一個使用 asyncio 協程的網路爬蟲(三)

使用協程
我們將從描述爬蟲如何工作開始。現在是時候用 asynio 去實現它了。
我們的爬蟲從獲取第一個網頁開始,解析出鏈接並把它們加到隊列中。此後它開始傲遊整個網站,並發地獲取網頁。但是由於客戶端和服務端的負載限制,我們希望有一個最大數目的運行的 worker,不能再多。任何時候一個 worker 完成一個網頁的獲取,它應該立即從隊列中取出下一個鏈接。我們會遇到沒有那麼多事乾的時候,所以一些 worker 必須能夠暫停。一旦又有 worker 獲取一個有很多鏈接的網頁,隊列會突增,暫停的 worker 立馬被喚醒幹活。最後,當任務完成後我們的程序必須馬上退出。
假如你的 worker 是線程,怎樣去描述你的爬蟲演算法?我們可以使用 Python 標準庫中的同步隊列。每次有新的一項加入,隊列增加它的 「tasks」 計數器。線程 worker 完成一個任務後調用 task_done。主線程阻塞在 Queue.join,直到「tasks」計數器與 task_done 調用次數相匹配,然後退出。
協程通過 asyncio 隊列,使用和線程一樣的模式來實現!首先我們導入它:
try:
from asyncio import JoinableQueue as Queue
except ImportError:
# In Python 3.5, asyncio.JoinableQueue is
# merged into Queue.
from asyncio import Queue
我們把 worker 的共享狀態收集在一個 crawler 類中,主要的邏輯寫在 crawl 方法中。我們在一個協程中啟動 crawl,運行 asyncio 的事件循環直到 crawl 完成:
loop = asyncio.get_event_loop()
crawler = crawling.Crawler('http://xkcd.com',
max_redirect=10)
loop.run_until_complete(crawler.crawl())
crawler 用一個根 URL 和最大重定向數 max_redirect 來初始化,它把 (URL, max_redirect) 序對放入隊列中。(為什麼要這樣做,請看下文)
class Crawler:
def __init__(self, root_url, max_redirect):
self.max_tasks = 10
self.max_redirect = max_redirect
self.q = Queue()
self.seen_urls = set()
# aiohttp's ClientSession does connection pooling and
# HTTP keep-alives for us.
self.session = aiohttp.ClientSession(loop=loop)
# Put (URL, max_redirect) in the queue.
self.q.put((root_url, self.max_redirect))
現在隊列中未完成的任務數是 1。回到我們的主程序,啟動事件循環和 crawl 方法:
loop.run_until_complete(crawler.crawl())
crawl 協程把 worker 們趕起來幹活。它像一個主線程:阻塞在 join 上直到所有任務完成,同時 worker 們在後台運行。
@asyncio.coroutine
def crawl(self):
"""Run the crawler until all work is done."""
workers = [asyncio.Task(self.work())
for _ in range(self.max_tasks)]
# When all work is done, exit.
yield from self.q.join()
for w in workers:
w.cancel()
如果 worker 是線程,可能我們不會一次把它們全部創建出來。為了避免創建線程的昂貴代價,通常一個線程池會按需增長。但是協程很廉價,我們可以直接把他們全部創建出來。
怎麼關閉這個 crawler 很有趣。當 join 完成,worker 存活但是被暫停:他們等待更多的 URL,所以主協程要在退出之前清除它們。否則 Python 解釋器關閉並調用所有對象的析構函數時,活著的 worker 會哭喊到:
ERROR:asyncio:Task was destroyed but it is pending!
cancel 又是如何工作的呢?生成器還有一個我們還沒介紹的特點。你可以從外部拋一個異常給它:
>>> gen = gen_fn()
>>> gen.send(None) # Start the generator as usual.
1
>>> gen.throw(Exception('error'))
Traceback (most recent call last):
File "<input>", line 3, in <module>
File "<input>", line 2, in gen_fn
Exception: error
生成器被 throw 恢復,但是它現在拋出一個異常。如過生成器的調用堆棧中沒有捕獲異常的代碼,這個異常被傳遞到頂層。所以註銷一個協程:
# Method of Task class.
def cancel(self):
self.coro.throw(CancelledError)
任何時候生成器暫停,在某些 yield from 語句它恢復並且拋出一個異常。我們在 task 的 step 方法中處理註銷。
# Method of Task class.
def step(self, future):
try:
next_future = self.coro.send(future.result)
except CancelledError:
self.cancelled = True
return
except StopIteration:
return
next_future.add_done_callback(self.step)
現在 task 知道它被註銷了,所以當它被銷毀時,它不再抱怨。
一旦 crawl 註銷了 worker,它就退出。同時事件循環看見這個協程結束了(我們後面會見到的),也就退出。
loop.run_until_complete(crawler.crawl())
crawl 方法包含了所有主協程需要做的事。而 worker 則完成從隊列中獲取 URL、獲取網頁、解析它們得到新的鏈接。每個 worker 獨立地運行 work 協程:
@asyncio.coroutine
def work(self):
while True:
url, max_redirect = yield from self.q.get()
# Download page and add new links to self.q.
yield from self.fetch(url, max_redirect)
self.q.task_done()
Python 看見這段代碼包含 yield from 語句,就把它編譯成生成器函數。所以在 crawl 方法中,我們調用了 10 次 self.work,但並沒有真正執行,它僅僅創建了 10 個指向這段代碼的生成器對象並把它們包裝成 Task 對象。task 接收每個生成器所 yield 的 future,通過調用 send 方法,當 future 解決時,用 future 的結果做為 send 的參數,來驅動它。由於生成器有自己的棧幀,它們可以獨立運行,帶有獨立的局部變數和指令指針。
worker 使用隊列來協調其小夥伴。它這樣等待新的 URL:
url, max_redirect = yield from self.q.get()
隊列的 get 方法自身也是一個協程,它一直暫停到有新的 URL 進入隊列,然後恢復並返回該條目。
碰巧,這也是當主協程註銷 worker 時,最後 crawl 停止,worker 協程暫停的地方。從協程的角度,yield from 拋出CancelledError 結束了它在循環中的最後旅程。
worker 獲取一個網頁,解析鏈接,把新的鏈接放入隊列中,接著調用task_done減小計數器。最終一個worker遇到一個沒有新鏈接的網頁,並且隊列里也沒有任務,這次task_done的調用使計數器減為0,而crawl正阻塞在join方法上,現在它就可以結束了。
我們承諾過要解釋為什麼隊列中要使用序對,像這樣:
# URL to fetch, and the number of redirects left.
('http://xkcd.com/353', 10)
新的 URL 的重定向次數是10。獲取一個特別的 URL 會重定向一個新的位置。我們減小重定向次數,並把新的 URL 放入隊列中。
# URL with a trailing slash. Nine redirects left.
('http://xkcd.com/353/', 9)
我們使用的 aiohttp 默認會跟蹤重定向並返回最終結果。但是,我們告訴它不要這樣做,爬蟲自己來處理重定向,以便它可以合併那些目的相同的重定向路徑:如果我們已經在 self.seen_urls 看到一個 URL,說明它已經從其他的地方走過這條路了。
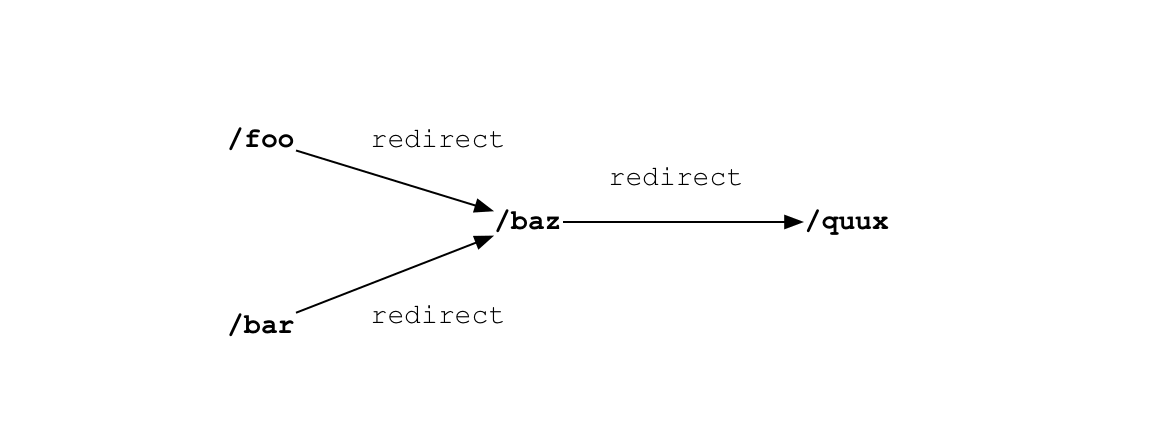
crawler 獲取「foo」並發現它重定向到了「baz」,所以它會加「baz」到隊列和 seen_urls 中。如果它獲取的下一個頁面「bar」 也重定向到「baz」,fetcher 不會再次將 「baz」加入到隊列中。如果該響應是一個頁面,而不是一個重定向,fetch 會解析它的鏈接,並把新鏈接放到隊列中。
@asyncio.coroutine
def fetch(self, url, max_redirect):
# Handle redirects ourselves.
response = yield from self.session.get(
url, allow_redirects=False)
try:
if is_redirect(response):
if max_redirect > 0:
next_url = response.headers['location']
if next_url in self.seen_urls:
# We have been down this path before.
return
# Remember we have seen this URL.
self.seen_urls.add(next_url)
# Follow the redirect. One less redirect remains.
self.q.put_nowait((next_url, max_redirect - 1))
else:
links = yield from self.parse_links(response)
# Python set-logic:
for link in links.difference(self.seen_urls):
self.q.put_nowait((link, self.max_redirect))
self.seen_urls.update(links)
finally:
# Return connection to pool.
yield from response.release()
如果這是多進程代碼,就有可能遇到討厭的競爭條件。比如,一個 worker 檢查一個鏈接是否在 seen_urls 中,如果沒有它就把這個鏈接加到隊列中並把它放到 seen_urls 中。如果它在這兩步操作之間被中斷,而另一個 worker 解析到相同的鏈接,發現它並沒有出現在 seen_urls 中就把它加入隊列中。這(至少)導致同樣的鏈接在隊列中出現兩次,做了重複的工作和錯誤的統計。
然而,一個協程只在 yield from 時才會被中斷。這是協程比多線程少遇到競爭條件的關鍵。多線程必須獲得鎖來明確的進入一個臨界區,否則它就是可中斷的。而 Python 的協程默認是不會被中斷的,只有它明確 yield 時才主動放棄控制權。
我們不再需要在用回調方式時用的 fetcher 類了。這個類只是不高效回調的一個變通方法:在等待 I/O 時,它需要一個存儲狀態的地方,因為局部變數並不能在函數調用間保留。倒是 fetch 協程可以像普通函數一樣用局部變數保存它的狀態,所以我們不再需要一個類。
當 fetch 完成對伺服器響應的處理,它返回到它的調用者 work。work 方法對隊列調用 task_done,接著從隊列中取出一個要獲取的 URL。
當 fetch 把新的鏈接放入隊列中,它增加未完成的任務計數器,並停留在主協程,主協程在等待 q.join,處於暫停狀態。而當沒有新的鏈接並且這是隊列中最後一個 URL 時,當 work 調用task_done,任務計數器變為 0,主協程從join` 中退出。
與 worker 和主協程一起工作的隊列代碼像這樣(實際的 asyncio.Queue 實現在 Future 所展示的地方使用 asyncio.Event 。不同之處在於 Event 是可以重置的,而 Future 不能從已解決返回變成待決。)
class Queue:
def __init__(self):
self._join_future = Future()
self._unfinished_tasks = 0
# ... other initialization ...
def put_nowait(self, item):
self._unfinished_tasks += 1
# ... store the item ...
def task_done(self):
self._unfinished_tasks -= 1
if self._unfinished_tasks == 0:
self._join_future.set_result(None)
@asyncio.coroutine
def join(self):
if self._unfinished_tasks > 0:
yield from self._join_future
主協程 crawl yield from join。所以當最後一個 worker 把計數器減為 0,它告訴 crawl 恢復運行並結束。
旅程快要結束了。我們的程序從 crawl 調用開始:
loop.run_until_complete(self.crawler.crawl())
程序如何結束?因為 crawl 是一個生成器函數,調用它返回一個生成器。為了驅動它,asyncio 把它包裝成一個 task:
class EventLoop:
def run_until_complete(self, coro):
"""Run until the coroutine is done."""
task = Task(coro)
task.add_done_callback(stop_callback)
try:
self.run_forever()
except StopError:
pass
class StopError(BaseException):
"""Raised to stop the event loop."""
def stop_callback(future):
raise StopError當這個任務完成,它拋出 StopError,事件循環把這個異常當作正常退出的信號。
但是,task 的 add_done_callbock 和 result 方法又是什麼呢?你可能認為 task 就像一個 future,不錯,你的直覺是對的。我們必須承認一個向你隱藏的細節,task 是 future。
class Task(Future):
"""A coroutine wrapped in a Future."""通常,一個 future 被別人調用 set_result 解決。但是 task,當協程結束時,它自己解決自己。記得我們解釋過當 Python 生成器返回時,它拋出一個特殊的 StopIteration 異常:
# Method of class Task.
def step(self, future):
try:
next_future = self.coro.send(future.result)
except CancelledError:
self.cancelled = True
return
except StopIteration as exc:
# Task resolves itself with coro's return
# value.
self.set_result(exc.value)
return
next_future.add_done_callback(self.step)
所以當事件循環調用 task.add_done_callback(stop_callback),它就準備被這個 task 停止。在看一次run_until_complete:
# Method of event loop.
def run_until_complete(self, coro):
task = Task(coro)
task.add_done_callback(stop_callback)
try:
self.run_forever()
except StopError:
pass
當 task 捕獲 StopIteration 並解決自己,這個回調從循環中拋出 StopError。循環結束,調用棧回到run_until_complete。我們的程序結束。
總結
現代的程序越來越多是 I/O 密集型而不是 CPU 密集型。對於這樣的程序,Python 的線程在兩個方面不合適:全局解釋器鎖阻止真正的並行計算,並且搶佔切換也導致他們更容易出現競爭。非同步通常是正確的選擇。但是隨著基於回調的非同步代碼增加,它會變得非常混亂。協程是一個更整潔的替代者。它們自然地重構成子過程,有健全的異常處理和棧追溯。
如果我們換個角度看 yield from 語句,一個協程看起來像一個傳統的做阻塞 I/O 的線程。甚至我們可以採用經典的多線程模式編程,不需要重新發明。因此,與回調相比,協程更適合有經驗的多線程的編碼者。
但是當我們睜開眼睛關注 yield from 語句,我們能看到協程放棄控制權、允許其它人運行的標誌點。不像多線程,協程展示出我們的代碼哪裡可以被中斷哪裡不能。在 Glyph Lefkowitz 富有啟發性的文章「Unyielding」:「線程讓局部推理變得困難,然而局部推理可能是軟體開發中最重要的事」。然而,明確的 yield,讓「通過過程本身而不是整個系統理解它的行為(和因此、正確性)」成為可能。
這章寫於 Python 和非同步的復興時期。你剛學到的基於生成器的的協程,在 2014 年發布在 Python 3.4 的 asyncio 模塊中。2015 年 9 月,Python 3.5 發布,協程成為語言的一部分。這個原生的協程通過「async def」來聲明, 使用「await」而不是「yield from」委託一個協程或者等待 Future。
除了這些優點,核心的思想不變。Python 新的原生協程與生成器只是在語法上不同,工作原理非常相似。事實上,在 Python 解釋器中它們共用同一個實現方法。Task、Future 和事件循環在 asynico 中扮演著同樣的角色。
你已經知道 asyncio 協程是如何工作的了,現在你可以忘記大部分的細節。這些機制隱藏在一個整潔的介面下。但是你對這基本原理的理解能讓你在現代非同步環境下正確而高效的編寫代碼。
(題圖素材來自:ruth-tay.deviantart.com)
via: http://aosabook.org/en/500L/pages/a-web-crawler-with-asyncio-coroutines.html
作者:A. Jesse Jiryu Davis , Guido van Rossum 譯者:qingyunha 校對:wxy
本文轉載來自 Linux 中國: https://github.com/Linux-CN/archive
對這篇文章感覺如何?
You may also like






More in:Linux中國

捐贈 Let's Encrypt,共建安全的互聯網

Let's Encrypt 正式發布,已經保護 380 萬個域名

關於Linux防火牆iptables的面試問答

Lets Encrypt 已被所有主流瀏覽器所信任









