人工智慧教程(七):Scikit-learn 和訓練第一個模型

在本系列的 上一篇文章 中,我們用 TensorFlow 構建了第一個神經網路,然後還通過 Keras 接觸了第一個數據集。在本系列的第七篇文章中,我們將繼續探索神經網路,並使用數據集來訓練模型。我們還將介紹另一個強大的機器學習 Python 庫 scikit-learn。不過在進入正題之前,我要介紹兩個轟動性的人工智慧應用:ChatGPT 和 DALL-E 2。(LCTT 譯註:此文原文發表於 2023 年初,恰值以 ChatGPT 為代表的 AI 熱潮開始掀起。)
OpenAI 是一個人工智慧研究實驗室,它在人工智慧和機器學習領域做了很多研究。 埃隆·馬斯克 是該組織的聯合創始人之一。2022 年 11 月,該實驗室推出了一款名為 ChatGPT 的在線工具。它是一個可以像人類一樣聊天的人工智慧聊天機器人。它是使用監督學習和強化學習技術訓練的 大型語言模型 (LLM)。ChatGPT 使用了 OpenAI 的 GPT-3.5 語言模型,這是 GPT-3( 生成式預訓練變換器 )的改進版本,GPT-3 是一種使用深度學習來生成類似人類文本的語言模型。(LCTT 譯註:OpenAI 已於 2023 年 3 月 14 日 發布了 GPT-4.0,它支持圖文混合的輸入輸出,並大幅提升了推理能力和準確性。)我仍然記得第一次使用 ChatGPT 時的興奮。它清楚地展現了人工智慧的能力。ChatGPT 的回答質量很高,通常與人類給出的答案沒有區別。你可以使用它來糾正語法錯誤、改寫句子、總結段落、編寫程序等。實際上,我就用 ChatGPT 改寫了本文中的許多句子。此外,我還故意使用有語法錯誤的文本測試了 ChatGPT,它糾正後的句子非常準確。它重新措辭和總結段落的能力也很驚人。
程序員甚至有可能使用 ChatGPT 在短時間內解決編程難題。在 編程探險挑戰賽 2022 中,就有人這樣宣稱(LCTT 譯註:比賽官方只是沒有完全禁止使用人工智慧作為輔助,但是並不很推崇這樣的作法。消息來源)。事實上在 2022 年 12 月,也就是 ChatGPT 發布的一個月後,Stack Overflow 發布了一條新的規定,禁止提交 GPT 或 ChatGPT 生成答案。(LCTT 譯註:消息來源:Temporary policy Generative AI (e.g., ChatGPT) is banned - Meta Stack Overflow)
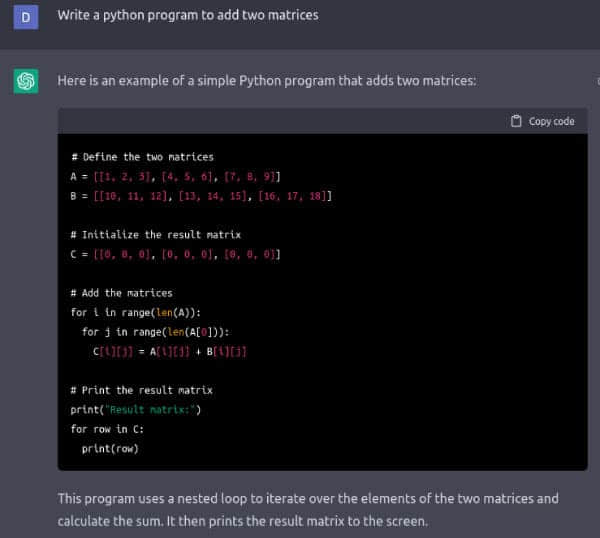
圖 1 顯示了 ChatGPT 編寫的將兩個矩陣相加的 Python 程序。我要求用 BASIC、FORTRAN、Pascal、Haskell、Lua、Pawn、C、c++、Java 等語言編寫程序,ChatGPT 總能給出答案,甚至對於像 Brainfuck 和 Ook! 這樣生僻的編程語言也是如此。我很確定 ChatGPT 沒有從互聯網上複製程序代碼。更確切地說,我認為 ChatGPT 是基於對上述編程語言的語法知識生成了這些答案的,這些知識是從訓練它的大量數據中獲得的。許多專家和觀察人士認為,隨著 ChatGPT 的發展,人工智慧已經成為主流。ChatGPT 的真正力量將在未來幾個月或幾年裡被看到。
OpenAI 的另一個令人驚嘆的在線人工智慧工具是 DALL-E 2,它以卡通機器人 WALL-E(LCTT 譯註:電源《機器人總動員》中的主角)和著名畫家/藝術家 薩爾瓦多·達利 的名字命名。DALL-E 2 是一個可以根據英文描述來生成繪畫的人工智慧系統。該工具支持豐富的圖像風格,如油畫、卡通、漫畫、現實主義、超現實主義、壁畫等。它還可以模仿著名畫家的風格,如達利、畢加索、梵高等。由 DALL-E 2 生成的圖像質量非常高。我用下面的描述測試了這個工具:「一個快樂的人在海灘旁看日出的立體主義畫作」。圖 2 是 DALL-E 2 根據我的描述生成的圖像之一。立體主義是畢加索推廣的一種繪畫風格。問問你的任何一個畫家朋友,他/她都會說這確實是一幅立體主義風格的畫。令人驚訝的是軟體——它也許很複雜——能夠模仿像畢加索、梵高、達利這樣的大師。我強烈建議你體驗一下它。這種體驗將非常有趣,同時也體現了人工智慧的威力。但請記住,像 ChatGPT 和 DALL-E 2 這樣的工具也會帶來很多問題,比如版權侵犯、學生的作業抄襲等。(LCTT 譯註:本文的題圖就是 DALL-E 3 生成的。)

介紹 scikit-learn
scikit-learn 是一個非常強大的機器學習 Python 庫。它是一個採用 新 BSD 許可協議 (LCTT 譯註:即三句版 BSD 許可證) 的自由開源軟體。scikit-learn 提供了回歸、分類、聚類和降維等當面的演算法,如 支持向量機 (SVM)、隨機森林、k-means 聚類等。
在下面關於 scikit-learn 的介紹中,我們將通過代碼討論支持向量機。支持向量機是機器學習中的一個重要的監督學習模型,可以用於分類和回歸分析。支持向量機的發明人 Vladimir Vapnik 和 Alexey Chervonenkis。他們還一起提出了 VC 維 概念,這是一個評估模型分類能力的理論框架。
圖 3 是使用支持向量機對數據進行分類的程序。第 1 行從 scikit-learn 導入 svm 模塊。跟前面幾篇中介紹的 python 庫一樣,scikit-learn 也可以通過 Anaconda Navigator 輕鬆安裝。第 2 行定義了一個名為 X 的列表,其中包含訓練數據。X 中的所有元素都是大小為 3 的列表。第 3 行定義了一個列表 y,其中包含列表 X 中數據的類別標籤。在本例中,數據屬於兩個類別,標籤只有 0 和 1 兩種。但是使用該技術可以對多個類別的數據進行分類。第 4 行使用 svm 模塊的 SVC() 方法生成一個支持向量分類器。第 5 行使用 svm 模塊的 fit() 方法,根據給定的訓練數據(本例中為數組 X 和 y)擬合 svm 分類器模型。最後,第 6 行和第 7 行基於該分類器進行預測。預測的結果也顯示在圖 3 中。可以看到,分類器能夠正確區分我們提供的測試數據。
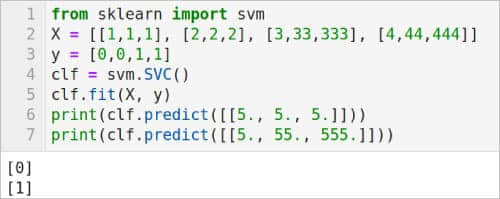
圖 4 中的代碼是一個使用 SVM 進行回歸的例子。第 1 行次從 scikit-learn 導入 svm 模塊。第 2 行定義了一個名為 X 的列表,其中包含訓練數據。注意,X 中的所有元素都是大小為 2 的列表。第 3 行定義了一個列表 y,其中包含與列表 X 中的數據相關的值。第 4 行使用 svm 模塊的 SVR() 方法生成支持向量回歸模型。第 5 行使用 svm 模塊的 fit() 方法,根據給定的訓練數據(本例中為數 X 和 y)擬合 svm 回歸模型。最後,第 6 行根據該 svm 回歸模型進行預測。此預測的結果顯示在圖 4 中。除了 SVR() 之外,還有 LinearSVR() 和 NuSVR() 兩種支持向量回歸模型。將第 4 行替換為 regr = svm.LinearSVR() 和 regr = svm.NuSVR(),並執行代碼來查看這些支持向量回歸模型的效果。

現在讓我們把注意力轉到神經網路和 TensorFlow 上。但在下一篇講無監督學習和聚類時,我們還會學習 scikit-learn 提供的其他方法。
神經網路和 TensorFlow
在上一篇中我們已經看到了 TensorFlow 的 nn 模塊提供的 ReLU ( 整流線性單元 )和 Leaky ReLU 兩個激活函數,下面再介紹兩個其他激活函數。tf.nn.crelu() 是串聯 ReLU 激活函數。tf.nn.elu() 是 指數線性單元 激活函數。我們將在後續用 TensorFlow 和 Keras 訓練我們的第一個模型時用到其中一個激活函數。
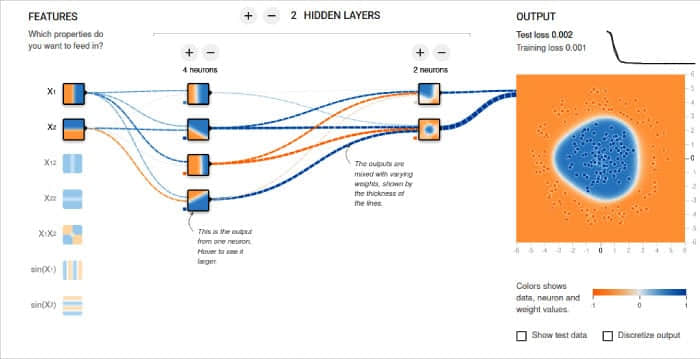
在開始訓練模型之前,我想向你分享 TensorFlow 的提供的「神經網路實驗場」工具。它通過可視化的方式幫助你理解神經網路的工作原理。你可以直觀地向神經網路中添加神經元和隱藏層,然後訓練該模型。你可以選擇 Tanh、Sigmoid、Linear 和 ReLU 等激活函數。分類模型和回歸模型都可以使用該工具進行分析。訓練的效果以動畫的形式顯示。圖 5 顯示了一個示例神經網路和它的輸出。你可以通過 https://playground.tensorflow.org 訪問它。
訓練第一個模型
現在,我們使用 上一篇 提到的 MNIST 手寫數字數據集來訓練模型,然後使用手寫數字圖像對其進行測試。完整的程序 digital.py 相對較大,為了便於理解,我將程序拆分成幾個部分來解釋,並且添加了額外的行號。
import numpy as np
from tensorflow import keras, expand_dims
from tensorflow.keras import layers
num_classes = 10
input_shape = (28, 28, 1)
(x_train, y_train), (x_test, y_test) = keras.datasets.mnist.load_data( )
第 1 行到第 3 行載入必要的包和模塊。第 4 行將類別的數量定義為 10,因為我們試圖對 0 到 9 進行分類。第 5 行將輸入維度定義為 (28,28,1),這表明我們使用是 28 x 28 像素的灰度圖像數據。第 6 行載入該數據集,並將其分為訓練數據和測試數據。關於該數據集的更多信息可以參考 上一篇 的相關介紹。
x_train = x_train.astype("float32") / 255
x_test = x_test.astype("float32") / 255
x_train = np.expand_dims(x_train, 3)
x_test = np.expand_dims(x_test, 3)
y_train = keras.utils.to_categorical(y_train, num_classes)
y_test = keras.utils.to_categorical(y_test, num_classes)
第 7 行和第 8 行將圖像像素值從 [0,255] 轉換到 [0,1]。其中 astype() 方法用於將整數值類型轉換為浮點值。第 9 行和第 10 行將數組 x_test 和 x_train 的維度從 (60000,28,28) 擴展為 (60000,28,28,1)。列表 y_train 和 y_test 包含從 0 到 9 的 10 個數字的標籤。第 11 行和第 12 行將列表 y_train 和 y_test 轉換為二進位類別矩陣。
try:
model = keras.models.load_model(「existing_model」)
except IOError:
model = keras.Sequential(
[
keras.Input(shape=input_shape),
layers.Conv2D(32, kernel_size=(3, 3), activation=」relu」),
layers.MaxPooling2D(pool_size=(2, 2)),
layers.Conv2D(64, kernel_size=(3, 3), activation=」relu」),
layers.MaxPooling2D(pool_size=(2, 2)),
layers.Flatten( ),
layers.Dropout(0.5),
layers.Dense(num_classes, activation=」softmax」),
]
)
batch_size = 64
epochs = 25
model.compile(loss=」categorical_crossentropy」, optimizer=」adam」, metrics=[「accuracy」])
model.fit(x_train, y_train, batch_size=batch_size, epochs=epochs, validation_split=0.1)
model.save(「existing_model」)
訓練模型是一個處理器密集和高內存消耗的操作,我們可不希望每次運行程序時都要重新訓練一遍模型。因此,在第 13 行和第 14 行中,我們先嘗試從 existing_model 目錄載入模型。第一次執行此代碼時,沒有模型存在,因此會引發異常。第 16 到 21 行通過定義、訓練和保存模型來處理這個異常。第 16 行代碼(跨越多行)定義了模型的結構。這一行的參數決定了模型的行為。我們使用的是一個序列模型,它有一系列順序連接的層,每一層都有一個輸入張量和一個輸出張量。我們將在下一篇文章中討論這些定義模型的參數。在此之前,將這個神經網路看作一個黑箱就可以了。
第 17 行將批大小定義為 64,它決定每批計算的樣本數量。第 18 行將 epoch 設置為 25,它決定了整個數據集將被學習演算法處理的次數。第 19 行對模型的訓練行為進行了配置。第 20 行根據給定的數據和參數訓練模型。對這兩行代碼的詳細解釋將推遲到下一篇文章中。最後,第 21 行將訓練好的模型保存到 existing_model 目錄中。模型會以多個 .pb 文件的形式保存在該目錄中。注意,第 16 到 21 行位於 except 塊中。
print(model.summary( ))
score = model.evaluate(x_test, y_test, verbose=0)
print(「Test loss:」, score[0])
print(「Test accuracy:」, score[1])
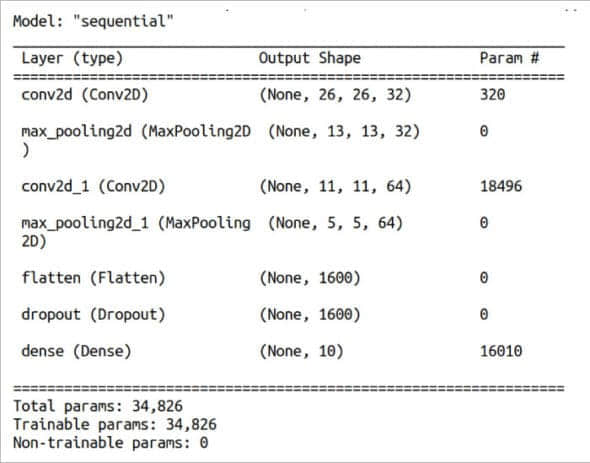
第 22 行列印我們訓練的模型的摘要信息(見圖 6)。回想一下,在載入數據集時將其分為了訓練數據和測試數據。第 23 行使用測試數據來測試我們訓練的模型的準確性。第 24 行和第 25 行列印測試的詳細信息(見圖 8)。
img = keras.utils.load_img("sample1.png").resize((28, 28)).convert('L')
img = keras.utils.img_to_array(img)
img = img.reshape((1, 28, 28, 1))
img = img.astype('float32')/255
score = model.predict(img)
print(score)
print("Number is", np.argmax(score))
print("Accuracy", np.max(score) * 100.0)
現在,是時候用實際數據來測試我們訓練的模型了。我在紙上寫了幾個數字,並掃描了它們。圖 7 是我用來測試模型的一個圖像。第 26 行載入圖像,然後將其大小調整為 28 x 28 像素,最後將其轉換為灰度圖像。第 27 到 29 行對圖像進行必要的預處理,以便將它輸入到我們訓練好的模型中。第 30 行預測圖像所屬的類別。第 31 到 33 行列印該預測的詳細信息。圖 8 顯示了程序 digital.py 的這部分輸出。從圖中可以看出,雖然圖像被正確識別為 7,但置信度只有 23.77%。進一步,從圖 8 中可以看到它被識別為 1 的置信度為 12.86%,被識別為 8 或 9 的置信度約為 11%。此外,該模型甚至在某些情況下會是分類錯誤。雖然我找不到導致性能低於標準的準確原因,但我認為相對較低的訓練圖像解析度以及測試圖像的質量可能是主要的影響因素。這雖然不是最好的模型,但我們現在有了第一個基於人工智慧和機器學習原理的訓練模型。希望在本系列的後續文章中,我們能構建出可以處理更困難任務的模型。

在本文介紹了 scikit-learn,在下一篇文章中我們還會繼續用到它。然後介紹了一些加深對神經網路的理解的知識和工具。我們還使用 Keras 訓練了第一個模型,並用這個模型進行預測。下一篇文章將繼續探索神經網路和模型訓練。我們還將了解 PyTorch,這是一個基於 Torch 庫的機器學習框架。PyTorch 可以用於開發 計算機視覺 (CV) 和 自然語言處理 (NLP) 相關的應用程序。

致謝:感謝我的學生 Sreyas S. 在撰寫本文過程中提出的創造性建議。
(題圖:DA/c8e10cac-a5a5-4d53-b5eb-db06f448e60e)
作者:Deepu Benson 選題:lujun9972 譯者:toknow-gh 校對:wxy
本文轉載來自 Linux 中國: https://github.com/Linux-CN/archive
對這篇文章感覺如何?
You may also like





More in:Linux中國

Let's Encrypt 正式發布,已經保護 380 萬個域名

關於Linux防火牆iptables的面試問答

Lets Encrypt 已被所有主流瀏覽器所信任

SSL/TLS 加密新紀元 – Lets Encrypt









