Logreduce:用 Python 和機器學習去除日誌噪音

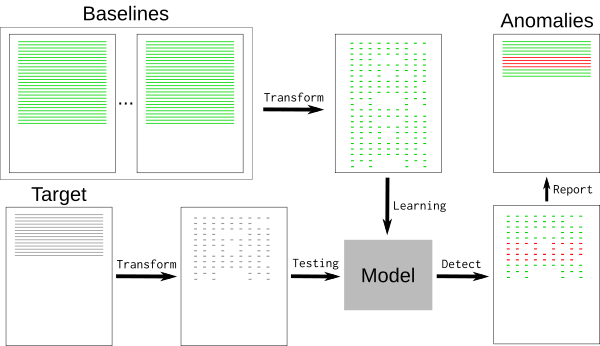
持續集成(CI)作業會生成大量數據。當一個作業失敗時,弄清楚出了什麼問題可能是一個繁瑣的過程,它涉及到調查日誌以發現根本原因 —— 這通常只能在全部的作業輸出的一小部分中找到。為了更容易地將最相關的數據與其餘數據分開,可以使用先前成功運行的作業結果來訓練 Logreduce 機器學習模型,以從失敗的運行日誌中提取異常。
此方法也可以應用於其他用例,例如,從 Journald 或其他系統級的常規日誌文件中提取異常。
使用機器學習來降低噪音
典型的日誌文件包含許多標稱事件(「基線」)以及與開發人員相關的一些例外事件。基線可能包含隨機元素,例如難以檢測和刪除的時間戳或唯一標識符。要刪除基線事件,我們可以使用 k-最近鄰模式識別演算法(k-NN)。
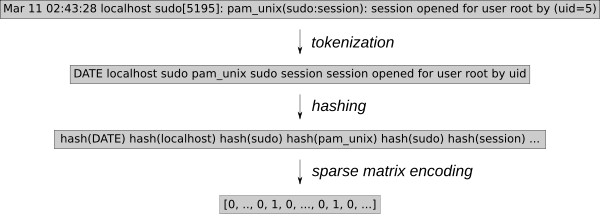
日誌事件必須轉換為可用於 k-NN 回歸的數值。使用通用特徵提取工具 HashingVectorizer 可以將該過程應用於任何類型的日誌。它散列每個單詞並在稀疏矩陣中對每個事件進行編碼。為了進一步減少搜索空間,這個標記化過程刪除了已知的隨機單詞,例如日期或 IP 地址。
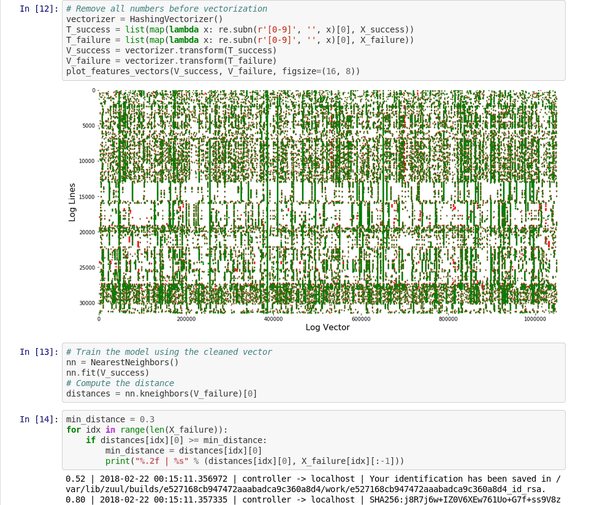
訓練模型後,k-NN 搜索可以告訴我們每個新事件與基線的距離。

這個 Jupyter 筆記本 演示了該稀疏矩陣向量的處理和圖形。
Logreduce 介紹
Logreduce Python 軟體透明地實現了這個過程。Logreduce 的最初目標是使用構建資料庫來協助分析 Zuul CI 作業的失敗問題,現在它已集成到 Software Factory 開發車間的作業日誌處理中。
最簡單的是,Logreduce 會比較文件或目錄並刪除相似的行。Logreduce 為每個源文件構建模型,並使用以下語法輸出距離高於定義閾值的任何目標行:distance | filename:line-number: line-content。
$ logreduce diff /var/log/audit/audit.log.1 /var/log/audit/audit.log
INFO logreduce.Classifier - Training took 21.982s at 0.364MB/s (1.314kl/s) (8.000 MB - 28.884 kilo-lines)
0.244 | audit.log:19963: type=USER_AUTH acct="root" exe="/usr/bin/su" hostname=managesf.sftests.com
INFO logreduce.Classifier - Testing took 18.297s at 0.306MB/s (1.094kl/s) (5.607 MB - 20.015 kilo-lines)
99.99% reduction (from 20015 lines to 1
更高級的 Logreduce 用法可以離線訓練模型以便重複使用。可以使用基線的許多變體來擬合 k-NN 搜索樹。
$ logreduce dir-train audit.clf /var/log/audit/audit.log.*
INFO logreduce.Classifier - Training took 80.883s at 0.396MB/s (1.397kl/s) (32.001 MB - 112.977 kilo-lines)
DEBUG logreduce.Classifier - audit.clf: written
$ logreduce dir-run audit.clf /var/log/audit/audit.logLogreduce 還實現了介面,以發現 Journald 時間範圍(天/周/月)和 Zuul CI 作業構建歷史的基線。它還可以生成 HTML 報告,該報告在一個簡單的界面中將在多個文件中發現的異常進行分組。
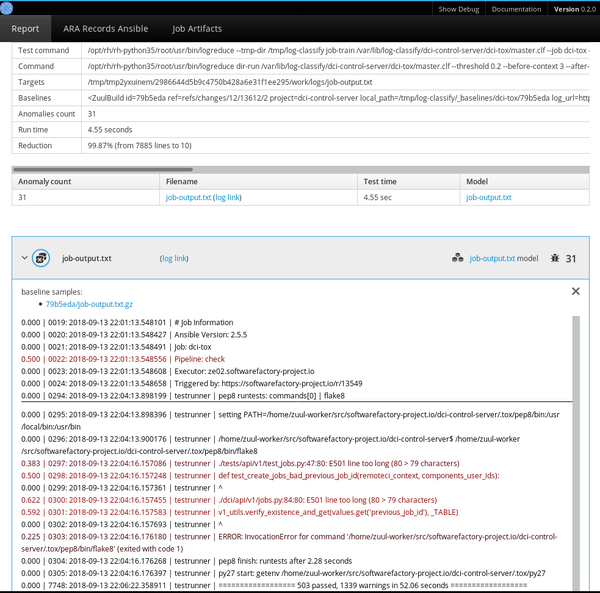
管理基線
使用 k-NN 回歸進行異常檢測的關鍵是擁有一個已知良好基線的資料庫,該模型使用資料庫來檢測偏離太遠的日誌行。此方法依賴於包含所有標稱事件的基線,因為基線中未找到的任何內容都將報告為異常。
CI 作業是 k-NN 回歸的重要目標,因為作業的輸出通常是確定性的,之前的運行結果可以自動用作基線。 Logreduce 具有 Zuul 作業角色,可以將其用作失敗的作業發布任務的一部分,以便發布簡明報告(而不是完整作業的日誌)。只要可以提前構建基線,該原則就可以應用於其他情況。例如,標稱系統的 SoS 報告 可用於查找缺陷部署中的問題。
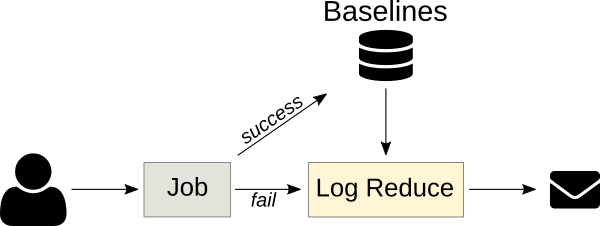
異常分類服務
下一版本的 Logreduce 引入了一種伺服器模式,可以將日誌處理卸載到外部服務,在外部服務中可以進一步分析該報告。它還支持導入現有報告和請求以分析 Zuul 構建。這些服務以非同步方式運行分析,並具有 Web 界面以調整分數並消除誤報。
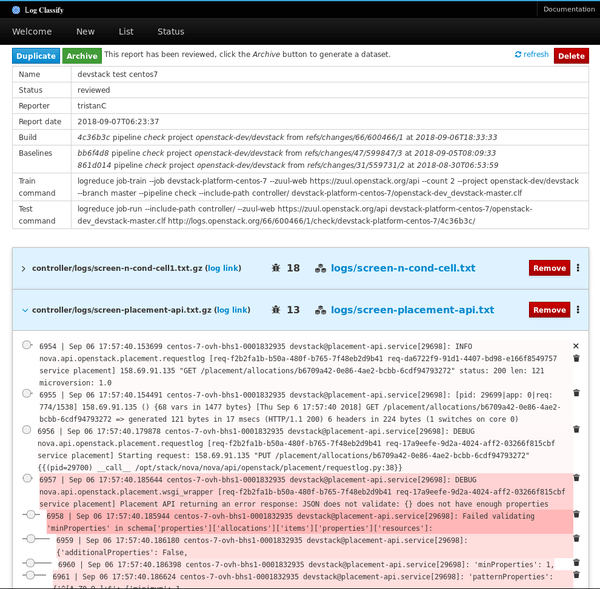
已審核的報告可以作為獨立數據集存檔,其中包含目標日誌文件和記錄在一個普通的 JSON 文件中的異常行的分數。
項目路線圖
Logreduce 已經能有效使用,但是有很多機會來改進該工具。未來的計劃包括:
- 策劃在日誌文件中發現的許多帶注釋的異常,並生成一個公共域數據集以進行進一步研究。日誌文件中的異常檢測是一個具有挑戰性的主題,並且有一個用於測試新模型的通用數據集將有助於識別新的解決方案。
- 重複使用帶注釋的異常模型來優化所報告的距離。例如,當用戶通過將距離設置為零來將日誌行標記為誤報時,模型可能會降低未來報告中這些日誌行的得分。
- 對存檔異常取指紋特徵以檢測新報告何時包含已知的異常。因此,該服務可以通知用戶該作業遇到已知問題,而不是報告異常的內容。解決問題後,該服務可以自動重新啟動該作業。
- 支持更多基準發現介面,用於 SOS 報告、Jenkins 構建、Travis CI 等目標。
如果你有興趣參與此項目,請通過 #log-classify Freenode IRC 頻道與我們聯繫。歡迎反饋!
via: https://opensource.com/article/18/9/quiet-log-noise-python-and-machine-learning
作者:Tristan de Cacqueray 選題:lujun9972 譯者:wxy 校對:wxy
本文轉載來自 Linux 中國: https://github.com/Linux-CN/archive
對這篇文章感覺如何?
You may also like






More in:Linux中國

捐贈 Let's Encrypt,共建安全的互聯網

Let's Encrypt 正式發布,已經保護 380 萬個域名

關於Linux防火牆iptables的面試問答

Lets Encrypt 已被所有主流瀏覽器所信任









