60 TB 數據:Facebook 是如何大規模使用 Apache Spark 的

Facebook 經常使用數據驅動的分析方法來做決策。在過去的幾年,用戶和產品的增長已經需要我們的分析工程師一次查詢就要操作數十 TB 大小的數據集。我們的一些批量分析執行在古老的 Hive 平台( Apache Hive 由 Facebook 貢獻於 2009 年)和 Corona 上——這是我們定製的 MapReduce 實現。Facebook 還不斷增加其對 Presto 的用量,用於對幾個包括 Hive 在內的內部數據存儲的 ANSI-SQL 查詢。我們也支持其他分析類型,比如 圖資料庫處理 和機器學習(Apache Giraph)和流(例如:Puma、Swift 和 Stylus)。
同時 Facebook 的各種產品涵蓋了廣泛的分析領域,我們與開源社區不斷保持溝通,以便共享我們的經驗並從其他人那裡學習。Apache Spark 於 2009 年在加州大學伯克利分校的 AMPLab 由 Matei Zaharia 發起,後來在2013 年貢獻給 Apache。它是目前增長最快的數據處理平台之一,由於它能支持流、批量、命令式(RDD)、聲明式(SQL)、圖資料庫和機器學習等用例,而且所有這些都內置在相同的 API 和底層計算引擎中。Spark 可以有效地利用更大量級的內存,優化整個 流水線 中的代碼,並跨任務重用 JVM 以獲得更好的性能。最近我們感覺 Spark 已經成熟,我們可以在一些批量處理用例方面把它與 Hive 相比較。在這篇文章其餘的部分,我們講述了在擴展 Spark 來替代我們一個 Hive 工作任務時的所得到經驗和學習到的教訓。
用例:實體排名的特徵準備
Facebook 會以多種方式做實時的 實體 排名。對於一些在線服務平台,原始特徵值是由 Hive 線下生成的,然後將數據載入到實時關聯查詢系統。我們在幾年前建立的基於 Hive 的老式基礎設施屬於計算資源密集型,且很難維護,因為其流水線被劃分成數百個較小的 Hive 任務。為了可以使用更加新的特徵數據和提升可管理性,我們拿一個現有的流水線試著將其遷移至 Spark。
以前的 Hive 實現
基於 Hive 的流水線由三個邏輯 階段 組成,每個階段對應由 entity_id 劃分的數百個較小的 Hive 作業,因為在每個階段運行大型 Hive 作業 不太可靠,並受到每個作業的最大 任務 數量的限制。
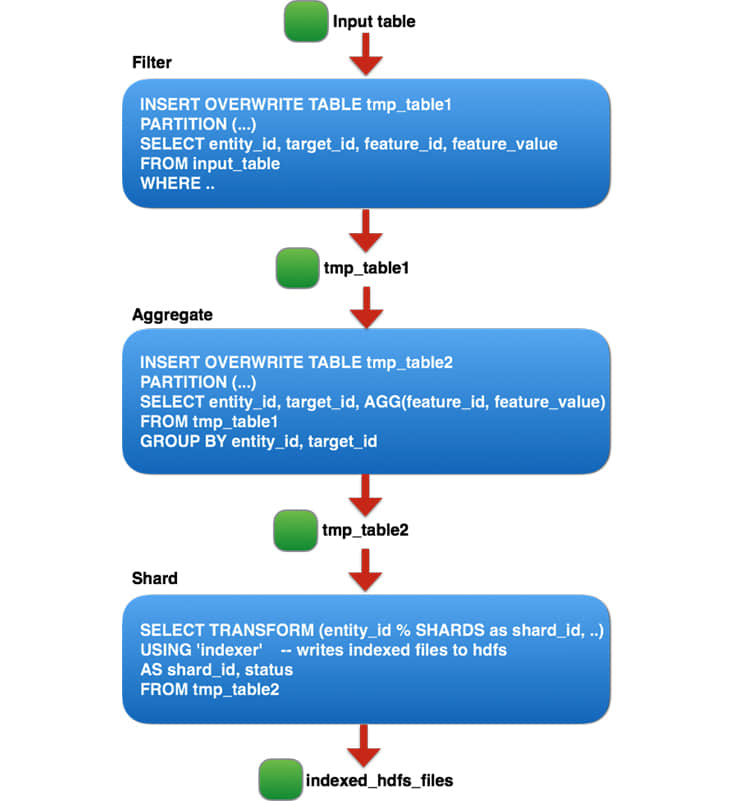
這三個邏輯階段可以總結如下:
- 過濾出非產品的特徵和噪點。
- 在每個(entity_id, target_id)對上進行聚合。
- 將表格分割成 N 個分片,並通過自定義二進位文件管理每個分片,以生成用於在線查詢的自定義索引文件。
基於 Hive 的流水線建立該索引大概要三天完成。它也難於管理,因為該流水線包含上百個分片的作業,使監控也變得困難。同時也沒有好的方法來估算流水線進度或計算剩餘時間。考慮到 Hive 流水線的上述限制,我們決定建立一個更快、更易於管理的 Spark 流水線。
Spark 實現
全量的調試會很慢,有挑戰,而且是資源密集型的。我們從轉換基於 Hive 流水線的最資源密集型的第二階段開始。我們以一個 50GB 的壓縮輸入例子開始,然後逐漸擴展到 300GB、1TB,然後到 20TB。在每次規模增長時,我們都解決了性能和穩定性問題,但是實驗到 20TB 時,我們發現了最大的改善機會。
運行 20TB 的輸入時,我們發現,由於大量的任務導致我們生成了太多輸出文件(每個大小在 100MB 左右)。在 10 小時的作業運行時中,有三分之一是用在將文件從階段目錄移動到 HDFS 中的最終目錄。起初,我們考慮兩個方案:要麼改善 HDFS 中的批量重命名來支持我們的用例,或者配置 Spark 生成更少的輸出文件(這很難,由於在這一步有大量的任務 — 70000 個)。我們退一步來看這個問題,考慮第三種方案。由於我們在流水線的第二步中生成的 tmp_table2 表是臨時的,僅用於存儲流水線的中間輸出,所以對於 TB 級數據的單一讀取作業任務,我們基本上是在壓縮、序列化和複製三個副本。相反,我們更進一步:移除兩個臨時表並整合 Hive 過程的所有三個部分到一個單獨的 Spark 作業,讀取 60TB 的壓縮數據然後對 90TB 的數據執行 重排 和 排序 。最終的 Spark 作業如下:
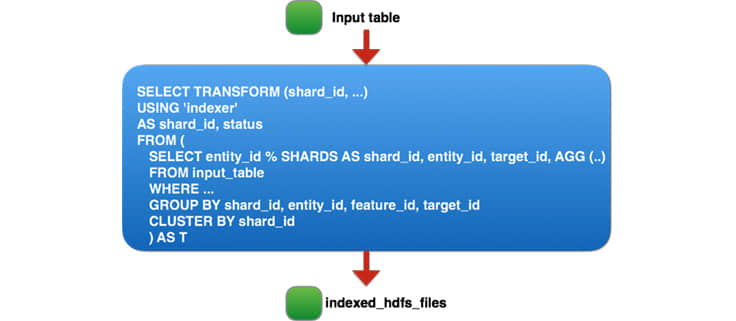
對於我們的作業如何規劃 Spark?
當然,為如此大的流水線運行一個單獨的 Spark 任務,第一次嘗試沒有成功,甚至是第十次嘗試也沒有。據我們所知,從 重排 的數據大小來說,這是現實世界最大的 Spark 作業(Databrick 的 PB 級排序是以合成數據來說)。我們對核心 Spark 基礎架構和我們的應用程序進行了許多改進和優化使這個作業得以運行。這種努力的優勢在於,許多這些改進適用於 Spark 的其他大型作業任務,我們將所有的工作回饋給開源 Apache Spark 項目 - 有關詳細信息請參閱 JIRA。下面,我們將重點講述將實體排名流水線之一部署到生產環境所做的重大改進。
可靠性修復
處理頻繁的節點重啟
為了可靠地執行長時間運行作業,我們希望系統能夠容錯並可以從故障中恢復(主要是由於平時的維護或軟體錯誤導致的機器重啟所引發的)。雖然 Spark 設計為可以容忍機器重啟,但我們發現它在足夠強健到可以處理常見故障之前還有各種錯誤/問題需要解決。
- 使 PipedRDD 穩健的 獲取 失敗(SPARK-13793):PipedRDD 以前的實現不夠強大,無法處理由於節點重啟而導致的獲取失敗,並且只要出現獲取失敗,該作業就會失敗。我們在 PipedRDD 中進行了更改,優雅的處理獲取失敗,使該作業可以從這種類型的獲取失敗中恢復。
- 可配置的最大獲取失敗次數(SPARK-13369):對於這種長時間運行的作業,由於機器重啟而引起的獲取失敗概率顯著增加。在 Spark 中每個階段的最大允許的獲取失敗次數是硬編碼的,因此,當達到最大數量時該作業將失敗。我們做了一個改變,使它是可配置的,並且在這個用例中將其從 4 增長到 20,從而使作業更穩健。
- 減少集群重啟混亂:長時間運行作業應該可以在集群重啟後存留,所以我們不用等著處理完成。Spark 的可重啟的 重排 服務功能可以使我們在節點重啟後保留 重排 文件。最重要的是,我們在 Spark 驅動程序中實現了一項功能,可以暫停執行任務調度,所以不會由於集群重啟而導致的過多的任務失敗,從而導致作業失敗。
其他的可靠性修復
- 響應遲鈍的驅動程序(SPARK-13279):在添加任務時,由於 O(N ^ 2) 複雜度的操作,Spark 驅動程序被卡住,導致該作業最終被卡住和死亡。 我們通過刪除不必要的 O(N ^ 2) 操作來修復問題。
- 過多的驅動 推測 :我們發現,Spark 驅動程序在管理大量任務時花費了大量的時間推測。 在短期內,我們禁止這個作業的推測。在長期,我們正在努力改變 Spark 驅動程序,以減少推測時間。
- 由於大型緩衝區的整數溢出導致的 TimSort 問題(SPARK-13850):我們發現 Spark 的不安全內存操作有一個漏洞,導致 TimSort 中的內存損壞。 感謝 Databricks 的人解決了這個問題,這使我們能夠在大內存緩衝區中運行。
- 調整重排(shuffle)服務來處理大量連接:在重排階段,我們看到許多執行程序在嘗試連接重排服務時超時。 增加 Netty 伺服器的線程(spark.shuffle.io.serverThreads)和積壓(spark.shuffle.io.backLog)的數量解決了這個問題。
- 修復 Spark 執行程序 OOM(SPARK-13958)(deal maker):首先在每個主機上打包超過四個 聚合 任務是很困難的。Spark 執行程序會內存溢出,因為排序程序(sorter)中存在導致無限增長的指針數組的漏洞。當不再有可用的內存用於指針數組增長時,我們通過強制將數據溢出到磁碟來修復問題。因此,現在我們可以每主機運行 24 個任務,而不會內存溢出。
性能改進
在實施上述可靠性改進後,我們能夠可靠地運行 Spark 作業了。基於這一點,我們將精力轉向與性能相關的項目,以充分發揮 Spark 的作用。我們使用 Spark 的指標和幾個分析器來查找一些性能瓶頸。
我們用來查找性能瓶頸的工具
- Spark UI 指標:Spark UI 可以很好地了解在特定階段所花費的時間。每個任務的執行時間被分為子階段,以便更容易地找到作業中的瓶頸。
- Jstack:Spark UI 還在執行程序進程上提供了一個按需分配的 jstack 函數,可用於中查找熱點代碼。
- Spark 的 Linux Perf / 火焰圖 支持:儘管上述兩個工具非常方便,但它們並不提供同時在數百台機器上運行的作業的 CPU 分析的聚合視圖。在每個作業的基礎上,我們添加了支持 Perf 分析(通過 libperfagent 的 Java 符號),並可以自定義採樣的持續時間/頻率。使用我們的內部指標收集框架,將分析樣本聚合併顯示為整個執行程序的火焰圖。
性能優化
- 修復 排序程序 中的內存泄漏(SPARK-14363)(30% 速度提升):我們發現了一個問題,當任務釋放所有內存頁時指針數組卻未被釋放。 因此,大量的內存未被使用,並導致頻繁的溢出和執行程序 OOM。 我們現在進行了改變,正確地釋放內存,並使大的分類運行更有效。 我們注意到,這一變化後 CPU 改善了 30%。
- Snappy 優化(SPARK-14277)(10% 速度提升):有個 JNI 方法(Snappy.ArrayCopy)在每一行被讀取/寫入時都會被調用。 我們發現了這個問題,Snappy 的行為被改為使用非 JNI 的 System.ArrayCopy 代替。 這一改變節約了大約 10% 的 CPU。
- 減少重排的寫入延遲(SPARK-5581)(高達 50% 的速度提升):在 映射 方面,當將重排數據寫入磁碟時,映射任務為每個分區打開並關閉相同的文件。 我們做了一個修復,以避免不必要的打開/關閉,對於大量寫入重排分區的作業來說,我們觀察到高達 50% 的 CPU 提升。
- 解決由於獲取失敗導致的重複任務運行問題(SPARK-14649):當獲取失敗發生時,Spark 驅動程序會重新提交已運行的任務,導致性能下降。 我們通過避免重新運行運行的任務來解決這個問題,我們看到當獲取失敗發生時該作業會更加穩定。
- 可配置 PipedRDD 的緩衝區大小(SPARK-14542)(10% 速度提升):在使用 PipedRDD 時,我們發現將數據從分類程序傳輸到管道進程的默認緩衝區的大小太小,我們的作業要花費超過 10% 的時間複製數據。我們使緩衝區大小可配置,以避免這個瓶頸。
- 緩存索引文件以加速重排獲取(SPARK-15074):我們觀察到重排服務經常成為瓶頸, 減少程序 花費 10% 至 15% 的時間等待獲取 映射 數據。通過深入了解問題,我們發現,重排服務為每個重排獲取打開/關閉重排索引文件。我們進行了更改以緩存索引信息,以便我們可以避免文件打開/關閉,並重新使用該索引信息以便後續獲取。這個變化將總的重排時間減少了 50%。
- 降低重排位元組寫入指標的更新頻率(SPARK-15569)(高達 20% 的速度提升):使用 Spark 的 Linux Perf 集成,我們發現大約 20% 的 CPU 時間正在花費探測和更新寫入的重排位元組寫入指標上。
- 可配置排序程序(sorter)的初始緩衝區大小(SPARK-15958)(高達 5% 的速度提升): 排序程序 的默認初始緩衝區大小太小(4 KB),我們發現它對於大型工作負載而言非常小 - 所以我們在緩衝區耗盡和內容複製上浪費了大量的時間。我們做了一個更改,使緩衝區大小可配置,並且緩衝區大小為 64 MB,我們可以避免大量的數據複製,使作業的速度提高約 5%。
- 配置任務數量:由於我們的輸入大小為 60T,每個 HDFS 塊大小為 256M,因此我們為該作業產生了超過 250,000 個任務。儘管我們能夠以如此多的任務來運行 Spark 作業,但是我們發現,當任務數量過高時,性能會下降。我們引入了一個配置參數,使 映射 輸入大小可配置,因此我們可以通過將輸入分割大小設置為 2 GB 來將該數量減少 8 倍。
在所有這些可靠性和性能改進之後,我們很高興地報告,我們為我們的實體排名系統之一構建和部署了一個更快、更易於管理的流水線,並且我們提供了在 Spark 中運行其他類似作業的能力。
Spark 流水線與 Hive 流水線性能對比
我們使用以下性能指標來比較 Spark 流水線與 Hive 流水線。請注意,這些數字並不是在查詢或作業級別的直接比較 Spark 與 Hive ,而是比較使用靈活的計算引擎(例如 Spark)構建優化的流水線,而不是比較僅在查詢/作業級別(如 Hive)操作的計算引擎。
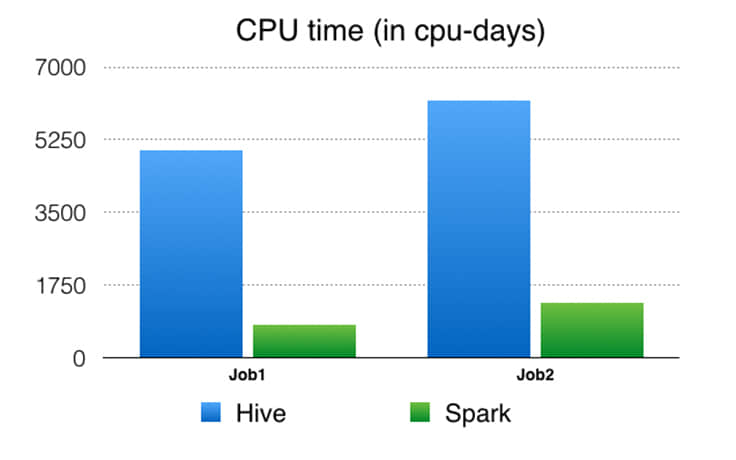
CPU 時間:這是從系統角度看 CPU 使用。例如,你在一個 32 核機器上使用 50% 的 CPU 10 秒運行一個單進程任務,然後你的 CPU 時間應該是 32 0.5 10 = 160 CPU 秒。
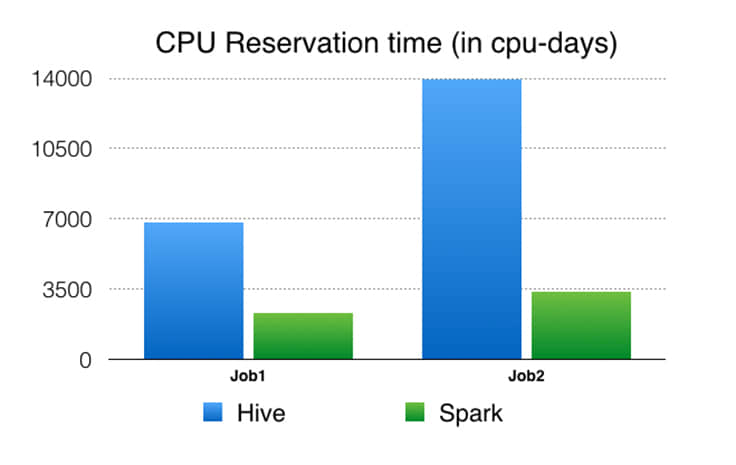
CPU 預留時間:這是從資源管理框架的角度來看 CPU 預留。例如,如果我們保留 32 位機器 10 秒鐘來運行作業,則CPU 預留時間為 32 * 10 = 320 CPU 秒。CPU 時間與 CPU 預留時間的比率反映了我們如何在集群上利用預留的CPU 資源。當準確時,與 CPU 時間相比,預留時間在運行相同工作負載時可以更好地比較執行引擎。例如,如果一個進程需要 1 個 CPU 的時間才能運行,但是必須保留 100 個 CPU 秒,則該指標的效率要低於需要 10 個 CPU 秒而僅保留 10 個 CPU 秒來執行相同的工作量的進程。我們還計算內存預留時間,但不包括在這裡,因為其數字類似於 CPU 預留時間,因為在同一硬體上運行實驗,而在 Spark 和 Hive 的情況下,我們不會將數據緩存在內存中。Spark 有能力在內存中緩存數據,但是由於我們的集群內存限制,我們決定類似與 Hive 一樣工作在核心外部。
等待時間:端到端的工作流失時間。
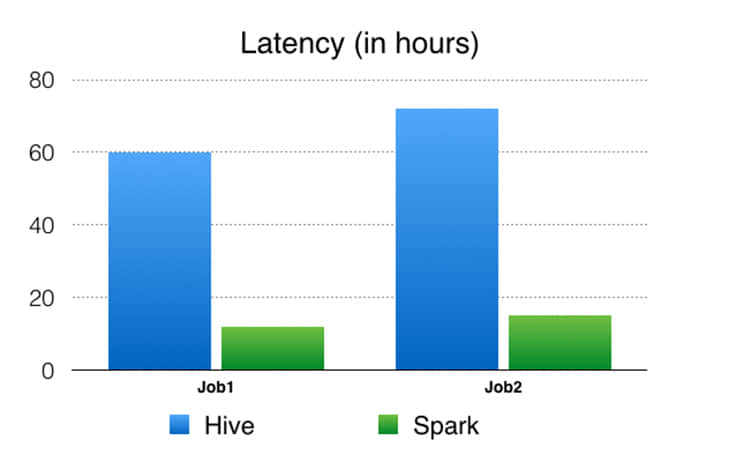
結論和未來工作
Facebook 的性能和可擴展的分析在產品開發中給予了協助。Apache Spark 提供了將各種分析用例統一為單一 API 和高效計算引擎的獨特功能。我們挑戰了 Spark,來將一個分解成數百個 Hive 作業的流水線替換成一個 Spark 作業。通過一系列的性能和可靠性改進之後,我們可以將 Spark 擴大到處理我們在生產中的實體排名數據處理用例之一。 在這個特殊用例中,我們展示了 Spark 可以可靠地重排和排序 90 TB+ 的中間數據,並在一個單一作業中運行了 25 萬個任務。 與舊的基於 Hive 的流水線相比,基於 Spark 的流水線產生了顯著的性能改進(4.5-6 倍 CPU,3-4 倍資源預留和大約 5 倍的延遲),並且已經投入使用了幾個月。
雖然本文詳細介紹了我們 Spark 最具挑戰性的用例,越來越多的客戶團隊已將 Spark 工作負載部署到生產中。 性能 、可維護性和靈活性是繼續推動更多用例到 Spark 的優勢。 Facebook 很高興成為 Spark 開源社區的一部分,並將共同開發 Spark 充分發揮其潛力。
via: https://code.facebook.com/posts/1671373793181703/apache-spark-scale-a-60-tb-production-use-case/
作者:Sital Kedia, 王碩傑, Avery Ching 譯者:wyangsun 校對:wxy
本文轉載來自 Linux 中國: https://github.com/Linux-CN/archive
對這篇文章感覺如何?
You may also like






More in:Linux中國

捐贈 Let's Encrypt,共建安全的互聯網

Let's Encrypt 正式發布,已經保護 380 萬個域名

關於Linux防火牆iptables的面試問答

Lets Encrypt 已被所有主流瀏覽器所信任









