權重:來自附近用戶「喜好」地點的「喜好」關係,得到的類別,確定的距離值,然後把它們按升序進行排序並返回結果。
在這些例子中,我們可以進行一個相當複雜的處理並且將其放到圖資料庫中,然後我們就可以使用實時演算法結果-聚類演算法和集群分配的結果。
我們更喜歡的工作流程是更新這些集群分配,更新頻率適合你自己就可以,比如每晚一次或每小時一次。當然,你可以根據直覺來決定多久更新一次這些集群分配是可接受的。
via: https://neo4j.com/blog/real-time-recommendation-engine-data-science/
作者:Nicole White 譯者:ucasFL 校對:wxy
本文轉載來自 Linux 中國: https://github.com/Linux-CN/archive
對這篇文章感覺如何?
You may also like






More in:Linux中國

捐贈 Let's Encrypt,共建安全的互聯網

Let's Encrypt 正式發布,已經保護 380 萬個域名

關於Linux防火牆iptables的面試問答

Lets Encrypt 已被所有主流瀏覽器所信任









