人工智慧教程(四):概率論入門

在本系列的 上一篇文章 中,我們進一步討論了矩陣和線性代數,並學習了用 JupyterLab 來運行 Python 代碼。在本系列的第四篇文章中,我們將開始學習 TensorFlow,這是一個非常強大的人工智慧和機器學習庫。我們也會簡要介紹一些其它有用的庫。稍後,我們將討論概率、理論以及代碼。和往常一樣,我們先討論一些能拓寬我們對人工智慧的理解的話題。
到目前為止,我們只是從技術方面討論人工智慧。隨著越來越多的人工智慧產品投入使用,現在是時候分析人工智慧的社會影響了。想像一個找工作的場景,如果你的求職申請由人來處理,在申請被拒絕時,你可以從他們那裡得到反饋,比如被拒的理由。如果你的求職申請由人工智慧程序處理,當你的申請被拒絕時,你不能要求該人工智慧軟體系統提供反饋。在這種情況下,你甚至不能確定你的申請被拒絕是否確實是僅基於事實的決定。這明確地告訴我們,從長遠來看,我們需要的不僅僅是魔法般的結果,還需要人工智慧具有 責任 和 保證 。(LCTT 譯註:責任主要指確保系統的決策過程是透明的、可解釋的,並且對系統的行為負責。保證是指對於系統性能指標和行為的一種承諾或者預期。)目前有很多試圖回答這些問題的研究。
人工智慧的應用也會引發許多道德和倫理上的問題。我們不必等到強人工智慧(也被稱為 通用人工智慧 —— AGI)出現才研究它的社會影響。我們可以通過思想實驗來探究人工智慧的影響。想像你在一個雨夜你駕車行駛在有髮夾完的道路上,突然你眼前有人橫穿馬路,你的反應是什麼?如果你突然剎車或轉向,你自己的生命將處於極大的危險之中。但如果你不這樣做,過馬路的人恐怕凶多吉少。因為我們人類具有自我犧牲的特質,在決策的瞬間,即使是最自私的人也可能決定救行人。但我們如何教會人工智慧系統模仿這種行為呢?畢竟從純粹的邏輯來看,自我犧牲是一個非常糟糕的選擇。
同樣的場景下,如果汽車是由人工智慧軟體在駕駛會發生什麼呢?既然你是汽車的主人,那麼人工智慧軟體理應把你的安全放在首位,它甚至全不顧其他乘客的安全。很容易看出,如果世界上所有的汽車都由這樣的軟體控制的話將導致徹底的混亂。現在,如果進一步假設乘坐自動駕駛汽車的乘客身患絕症。那麼對於一個數學機器來說,為了行人犧牲乘客是合乎邏輯的。但對於我們這些有血有肉的人卻不見得如此。你可以花點時間思考一下其它場景,注重邏輯的機器和熱血的人類都會做出什麼樣的決策。
有很多書籍和文章在討論人工智慧全面運作後的政治、社會和倫理方面的問題。但對於我們這些普通人和計算機工程師來說,讀所有的書都是不必要的。然而,由於人工智慧的社會意義如此重要,我們也不能輕易擱置這個問題。為了了解人工智慧的社會政治方面,我建議你通過幾部電影來理解人工智慧(強人工智慧)如何影響我們所有人。 斯坦利·庫布里克 的傑作《 2001:太空漫遊 》是最早描繪超級智能生物如何俯視我們人類的電影之一。這部電影中人工智慧認為人類是世界最大的威脅,並決定毀滅人類。事實上,有相當多的電影都在探索這種情節。由偉大的藝術大師 史蒂文·斯皮爾伯格 親自執導的《 人工智慧 》,探討了人工智慧機器如何與人類互動。另一部名為《 機械姬 》的電影詳細闡述了這一思路,講述了具有人工智慧的機器。在我看來這些都是了解人工智慧的影響必看的電影。
最後思考一下,試想如果馬路上的汽車使用來自製造商的不同的自動駕駛規則和人工智慧,這將導致徹底的混亂。
TensorFlow 入門
TensorFlow 是由 谷歌大腦 團隊開發的一個自由開源的庫,使用 Apache 2.0 許可證。TensorFlow 是開發人工智慧和機器學習程序的重量級的庫。除了 Python 之外,TensorFlow 還提供 C++、Java、JavaScript 等編程語言的介面。在我們進一步討論之前,有必要解釋一下 張量 是什麼。如果你熟悉物理學,張量這個詞對你來說可能並不陌生。但如果你不知道張量是什麼也不用擔心,現階段把它看作多維數組就行了。當然,這是一種過度簡化的理解。TensorFlow 可以在 NumPy 提供的多維數組之上運行。
首先,我們要在 JupyterLab 中安裝 TensorFlow。TensorFlow 有 GPU 版本和 CPU 版本兩種安裝類型可以選擇。這主要取決於你的系統是否有合適的 GPU。GPU 是一種利用並行處理來加快圖像處理速度的電路。它被廣泛用在遊戲和設計領域,在開發人工智慧和機器學習程序時也是必不可少的硬體。但一個不太好的消息是 TensorFlow 只兼容英偉達的 GPU。此外,你需要在系統中安裝一個稱為 CUDA( 計算統一設備架構 )的並行計算平台。如果你的系統滿足這些要求,那麼在 JupyterLab 上執行命令 pip install tensorflow-gpu 來安裝 GPU 版本的 TensorFlow。如果你系統的 GPU 配置無法滿足要求,當你嘗試使用 TensorFlow 時,會得到如下錯誤消息:「CUDA_ERROR_NO_DEVICE: no CUDA-capable device is detected」。此時使用 pip uninstall tensorflow-gpu 卸載 GPU 版本的 TensorFlow。然後執行命令 pip install tensorflow 安裝 CPU 版本的 TensorFlow。現在 TensorFlow 就準備就緒了。請注意,目前我們將討論限制在 CPU 和 TensorFlow 上。

現在,讓我們運行第一個由 TensorFlow 驅動的 Python 代碼。圖 1 顯示了一個簡單的 Python 腳本及其在 JupyterLab 上執行時的輸出。前兩行代碼將庫 NumPy 和 TensorFlow 導入到 Python 腳本中。順便一提,如果你想在 Jupyter Notebook 單元中顯示行號,單擊菜單 「 查看 > 顯示行號 」。第 3 行使用 NumPy 創建了一個名為 arr 的數組,其中包含三個元素。第 4 行代碼將數組 arr 的每個元素乘 3,將結果存儲在一個名為 ten 的變數中。第 5 行和第 6 行分別列印變數 arr 和 ten 的類型。從代碼的輸出中可以看到,arr 和 ten 的類型是不同的。第 7 行列印變數 ten 的值。注意,ten 的形狀與數組 arr 的形狀是相同的。 數據類型 int64 在本例中用於表示整數。這使得本例中 NumPy 和 TensorFlow 數據類型之間的無縫轉換成為可能。
TensorFlow 支持很多操作和運算。隨著處理的數據量的增加,這些操作會變得越來越複雜。TensorFlow 支持常見的算術運算,比如乘法、減法、除法、冪運算、模運算等。如果參與運算的是列表或元組,TensorFlow 會逐元素執行該操作。

TensorFlow 還支持邏輯運算、關係運算和位運算。這裡的操作也是按元素執行的。圖 2 顯示了執行這些按元素操作的 Python 腳本。第 1 行代碼從列表創建一個張量,並將其存儲在變數 t1 中。TensorFlow 的函數 constant() 用於從 Python 對象(如列表、元組等)創建張量。類似地,第 2 行創建了另一個張量 t2。第 3 行和第 4 行都是執行逐元素求冪並列印輸出。從圖 2 中可以清楚地看出,該求冪的結果是相同的。第 5 行代碼比較張量 t1 和 t2 的元素並列印結果。輸出中的 [True True False] 分別是對應 3>2、4>3 和 2>6 的結果。第 6 行的輸出與之類似。

圖 3 展示了 TensorFlow 處理矩陣的例子。第 1 行和第 3 行分別構造兩個矩陣 x 和 y,第 2 行和第 4 行分別列印矩陣 x 和 y的形狀。代碼的輸出顯示 x 的形狀為 (3,3),y 的形狀為 (3,)。從本系列前面介紹的矩陣知識,我們知道這兩個矩陣是不能相乘的。
因此,在第 5 行中將矩陣 y 增加了一個維度。在第 6 行,再次列印矩陣 y 的形狀,輸出結果為 (3,1)。現在矩陣 x 和 y 可以相乘了。第 7 行中,將矩陣相乘並列印輸出。注意,類似的操作也可以在張量上執行,即使張量的維數很高,TensorFlow 也可以很好地擴展。在本系列的後續文章中,我們將更多地了解 TensorFlow 支持的數據類型和其他複雜操作。
既然介紹了 TensorFlow,我想我也應該提一下 Keras。它為 TensorFlow 提供 Python 介面。在後續的文章中,我們將專門介紹 Keras。
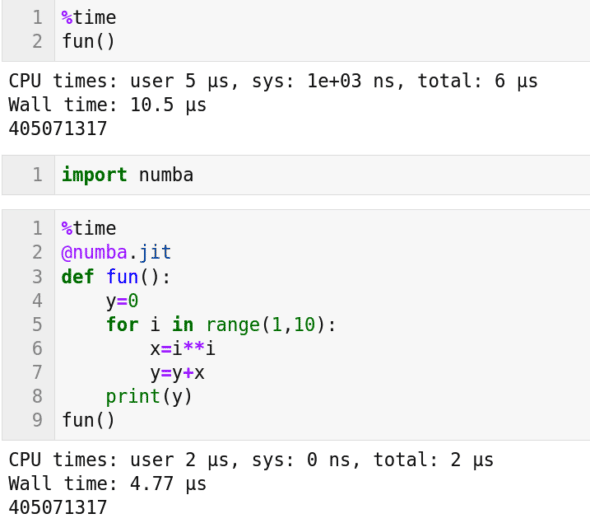
我們如何利用非英偉達 GPU 的能力呢?有許多功能強大的軟體包可以做到這一點。比如 PyOpenCL,一個在 Python 中編寫並行程序的框架。它讓我們可以使用 OpenCL( 開放計算語言 )。OpenCL 可以與 AMD、Arm、英偉達等廠商的 GPU 進行交互。當然還有其他選擇,比如 Numba。它是一種JIT 編譯器,可用在代碼執行期間將 Python 代碼編譯為機器碼。如果 GPU 可用,Numba 允許代碼使用的 GPU 能力。圖 4 是展示了使用 Numba 的 Python 代碼。
我們可以看到函數 fun() 具有允許並行化的特徵。從圖 4 中可以看到,代碼在不使用和使用 Numba 的情況下的答案是相同的。但是我們可以看到所花費的執行時間是不同的。當使用 Numba 並行化代碼時,只花費了不到一半的時間。此外隨著問題規模的增加,並行化和非並行化版本所花費的時間之間的差距也將增加。
SymPy 入門
SymPy 是一個用於符號計算的 Python 庫。通過圖 5 中的例子,讓我們試著理解什麼是符號計算。它使用 SymPy 提供的函數 Integral()來求積分。圖 5 也顯示了這個符號計算的輸出。注意,SciPy 提供的 integrate() 函數返回數值計算結果,而 SymPy 的 Integral() 函數能提供精確的符號結果表達式。人工智慧和機器學習程序開發中會用到一些統計學操作,SymPy 在執行這些操作時非常有用。

在本系列的下一篇文章中,我們將討論 Theano。Theano 是一個 Python 庫和優化編譯器,用於計算數學表達式。
概率論入門
現在是概率論出場的時候了,它是人工智慧和機器學習的另一個重要話題。對概率論的詳細討論超出了本系列的範圍。我強烈建議在繼續閱讀之前,先通過維基百科上關於「概率」、「貝葉斯定理」和「標準差」的文章了解一些重要的術語和概念,如概率、獨立事件、互斥事件、條件概率、貝葉斯定理、均值、標準差等。學習完這些後,你將能夠輕鬆理解後面關於概率的討論。
我們從概率分布開始講起。根據維基百科的說法,「概率分布是一個數學函數,它能給出一個實驗中不同的可能結果發生的概率」。現在,讓我們試著理解什麼是概率分布函數。最著名的概率分布函數是正態分布,通常也稱為高斯分布(以偉大的數學家高斯的名字命名)。正態分布函數的圖像是一條鐘形曲線。圖 6 是一個鐘形曲線的例子。鐘形曲線的確切形狀取決於均值和標準差。讓我們試著通過分析一種自然現象來理解鐘形曲線。從網上可以查到,中國男性的平均身高約為1.7米。在我們周圍的到多數男性的身高都非常接近這個數字。你看到一個身高低於1.4米或高於2米的男人的可能性很小。如果記錄 100 萬人的身高,然後以橫軸為身高,縱軸為該身高的人數,繪製統計結果,你會發現繪製出的圖像近似為鐘形曲線,其中只有一些輕微的傾斜和彎曲。因此,正態分布很容易地捕捉到自然現象的概率特徵。
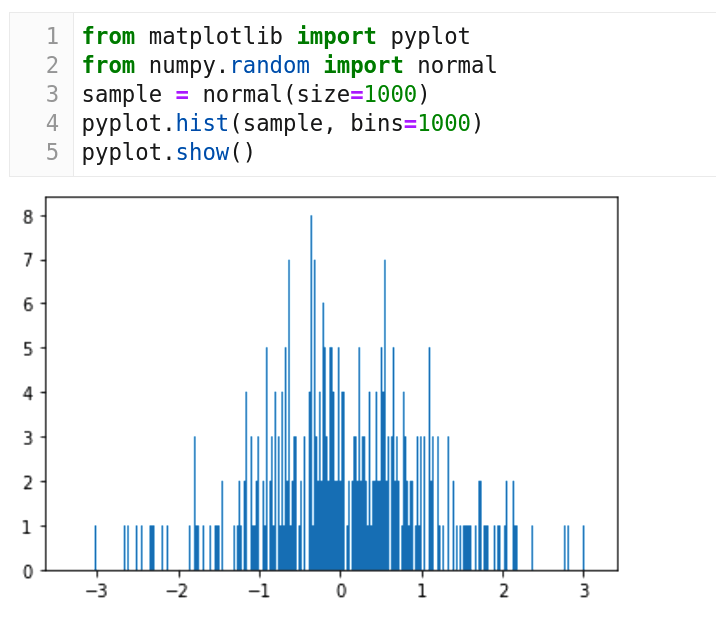
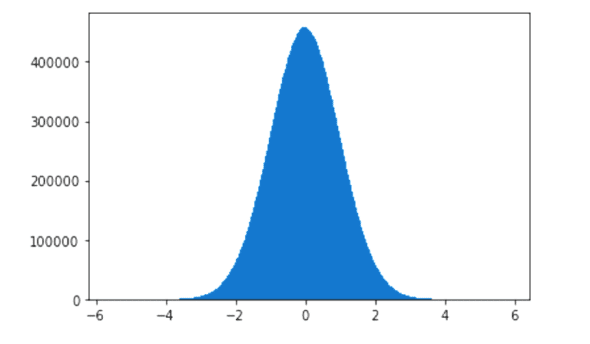
現在,我們來看一個使用正態分布的例子。圖 7 的代碼中我們使用 NumPy 的正態分布的函數 normal(),然後使用 Matplotlib 進行繪圖。從第 3 行我們可以看到樣本大小為 1000。第 4 行繪製一個包含 1000 個 桶 的直方圖。但是圖 7 的鐘形曲線與圖 6 中看到的鐘形曲線相差很大。究其原因是我們的樣本數量只有 1000。樣本量應該足夠大才能獲得更清晰的圖像。將第 3 行代碼替換為 sample = normal(size=100000000),行並再次執行程序。圖 8 顯示了一條更好的鐘形曲線。這一次,我們的樣本大小為 100,000,000,鐘形曲線與圖 6 所示非常相似。正態分布和鐘形曲線只是開始。在下一篇文章中,我們將討論可以概括其他事件和自然現象的概率分布函數。下一次,我們還將更正式地討論這個主題。
本篇的內容就到此結束了。在下一篇文章中,我們將繼續探索概率和統計中的一些概念。我們還將安裝和使用 Anaconda,這是一個用於科學計算的 Python 發行版,對於開發人工智慧、機器學習和數據科學程序特別有用。如前所述,我們還將熟悉另一個名為 Theano 的 Python 庫,它在人工智慧和機器學習領域被大量使用。
(題圖:DA/2a8d805a-01d3-4039-b96c-74766491e264)
via: https://www.opensourceforu.com/2023/01/ai-an-introduction-to-probability/
作者:Deepu Benson 選題:lujun9972 譯者:toknow-gh 校對:wxy
本文轉載來自 Linux 中國: https://github.com/Linux-CN/archive
對這篇文章感覺如何?
You may also like






More in:Linux中國

捐贈 Let's Encrypt,共建安全的互聯網

Let's Encrypt 正式發布,已經保護 380 萬個域名

關於Linux防火牆iptables的面試問答

Lets Encrypt 已被所有主流瀏覽器所信任









