5 個適合系統管理員使用的告警可視化工具

你大概已經知道(或猜到) 告警可視化 工具是用來做什麼的了。下面我們就要來說一下,為什麼要討論這樣的工具,甚至某些系統專門將可視化作為特有的功能。
可觀察性 的概念來自 控制理論 ,這個概念描述了我們通過對系統的輸入和輸出來了解其的能力。本文將重點介紹具有可觀察性的輸出組件。
告警可視化工具可以對其它系統的輸出進行分析,進而對輸出的信息進行結構化表示。告警實際上是對系統異常狀態的描述,而可視化則是讓用戶能夠直觀理解的結構化表示。
常見的可視化告警
告警
首先要明確一下 告警 的含義。在人員無法響應告警內容情況下,不應該發送告警 —— 包括那些發給多個人但只有其中少數人可以響應的告警,以及系統中的每個異常都觸發的告警。因為這樣會產生告警疲勞,告警接收者也往往會對這些過多的告警採取忽視的態度 —— 直到系統惡化到以少見的方式告警。
例如,如果管理員每天都會收到告警系統發來的數百封告警郵件,他就很容易會忽略告警系統的所有郵件。除非他真的看到問題發生,或者受到了客戶或上級的詢問時,管理員才會重新重視告警信息。在這種情況下,告警已經失去了原有的意義和用途。
告警不是一個持續的信息流或者狀態更新。告警的目的在於暴露系統無法自動恢復的問題,而且告警應該只發送給最有可能解決問題的人員。超出這個定義的內容都不應該作為告警,否則將會對實際工作造成不良的影響。
不同的告警體系都會有各自的告警類型,因此不能用優先順序(P1-P5)或者諸如「信息」、「警告」、「嚴重」之類的字眼來一概而論,下面我會介紹一些新興的複雜系統的事件響應中出現的通用分類方式。
剛才我提到了一個「信息」這個告警類型,但實際上告警不應該是一個信息,儘管有些人可能會不這樣認為。但我覺得如果一個告警沒有發送給任何一個人,它就不應該是警報,而只是一些在許多系統中被視為警報的數據點,代表了一些應該知曉但不需要響應的事件。它更應該作為告警可視化工具的一部分,而不是會導致觸發告警的事件。《實用監控》是這個領域的必讀書籍,其作者 Mike Julian 在書中就介紹了他自己關於告警的看法。
而非信息警報則代表告警需要被響應以及需要相關的操作。我將這些告警大致分為內部故障和外部故障兩種類型,而對於大多數公司來說,通常會有兩個以上的級別來確定響應告警的優先順序。系統性能下降就是一種故障,因為其對用戶的影響通常都是未知的。
內部故障比外部故障的優先順序低,但也需要快速響應。內部故障通常包括公司員工使用的內部系統或僅對公司員工可見的應用故障。
外部故障則包括任何馬上會產生業務影響的系統故障,但不包括影響系統更新的故障。外部故障一般包括客戶所面臨的應用故障、資料庫故障和導致系統可用性或一致性失效的網路故障,這些都會影響用戶的正常使用。對於不直接影響用戶的依賴組件故障也屬於外部故障,隨著應用程序的不斷運行,一旦依賴組件發生故障,系統的性能也會受到波及。這種情況對於使用某些外部服務或數據源的系統來說很常見,儘管這些外部服務或數據源對於可能不涉及到系統的主要功能,但是當系統在處理相關依賴組件的錯誤時可能會出現較明顯的延遲。
可視化
可視化的種類有很多,我就不一一贅述了。這是一個有趣的研究領域,在我這些年的數據分析經歷當中,學習和應用可視化方面的知識可以說是相當有挑戰性。我們需要將複雜的系統輸出通過直觀的方式來向他人展示,才能有效地把信息傳播出去。Google Charts 和 Tableau 都提供了很多可視化方面的工具。下面將會介紹一些最常見的可視化創新解決方案。
折線圖
折線圖可能是最常見的可視化方式了,它可以讓用戶很直觀地按照時間維度了解系統的情況。系統中每個單一或聚合的指標都會以一條折線在圖表中體現。但當同一個圖表中同時存在多條折線時,就可能會對閱讀有所影響(如下圖所示),所以大多數情況下都可以選擇僅查看其中的少數幾條折線,而不是讓所有折線同時顯示。如果某個指標的數值產生了大於正常範圍的波動,就會很容易發現。例如下圖中異常的紫線、黃線、淺藍線。
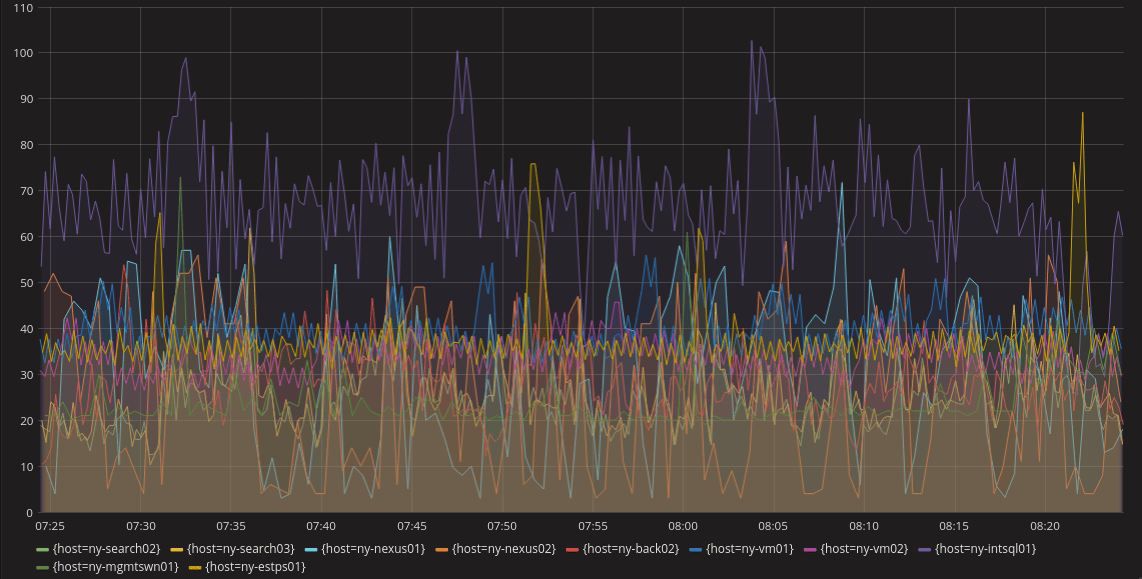
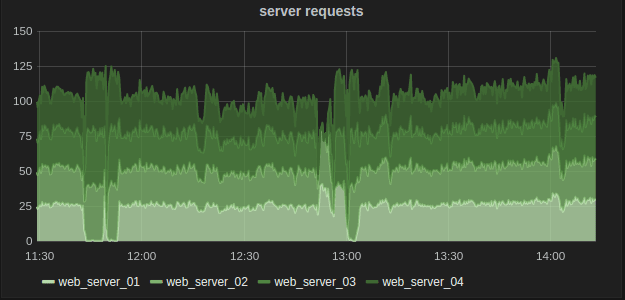
折線圖的另一個用法是可以將多條折線堆疊起來以顯示它們之間的關係。例如對於通過折線圖反映伺服器的請求數量,可以單獨看到每台伺服器上的請求,也可以聚合在一起看。這就可以在同一個圖表中靈活查看整個系統以及每個實例的情況了。
熱力圖
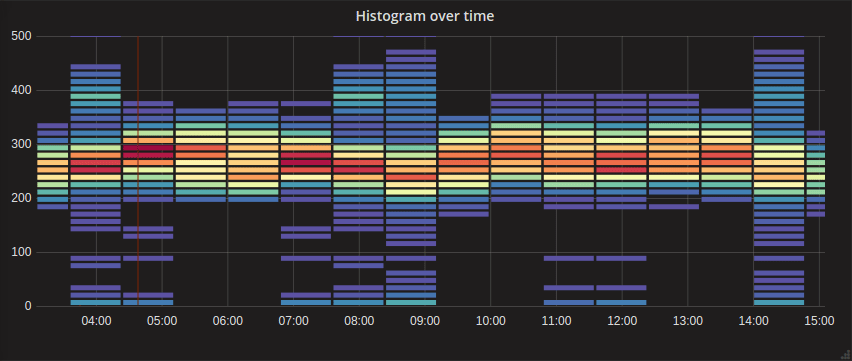
另一種常見的可視化方式是熱力圖。熱力圖與條形圖比較類似,還可以在條形圖的基礎上顯示某部分在整體中佔比的變化情況。例如在查看網路請求延時的時候,就可以使用熱力圖快速查看到所有網路請求的總體趨勢和分布情況,另外,它可以使用不同顏色來表示不同部分的數值。
在以下這個熱力圖中,通過豎直方向上每個時間段的色塊數量分布,可以清楚地看到大部分數據集中在整個範圍的中心位置。我們還可以發現,大多數時間段的色塊分布都是比較寬鬆的,而 14:00 到 15:00 這一段則分布得很密集,這樣的分布有可能意味著一種不健康的狀態。
儀錶圖
還有一種常見的可視化方式是儀錶圖,用戶可以通過儀錶圖快速了解單個指標。儀錶一般用於單個指標的顯示,例如車速表代表汽車的行駛速度、油量表代表油箱中的汽油量等等。大多數的儀錶圖都有一個共通點,就是會劃分出所示指標的對應狀態。如下圖所示,綠色表示正常的狀態,橙色表示不良的狀態,而紅色則表示極差的狀態。下圖中間一行模擬了真實儀錶的顯示情況。
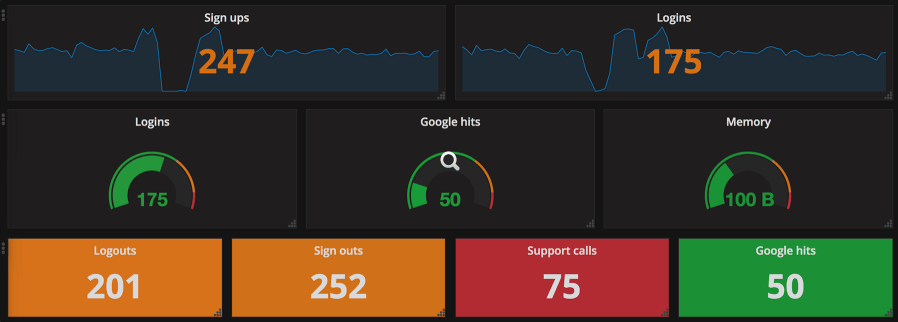
上面圖表中,除了常規儀錶樣式的顯示方式之外,還有較為直接的數據顯示方式,配合相同的配色方案,一眼就可以看出各個指標所處的狀態,這一點與和儀錶的特點類似。所以,最下面一行可能是儀錶圖的最佳顯示方式,用戶不需要仔細閱讀,就可以大致了解各個指標的不同狀態。這種類型的可視化是我最常用的類型,在數秒鐘之間,我就可以全面地總覽系統各方面地運行情況。
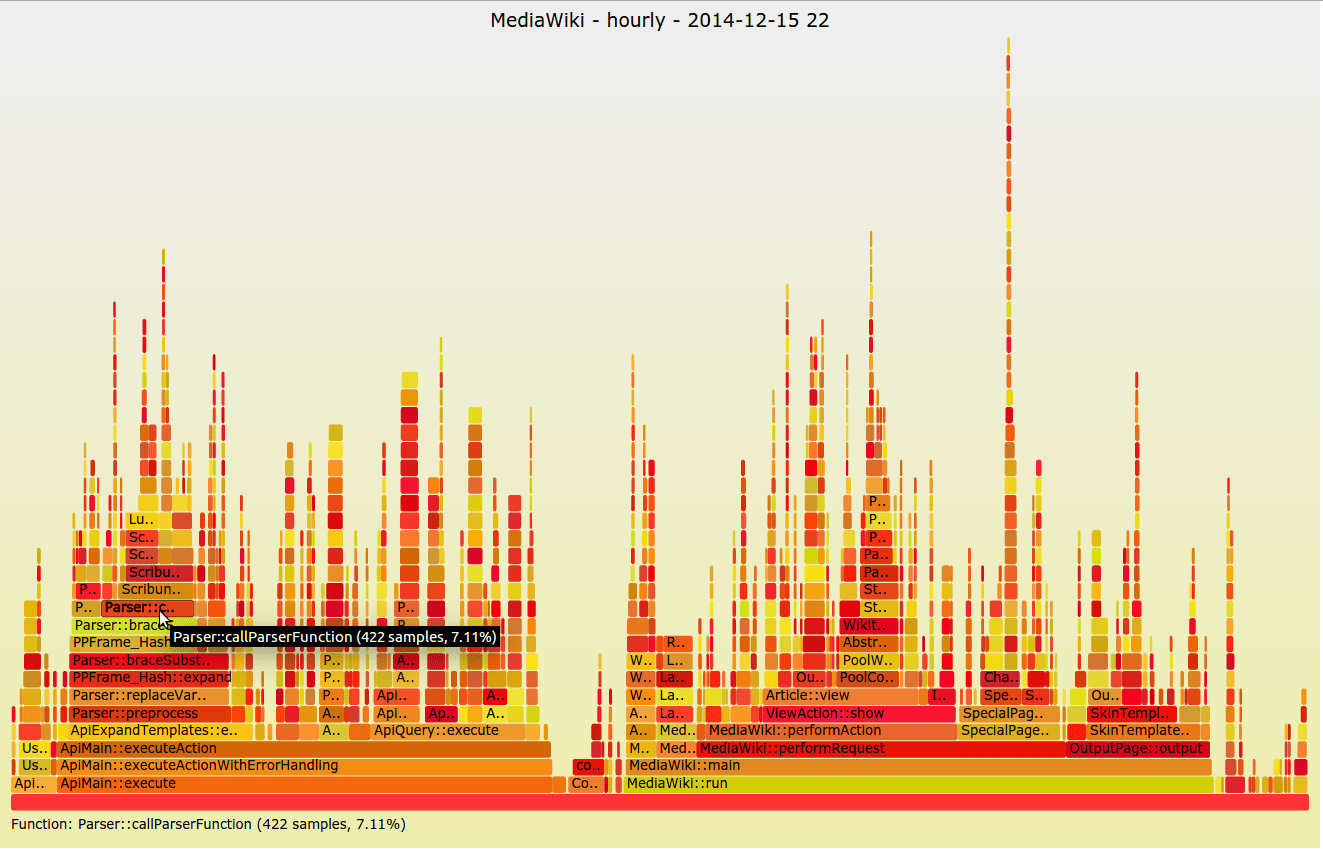
火焰圖
由 Netflix 的 Brendan Gregg 在 2011 年開始使用的火焰圖是一種較為少見地可視化方式。它不像儀錶圖那樣可以從圖表中快速得到關鍵信息,通常只會在需要解決某個應用的問題的時候才會用到這種圖表。火焰圖主要用於 CPU、內存和相關幀方面的表示,X 軸按字母順序將幀一一列出,而 Y 軸則表示堆棧的深度。圖中每個矩形都是一個標明了調用的函數的堆棧幀。矩形越寬,就表示它在堆棧中出現越頻繁。在分析系統性能問題的時候,火焰圖能夠起到很大的作用,大家不妨嘗試一下。
工具的選擇
在告警工具方面,有幾個商用的工具相當不錯。但由於這是一篇介紹開源技術的文章,我只會介紹那些已經被廣泛使用的免費工具。希望你也能夠為這些工具貢獻你自己的代碼,讓它們更加完善。
告警工具
Bosun
如果你的電腦出現問題,得多虧 Stack Exchange 你才能在網上查到解決辦法。Stack Exchange 以眾包問答的模式運營著很多不同類型的網站。其中就有廣受開發者歡迎的 Stack Overflow,以及運維方面有名的 Super User。除此以外,從育兒經驗到科幻小說、從哲學討論到單車論壇,Stack Exchange 都有涉獵。
Stack Exchange 開源了它的告警管理系統 Bosun,同時也發布了 Prometheus 及其 AlertManager 系統。這兩個系統有共通點。Bosun 和 Prometheus 一樣使用 Golang 開發,但 Bosun 比 Prometheus 更為強大,因為它可以使用 指標聚合 以外的方式與系統交互。Bosun 還可以從日誌和事件收集系統中提取數據,並且支持 Graphite、InfluxDB、OpenTSDB 和 Elasticsearch。
Bosun 的架構包括一個單一的伺服器的二進位文件,一個諸如 OpenTSDB 的後端、Redis 以及 scollector 代理。 scollector 代理會自動檢測主機上正在運行的服務,並反饋這些進程和其它的系統資源的情況。這些數據將發送到後端。隨後 Bosun 的二進位服務文件會向後端發起查詢,確定是否需要觸發告警。也可以通過 Grafana 這些工具通過一個通用介面查詢 Bosun 的底層後端。而 Redis 則用於存儲 Bosun 的狀態信息和元數據。
Bosun 有一個非常巧妙的功能,就是可以根據歷史數據來測試告警。這是我幾年前在使用 Prometheus 的時候就非常需要的功能,當時我有一個異常的數據需要產生告警,但沒有一個可以用於測試的簡便方法。為了確保告警能夠正常觸發,我不得不造出對應的數據來進行測試。而 Bosun 讓這個步驟的耗時大大縮短。
Bosun 更是涵蓋了所有常用過的功能,包括簡單的圖形化表示和告警的創建。它還帶有強大的用於編寫告警規則的表達式語言。但 Bosun 默認只帶有電子郵件通知配置和 HTTP 通知配置,因此如果需要連接到 Slack 或其它工具,就需要對配置作出更大程度的定製化(其文檔中有)。類似於 Prometheus,Bosun 還可以使用模板通知,你可以使用 HTML 和 CSS 來創建你所需要的電子郵件通知。
Cabot
Cabot 由 Arachnys 公司開發。你或許對 Arachnys 公司並不了解,但它很有影響力:Arachnys 公司構建了一個基於雲的先進解決方案,用於防範金融犯罪。在之前的公司時,我也曾經參與過類似「了解你的客戶(KYC)」的工作。大多數公司都認為與恐怖組織產生聯繫會造成相當不好的影響,因為恐怖組織可能會利用自己的系統來籌集資金。而這些解決方案將有助於防範欺詐類犯罪,儘管這類犯罪情節相對較輕,但仍然也會對機構產生風險。
Arachnys 公司為什麼要開發 Cabot 呢?其實只是因為 Arachnys 的開發人員對 Nagios 不太熟悉。Cabot 的出現對很多人來說都是一個好消息,它基於 Django 和 Bootstrap 開發,因此如果想對這個項目做出自己的貢獻,門檻並不高。(另外值得一提的是,Cabot 這個名字來源於開發者的狗。)
與 Bosun 類似,Cabot 也不對數據進行收集,而是使用監控對象的 API 提供的數據。因此,Cabot 告警的模式是拉取而不是推送。它通過訪問每個監控對象的 API,根據特定的指標檢索所需的數據,然後將告警數據使用 Redis 緩存,進而持久化存儲到 Postgres 資料庫。
Cabot 的一個較為少見的特點是,它原生支持 Graphite,同時也支持 Jenkins。Jenkins 在這裡被視為一個集中式的定時任務,它會以對待故障的方式去對待構建失敗的狀況。構建失敗當然沒有系統故障那麼緊急,但一旦出現構建失敗,還是需要團隊採取措施去處理,畢竟並不是每個人在收到構建失敗的電子郵件時都會親自去檢查 Jenkins。
Cabot 另一個有趣的功能是它可以接入 Google 日曆安排值班人員,這個稱為 Rota 的功能用處很大,希望其它告警系統也能加入類似的功能。Cabot 目前僅支持安排主備聯繫人,但還有繼續改進的空間。它自己的文檔也提到,如果需要全面的功能,更應該考慮付費的解決方案。
StatsAgg
Pearson 作為一家開發了 StatsAgg 告警平台的出版公司,這是極為罕見的,當然也很值得敬佩。除此以外,Pearson 還運營著另外幾個網站以及和 O'Reilly Media 合資的企業。但我仍然會將它視為出版教學書籍的公司。
StatsAgg 除了是一個告警平台,還是一個指標聚合平台,甚至也有點類似其它系統的代理。StatsAgg 支持通過 Graphite、StatsD、InfluxDB 和 OpenTSDB 輸入數據,也支持將其轉發到各種平台。但隨著中心服務的負載不斷增加,風險也不斷增大。儘管如此,如果 StatsAgg 的基礎架構足夠強壯,即使後端存儲平台出現故障,也不會對它產生告警的過程造成影響。
StatsAgg 是用 Java 開發的,為了儘可能降低複雜性,它僅包括主服務和一個 UI。StatsAgg 支持基於正則表達式匹配來發送告警,而且它更注重於服務方面的告警,而不是伺服器基礎告警。我認為它填補了開源監控工具方面的空白,而這正式它自己的目標。
可視化工具
Grafana
Grafana 的知名度很高,它也被廣泛採用。每當我需要用到數據面板的時候,我總是會想到它,因為它比我使用過的任何一款類似的產品都要好。Grafana 由 Torkel Ödegaard 開發的,像 Cabot 一樣,也是在聖誕節期間開發的,並在 2014 年 1 月發布。在短短几年之間,它已經有了長足的發展。Grafana 基於 Kibana 開發,Torkel 開啟了新的分支並將其命名為 Grafana。
Grafana 著重體現了實用性以及數據呈現的美觀性。它天生就可以從 Graphite、Elasticsearch、OpenTSDB、Prometheus 和 InfluxDB 收集數據。此外有一個 Grafana 商用版插件可以從更多數據源獲取數據,但是其他數據源插件也並非沒有開源版本,Grafana 的插件生態系統已經提供了各種數據源。
Grafana 能做什麼呢?Grafana 提供了一個中心化的了解系統的方式。它通過 web 來展示數據,任何人都有機會訪問到相關信息,當然也可以使用身份驗證來對訪問進行限制。Grafana 使用各種可視化方式來提供對系統一目了然的了解。Grafana 還支持不同類型的可視化方式,包括集成告警可視化的功能。
現在你可以更直觀地設置告警了。通過 Grafana,可以查看圖表,還可以查看由於系統性能下降而觸發告警的位置,單擊要觸發報警的位置,並告訴 Grafana 將告警發送何處。這是一個對告警平台非常強大的補充。告警平台不一定會因此而被取代,但告警系統一定會由此得到更多啟發和發展。
Grafana 還引入了很多團隊協作的功能。不同用戶之間能夠共享數據面板,你不再需要為 Kubernetes 集群創建獨立的數據面板,因為由 Kubernetes 開發者和 Grafana 開發者共同維護的一些數據面板已經可用了。
團隊協作過程中一個重要的功能是注釋。注釋功能允許用戶將上下文添加到圖表當中,其他用戶就可以通過上下文更直觀地理解圖表。當團隊成員在處理某個事件,並且需要溝通和理解時,這個功能就十分重要了。將所有相關信息都放在需要的位置,可以讓整個團隊中快速達成共識。在團隊需要調查故障原因和定位事件責任時,這個功能就可以發揮作用了。
Vizceral
Vizceral 由 Netflix 開發,用於在故障發生時更有效地了解流量的情況。Grafana 是一種通用性更強的工具,而 Vizceral 則專用於某些領域。 儘管 Netflix 表示已經不再在內部使用 Vizceral,也不再主動對其展開維護,但 Vizceral 仍然會定期更新。我在這裡介紹這個工具,主要是為了介紹它的的可視化機制,以及如何利用它來協助解決問題。你可以在樣例環境中用它來更好地掌握這一類系統的特性。
via: https://opensource.com/article/18/10/alerting-and-visualization-tools-sysadmins
作者:Dan Barker 選題:lujun9972 譯者:HankChow 校對:wxy
本文轉載來自 Linux 中國: https://github.com/Linux-CN/archive
對這篇文章感覺如何?
You may also like






More in:Linux中國

捐贈 Let's Encrypt,共建安全的互聯網

Let's Encrypt 正式發布,已經保護 380 萬個域名

關於Linux防火牆iptables的面試問答

Lets Encrypt 已被所有主流瀏覽器所信任









