
作为 Debian 用户,在使用 apt 更新系统时偶尔会发现某次安装更新的时间特别长,这往往出现在较大版本的更新中,仔细观察后就会发现,这个耗时极长的操作并不是安装某个软件,而是对一个名为 initrd.img 的文件进行解压、修改再重新压缩,那么为什么我们会需要在更新系统时修改这个文件呢?这还要从 Linux 的启动流程说起。
在远古时代
回到 Linux 的远古时代,那时 Linux 支持的外设和功能还没有像今天这样丰富,因此启动也相对较为简单,只需要一个 Bootloader 启动内核(例如 LILO 或 GRUB 等),并在启动时向内核传递 rootfs 所在的设备即可,之后 Linux 即可寻找到 rootfs 并正常启动。
以笔者这张龙芯 2K1000LA 嵌入式开发板搭载的 PMON 5.0.2 引导程序为例,要让内核知道 rootfs 的位置,只需要在/boot/boot.cfg文件中内核的启动参数上加上这样一条:
root=/dev/sda值得一提的是,这里的/dev/sda通常指的是硬盘,例如在我的机器上就是安装在主板上的 nvme 硬盘,那么问题就来了,如果在保持内核不变的同时,想要从 U 盘上的 rootfs 启动怎么办呢?你可能会以为只需要这样修改就好了:
root=/dev/sdb当初的笔者也是这么想的,然而事情并没有这么简单,修改完毕开机之后,内核很快抛出了找不到 /dev/sdb 的 Panic,于是在 Linux Kernel 手册里翻找一番之后,我找到了这样的一个参数:
rootwait [KNL] Wait (indefinitely) for root device to show up.
Useful for devices that are detected asynchronously
(e.g. USB and MMC devices).在参数的简介中特别说明了适用 USB 等异步检测的设备,在启动参数中加上它之后,内核终于成功启动到了 U 盘中的 rootfs,一个简陋的 Live USB 系统也就这样做好了,整体体验属实是相当复古了。
不过从严格意义上来说,这并不能算是“返古”,毕竟对于嵌入式系统来说,接入的设备和应用场景都相对固定,因此没有必要为系统启动引入额外的层级。但对于桌面工作站、甚至是服务器等运行 Linux 的设备来说,他们需要处理远比这复杂的场景,rootfs 可能会存储在 RAID 磁盘阵列中,可能需要实现 XFS 等复杂的文件系统才能读取,甚至这台设备可能就没有硬盘,需要从网络加载 rootfs 等等...随着需求越来越复杂,人们意识到不能无限制地向 Kernel 中塞入代码,于是在 Linux 引入了一个全新的机制——早期用户空间。
早期用户空间
众所周知,在计算机领域解决问题的最好方式之一就是:引入一层新的抽象,于是早期用户空间(Early Userspace)横空出世。它正是为了解决 Linux 的启动越来越复杂,需要内核支持的功能越来越多这一问题出现的。它主要由三个部分组成:
- gen_init_cpio,这个程序会生成包含根文件系统的 cpio 格式镜像,这个文件是压缩过的,并且可以直接包含在内核中。
- initramfs,它的实现代码会在内核启动的过程中解压缩并加载 cpio 格式的镜像
- klibc,这是一个用户态的微型 libc 库,专门为早期用户空间设计,体积非常小。
这三个部分共同组合构成了早期用户空间,可以把它理解成一个专门为了初始化各种设备优化的根文件系统,它的体积很小,可以直接塞进 Linux 内核镜像中,不过大部分发行版还是会选择将其作为一个单独的文件,放在/boot目录里,并在启动时使用如下的命令加载它:
initrd = <position of initrd image>加载完成并启动到早期用户空间之后,首先会执行该系统根目录下的/init文件,它通常会是一个/bin/busybox的软链接,busybox 笔者在过去也介绍过,集成了一系列实用工具,例如 sh、ls、mount 等等使用这些工具和脚本的组合,便可以准备好加载真正的根目录所需的各种环境,之后再使用switch_root切换过去即可。
不过现如今,在大部分 Linux 发行版启动时,能看到的输出大部分都是由 systemd 输出的了——这也是没办法的事,相比于遵守 KISS 哲学的 SysVinit,大而全的管理工具在如今更得人心,乃至于大部分的发行版中的 initramfs 中包含的 init 也都是 systemd 而不是 busybox 了。
实际上,在 Linux 2.6 之后,并不需要上面的参数也能加载早期用户空间了,该版本的 Linux 引入了一种新的格式:initramfs,相较于使用镜像文件格式的传统 initrd,initramfs 是一个使用 gzip 压缩后的 cpio 文件,它不仅能单独存储,还能集成在内核文件当中,并且相较于镜像文件依赖于某种特定的文件系统(如 ext2),initramfs 是基于 ramfs 的全新实现,相对加载效率更高,并且速度更快。
在编译 Linux 时即可使用 menuconfig 设置是否启用 initramfs/initrd,以及是否把 initramfs 集成进内核里,默认前者是开启的状态,而后者在大多数 Linux 发行版中则是关闭的状态,毕竟它会显著增加 Linux 内核镜像文件的体积,往往是得不偿失的。
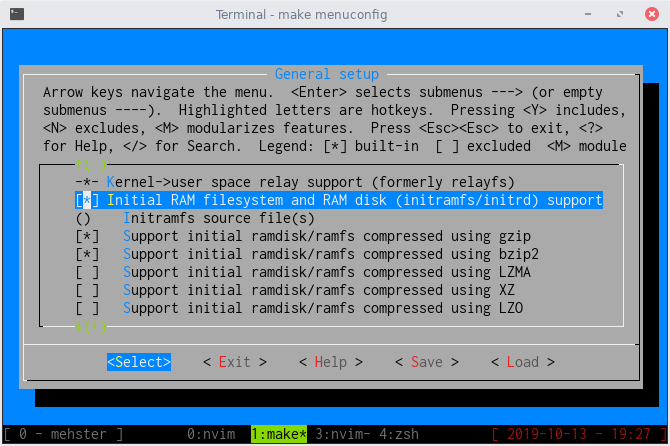
除了在编译内核时,也可以使用工具直接制作 initramfs 文件,这里用一个最简单的 C 程序和 qemu 为例子来演示,下面是init.c文件的内容。
#include <stdio.h>
void main()
{
printf("Hello World!");
fflush(stdout);
// 避免 init 程序结束导致 Kernel Panic
while(true);
}使用 gcc 静态编译该程序,防止因为缺少动态库导致无法运行。
gcc -static init.c -o init再使用 cpio 归档程序创建 initramfs 文件。
echo init | cpio -o --format=newc > initramfs最后使用 qemu 指定内核和 initrd 文件启动,测试它是否能正常启动到初期用户空间并运行 init 程序:
qemu-system-x86_64 -m 1024M -kernel zImage -initrd initramfs qemu 输出Hello World并自旋,证明成功启动到了 initramfs 中的根文件系统。
链式启动
关于 Linux 的启动过程,其实还有非常多有趣的部分,例如笔者在开头一笔带过的 Bootloader,像是 Linuxboot 这样的项目宣称能在服务器上做到比传统 UEFI 快得多的启动速度,实际上它的底层实现与早期用户空间的概念也有异曲同工之妙——先进入一个小型系统,进行设备的探测和初始化,最后用kexec加载内核,可惜的是由于kexec只支持 Linux,因此无法使用 Linuxboot 启动 Windows 和其他 BSD 系统...不过事情真的如此吗?

显然,有人不这么认为。来自 Trammell Hudson's Projects 的工程师们就整了个大活——用 Linux 链式启动 Windows:Booting Windows with Linux,并且他们还给出了这么做的理由:为了安全!是的,即便 Windows 11 带来了 TPM(受信任的平台模块)支持也并不足够,因为在实际的生产环境中,服务器可能需要加载存放在网络上的系统,而这就是 TPM 力所不能及的了,因此他们决定引入 Linux 加载安全模块,再用它启动 Windows。
当然,他们并没有使用 kexec 直接启动 Windows 内核——这需要对 Windows 内核进行相当程度的逆向,显然不可能用于实际生产环境;也没有选择使用 Linux 加载 EFI 文件——虽然这些文档都是开源的,实现一个这样的加载器并不困难,但难点在于 kexec 默认并不支持 Windows 可执行文件(即 PE32)格式的 EFI 文件,还会涉及到关于 Linux 与 Windows 之间共享库的兼容问题等等,因此他们也没有选择这个方案。最终,他们走了第三条路——链式引导。
这篇文章的内容非常丰富,以上的介绍只是一个简单的引文,关于他们是如何实现链式引导的更多内容我会在之后的文章中向各位分享,或许会是对原文的简单翻译,也或许会有我个人的一些理解和补充,敬请期待!
参考文章
kernel parameters
early userpace support
ramfs, rootfs, initramfs
对这篇文章感觉如何?
You may also like





More in:内核

龙芯开始发布针对3A6000系列CPU的Linux补丁

Linux 6.4-rc1发布,新增Intel LAM、多项AMD功能、更多Rust代码和早期Apple M2支持

Linux 共享库的 soname 命名机制

Linux 5.6 内核发布









