機器學習的新捷徑:通過 SYCL 在 GPU 上加速 C++

在機器學習、計算機視覺以及高性能計算領域,充分利用顯卡計算應用程序的能力已成為當前的熱門。類似 OpenCL 的技術通過硬體無關的編程模型展現了這種能力,使得你可以編寫抽象於不同體系架構的代碼。它的目標是「一次編寫,到處運行」,不管它是 Intel CPU、AMD 獨立顯卡還是 DSP 等等。不幸的是,對於日常程序員,OpenCL 的學習曲線陡峭;一個簡單的 Hello World 程序可能就需要上百行晦澀難懂的代碼。因此,為了減輕這種痛苦,Khronos 組織已經開發了一個稱為 SYCL 的新標準,這是一個在 OpenCL 之上的 C++ 抽象層。通過 SYCL,你可以使用乾淨、現代的 C++ 開發出這些通用 GPU(GPGPU)應用程序,而無需拘泥於 OpenCL。下面是一個使用 SYCL 開發,通過並行 STL 實現的向量乘法事例:
#include <vector>
#include <iostream>
#include <sycl/execution_policy>
#include <experimental/algorithm>
#include <sycl/helpers/sycl_buffers.hpp>
using namespace std::experimental::parallel;
using namespace sycl::helpers;
int main() {
constexpr size_t array_size = 1024*512;
std::array<cl::sycl::cl_int, array_size> a;
std::iota(begin(a),end(a),0);
{
cl::sycl::buffer<int> b(a.data(), cl::sycl::range<1>(a.size()));
cl::sycl::queue q;
sycl::sycl_execution_policy<class Mul> sycl_policy(q);
transform(sycl_policy, begin(b), end(b), begin(b),
[](int x) { return x*2; });
}
}
為了作為對比,下面是一個通過 C++ API 使用 OpenCL 編寫的大概對應版本(無需花過多時間閱讀,只需注意到它看起來難看而且冗長)。
#include <iostream>
#include <array>
#include <numeric>
#include <CL/cl.hpp>
int main(){
std::vector<cl::Platform> all_platforms;
cl::Platform::get(&all_platforms);
if(all_platforms.size()==0){
std::cout<<" No platforms found. Check OpenCL installation!n";
exit(1);
}
cl::Platform default_platform=all_platforms[0];
std::vector<cl::Device> all_devices;
default_platform.getDevices(CL_DEVICE_TYPE_ALL, &all_devices);
if(all_devices.size()==0){
std::cout<<" No devices found. Check OpenCL installation!n";
exit(1);
}
cl::Device default_device=all_devices[0];
cl::Context context({default_device});
cl::Program::Sources sources;
std::string kernel_code=
" void kernel mul2(global int* A){"
" A[get_global_id(0)]=A[get_global_id(0)]*2;"
" }";
sources.push_back({kernel_code.c_str(),kernel_code.length()});
cl::Program program(context,sources);
if(program.build({default_device})!=CL_SUCCESS){
std::cout<<" Error building: "<<program.getBuildInfo<CL_PROGRAM_BUILD_LOG>(default_device)<<"n";
exit(1);
}
constexpr size_t array_size = 1024*512;
std::array<cl_int, array_size> a;
std::iota(begin(a),end(a),0);
cl::Buffer buffer_A(context,CL_MEM_READ_WRITE,sizeof(int)*a.size());
cl::CommandQueue queue(context,default_device);
if (queue.enqueueWriteBuffer(buffer_A,CL_TRUE,0,sizeof(int)*a.size(),a.data()) != CL_SUCCESS) {
std::cout << "Failed to write memory;n";
exit(1);
}
cl::Kernel kernel_add = cl::Kernel(program,"mul2");
kernel_add.setArg(0,buffer_A);
if (queue.enqueueNDRangeKernel(kernel_add,cl::NullRange,cl::NDRange(a.size()),cl::NullRange) != CL_SUCCESS) {
std::cout << "Failed to enqueue kerneln";
exit(1);
}
if (queue.finish() != CL_SUCCESS) {
std::cout << "Failed to finish kerneln";
exit(1);
}
if (queue.enqueueReadBuffer(buffer_A,CL_TRUE,0,sizeof(int)*a.size(),a.data()) != CL_SUCCESS) {
std::cout << "Failed to read resultn";
exit(1);
}
}
在這篇博文中我會介紹使用 SYCL 加速你 GPU 上的 C++ 代碼。
GPGPU 簡介
在我開始介紹如何使用 SYCL 之前,我首先給那些不熟悉這方面的人簡要介紹一下為什麼你可能想要在 GPU 上運行計算任務。如果已經使用過 OpenCL、CUDA 或類似的庫,可以跳過這一節。
GPU 和 CPU 的一個關鍵不同就是 GPU 有大量小的、簡單的處理單元,而不是少量(對於普通消費者桌面硬體通常是 1-8 個)複雜而強大的核。
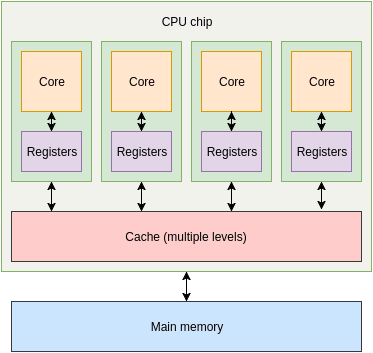
上面是一個 4 核 CPU 的簡單漫畫示意圖。每個核都有一組寄存器以及不同等級的緩存(有些是共享緩存、有些不是),然後是主內存。
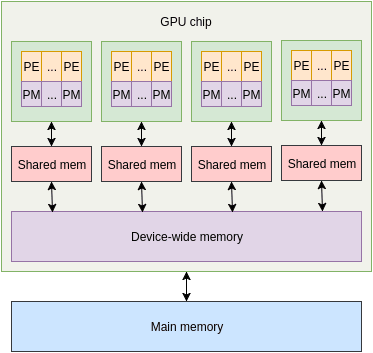
在 GPU 上,多個小處理單元被組成一個執行單元。每個小處理單元都附有少量內存,每個執行單元都有一些共享內存用於它的處理單元。除此之外,還有一些 GPU 範圍的內存,然後是 CPU 使用的主內存。執行單元內部的單元是 lockstep ,每個單元都在不同的數據片上執行相同的指令。
這可以使 GPU 同時處理大量的數據。如果是在 CPU 上,也許你可以使用多線程和向量指令在給定時間內完成大量的工作,但是 GPU 所能處理的遠多於此。在 GPU 上一次性能夠處理的數據規模使得它非常適合於類似圖形(duh)、數學處理、神經網路等等。
GPGPU 編程的很多方面使得它和日常的 CPU 編程完全不同。例如,從主內存傳輸數據到 GPU 是很慢的。真的很慢。會完全乾掉你的性能使你慢下來。因此,GPU 編程的權衡是儘可能多地利用加速器的高吞吐量來掩蓋數據來往的延遲。
這裡還有一些不那麼明顯的問題,例如分支的開銷。由於執行單元內的處理單元按照 lockstep 工作,使它們執行不同路徑(不同的控制流)的嵌套分支就是個真正的問題。這通常通過在所有單元上執行所有分支並標記出無用結果來解決。這是一個基於嵌套級別的指數級的複雜度,這當然是壞事情。當然,有一些優化方法可以拯救該問題,但需要注意:你從 CPU 領域帶來的簡單假設和知識在 GPU 領域可能導致大問題。
在我們回到 SYCL 之前,需要介紹一些術語。 主機 是主 CPU 運行的機器, 設備 是會運行你 OpenCL 代碼的地方。設備可能就是主機,但也可能是你機器上的一些加速器、模擬器等。 內核 是一個特殊函數,它是在你設備上運行代碼的入口點。通常還會提供一些主機設置好的緩存給它用於輸入和輸出數據。
回到 SYCL
這裡有兩個可用的 SYCL 實現:triSYCL,由 Xilinx 開發的實驗性開源版本(通常作為標準的試驗台使用),以及 ComputeCpp,由 Codeplay(我在 Codeplay 工作,但這篇文章是在沒有我僱主建議的情況下使用我自己時間編寫的) 開發的工業級實現(當前處於開發測試版)。只有 ComputeCpp 支持在 GPU 上執行內核,因此在這篇文章中我們會使用它。
第一步是在你的機器上配置以及運行 ComputeCpp。主要組件是一個實現了 SYCL API 的運行時庫,以及一個基於 Clang 的編譯器,它負責編譯你的主機代碼和設備代碼。在本文寫作時,已經在 Ubuntu 和 CentOS 上官方支持 Intel CPU 以及某些 AMD GPU。在其它 Linux 發行版上讓它工作也非常簡單(例如,我讓它在我的 Arch 系統上運行)。對更多的硬體和操作系統的支持正在進行中,查看支持平台文檔獲取最新列表。這裡列出了依賴和組件。你也可能想要下載 SDK,其中包括了示例、文檔、構建系統集成文件,以及其它。在這篇文章中我會使用 SYCL 並行 STL,如果你想要自己在家學習的話也要下載它。
一旦你設置好了一切,我們就可以開始通用 GPU 編程了!正如簡介中提到的,我的第一個示例使用 SYCL 並行 STL 實現。我們現在來看看如何使用純 SYCL 編寫代碼。
#include <CL/sycl.hpp>
#include <array>
#include <numeric>
#include <iostream>
int main() {
const size_t array_size = 1024*512;
std::array<cl::sycl::cl_int, array_size> in,out;
std::iota(begin(in),end(in),0);
{
cl::sycl::queue device_queue;
cl::sycl::range<1> n_items{array_size};
cl::sycl::buffer<cl::sycl::cl_int, 1> in_buffer(in.data(), n_items);
cl::sycl::buffer<cl::sycl::cl_int, 1> out_buffer(out.data(), n_items);
device_queue.submit([&](cl::sycl::handler &cgh) {
constexpr auto sycl_read = cl::sycl::access::mode::read;
constexpr auto sycl_write = cl::sycl::access::mode::write;
auto in_accessor = in_buffer.get_access<sycl_read>(cgh);
auto out_accessor = out_buffer.get_access<sycl_write>(cgh);
cgh.parallel_for<class VecScalMul>(n_items,
[=](cl::sycl::id<1> wiID) {
out_accessor[wiID] = in_accessor[wiID]*2;
});
});
}
}
我會把它劃分為一個個片段。
#include <CL/sycl.hpp>
我們做的第一件事就是包含 SYCL 頭文件,它會在我們的命令中添加 SYCL 運行時庫。
const size_t array_size = 1024*512;
std::array<cl::sycl::cl_int, array_size> in,out;
std::iota(begin(in),end(in),0);
這裡我們構造了一個很大的整型數組並用數字 0 到 array_size-1 初始化(這就是 std::iota 所做的)。注意我們使用 cl::sycl::cl_int 確保兼容性。
{
//...
}
接著我們打開一個新的作用域,其目的為二:
device_queue將在該作用域結束時解構,它將阻塞,直到內核完成。in_buffer和out_buffer也將解構,這將強制數據傳輸回主機並允許我們從in和out中訪問數據。cl::sycl::queue device_queue;
現在我們創建我們的命令隊列。命令隊列是所有工作(內核)在分發到設備之前需要入隊的地方。有很多方法可以定製隊列,例如說提供設備用於入隊或者設置非同步錯誤處理器,但對於這個例子默認構造器就可以了;它會查找兼容的 GPU,如果失敗的話會回退到主機 CPU。
cl::sycl::range<1> n_items{array_size};
接下來我們創建一個範圍,它描述了內核在上面執行的數據的形狀。在我們簡單的例子中,它是一個一維數組,因此我們使用 cl::sycl::range<1>。如果數據是二維的,我們就會使用 cl::sycl::range<2>,以此類推。除了 cl::sycl::range,還有 cl::sycl::ndrange,它允許你指定工作組大小以及越界範圍,但在我們的例子中我們不需要使用它。
cl::sycl::buffer<cl::sycl::cl_int, 1> in_buffer(in.data(), n_items);
cl::sycl::buffer<cl::sycl::cl_int, 1> out_buffer(out.data(), n_items);
為了控制主機和設備之間的數據共享和傳輸,SYCL 提供了一個 buffer 類。我們創建了兩個 SYCL 緩存用於管理我們的輸入和輸出數組。
device_queue.submit([&](cl::sycl::handler &cgh) {/*...*/});
設置好了我們所有數據之後,我們就可以入隊真正的工作。有多種方法可以做到,但設置並行執行的一個簡單方法是在我們的隊列中調用 .submit 函數。對於這個函數我們傳遞了一個運行時調度該任務時會被執行的「命令組偽函數」(偽函數是規範,不是我創造的)。命令組處理器設置任何內核需要的餘下資源並分發它。
constexpr auto sycl_read = cl::sycl::access::mode::read_write;
constexpr auto sycl_write = cl::sycl::access::mode::write;
auto in_accessor = in_buffer.get_access<sycl_read>(cgh);
auto out_accessor = out_buffer.get_access<sycl_write>(cgh);
為了控制到我們緩存的訪問並告訴該運行時環境我們會如何使用數據,我們需要創建訪問器。很顯然,我們創建了一個訪問器用於從 in_buffer 讀入,一個訪問器用於寫到 out_buffer。
cgh.parallel_for<class VecScalMul>(n_items,
[=](cl::sycl::id<1> wiID) {
out_accessor[wiID] = in_accessor[wiID]*2;
});
現在我們已經完成了所有設置,我們可以真正的在我們的設備上做一些計算了。這裡我們根據範圍 n_items 在命令組處理器 cgh 之上分發一個內核。實際內核自身是一個使用 work-item 標識符作為輸入、輸出我們計算結果的 lamda 表達式。在這種情況下,我們從 in_accessor 使用 work-item 標識符作為索引讀入,將其乘以 2,然後將結果保存到 out_accessor 相應的位置。<class VecScalMul> 是一個為了在標準 C++ 範圍內工作的不幸的副產品,因此我們需要給內核一個唯一的類名以便編譯器能完成它的工作。
}
在此之後,我們現在可以訪問 out 並期望看到正確的結果。
這裡有相當多的新概念在起作用,但使用這些技術你可以看到這些能力和所展現出來的東西。當然,如果你只是想在你的 GPU 上執行一些代碼而不關心定製化,那麼你就可以使用 SYCL 並行 STL 實現。
SYCL 並行 STL
SYCL 並行 STL 是一個 TS 的並行化實現,它分發你的演算法函數對象作為 SYCL 內核。在這個頁面前面我們已經看過這樣的例子,讓我們來快速過一遍。
#include <vector>
#include <iostream>
#include <sycl/execution_policy>
#include <experimental/algorithm>
#include <sycl/helpers/sycl_buffers.hpp>
using namespace std::experimental::parallel;
using namespace sycl::helpers;
int main() {
constexpr size_t array_size = 1024*512;
std::array<cl::sycl::cl_int, array_size> in,out;
std::iota(begin(in),end(in),0);
{
cl::sycl::buffer<int> in_buffer(in.data(), cl::sycl::range<1>(in.size()));
cl::sycl::buffer<int> out_buffer(out.data(), cl::sycl::range<1>(out.size()));
cl::sycl::queue q;
sycl::sycl_execution_policy<class Mul> sycl_policy(q);
transform(sycl_policy, begin(in_buffer), end(in_buffer), begin(out_buffer),
[](int x) { return x*2; });
}
}
constexpr size_t array_size = 1024*512;
std::array<cl::sycl::cl_int, array_size> in, out;
std::iota(begin(in),end(in),0);
到現在為止一切如此相似。我們再一次創建一組數組用於保存我們的輸入輸出數據。
cl::sycl::buffer<int> in_buffer(in.data(), cl::sycl::range<1>(in.size()));
cl::sycl::buffer<int> out_buffer(out.data(), cl::sycl::range<1>(out.size()));
cl::sycl::queue q;
這裡我們創建類似上個例子的緩存和隊列。
sycl::sycl_execution_policy<class Mul> sycl_policy(q);
這就是有趣的部分。我們從我們的隊列中創建 sycl_execution_policy,給它一個名稱讓內核使用。這個執行策略然後可以像 std::execution::par 或 std::execution::seq 那樣使用。
transform(sycl_policy, begin(in_buffer), end(in_buffer), begin(out_buffer),
[](int x) { return x*2; });
現在我們的內核分發看起來像提供了一個執行策略的 std::transform 調用。我們傳遞的閉包會被編譯並在設備上執行,而不需要我們做其它更加複雜的設置。
當然,除了 transform 你可以做更多。開發的時候,SYCL 並行 STL 支持以下演算法:
sorttransformfor_eachfor_each_ncount_ifreduceinner_producttransform_reduce
這就是這篇短文需要介紹的東西。如果你想和 SYCL 的開發保持同步,那就要看 sycl.tech。最近重要的開發就是移植 Eigen 和 Tensorflow 到 SYCL ,為 OpenCL 設備帶來引入關注的人工智慧編程。對我個人而言,我很高興看到高級編程模型可以用於異構程序自動優化,以及它們是怎樣支持類似 HPX 或 SkelCL 等更高級的技術。
via: https://blog.tartanllama.xyz/c++/2017/05/19/sycl/
作者:TartanLlama 譯者:ictlyh 校對:wxy
本文轉載來自 Linux 中國: https://github.com/Linux-CN/archive
對這篇文章感覺如何?
You may also like






More in:Linux中國

捐贈 Let's Encrypt,共建安全的互聯網

Let's Encrypt 正式發布,已經保護 380 萬個域名

關於Linux防火牆iptables的面試問答

Lets Encrypt 已被所有主流瀏覽器所信任









