編譯器簡介: 在 Siri 前時代如何與計算機對話

簡單說來,一個 編譯器 不過是一個可以翻譯其他程序的程序。傳統的編譯器可以把源代碼翻譯成你的計算機能夠理解的可執行機器代碼。(一些編譯器將源代碼翻譯成別的程序語言,這樣的編譯器稱為源到源翻譯器或 轉化器 。)LLVM 是一個廣泛使用的編譯器項目,包含許多模塊化的編譯工具。
傳統的編譯器設計包含三個部分:
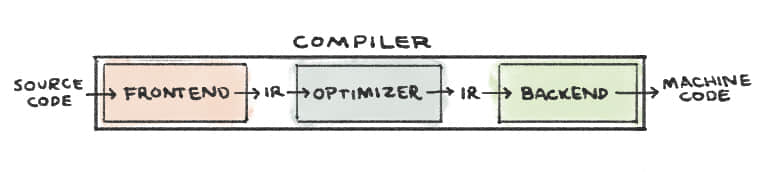
- 前端 將源代碼翻譯為 中間表示 (IR)* 。clang 是 LLVM 中用於 C 家族語言的前端工具。
- 優化器 分析 IR 然後將其轉化為更高效的形式。opt 是 LLVM 的優化工具。
- 後端 通過將 IR 映射到目標硬體指令集從而生成機器代碼。llc 是 LLVM 的後端工具。
註:LLVM 的 IR 是一種和彙編類似的低級語言。然而,它抽離了特定硬體信息。
Hello, Compiler
下面是一個列印 「Hello, Compiler!」 到標準輸出的簡單 C 程序。C 語法是人類可讀的,但是計算機卻不能理解,不知道該程序要幹什麼。我將通過三個編譯階段使該程序變成機器可執行的程序。
// compile_me.c
// Wave to the compiler. The world can wait.
#include <stdio.h>
int main() {
printf("Hello, Compiler!n");
return 0;
}
前端
正如我在上面所提到的,clang 是 LLVM 中用於 C 家族語言的前端工具。Clang 包含 C 預處理器 、 詞法分析器 、 語法解析器 、 語義分析器 和 IR 生成器 。
C 預處理器在將源程序翻譯成 IR 前修改源程序。預處理器處理外部包含文件,比如上面的 #include <stdio.h>。 它將會把這一行替換為 stdio.h C 標準庫文件的完整內容,其中包含 printf 函數的聲明。
通過運行下面的命令來查看預處理步驟的輸出:
clang -E compile_me.c -o preprocessed.i
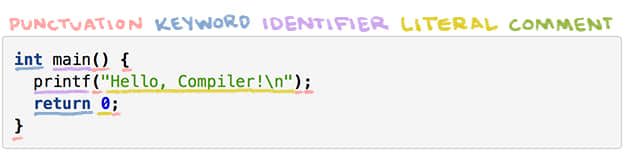
詞法分析器(或 掃描器 或 分詞器 )將一串字元轉化為一串單詞。每一個單詞或 記號 ,被歸併到五種語法類別之一:標點符號、關鍵字、標識符、文字或注釋。
compile_me.c 的分詞過程:
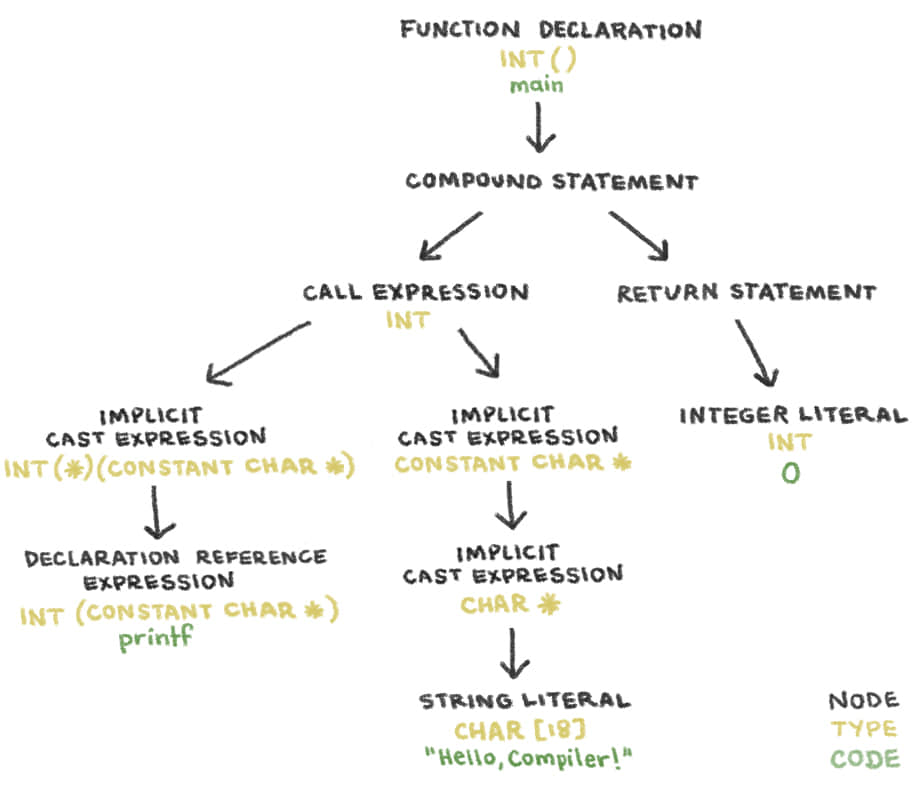
語法分析器確定源程序中的單詞流是否組成了合法的句子。在分析記號流的語法後,它會輸出一個 抽象語法樹 (AST)。Clang 的 AST 中的節點表示聲明、語句和類型。
compile_me.c 的語法樹:
語義分析器會遍歷抽象語法樹,從而確定代碼語句是否有正確意義。這個階段會檢查類型錯誤。如果 compile_me.c 的 main 函數返回 "zero"而不是 0, 那麼語義分析器將會拋出一個錯誤,因為 "zero" 不是 int 類型。
IR 生成器將抽象語法樹翻譯為 IR。
對 compile_me.c 運行 clang 來生成 LLVM IR:
clang -S -emit-llvm -o llvm_ir.ll compile_me.c
在 llvm_ir.ll 中的 main 函數:
; llvm_ir.ll
@.str = private unnamed_addr constant [18 x i8] c"Hello, Compiler!�A�0", align 1
define i32 @main() {
%1 = alloca i32, align 4 ; <- memory allocated on the stack
store i32 0, i32* %1, align 4
%2 = call i32 (i8*, ...) @printf(i8* getelementptr inbounds ([18 x i8], [18 x i8]* @.str, i32 0, i32 0))
ret i32 0
}
declare i32 @printf(i8*, ...)
優化程序
優化程序的工作是基於其對程序的運行時行為的理解來提高代碼效率。優化程序將 IR 作為輸入,然後生成改進後的 IR 作為輸出。LLVM 的優化工具 opt 將會通過標記 -O2(大寫字母 o,數字 2)來優化處理器速度,通過標記 Os(大寫字母 o,小寫字母 s)來減少指令數目。
看一看上面的前端工具生成的 LLVM IR 代碼和運行下面的命令生成的結果之間的區別:
opt -O2 -S llvm_ir.ll -o optimized.ll
在 optimized.ll 中的 main 函數:
optimized.ll
@str = private unnamed_addr constant [17 x i8] c"Hello, Compiler!�0"
define i32 @main() {
%puts = tail call i32 @puts(i8* getelementptr inbounds ([17 x i8], [17 x i8]* @str, i64 0, i64 0))
ret i32 0
}
declare i32 @puts(i8* nocapture readonly)
優化後的版本中, main 函數沒有在棧中分配內存,因為它不使用任何內存。優化後的代碼中調用 puts 函數而不是 printf 函數,因為程序中並沒有使用 printf 函數的格式化功能。
當然,優化程序不僅僅知道何時可以把 printf 函數用 puts 函數代替。優化程序也能展開循環並內聯簡單計算的結果。考慮下面的程序,它將兩個整數相加並列印出結果。
// add.c
#include <stdio.h>
int main() {
int a = 5, b = 10, c = a + b;
printf("%i + %i = %in", a, b, c);
}
下面是未優化的 LLVM IR:
@.str = private unnamed_addr constant [14 x i8] c"%i + %i = %i�A�0", align 1
define i32 @main() {
%1 = alloca i32, align 4 ; <- allocate stack space for var a
%2 = alloca i32, align 4 ; <- allocate stack space for var b
%3 = alloca i32, align 4 ; <- allocate stack space for var c
store i32 5, i32* %1, align 4 ; <- store 5 at memory location %1
store i32 10, i32* %2, align 4 ; <- store 10 at memory location %2
%4 = load i32, i32* %1, align 4 ; <- load the value at memory address %1 into register %4
%5 = load i32, i32* %2, align 4 ; <- load the value at memory address %2 into register %5
%6 = add nsw i32 %4, %5 ; <- add the values in registers %4 and %5. put the result in register %6
store i32 %6, i32* %3, align 4 ; <- put the value of register %6 into memory address %3
%7 = load i32, i32* %1, align 4 ; <- load the value at memory address %1 into register %7
%8 = load i32, i32* %2, align 4 ; <- load the value at memory address %2 into register %8
%9 = load i32, i32* %3, align 4 ; <- load the value at memory address %3 into register %9
%10 = call i32 (i8*, ...) @printf(i8* getelementptr inbounds ([14 x i8], [14 x i8]* @.str, i32 0, i32 0), i32 %7, i32 %8, i32 %9)
ret i32 0
}
declare i32 @printf(i8*, ...)
下面是優化後的 LLVM IR:
@.str = private unnamed_addr constant [14 x i8] c"%i + %i = %i�A�0", align 1
define i32 @main() {
%1 = tail call i32 (i8*, ...) @printf(i8* getelementptr inbounds ([14 x i8], [14 x i8]* @.str, i64 0, i64 0), i32 5, i32 10, i32 15)
ret i32 0
}
declare i32 @printf(i8* nocapture readonly, ...)
優化後的 main 函數本質上是未優化版本的第 17 行和 18 行,伴有變數值內聯。opt 計算加法,因為所有的變數都是常數。很酷吧,對不對?
後端
LLVM 的後端工具是 llc。它分三個階段將 LLVM IR 作為輸入生成機器代碼。
- 指令選擇是將 IR 指令映射到目標機器的指令集。這個步驟使用虛擬寄存器的無限名字空間。
- 寄存器分配是將虛擬寄存器映射到目標體系結構的實際寄存器。我的 CPU 是 x86 結構,它只有 16 個寄存器。然而,編譯器將會儘可能少的使用寄存器。
- 指令安排是重排操作,從而反映出目標機器的性能約束。
運行下面這個命令將會產生一些機器代碼:
llc -o compiled-assembly.s optimized.ll
_main:
pushq %rbp
movq %rsp, %rbp
leaq L_str(%rip), %rdi
callq _puts
xorl %eax, %eax
popq %rbp
retq
L_str:
.asciz "Hello, Compiler!"
這個程序是 x86 彙編語言,它是計算機所說的語言,並具有人類可讀語法。某些人最後也許能理解我。

相關資源:
(題圖:deviantart.net)
via: https://nicoleorchard.com/blog/compilers
作者:Nicole Orchard 譯者:ucasFL 校對:wxy
本文轉載來自 Linux 中國: https://github.com/Linux-CN/archive
對這篇文章感覺如何?
You may also like






More in:Linux中國

捐贈 Let's Encrypt,共建安全的互聯網

Let's Encrypt 正式發布,已經保護 380 萬個域名

關於Linux防火牆iptables的面試問答

Lets Encrypt 已被所有主流瀏覽器所信任









