大數據探索:在樹莓派上通過 Apache Spark on YARN 搭建 Hadoop 集群

有些時候我們想從 DQYDJ 網站的數據中分析點有用的東西出來,在過去,我們要用 R 語言提取固定寬度的數據,然後通過數學建模來分析美國的最低收入補貼,當然也包括其他優秀的方法。
今天我將向你展示對大數據的一點探索,不過有點變化,使用的是全世界最流行的微型電腦————樹莓派,如果手頭沒有,那就看下一篇吧(可能是已經處理好的數據),對於其他用戶,請繼續閱讀吧,今天我們要建立一個樹莓派 Hadoop集群!
I. 為什麼要建立一個樹莓派的 Hadoop 集群?

由三個樹莓派節點組成的 Hadoop 集群
我們對 DQYDJ 的數據做了大量的處理工作,但這些還不能稱得上是大數據。
和許許多多有爭議的話題一樣,數據的大小之別被解釋成這樣一個笑話:
如果能被內存所存儲,那麼它就不是大數據。 ————佚名
似乎這兒有兩種解決問題的方法:
- 我們可以找到一個足夠大的數據集合,任何家用電腦的物理或虛擬內存都存不下。
- 我們可以買一些不用特別定製,我們現有數據就能淹沒它的電腦:
—— 上手樹莓派 2B
這個由設計師和工程師製作出來的精緻小玩意兒擁有 1GB 的內存, MicroSD 卡充當它的硬碟,此外,每一台的價格都低於 50 美元,這意味著你可以花不到 250 美元的價格搭建一個 Hadoop 集群。
或許天下沒有比這更便宜的入場券來帶你進入大數據的大門。
II. 製作一個樹莓派集群
我最喜歡製作的原材料。
這裡我將給出我原來為了製作樹莓派集群購買原材料的鏈接,如果以後要在亞馬遜購買的話你可先這些鏈接收藏起來,也是對本站的一點支持。(謝謝)
- 樹莓派 2B 3 塊
- 4 層亞克力支架
- 6 口 USB 轉接器,我選了白色 RAVPower 50W 10A 6 口 USB 轉接器
- MicroSD 卡,這個五件套 32GB 卡非常棒
- 短的 MicroUSB 數據線,用於給樹莓派供電
- 短網線
- 雙面膠,我有一些 3M 的,很好用
開始製作
- 首先,裝好三個樹莓派,每一個用螺絲釘固定在亞克力面板上。(看下圖)
- 接下來,安裝乙太網交換機,用雙面膠貼在其中一個在亞克力面板上。
- 用雙面膠貼將 USB 轉接器貼在一個在亞克力面板使之成為最頂層。
- 接著就是一層一層都拼好——這裡我選擇將樹莓派放在交換機和USB轉接器的底下(可以看看完整安裝好的兩張截圖)
想辦法把線路放在需要的地方——如果你和我一樣購買力 USB 線和網線,我可以將它們捲起來放在亞克力板子的每一層
現在不要急著上電,需要將系統燒錄到 SD 卡上才能繼續。
燒錄 Raspbian
按照這個教程將 Raspbian 燒錄到三張 SD 卡上,我使用的是 Win7 下的 Win32DiskImager。
將其中一張燒錄好的 SD 卡插在你想作為主節點的樹莓派上,連接 USB 線並啟動它。
啟動主節點
這裡有一篇非常棒的「Because We Can Geek」的教程,講如何安裝 Hadoop 2.7.1,此處就不再熬述。
在啟動過程中有一些要注意的地方,我將帶著你一起設置直到最後一步,記住我現在使用的 IP 段為 192.168.1.50 – 192.168.1.52,主節點是 .50,從節點是 .51 和 .52,你的網路可能會有所不同,如果你想設置靜態 IP 的話可以在評論區看看或討論。
一旦你完成了這些步驟,接下來要做的就是啟用交換文件,Spark on YARN 將分割出一塊非常接近內存大小的交換文件,當你內存快用完時便會使用這個交換分區。
(如果你以前沒有做過有關交換分區的操作的話,可以看看這篇教程,讓 swappiness 保持較低水準,因為 MicroSD 卡的性能扛不住)
現在我準備介紹有關我的和「Because We Can Geek」關於啟動設置一些微妙的區別。
對於初學者,確保你給你的樹莓派起了一個正式的名字——在 /etc/hostname 設置,我的主節點設置為 『RaspberryPiHadoopMaster』 ,從節點設置為 『RaspberryPiHadoopSlave#』
主節點的 /etc/hosts 配置如下:
#/etc/hosts
127.0.0.1 localhost
::1 localhost ip6-localhost ip6-loopback
ff02::1 ip6-allnodes
ff02::2 ip6-allrouters
192.168.1.50 RaspberryPiHadoopMaster
192.168.1.51 RaspberryPiHadoopSlave1
192.168.1.52 RaspberryPiHadoopSlave2
如果你想讓 Hadoop、YARN 和 Spark 運行正常的話,你也需要修改這些配置文件(不妨現在就編輯)。
這是 hdfs-site.xml:
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<property>
<name>fs.default.name</name>
<value>hdfs://RaspberryPiHadoopMaster:54310</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/hdfs/tmp</value>
</property>
</configuration>
這是 yarn-site.xml (注意內存方面的改變):
<?xml version="1.0"?>
<configuration>
<!-- Site specific YARN configuration properties -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.resource.cpu-vcores</name>
<value>4</value>
</property>
<property>
<name>yarn.nodemanager.resource.memory-mb</name>
<value>1024</value>
</property>
<property>
<name>yarn.scheduler.minimum-allocation-mb</name>
<value>128</value>
</property>
<property>
<name>yarn.scheduler.maximum-allocation-mb</name>
<value>1024</value>
</property>
<property>
<name>yarn.scheduler.minimum-allocation-vcores</name>
<value>1</value>
</property>
<property>
<name>yarn.scheduler.maximum-allocation-vcores</name>
<value>4</value>
</property>
<property>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
<description>Whether virtual memory limits will be enforced for containers</description>
</property>
<property>
<name>yarn.nodemanager.vmem-pmem-ratio</name>
<value>4</value>
<description>Ratio between virtual memory to physical memory when setting memory limits for containers</description>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>RaspberryPiHadoopMaster:8025</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>RaspberryPiHadoopMaster:8030</value>
</property>
<property>
<name>yarn.resourcemanager.address</name>
<value>RaspberryPiHadoopMaster:8040</value>
</property>
</configuration>
slaves:
RaspberryPiHadoopMaster
RaspberryPiHadoopSlave1
RaspberryPiHadoopSlave2
core-site.xml:
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<property>
<name>fs.default.name</name>
<value>hdfs://RaspberryPiHadoopMaster:54310</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/hdfs/tmp</value>
</property>
</configuration>
設置兩個從節點:
接下來按照 「Because We Can Geek」上的教程,你需要對上面的文件作出小小的改動。 在 yarn-site.xml 中主節點沒有改變,所以從節點中不必含有這個 slaves 文件。
III. 在我們的樹莓派集群中測試 YARN
如果所有設備都正常工作,在主節點上你應該執行如下命令:
start-dfs.sh
start-yarn.sh
當設備啟動後,以 Hadoop 用戶執行,如果你遵循教程,用戶應該是 hduser。
接下來執行 hdfs dfsadmin -report 查看三個節點是否都正確啟動,確認你看到一行粗體文字 『Live datanodes (3)』:
Configured Capacity: 93855559680 (87.41 GB)
Raspberry Pi Hadoop Cluster picture Straight On
Present Capacity: 65321992192 (60.84 GB)
DFS Remaining: 62206627840 (57.93 GB)
DFS Used: 3115364352 (2.90 GB)
DFS Used%: 4.77%
Under replicated blocks: 0
Blocks with corrupt replicas: 0
Missing blocks: 0
Missing blocks (with replication factor 1): 0
————————————————-
Live datanodes (3):
Name: 192.168.1.51:50010 (RaspberryPiHadoopSlave1)
Hostname: RaspberryPiHadoopSlave1
Decommission Status : Normal
你現在可以做一些簡單的諸如 『Hello, World!』 的測試,或者直接進行下一步。
IV. 安裝 SPARK ON YARN
YARN 的意思是另一種非常好用的資源調度器(Yet Another Resource Negotiator),已經作為一個易用的資源管理器集成在 Hadoop 基礎安裝包中。
Apache Spark 是 Hadoop 生態圈中的另一款軟體包,它是一個毀譽參半的執行引擎和捆綁的 MapReduce。在一般情況下,相對於基於磁碟存儲的 MapReduce,Spark 更適合基於內存的存儲,某些運行任務能夠得到 10-100 倍提升——安裝完成集群後你可以試試 Spark 和 MapReduce 有什麼不同。
我個人對 Spark 還是留下非常深刻的印象,因為它提供了兩種數據工程師和科學家都比較擅長的語言—— Python 和 R。
安裝 Apache Spark 非常簡單,在你家目錄下,wget "為 Hadoop 2.7 構建的 Apache Spark」(來自這個頁面),然後運行 tar -xzf 「tgz 文件」,最後把解壓出來的文件移動至 /opt,並清除剛才下載的文件,以上這些就是安裝步驟。
我又創建了只有兩行的文件 spark-env.sh,其中包含 Spark 的配置文件目錄。
SPARK_MASTER_IP=192.168.1.50
SPARK_WORKER_MEMORY=512m
(在 YARN 跑起來之前我不確定這些是否有必要。)
V. 你好,世界! 為 Apache Spark 尋找有趣的數據集!
在 Hadoop 世界裡面的 『Hello, World!』 就是做單詞計數。
我決定讓我們的作品做一些內省式……為什麼不統計本站最常用的單詞呢?也許統計一些關於本站的大數據會更有用。
如果你有一個正在運行的 WordPress 博客,可以通過簡單的兩步來導出和凈化。
- 我使用 Export to Text 插件導出文章的內容到純文本文件中
- 我使用一些壓縮庫編寫了一個 Python 腳本來剔除 HTML
import bleach
# Change this next line to your 'import' filename, whatever you would like to strip
# HTML tags from.
ascii_string = open('dqydj_with_tags.txt', 'r').read()
new_string = bleach.clean(ascii_string, tags=[], attributes={}, styles=[], strip=True)
new_string = new_string.encode('utf-8').strip()
# Change this next line to your 'export' filename
f = open('dqydj_stripped.txt', 'w')
f.write(new_string)
f.close()
現在我們有了一個更小的、適合複製到樹莓派所搭建的 HDFS 集群上的文件。
如果你不能樹莓派主節點上完成上面的操作,找個辦法將它傳輸上去(scp、 rsync 等等),然後用下列命令行複製到 HDFS 上。
hdfs dfs -copyFromLocal dqydj_stripped.txt /dqydj_stripped.txt
現在準備進行最後一步 - 向 Apache Spark 寫入一些代碼。
VI. 點亮 Apache Spark
Cloudera 有個極棒的程序可以作為我們的超級單詞計數程序的基礎,你可以在這裡找到。我們接下來為我們的內省式單詞計數程序修改它。
在主節點上安裝『stop-words』這個 python 第三方包,雖然有趣(我在 DQYDJ 上使用了 23,295 次 the 這個單詞),你可能不想看到這些語法單詞佔據著單詞計數的前列,另外,在下列代碼用你自己的數據集替換所有有關指向 dqydj 文件的地方。
import sys
from stop_words import get_stop_words
from pyspark import SparkContext, SparkConf
if __name__ == "__main__":
# create Spark context with Spark configuration
conf = SparkConf().setAppName("Spark Count")
sc = SparkContext(conf=conf)
# get threshold
try:
threshold = int(sys.argv[2])
except:
threshold = 5
# read in text file and split each document into words
tokenized = sc.textFile(sys.argv[1]).flatMap(lambda line: line.split(" "))
# count the occurrence of each word
wordCounts = tokenized.map(lambda word: (word.lower().strip(), 1)).reduceByKey(lambda v1,v2:v1 +v2)
# filter out words with fewer than threshold occurrences
filtered = wordCounts.filter(lambda pair:pair[1] >= threshold)
print "*" * 80
print "Printing top words used"
print "-" * 80
filtered_sorted = sorted(filtered.collect(), key=lambda x: x[1], reverse = True)
for (word, count) in filtered_sorted: print "%s : %d" % (word.encode('utf-8').strip(), count)
# Remove stop words
print "nn"
print "*" * 80
print "Printing top non-stop words used"
print "-" * 80
# Change this to your language code (see the stop-words documentation)
stop_words = set(get_stop_words('en'))
no_stop_words = filter(lambda x: x[0] not in stop_words, filtered_sorted)
for (word, count) in no_stop_words: print "%s : %d" % (word.encode('utf-8').strip(), count)
保存好 wordCount.py,確保上面的路徑都是正確無誤的。
現在,準備念出咒語,讓運行在 YARN 上的 Spark 跑起來,你可以看到我在 DQYDJ 使用最多的單詞是哪一個。
/opt/spark-2.0.0-bin-hadoop2.7/bin/spark-submit –master yarn –executor-memory 512m –name wordcount –executor-cores 8 wordCount.py /dqydj_stripped.txt
VII. 我在 DQYDJ 使用最多的單詞
可能入列的單詞有哪一些呢?「can, will, it』s, one, even, like, people, money, don』t, also「.
嘿,不錯,「money」悄悄擠進了前十。在一個致力於金融、投資和經濟的網站上談論這似乎是件好事,對吧?
下面是的前 50 個最常用的辭彙,請用它們刻畫出有關我的文章的水平的結論。
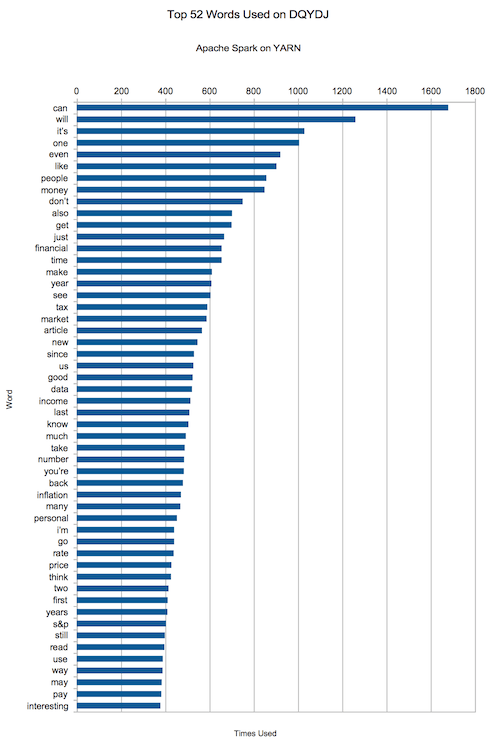
我希望你能喜歡這篇關於 Hadoop、YARN 和 Apache Spark 的教程,現在你可以在 Spark 運行和編寫其他的應用了。
你的下一步是任務是開始閱讀 pyspark 文檔(以及用於其他語言的該庫),去學習一些可用的功能。根據你的興趣和你實際存儲的數據,你將會深入學習到更多——有流數據、SQL,甚至機器學習的軟體包!
你怎麼看?你要建立一個樹莓派 Hadoop 集群嗎?想要在其中挖掘一些什麼嗎?你在上面看到最令你驚奇的單詞是什麼?為什麼 'S&P' 也能上榜?
(題圖:Pixabay,CC0)
via: https://dqydj.com/raspberry-pi-hadoop-cluster-apache-spark-yarn/
本文轉載來自 Linux 中國: https://github.com/Linux-CN/archive
對這篇文章感覺如何?
You may also like






More in:Linux中國

捐贈 Let's Encrypt,共建安全的互聯網

Let's Encrypt 正式發布,已經保護 380 萬個域名

關於Linux防火牆iptables的面試問答

Lets Encrypt 已被所有主流瀏覽器所信任









