9 個鮮為人知的 Python 數據科學庫

Python 是一種令人驚嘆的語言。事實上,它是世界上增長最快的編程語言之一。它一次又一次地證明了它在各個行業的開發者和數據科學者中的作用。Python 及其庫的整個生態系統使其成為全世界用戶的恰當選擇,無論是初學者還是高級用戶。它成功和受歡迎的原因之一是它的一組強大的庫,使它如此動態和快速。
在本文中,我們將看到 Python 庫中的一些數據科學工具,而不是那些常用的工具,如 pandas、scikit-learn 和 matplotlib。雖然像 pandas、scikit-learn 這樣的庫是機器學習中最常想到的,但是了解這個領域的其他 Python 庫也是非常有幫助的。
Wget
提取數據,尤其是從網路中提取數據,是數據科學家的重要任務之一。Wget 是一個免費的工具,用於從網路上非互動式下載文件。它支持 HTTP、HTTPS 和 FTP 協議,以及通過 HTTP 代理進行訪問。因為它是非互動式的,所以即使用戶沒有登錄,它也可以在後台工作。所以下次你想下載一個網站或者網頁上的所有圖片,wget 會提供幫助。
安裝:
$ pip install wget例子:
import wget
url = 'http://www.futurecrew.com/skaven/song_files/mp3/razorback.mp3'
filename = wget.download(url)
100% [................................................] 3841532 / 3841532
filename
'razorback.mp3'鐘擺
對於在 Python 中處理日期時間感到沮喪的人來說, Pendulum 庫是很有幫助的。這是一個 Python 包,可以簡化日期時間操作。它是 Python 原生類的一個替代品。有關詳細信息,請參閱其文檔。
安裝:
$ pip install pendulum例子:
import pendulum
dt_toronto = pendulum.datetime(2012, 1, 1, tz='America/Toronto')
dt_vancouver = pendulum.datetime(2012, 1, 1, tz='America/Vancouver')
print(dt_vancouver.diff(dt_toronto).in_hours())
3不平衡學習
當每個類別中的樣本數幾乎相同(即平衡)時,大多數分類演算法會工作得最好。但是現實生活中的案例中充滿了不平衡的數據集,這可能會影響到機器學習演算法的學習和後續預測。幸運的是,imbalanced-learn 庫就是為了解決這個問題而創建的。它與 scikit-learn 兼容,並且是 scikit-learn-contrib 項目的一部分。下次遇到不平衡的數據集時,可以嘗試一下。
安裝:
pip install -U imbalanced-learn
# or
conda install -c conda-forge imbalanced-learn例子:
有關用法和示例,請參閱其文檔 。
FlashText
在自然語言處理(NLP)任務中清理文本數據通常需要替換句子中的關鍵詞或從句子中提取關鍵詞。通常,這種操作可以用正則表達式來完成,但是如果要搜索的術語數達到數千個,它們可能會變得很麻煩。
Python 的 FlashText 模塊,基於 FlashText 演算法,為這種情況提供了一個合適的替代方案。FlashText 的最佳部分是運行時間與搜索項的數量無關。你可以在其 文檔 中讀到更多關於它的信息。
安裝:
$ pip install flashtext例子:
提取關鍵詞:
from flashtext import KeywordProcessor
keyword_processor = KeywordProcessor()
# keyword_processor.add_keyword(<unclean name>, <standardised name>)
keyword_processor.add_keyword('Big Apple', 'New York')
keyword_processor.add_keyword('Bay Area')
keywords_found = keyword_processor.extract_keywords('I love Big Apple and Bay Area.')
keywords_found
['New York', 'Bay Area']替代關鍵詞:
keyword_processor.add_keyword('New Delhi', 'NCR region')
new_sentence = keyword_processor.replace_keywords('I love Big Apple and new delhi.')
new_sentence
'I love New York and NCR region.'有關更多示例,請參閱文檔中的 用法 一節。
模糊處理
這個名字聽起來很奇怪,但是 FuzzyWuzzy 在字元串匹配方面是一個非常有用的庫。它可以很容易地實現字元串匹配率、令牌匹配率等操作。對於匹配保存在不同資料庫中的記錄也很方便。
安裝:
$ pip install fuzzywuzzy例子:
from fuzzywuzzy import fuzz
from fuzzywuzzy import process
# 簡單的匹配率
fuzz.ratio("this is a test", "this is a test!")
97
# 部分的匹配率
fuzz.partial_ratio("this is a test", "this is a test!")
100更多的例子可以在 FuzzyWuzy 的 GitHub 倉庫得到。
PyFlux
時間序列分析是機器學習中最常遇到的問題之一。PyFlux 是 Python 中的開源庫,專門為處理時間序列問題而構建的。該庫擁有一系列優秀的現代時間序列模型,包括但不限於 ARIMA、GARCH 以及 VAR 模型。簡而言之,PyFlux 為時間序列建模提供了一種概率方法。這值得一試。
安裝:
pip install pyflux例子:
有關用法和示例,請參閱其 文檔。
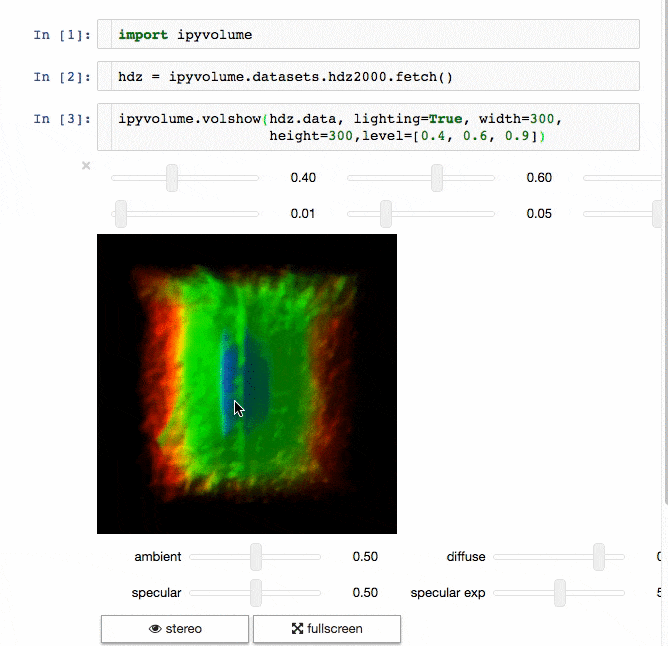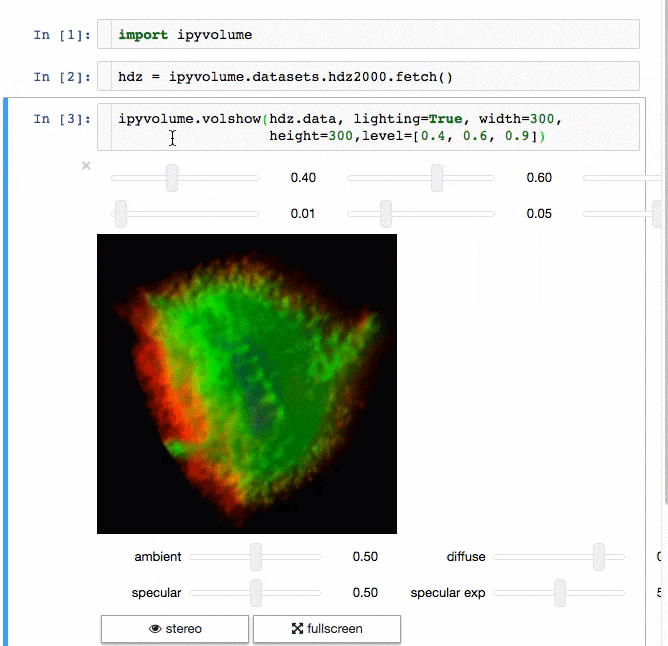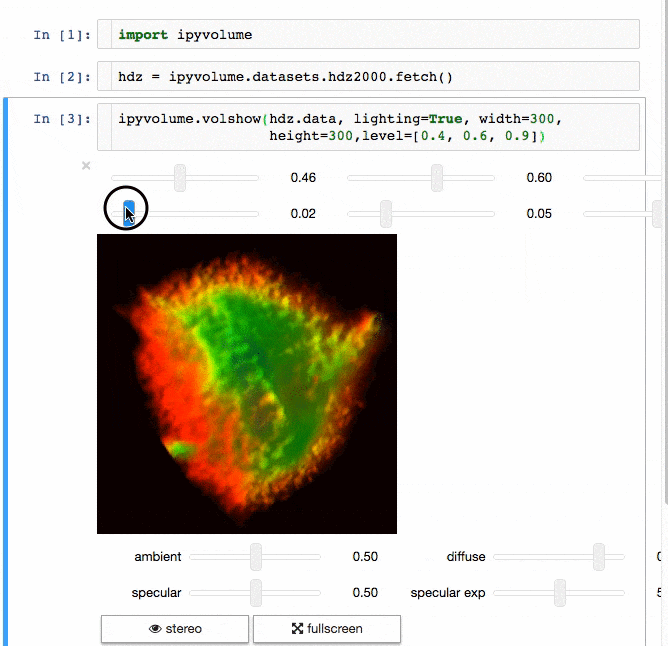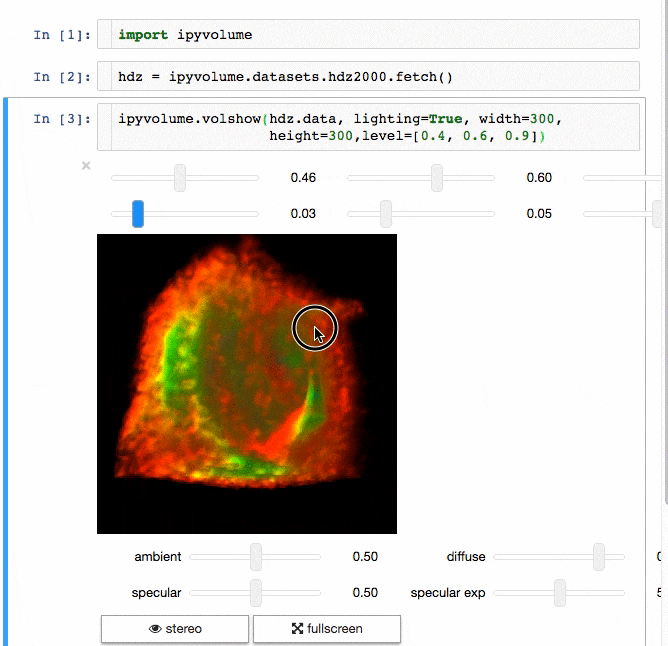
IPyvolume
交流結果是數據科學的一個重要方面,可視化結果提供了顯著優勢。 IPyvolume 是一個 Python 庫,用於在 Jupyter 筆記本中可視化 3D 體積和形狀(例如 3D 散點圖),配置和工作量極小。然而,它目前處於 1.0 之前的階段。一個很好的類比是這樣的: IPyVolumee volshow 是 3D 陣列,Matplotlib 的 imshow 是 2D 陣列。你可以在其 文檔 中讀到更多關於它的信息。
安裝:
Using pip
$ pip install ipyvolume
Conda/Anaconda
$ conda install -c conda-forge ipyvolume例子:
動畫:
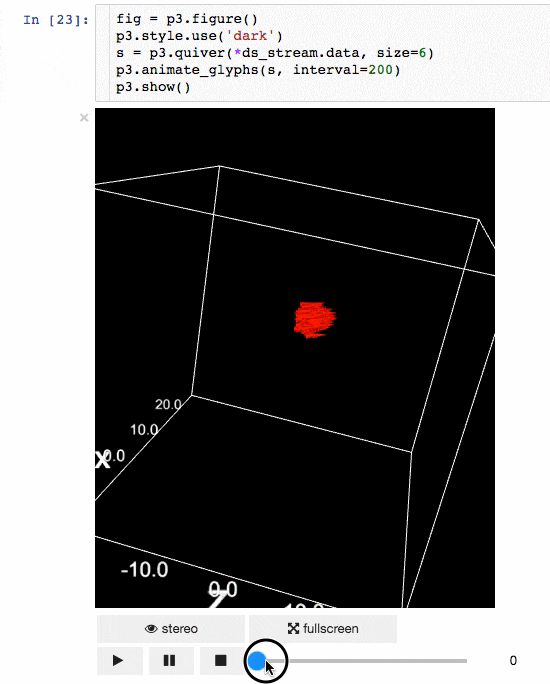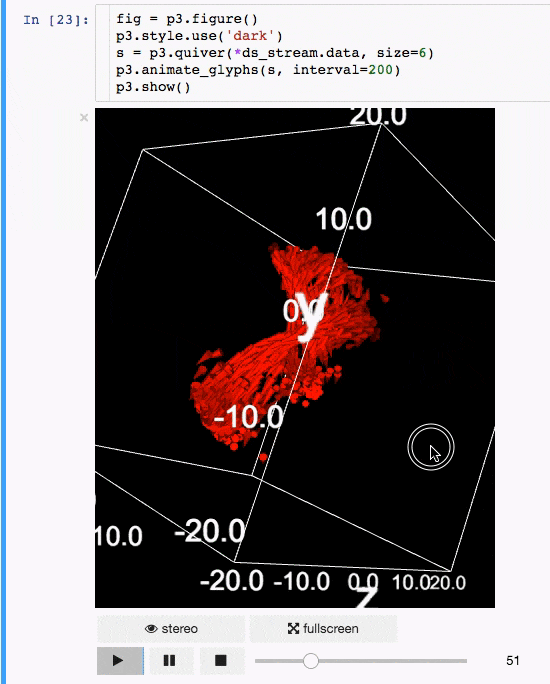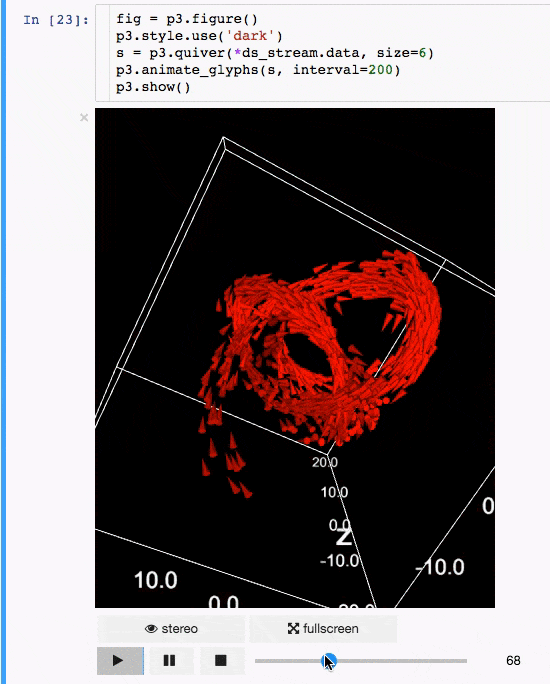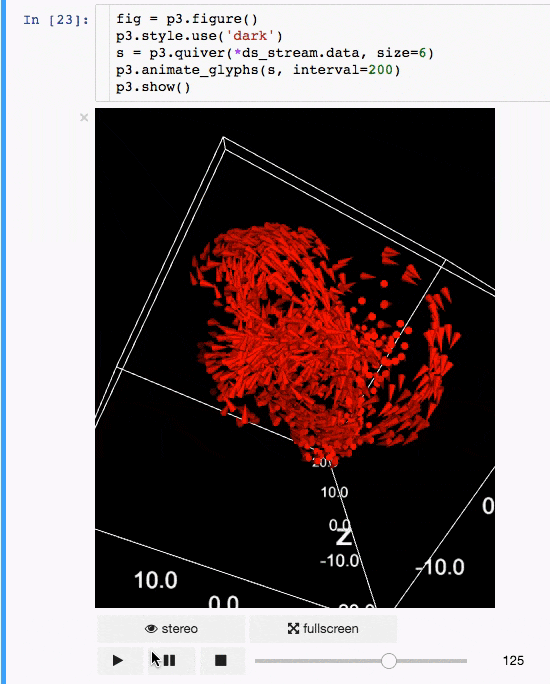
體繪製:
Dash
Dash 是一個用於構建 Web 應用程序的高效 Python 框架。它構建於 Flask、Plotty.js 和 Response.js 之上,將下拉菜單、滑塊和圖形等流行 UI 元素與你的 Python 分析代碼聯繫起來,而不需要JavaScript。Dash 非常適合構建可在 Web 瀏覽器中呈現的數據可視化應用程序。有關詳細信息,請參閱其 用戶指南 。
安裝:
pip install dash==0.29.0 # The core dash backend
pip install dash-html-components==0.13.2 # HTML components
pip install dash-core-components==0.36.0 # Supercharged components
pip install dash-table==3.1.3 # Interactive DataTable component (new!)例子:
下面的示例顯示了一個具有下拉功能的高度交互的圖表。當用戶在下拉列表中選擇一個值時,應用程序代碼將數據從 Google Finance 動態導出到 Pandas 數據框架中。
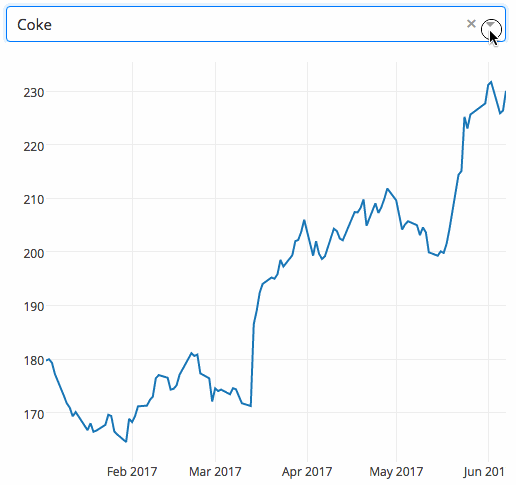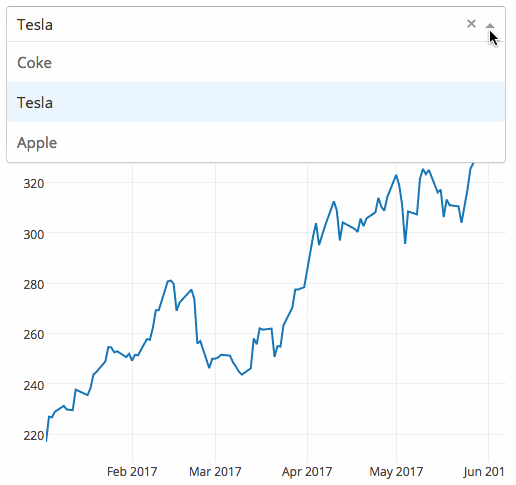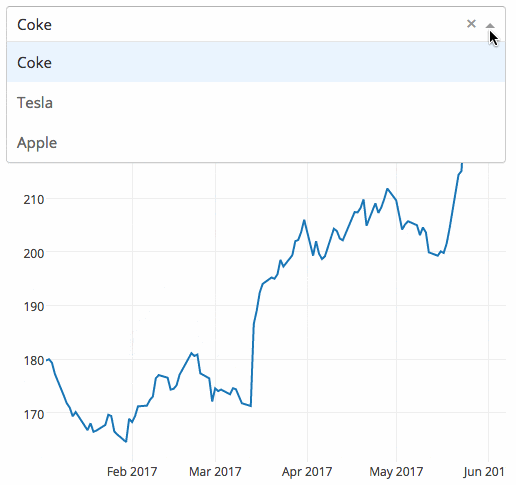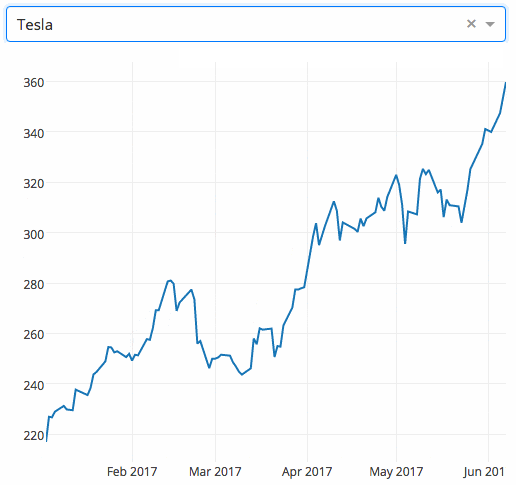
Gym
從 OpenAI 而來的 Gym 是開發和比較強化學習演算法的工具包。它與任何數值計算庫兼容,如 TensorFlow 或 Theano。Gym 是一個測試問題的集合,也稱為「環境」,你可以用它來制定你的強化學習演算法。這些環境有一個共享的介面,允許您編寫通用演算法。
安裝:
pip install gym例子:
以下示例將在 CartPole-v0 環境中,運行 1000 次,在每一步渲染環境。
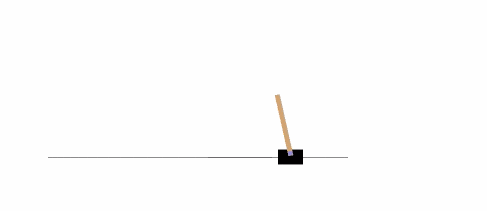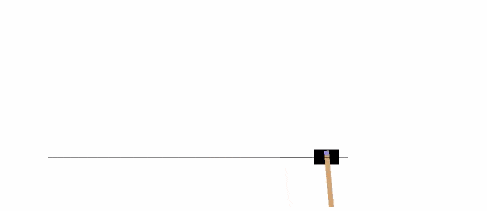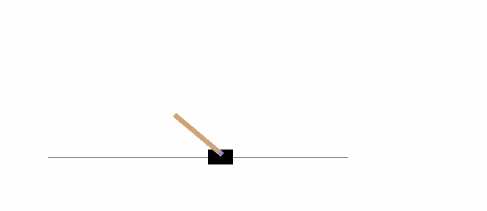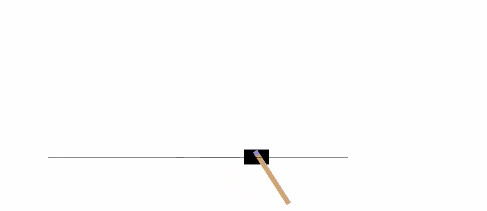
你可以在 Gym 網站上讀到 其它的環境 。
結論
這些是我挑選的有用但鮮為人知的數據科學 Python 庫。如果你知道另一個要添加到這個列表中,請在下面的評論中提及。
本文最初發表在 Analytics Vidhya 的媒體頻道上,並經許可轉載。
via: https://opensource.com/article/18/11/python-libraries-data-science
作者:Parul Pandey 選題:lujun9972 譯者:heguangzhi 校對:wxy
本文轉載來自 Linux 中國: https://github.com/Linux-CN/archive
對這篇文章感覺如何?
You may also like






More in:Linux中國

捐贈 Let's Encrypt,共建安全的互聯網

Let's Encrypt 正式發布,已經保護 380 萬個域名

關於Linux防火牆iptables的面試問答

Lets Encrypt 已被所有主流瀏覽器所信任









