7 個使用 bcc/BPF 的性能分析神器

在 Linux 中出現的一種新技術能夠為系統管理員和開發者提供大量用於性能分析和故障排除的新工具和儀錶盤。它被稱為 增強的伯克利數據包過濾器 (eBPF,或 BPF),雖然這些改進並不是由伯克利開發的,而且它們不僅僅是處理數據包,更多的是過濾。我將討論在 Fedora 和 Red Hat Linux 發行版中使用 BPF 的一種方法,並在 Fedora 26 上演示。
BPF 可以在內核中運行由用戶定義的沙盒程序,可以立即添加新的自定義功能。這就像按需給 Linux 系統添加超能力一般。 你可以使用它的例子包括如下:
- 高級性能跟蹤工具:對文件系統操作、TCP 事件、用戶級事件等的可編程的低開銷檢測。
- 網路性能: 儘早丟棄數據包以提高對 DDoS 的恢復能力,或者在內核中重定向數據包以提高性能。
- 安全監控: 7x24 小時的自定義檢測和記錄內核空間與用戶空間內的可疑事件。
在可能的情況下,BPF 程序必須通過一個內核驗證機制來保證它們的安全運行,這比寫自定義的內核模塊更安全。我在此假設大多數人並不編寫自己的 BPF 程序,而是使用別人寫好的。在 GitHub 上的 BPF Compiler Collection (bcc) 項目中,我已發布許多開源代碼。bcc 為 BPF 開發提供了不同的前端支持,包括 Python 和 Lua,並且是目前最活躍的 BPF 工具項目。
7 個有用的 bcc/BPF 新工具
為了了解 bcc/BPF 工具和它們的檢測內容,我創建了下面的圖表並添加到 bcc 項目中。
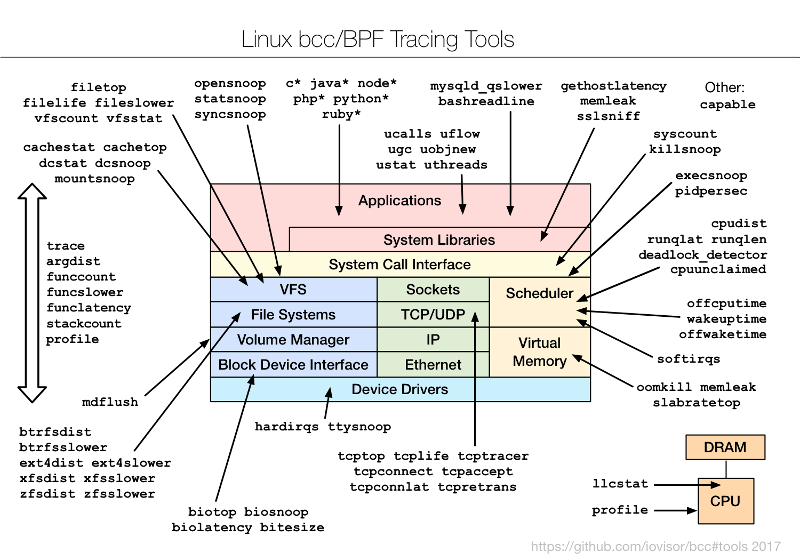
這些是命令行界面工具,你可以通過 SSH 使用它們。目前大多數分析,包括我的老闆,都是用 GUI 和儀錶盤進行的。SSH 是最後的手段。但這些命令行工具仍然是預覽 BPF 能力的好方法,即使你最終打算通過一個可用的 GUI 使用它。我已著手向一個開源 GUI 添加 BPF 功能,但那是另一篇文章的主題。現在我想向你分享今天就可以使用的 CLI 工具。
1、 execsnoop
從哪兒開始呢?如何查看新的進程。那些會消耗系統資源,但很短暫的進程,它們甚至不會出現在 top(1) 命令或其它工具中的顯示之中。這些新進程可以使用 execsnoop 進行檢測(或使用行業術語說,可以 被追蹤 )。 在追蹤時,我將在另一個窗口中通過 SSH 登錄:
# /usr/share/bcc/tools/execsnoop
PCOMM PID PPID RET ARGS
sshd 12234 727 0 /usr/sbin/sshd -D -R
unix_chkpwd 12236 12234 0 /usr/sbin/unix_chkpwd root nonull
unix_chkpwd 12237 12234 0 /usr/sbin/unix_chkpwd root chkexpiry
bash 12239 12238 0 /bin/bash
id 12241 12240 0 /usr/bin/id -un
hostname 12243 12242 0 /usr/bin/hostname
pkg-config 12245 12244 0 /usr/bin/pkg-config --variable=completionsdir bash-completion
grepconf.sh 12246 12239 0 /usr/libexec/grepconf.sh -c
grep 12247 12246 0 /usr/bin/grep -qsi ^COLOR.*none /etc/GREP_COLORS
tty 12249 12248 0 /usr/bin/tty -s
tput 12250 12248 0 /usr/bin/tput colors
dircolors 12252 12251 0 /usr/bin/dircolors --sh /etc/DIR_COLORS
grep 12253 12239 0 /usr/bin/grep -qi ^COLOR.*none /etc/DIR_COLORS
grepconf.sh 12254 12239 0 /usr/libexec/grepconf.sh -c
grep 12255 12254 0 /usr/bin/grep -qsi ^COLOR.*none /etc/GREP_COLORS
grepconf.sh 12256 12239 0 /usr/libexec/grepconf.sh -c
grep 12257 12256 0 /usr/bin/grep -qsi ^COLOR.*none /etc/GREP_COLORS
哇哦。 那是什麼? 什麼是 grepconf.sh? 什麼是 /etc/GREP_COLORS? 是 grep 在讀取它自己的配置文件……由 grep 運行的? 這究竟是怎麼工作的?
歡迎來到有趣的系統追蹤世界。 你可以學到很多關於系統是如何工作的(或者根本不工作,在有些情況下),並且發現一些簡單的優化方法。 execsnoop 通過跟蹤 exec() 系統調用來工作,exec() 通常用於在新進程中載入不同的程序代碼。
2、 opensnoop
接著上面繼續,所以,grepconf.sh 可能是一個 shell 腳本,對吧? 我將運行 file(1) 來檢查它,並使用opensnoop bcc 工具來查看打開的文件:
# /usr/share/bcc/tools/opensnoop
PID COMM FD ERR PATH
12420 file 3 0 /etc/ld.so.cache
12420 file 3 0 /lib64/libmagic.so.1
12420 file 3 0 /lib64/libz.so.1
12420 file 3 0 /lib64/libc.so.6
12420 file 3 0 /usr/lib/locale/locale-archive
12420 file -1 2 /etc/magic.mgc
12420 file 3 0 /etc/magic
12420 file 3 0 /usr/share/misc/magic.mgc
12420 file 3 0 /usr/lib64/gconv/gconv-modules.cache
12420 file 3 0 /usr/libexec/grepconf.sh
1 systemd 16 0 /proc/565/cgroup
1 systemd 16 0 /proc/536/cgroup
像 execsnoop 和 opensnoop 這樣的工具會將每個事件列印一行。上圖顯示 file(1) 命令當前打開(或嘗試打開)的文件:返回的文件描述符(「FD」 列)對於 /etc/magic.mgc 是 -1,而 「ERR」 列指示它是「文件未找到」。我不知道該文件,也不知道 file(1) 正在讀取的 /usr/share/misc/magic.mgc 文件是什麼。我不應該感到驚訝,但是 file(1) 在識別文件類型時沒有問題:
# file /usr/share/misc/magic.mgc /etc/magic
/usr/share/misc/magic.mgc: magic binary file for file(1) cmd (version 14) (little endian)
/etc/magic: magic text file for file(1) cmd, ASCII text
opensnoop 通過跟蹤 open() 系統調用來工作。為什麼不使用 strace -feopen file 命令呢? 在這種情況下是可以的。然而,opensnoop 的一些優點在於它能在系統範圍內工作,並且跟蹤所有進程的 open() 系統調用。注意上例的輸出中包括了從 systemd 打開的文件。opensnoop 應該系統開銷更低:BPF 跟蹤已經被優化過,而當前版本的 strace(1) 仍然使用較老和較慢的 ptrace(2) 介面。
3、 xfsslower
bcc/BPF 不僅僅可以分析系統調用。xfsslower 工具可以跟蹤大於 1 毫秒(參數)延遲的常見 XFS 文件系統操作。
# /usr/share/bcc/tools/xfsslower 1
Tracing XFS operations slower than 1 ms
TIME COMM PID T BYTES OFF_KB LAT(ms) FILENAME
14:17:34 systemd-journa 530 S 0 0 1.69 system.journal
14:17:35 auditd 651 S 0 0 2.43 audit.log
14:17:42 cksum 4167 R 52976 0 1.04 at
14:17:45 cksum 4168 R 53264 0 1.62 [
14:17:45 cksum 4168 R 65536 0 1.01 certutil
14:17:45 cksum 4168 R 65536 0 1.01 dir
14:17:45 cksum 4168 R 65536 0 1.17 dirmngr-client
14:17:46 cksum 4168 R 65536 0 1.06 grub2-file
14:17:46 cksum 4168 R 65536 128 1.01 grub2-fstest
[...]
在上圖輸出中,我捕獲到了多個延遲超過 1 毫秒 的 cksum(1) 讀取操作(欄位 「T」 等於 「R」)。這是在 xfsslower 工具運行的時候,通過在 XFS 中動態地檢測內核函數實現的,併當它結束的時候解除該檢測。這個 bcc 工具也有其它文件系統的版本:ext4slower、btrfsslower、zfsslower 和 nfsslower。
這是個有用的工具,也是 BPF 追蹤的重要例子。對文件系統性能的傳統分析主要集中在塊 I/O 統計信息 —— 通常你看到的是由 iostat(1) 工具輸出,並由許多性能監視 GUI 繪製的圖表。這些統計數據顯示的是磁碟如何執行,而不是真正的文件系統如何執行。通常比起磁碟來說,你更關心的是文件系統的性能,因為應用程序是在文件系統中發起請求和等待。並且,文件系統的性能可能與磁碟的性能大為不同!文件系統可以完全從內存緩存中讀取數據,也可以通過預讀演算法和回寫緩存來填充緩存。xfsslower 顯示了文件系統的性能 —— 這是應用程序直接體驗到的性能。通常這對於排除整個存儲子系統的問題是有用的;如果確實沒有文件系統延遲,那麼性能問題很可能是在別處。
4、 biolatency
雖然文件系統性能對於理解應用程序性能非常重要,但研究磁碟性能也是有好處的。當各種緩存技巧都無法挽救其延遲時,磁碟的低性能終會影響應用程序。 磁碟性能也是容量規劃研究的目標。
iostat(1) 工具顯示了平均磁碟 I/O 延遲,但平均值可能會引起誤解。 以直方圖的形式研究 I/O 延遲的分布是有用的,這可以通過使用 [biolatency] 來實現18:
# /usr/share/bcc/tools/biolatency
Tracing block device I/O... Hit Ctrl-C to end.
^C
usecs : count distribution
0 -> 1 : 0 | |
2 -> 3 : 0 | |
4 -> 7 : 0 | |
8 -> 15 : 0 | |
16 -> 31 : 0 | |
32 -> 63 : 1 | |
64 -> 127 : 63 |**** |
128 -> 255 : 121 |********* |
256 -> 511 : 483 |************************************ |
512 -> 1023 : 532 |****************************************|
1024 -> 2047 : 117 |******** |
2048 -> 4095 : 8 | |
這是另一個有用的工具和例子;它使用一個名為 maps 的 BPF 特性,它可以用來實現高效的內核摘要統計。從內核層到用戶層的數據傳輸僅僅是「計數」列。 用戶級程序生成其餘的。
值得注意的是,這種工具大多支持 CLI 選項和參數,如其使用信息所示:
# /usr/share/bcc/tools/biolatency -h
usage: biolatency [-h] [-T] [-Q] [-m] [-D] [interval] [count]
Summarize block device I/O latency as a histogram
positional arguments:
interval output interval, in seconds
count number of outputs
optional arguments:
-h, --help show this help message and exit
-T, --timestamp include timestamp on output
-Q, --queued include OS queued time in I/O time
-m, --milliseconds millisecond histogram
-D, --disks print a histogram per disk device
examples:
./biolatency # summarize block I/O latency as a histogram
./biolatency 1 10 # print 1 second summaries, 10 times
./biolatency -mT 1 # 1s summaries, milliseconds, and timestamps
./biolatency -Q # include OS queued time in I/O time
./biolatency -D # show each disk device separately
它們的行為就像其它 Unix 工具一樣,以利於採用而設計。
5、 tcplife
另一個有用的工具是 tcplife ,該例顯示 TCP 會話的生命周期和吞吐量統計。
# /usr/share/bcc/tools/tcplife
PID COMM LADDR LPORT RADDR RPORT TX_KB RX_KB MS
12759 sshd 192.168.56.101 22 192.168.56.1 60639 2 3 1863.82
12783 sshd 192.168.56.101 22 192.168.56.1 60640 3 3 9174.53
12844 wget 10.0.2.15 34250 54.204.39.132 443 11 1870 5712.26
12851 curl 10.0.2.15 34252 54.204.39.132 443 0 74 505.90
在你說 「我不是可以只通過 tcpdump(8) 就能輸出這個?」 之前請注意,運行 tcpdump(8) 或任何數據包嗅探器,在高數據包速率的系統上的開銷會很大,即使 tcpdump(8) 的用戶層和內核層機制已經過多年優化(要不可能更差)。tcplife 不會測試每個數據包;它只會有效地監視 TCP 會話狀態的變化,並由此得到該會話的持續時間。它還使用已經跟蹤了吞吐量的內核計數器,以及進程和命令信息(「PID」 和 「COMM」 列),這些對於 tcpdump(8) 等線上嗅探工具是做不到的。
6、 gethostlatency
之前的每個例子都涉及到內核跟蹤,所以我至少需要一個用戶級跟蹤的例子。 這就是 gethostlatency,它檢測用於名稱解析的 gethostbyname(3) 和相關的庫調用:
# /usr/share/bcc/tools/gethostlatency
TIME PID COMM LATms HOST
06:43:33 12903 curl 188.98 opensource.com
06:43:36 12905 curl 8.45 opensource.com
06:43:40 12907 curl 6.55 opensource.com
06:43:44 12911 curl 9.67 opensource.com
06:45:02 12948 curl 19.66 opensource.cats
06:45:06 12950 curl 18.37 opensource.cats
06:45:07 12952 curl 13.64 opensource.cats
06:45:19 13139 curl 13.10 opensource.cats
是的,總是有 DNS 請求,所以有一個工具來監視系統範圍內的 DNS 請求會很方便(這隻有在應用程序使用標準系統庫時才有效)。看看我如何跟蹤多個對 「opensource.com」 的查找? 第一個是 188.98 毫秒,然後更快,不到 10 毫秒,毫無疑問,這是緩存的作用。它還追蹤多個對 「opensource.cats」 的查找,一個不存在的可憐主機名,但我們仍然可以檢查第一個和後續查找的延遲。(第二次查找後是否有一些否定緩存的影響?)
7、 trace
好的,再舉一個例子。 trace 工具由 Sasha Goldshtein 提供,並提供了一些基本的 printf(1) 功能和自定義探針。 例如:
# /usr/share/bcc/tools/trace 'pam:pam_start "%s: %s", arg1, arg2'
PID TID COMM FUNC -
13266 13266 sshd pam_start sshd: root
在這裡,我正在跟蹤 libpam 及其 pam_start(3) 函數,並將其兩個參數都列印為字元串。 libpam 用於插入式身份驗證模塊系統,該輸出顯示 sshd 為 「root」 用戶調用了 pam_start()(我登錄了)。 其使用信息中有更多的例子(trace -h),而且所有這些工具在 bcc 版本庫中都有手冊頁和示例文件。 例如 trace_example.txt 和 trace.8。
通過包安裝 bcc
安裝 bcc 最佳的方法是從 iovisor 倉儲庫中安裝,按照 bcc 的 INSTALL.md 進行即可。IO Visor 是包括了 bcc 的 Linux 基金會項目。4.x 系列 Linux 內核中增加了這些工具所使用的 BPF 增強功能,直到 4.9 添加了全部支持。這意味著擁有 4.8 內核的 Fedora 25 可以運行這些工具中的大部分。 使用 4.11 內核的 Fedora 26 可以全部運行它們(至少在目前是這樣)。
如果你使用的是 Fedora 25(或者 Fedora 26,而且這個帖子已經在很多個月前發布了 —— 你好,來自遙遠的過去!),那麼這個通過包安裝的方式是可以工作的。 如果您使用的是 Fedora 26,那麼請跳至「通過源代碼安裝」部分,它避免了一個已修復的的已知錯誤。 這個錯誤修複目前還沒有進入 Fedora 26 軟體包的依賴關係。 我使用的系統是:
# uname -a
Linux localhost.localdomain 4.11.8-300.fc26.x86_64 #1 SMP Thu Jun 29 20:09:48 UTC 2017 x86_64 x86_64 x86_64 GNU/Linux
# cat /etc/fedora-release
Fedora release 26 (Twenty Six)
以下是我所遵循的安裝步驟,但請參閱 INSTALL.md 獲取更新的版本:
# echo -e '[iovisor]nbaseurl=https://repo.iovisor.org/yum/nightly/f25/$basearchnenabled=1ngpgcheck=0' | sudo tee /etc/yum.repos.d/iovisor.repo
# dnf install bcc-tools
[...]
Total download size: 37 M
Installed size: 143 M
Is this ok [y/N]: y
安裝完成後,您可以在 /usr/share 中看到新的工具:
# ls /usr/share/bcc/tools/
argdist dcsnoop killsnoop softirqs trace
bashreadline dcstat llcstat solisten ttysnoop
[...]
試著運行其中一個:
# /usr/share/bcc/tools/opensnoop
chdir(/lib/modules/4.11.8-300.fc26.x86_64/build): No such file or directory
Traceback (most recent call last):
File "/usr/share/bcc/tools/opensnoop", line 126, in
b = BPF(text=bpf_text)
File "/usr/lib/python3.6/site-packages/bcc/__init__.py", line 284, in __init__
raise Exception("Failed to compile BPF module %s" % src_file)
Exception: Failed to compile BPF module
運行失敗,提示 /lib/modules/4.11.8-300.fc26.x86_64/build 丟失。 如果你也遇到這個問題,那只是因為系統缺少內核頭文件。 如果你看看這個文件指向什麼(這是一個符號鏈接),然後使用 dnf whatprovides 來搜索它,它會告訴你接下來需要安裝的包。 對於這個系統,它是:
# dnf install kernel-devel-4.11.8-300.fc26.x86_64
[...]
Total download size: 20 M
Installed size: 63 M
Is this ok [y/N]: y
[...]
現在:
# /usr/share/bcc/tools/opensnoop
PID COMM FD ERR PATH
11792 ls 3 0 /etc/ld.so.cache
11792 ls 3 0 /lib64/libselinux.so.1
11792 ls 3 0 /lib64/libcap.so.2
11792 ls 3 0 /lib64/libc.so.6
[...]
運行起來了。 這是捕獲自另一個窗口中的 ls 命令活動。 請參閱前面的部分以使用其它有用的命令。
通過源碼安裝
如果您需要從源代碼安裝,您還可以在 INSTALL.md 中找到文檔和更新說明。 我在 Fedora 26 上做了如下的事情:
sudo dnf install -y bison cmake ethtool flex git iperf libstdc++-static
python-netaddr python-pip gcc gcc-c++ make zlib-devel
elfutils-libelf-devel
sudo dnf install -y luajit luajit-devel # for Lua support
sudo dnf install -y
http://pkgs.repoforge.org/netperf/netperf-2.6.0-1.el6.rf.x86_64.rpm
sudo pip install pyroute2
sudo dnf install -y clang clang-devel llvm llvm-devel llvm-static ncurses-devel
除 netperf 外一切妥當,其中有以下錯誤:
Curl error (28): Timeout was reached for http://pkgs.repoforge.org/netperf/netperf-2.6.0-1.el6.rf.x86_64.rpm [Connection timed out after 120002 milliseconds]
不必理會,netperf 是可選的,它只是用於測試,而 bcc 沒有它也會編譯成功。
以下是餘下的 bcc 編譯和安裝步驟:
git clone https://github.com/iovisor/bcc.git
mkdir bcc/build; cd bcc/build
cmake .. -DCMAKE_INSTALL_PREFIX=/usr
make
sudo make install
現在,命令應該可以工作了:
# /usr/share/bcc/tools/opensnoop
PID COMM FD ERR PATH
4131 date 3 0 /etc/ld.so.cache
4131 date 3 0 /lib64/libc.so.6
4131 date 3 0 /usr/lib/locale/locale-archive
4131 date 3 0 /etc/localtime
[...]
寫在最後和其他的前端
這是一個可以在 Fedora 和 Red Hat 系列操作系統上使用的新 BPF 性能分析強大功能的快速瀏覽。我演示了 BPF 的流行前端 bcc ,並包括了其在 Fedora 上的安裝說明。bcc 附帶了 60 多個用於性能分析的新工具,這將幫助您充分利用 Linux 系統。也許你會直接通過 SSH 使用這些工具,或者一旦 GUI 監控程序支持 BPF 的話,你也可以通過它們來使用相同的功能。
此外,bcc 並不是正在開發的唯一前端。ply 和 bpftrace,旨在為快速編寫自定義工具提供更高級的語言支持。此外,SystemTap 剛剛發布版本 3.2,包括一個早期的實驗性 eBPF 後端。 如果這個繼續開發,它將為運行多年來開發的許多 SystemTap 腳本和 tapset(庫)提供一個安全和高效的生產級引擎。(隨同 eBPF 使用 SystemTap 將是另一篇文章的主題。)
如果您需要開發自定義工具,那麼也可以使用 bcc 來實現,儘管語言比 SystemTap、ply 或 bpftrace 要冗長得多。我的 bcc 工具可以作為代碼示例,另外我還貢獻了用 Python 開發 bcc 工具的教程。 我建議先學習 bcc 的 multi-tools,因為在需要編寫新工具之前,你可能會從裡面獲得很多經驗。 您可以從它們的 bcc 存儲庫funccount,funclatency,funcslower,stackcount,trace ,argdist 的示例文件中研究 bcc。
感謝 Opensource.com 進行編輯。
關於作者
Brendan Gregg 是 Netflix 的一名高級性能架構師,在那裡他進行大規模的計算機性能設計、分析和調優。
via:https://opensource.com/article/17/11/bccbpf-performance
作者:Brendan Gregg 譯者:yongshouzhang 校對:wxy
本文轉載來自 Linux 中國: https://github.com/Linux-CN/archive
對這篇文章感覺如何?
You may also like






More in:Linux中國

捐贈 Let's Encrypt,共建安全的互聯網

Let's Encrypt 正式發布,已經保護 380 萬個域名

關於Linux防火牆iptables的面試問答

Lets Encrypt 已被所有主流瀏覽器所信任









