Apache Kafka:為「無縫系統」提供非同步消息支持

你有沒有想過,電子商務平台是如何在處理巨大的流量時,做到不會卡頓的呢?有沒有想過,OTT 平台是如何在同時向數百萬用戶交付內容時,做到平穩運行的呢?其實,關鍵就在於它們的分散式架構。
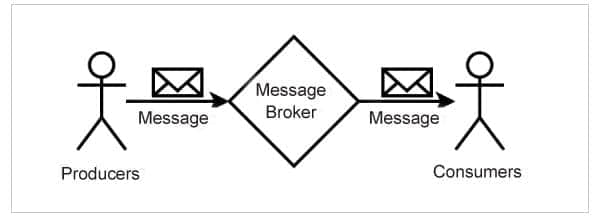
採用分散式架構設計的系統由多個功能組件組成。這些功能組件通常分布在多個機器上,它們通過網路,非同步地交換消息,從而實現相互協作。正是由於非同步消息的存在,組件之間才能實現可伸縮、無阻塞的通信,整個系統才能夠平穩運行。
非同步消息
非同步消息的常見特性有:
- 消息的 生產者 和 消費者 都不知道彼此的存在。它們在不知道對方的情況下,加入和離開系統。
- 消息 代理 充當了生產者和消費者之間的中介。
- 生產者把每條消息,都與一個「 主題 」相關聯。主題是一個簡單的字元串。
- 生產者可以在多個主題上發送消息,不同的生產者也可以在同一主題上發送消息。
- 消費者向代理訂閱一個或多個主題的消息。
- 生產者只將消息發送給代理,而不發送給消費者。
- 代理會把消息發送給訂閱該主題的所有消費者。
- 代理將消息傳遞給針對該主題註冊的所有消費者。
- 生產者並不期望得到消費者的任何回應。換句話說,生產者和消費者不會相互阻塞。
市場上的消息代理有很多,而 Apache Kafka 是其中最受歡迎的之一。
Apache Kafka
Apache Kafka 是一個支持流式處理的、開源的分散式消息系統,它由 Apache 軟體基金會開發。在架構上,它是多個代理組成的集群,這些代理間通過 Apache ZooKeeper 服務來協調。在接收、持久化和發送消息時,這些代理分擔集群上的負載。
分區
Kafka 將消息寫入稱為「 分區 」的桶中。一個特定分區只保存一個主題上的消息。例如,Kafka 會把 heartbeats 主題上的消息寫入名為 heartbeats-0 的分區(假設它是個單分區主題),這個過程和生產者無關。
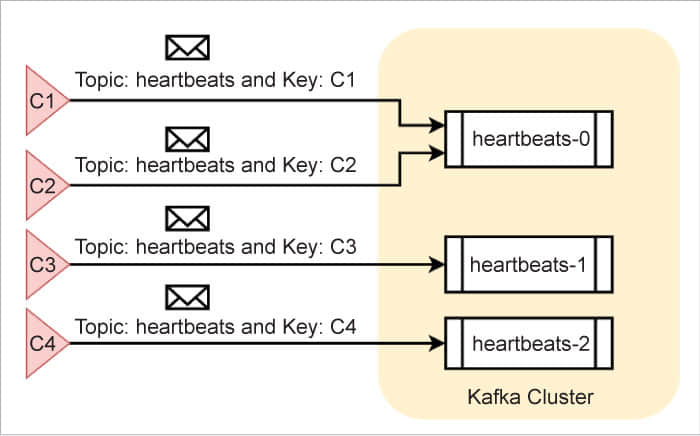
不過,為了利用 Kafka 集群所提供的並行處理能力,管理員通常會為指定主題創建多個分區。舉個例子,假設管理員為 heartbeats 主題創建了三個分區,Kafka 會將它們分別命名為 heartbeats-0、heartbeats-1 和 heartbeats-2。Kafka 會以某種方式,把消息分配到這三個分區中,並使它們均勻分布。
還有另一種可能的情況,生產者將每條消息與一個 消息鍵 相關聯。例如,同樣都是在 heartbeats 主題上發送消息,有個組件使用 C1 作為消息鍵,另一個則使用 C2。在這種情況下,Kafka 會確保,在一個主題中,帶有相同消息鍵的消息,總是會被寫入到同一個分區。不過,在一個分區中,消息的消息鍵卻不一定相同。下面的圖 2 顯示了消息在不同分區中的一種可能分布。
領導者和同步副本
Kafka 在(由多個代理組成的)集群中維護了多個分區。其中,負責維護分區的那個代理被稱為「 領導者 」。只有領導者能夠在它的分區上接收和發送消息。
可是,萬一分區的領導者發生故障了,又該怎麼辦呢?為了確保業務連續性,每個領導者(代理)都會把它的分區複製到其他代理上。此時,這些其他代理就稱為該分區的 同步副本 (ISR)。一旦分區的領導者發生故障,ZooKeeper 就會發起一次選舉,把選中的那個同步副本任命為新的領導者。此後,這個新的領導者將承擔該分區的消息接受和發送任務。管理員可以指定分區需要維護的同步副本的大小。

消息持久化
代理會將每個分區都映射到一個指定的磁碟文件,從而實現持久化。默認情況下,消息會在磁碟上保留一個星期。當消息寫入分區後,它們的內容和順序就不能更改了。管理員可以配置一些策略,如消息的保留時長、壓縮演算法等。
消費消息
與大多數其他消息系統不同,Kafka 不會主動將消息發送給消費者。相反,消費者應該監聽主題,並主動讀取消息。一個消費者可以從某個主題的多個分區中讀取消息。多個消費者也可以讀取來自同一個分區的消息。Kafka 保證了同一條消息不會被同一個消費者重複讀取。
Kafka 中的每個消費者都有一個組 ID。那些組 ID 相同的消費者們共同組成了一個消費者組。通常,為了從 N 個主題分區讀取消息,管理員會創建一個包含 N 個消費者的消費者組。這樣一來,組內的每個消費者都可以從它的指定分區中讀取消息。如果組內的消費者比可用分區還要多,那麼多出來的消費者就會處於閑置狀態。
在任何情況下,Kafka 都保證:不管組內有多少個消費者,同一條消息只會被該消費者組讀取一次。這個架構提供了一致性、高性能、高可擴展性、准實時交付和消息持久性,以及零消息丟失。
安裝、運行 Kafka
儘管在理論上,Kafka 集群可以由任意數量的代理組成,但在生產環境中,大多數集群通常由三個或五個代理組成。
在這裡,我們將搭建一個單代理集群,對於生產環境來說,它已經夠用了。
在瀏覽器中訪問 https://kafka.apache.org/downloads,下載 Kafka 的最新版本。在 Linux 終端中,我們也可以使用下面的命令來下載它:
wget https://www.apache.org/dyn/closer.cgi?path=/kafka/2.8.0/kafka_2.12-2.8.0.tgz
如果需要的話,我們也可以把下載來的檔案文件 kafka_2.12-2.8.0.tgz 移動到另一個目錄下。解壓這個檔案,你會得到一個名為 kafka_2.12-2.8.0 的目錄,它就是之後我們要設置的 KAFKA_HOME。
打開 KAFKA_HOME/config 目錄下的 server.properties 文件,取消注釋下面這一行配置:
listeners=PLAINTEXT://:9092
這行配置的作用是讓 Kafka 在本機的 9092 埠接收普通文本消息。我們也可以配置 Kafka 通過 安全通道 接收消息,在生產環境中,我們也推薦這麼做。
無論集群中有多少個代理,Kafka 都需要 ZooKeeper 來管理和協調它們。即使是單代理集群,也是如此。Kafka 在安裝時,會附帶安裝 ZooKeeper,因此,我們可以在 KAFKA_HOME 目錄下,在命令行中使用下面的命令來啟動它:
./bin/zookeeper-server-start.sh ./config/zookeeper.properties
當 ZooKeeper 運行起來後,我們就可以在另一個終端中啟動 Kafka 了,命令如下:
./bin/kafka-server-start.sh ./config/server.properties
到這裡,一個單代理的 Kafka 集群就運行起來了。
驗證 Kafka
讓我們在 topic-1 主題上嘗試下發送和接收消息吧!我們可以使用下面的命令,在創建主題時為它指定分區的個數:
./bin/kafka-topics.sh --create --topic topic-1 --zookeeper localhost:2181 --partitions 3 --replication-factor 1
上述命令還同時指定了 複製因子 ,它的值不能大於集群中代理的數量。我們使用的是單代理集群,因此,複製因子只能設置為 1。
當主題創建完成後,生產者和消費者就可以在上面交換消息了。Kafka 的發行版內附帶了生產者和消費者的命令行工具,供測試時用。
打開第三個終端,運行下面的命令,啟動生產者:
./bin/kafka-console-producer.sh --broker-list localhost:9092 --topic topic-1
上述命令顯示了一個提示符,我們可以在後面輸入簡單文本消息。由於我們指定的命令選項,生產者會把 topic-1 上的消息,發送到運行在本機的 9092 埠的 Kafka 中。
打開第四個終端,運行下面的命令,啟動消費者:
./bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic topic-1 –-from-beginning
上述命令啟動了一個消費者,並指定它連接到本機 9092 埠的 Kafka。它訂閱了 topic-1 主題,以讀取其中的消息。由於命令行的最後一個選項,這個消費者會從最開頭的位置,開始讀取該主題的所有消息。
我們注意到,生產者和消費者連接的是同一個代理,訪問的是同一個主題,因此,消費者在收到消息後會把消息列印到終端上。
下面,讓我們在實際應用場景中,嘗試使用 Kafka 吧!
案例
假設有一家叫做 ABC 的公共汽車運輸公司,它擁有一支客運車隊,往返於全國不同城市之間。由於 ABC 希望實時跟蹤每輛客車,以提高其運營質量,因此,它提出了一個基於 Apache Kafka 的解決方案。
首先,ABC 公司為所有公交車都配備了位置追蹤設備。然後,它使用 Kafka 建立了一個操作中心,以接收來自數百輛客車的位置更新。它還開發了一個 儀錶盤 ,以顯示任一時間點所有客車的當前位置。圖 5 展示了上述架構:
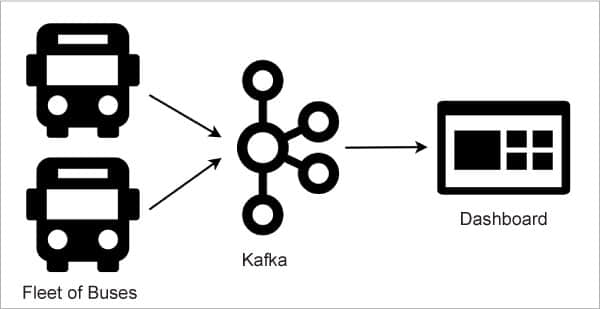
在這種架構下,客車上的設備扮演了消息生產者的角色。它們會周期性地把當前位置發送到 Kafka 的 abc-bus-location 主題上。ABC 公司選擇以客車的 行程編號 作為消息鍵,以處理來自不同客車的消息。例如,對於從 Bengaluru 到 Hubballi 的客車,它的行程編號就會是 BLRHL003,那麼在這段旅程中,對於所有來自該客車的消息,它們的消息鍵都會是 BLRHL003。
儀錶盤應用扮演了消息消費者的角色。它在代理上註冊了同一個主題 abc-bus-location。如此,這個主題就成為了生產者(客車)和消費者(儀錶盤)之間的虛擬通道。
客車上的設備不會期待得到來自儀錶盤應用的任何回復。事實上,它們相互之間都不知道對方的存在。得益於這種架構,數百輛客車和操作中心之間實現了非阻塞通信。
實現
假設 ABC 公司想要創建三個分區來維護位置更新。由於我們的開發環境只有一個代理,因此複製因子應設置為 1。
相應地,以下命令創建了符合需求的主題:
./bin/kafka-topics.sh --create --topic abc-bus-location --zookeeper localhost:2181 --partitions 3 --replication-factor 1
生產者和消費者應用可以用多種語言編寫,如 Java、Scala、Python 和 JavaScript 等。下面幾節中的代碼展示了它們在 Java 中的編寫方式,好讓我們有一個初步了解。
Java 生產者
下面的 Fleet 類模擬了在 ABC 公司的 6 輛客車上運行的 Kafka 生產者應用。它會把位置更新發送到指定代理的 abc-bus-location 主題上。請注意,簡單起見,主題名稱、消息鍵、消息內容和代理地址等,都在代碼里硬編碼的。
public class Fleet {
public static void main(String[] args) throws Exception {
String broker = 「localhost:9092」;
Properties props = new Properties();
props.setProperty(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, broker);
props.setProperty(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG,
StringSerializer.class.getName());
props.setProperty(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG,
StringSerializer.class.getName());
Producer<String, String> producer = new KafkaProducer<String, String>(props);
String topic = 「abc-bus-location」;
Map<String, String> locations = new HashMap<>();
locations.put(「BLRHBL001」, 「13.071362, 77.461906」);
locations.put(「BLRHBL002」, 「14.399654, 76.045834」);
locations.put(「BLRHBL003」, 「15.183959, 75.137622」);
locations.put(「BLRHBL004」, 「13.659576, 76.944675」);
locations.put(「BLRHBL005」, 「12.981337, 77.596181」);
locations.put(「BLRHBL006」, 「13.024843, 77.546983」);
IntStream.range(0, 10).forEach(i -> {
for (String trip : locations.keySet()) {
ProducerRecord<String, String> record
= new ProducerRecord<String, String>(
topic, trip, locations.get(trip));
producer.send(record);
}
});
producer.flush();
producer.close();
}
}
Java 消費者
下面的 Dashboard 類實現了一個 Kafka 消費者應用,運行在 ABC 公司的操作中心。它會監聽 abc-bus-location 主題,並且它的消費者組 ID 是 abc-dashboard。當收到消息後,它會立即顯示來自客車的詳細位置信息。我們本該配置這些詳細位置信息,但簡單起見,它們也是在代碼里硬編碼的:
public static void main(String[] args) {
String broker = 「127.0.0.1:9092」;
String groupId = 「abc-dashboard」;
Properties props = new Properties();
props.setProperty(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, broker);
props.setProperty(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG,
StringDeserializer.class.getName());
props.setProperty(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG,
StringDeserializer.class.getName());
props.setProperty(ConsumerConfig.GROUP_ID_CONFIG, groupId);
@SuppressWarnings(「resource」)
Consumer<String, String> consumer = new KafkaConsumer<String, String>(props);
consumer.subscribe(Arrays.asList(「abc-bus-location」));
while (true) {
ConsumerRecords<String, String> records
= consumer.poll(Duration.ofMillis(1000));
for (ConsumerRecord<String, String> record : records) {
String topic = record.topic();
int partition = record.partition();
String key = record.key();
String value = record.value();
System.out.println(String.format(
「Topic=%s, Partition=%d, Key=%s, Value=%s」,
topic, partition, key, value));
}
}
}
依賴
為了編譯和運行這些代碼,我們需要 JDK 8 及以上版本。看到下面的 pom.xml 文件中的 Maven 依賴了嗎?它們會把所需的 Kafka 客戶端庫下載並添加到類路徑中:
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka-clients</artifactId>
<version>2.8.0</version>
</dependency>
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-simple</artifactId>
<version>1.7.25</version>
</dependency>
部署
由於 abc-bus-location 主題在創建時指定了 3 個分區,我們自然就會想要運行 3 個消費者,來讓讀取位置更新的過程更快一些。為此,我們需要同時在 3 個不同的終端中運行儀錶盤。因為所有這 3 個儀錶盤都註冊在同一個組 ID 下,它們自然就構成了一個消費者組。Kafka 會為每個儀錶盤都分配一個特定的分區(來消費)。
當所有儀錶盤實例都運行起來後,在另一個終端中啟動 Fleet 類。圖 6、7、8 展示了儀錶盤終端中的控制台示例輸出。
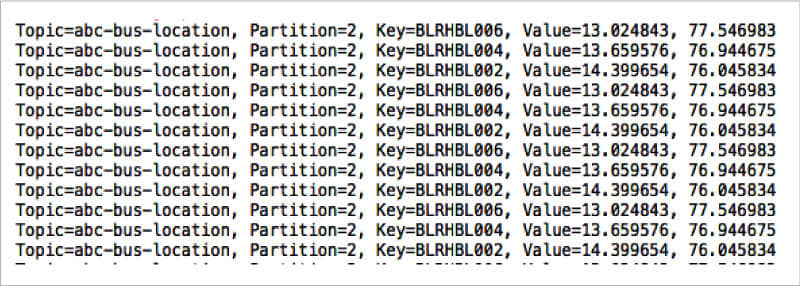
仔細看看控制台消息,我們會發現第一個、第二個和第三個終端中的消費者,正在分別從 partition-2、partition-1 和 partition-0 中讀取消息。另外,我們還能發現,消息鍵為 BLRHBL002、BLRHBL004 和 BLRHBL006 的消息寫入了 partition-2,消息鍵為 BLRHBL005 的消息寫入了 partition-1,剩下的消息寫入了 partition-0。

使用 Kafka 的好處在於,只要集群設計得當,它就可以水平擴展,從而支持大量客車和數百萬條消息。

不止是消息
根據 Kafka 官網上的數據,在《財富》100 強企業中,超過 80% 都在使用 Kafka。它部署在許多垂直行業,如金融服務、娛樂等。雖然 Kafka 起初只是一種簡單的消息服務,但它已憑藉行業級的流處理能力,成為了大數據生態系統的一環。對於那些喜歡託管解決方案的企業,Confluent 提供了基於雲的 Kafka 服務,只需支付訂閱費即可。(LCTT 譯註:Confluent 是一個基於 Kafka 的商業公司,它提供的 Confluent Kafka 在 Apache Kafka 的基礎上,增加了許多企業級特性,被認為是「更完整的 Kafka」。)
via: https://www.opensourceforu.com/2021/11/apache-kafka-asynchronous-messaging-for-seamless-systems/
作者:Krishna Mohan Koyya 選題:lkxed 譯者:lkxed 校對:wxy
本文轉載來自 Linux 中國: https://github.com/Linux-CN/archive
對這篇文章感覺如何?
You may also like






More in:Linux中國

捐贈 Let's Encrypt,共建安全的互聯網

Let's Encrypt 正式發布,已經保護 380 萬個域名

關於Linux防火牆iptables的面試問答

Lets Encrypt 已被所有主流瀏覽器所信任









