並發伺服器(二):線程

這是並發網路伺服器系列的第二節。第一節 提出了服務端實現的協議,還有簡單的順序伺服器的代碼,是這整個系列的基礎。
這一節里,我們來看看怎麼用多線程來實現並發,用 C 實現一個最簡單的多線程伺服器,和用 Python 實現的線程池。
該系列的所有文章:
多線程的方法設計並發伺服器
說起第一節里的順序伺服器的性能,最顯而易見的,是在伺服器處理客戶端連接時,計算機的很多資源都被浪費掉了。儘管假定客戶端快速發送完消息,不做任何等待,仍然需要考慮網路通信的開銷;網路要比現在的 CPU 慢上百萬倍還不止,因此 CPU 運行伺服器時會等待接收套接字的流量,而大量的時間都花在完全不必要的等待中。
這裡是一份示意圖,表明順序時客戶端的運行過程:
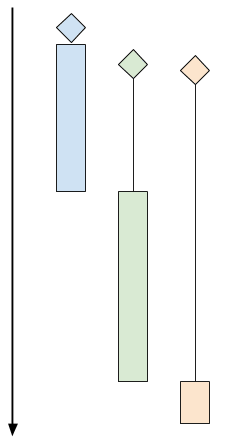
這個圖片上有 3 個客戶端程序。棱形表示客戶端的「到達時間」(即客戶端嘗試連接伺服器的時間)。黑色線條表示「等待時間」(客戶端等待伺服器真正接受連接所用的時間),有色矩形表示「處理時間」(伺服器和客戶端使用協議進行交互所用的時間)。有色矩形的末端表示客戶端斷開連接。
上圖中,綠色和橘色的客戶端儘管緊跟在藍色客戶端之後到達伺服器,也要等到伺服器處理完藍色客戶端的請求。這時綠色客戶端得到響應,橘色的還要等待一段時間。
多線程伺服器會開啟多個控制線程,讓操作系統管理 CPU 的並發(使用多個 CPU 核心)。當客戶端連接的時候,創建一個線程與之交互,而在主線程中,伺服器能夠接受其他的客戶端連接。下圖是該模式的時間軸:
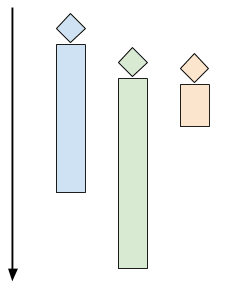
每個客戶端一個線程,在 C 語言里要用 pthread
這篇文章的 第一個示例代碼 是一個簡單的 「每個客戶端一個線程」 的伺服器,用 C 語言編寫,使用了 phtreads API 用於實現多線程。這裡是主循環代碼:
while (1) {
struct sockaddr_in peer_addr;
socklen_t peer_addr_len = sizeof(peer_addr);
int newsockfd =
accept(sockfd, (struct sockaddr*)&peer_addr, &peer_addr_len);
if (newsockfd < 0) {
perror_die("ERROR on accept");
}
report_peer_connected(&peer_addr, peer_addr_len);
pthread_t the_thread;
thread_config_t* config = (thread_config_t*)malloc(sizeof(*config));
if (!config) {
die("OOM");
}
config->sockfd = newsockfd;
pthread_create(&the_thread, NULL, server_thread, config);
// 回收線程 —— 在線程結束的時候,它佔用的資源會被回收
// 因為主線程在一直運行,所以它比服務線程存活更久。
pthread_detach(the_thread);
}
這是 server_thread 函數:
void* server_thread(void* arg) {
thread_config_t* config = (thread_config_t*)arg;
int sockfd = config->sockfd;
free(config);
// This cast will work for Linux, but in general casting pthread_id to an 這個類型轉換在 Linux 中可以正常運行,但是一般來說將 pthread_id 類型轉換成整形不便於移植代碼
// integral type isn't portable.
unsigned long id = (unsigned long)pthread_self();
printf("Thread %lu created to handle connection with socket %dn", id,
sockfd);
serve_connection(sockfd);
printf("Thread %lu donen", id);
return 0;
}
線程 「configuration」 是作為 thread_config_t 結構體進行傳遞的:
typedef struct { int sockfd; } thread_config_t;
主循環中調用的 pthread_create 產生一個新線程,然後運行 server_thread 函數。這個線程會在 server_thread 返回的時候結束。而在 serve_connection 返回的時候 server_thread 才會返回。serve_connection 和第一節完全一樣。
第一節中我們用腳本生成了多個並發訪問的客戶端,觀察伺服器是怎麼處理的。現在來看看多線程伺服器的處理結果:
$ python3.6 simple-client.py -n 3 localhost 9090
INFO:2017-09-20 06:31:56,632:conn1 connected...
INFO:2017-09-20 06:31:56,632:conn2 connected...
INFO:2017-09-20 06:31:56,632:conn0 connected...
INFO:2017-09-20 06:31:56,632:conn1 sending b'^abc$de^abte$f'
INFO:2017-09-20 06:31:56,632:conn2 sending b'^abc$de^abte$f'
INFO:2017-09-20 06:31:56,632:conn0 sending b'^abc$de^abte$f'
INFO:2017-09-20 06:31:56,633:conn1 received b'b'
INFO:2017-09-20 06:31:56,633:conn2 received b'b'
INFO:2017-09-20 06:31:56,633:conn0 received b'b'
INFO:2017-09-20 06:31:56,670:conn1 received b'cdbcuf'
INFO:2017-09-20 06:31:56,671:conn0 received b'cdbcuf'
INFO:2017-09-20 06:31:56,671:conn2 received b'cdbcuf'
INFO:2017-09-20 06:31:57,634:conn1 sending b'xyz^123'
INFO:2017-09-20 06:31:57,634:conn2 sending b'xyz^123'
INFO:2017-09-20 06:31:57,634:conn1 received b'234'
INFO:2017-09-20 06:31:57,634:conn0 sending b'xyz^123'
INFO:2017-09-20 06:31:57,634:conn2 received b'234'
INFO:2017-09-20 06:31:57,634:conn0 received b'234'
INFO:2017-09-20 06:31:58,635:conn1 sending b'25$^ab0000$abab'
INFO:2017-09-20 06:31:58,635:conn2 sending b'25$^ab0000$abab'
INFO:2017-09-20 06:31:58,636:conn1 received b'36bc1111'
INFO:2017-09-20 06:31:58,636:conn2 received b'36bc1111'
INFO:2017-09-20 06:31:58,637:conn0 sending b'25$^ab0000$abab'
INFO:2017-09-20 06:31:58,637:conn0 received b'36bc1111'
INFO:2017-09-20 06:31:58,836:conn2 disconnecting
INFO:2017-09-20 06:31:58,836:conn1 disconnecting
INFO:2017-09-20 06:31:58,837:conn0 disconnecting
實際上,所有客戶端同時連接,它們與伺服器的通信是同時發生的。
每個客戶端一個線程的難點
儘管在現代操作系統中就資源利用率方面來看,線程相當的高效,但前一節中講到的方法在高負載時卻會出現紕漏。
想像一下這樣的情景:很多客戶端同時進行連接,某些會話持續的時間長。這意味著某個時刻伺服器上有很多活躍的線程。太多的線程會消耗掉大量的內存和 CPU 資源,而僅僅是用於上下文切換 注1 。另外其也可視為安全問題:因為這樣的設計容易讓伺服器成為 DoS 攻擊 的目標 —— 上百萬個客戶端同時連接,並且客戶端都處於閑置狀態,這樣耗盡了所有資源就可能讓伺服器宕機。
當伺服器要與每個客戶端通信,CPU 進行大量計算時,就會出現更嚴重的問題。這種情況下,容易想到的方法是減少伺服器的響應能力 —— 只有其中一些客戶端能得到伺服器的響應。
因此,對多線程伺服器所能夠處理的並發客戶端數做一些 速率限制 就是個明智的選擇。有很多方法可以實現。最容易想到的是計數當前已經連接上的客戶端,把連接數限制在某個範圍內(需要通過仔細的測試後決定)。另一種流行的多線程應用設計是使用 線程池。
線程池
線程池 很簡單,也很有用。伺服器創建幾個任務線程,這些線程從某些隊列中獲取任務。這就是「池」。然後每一個客戶端的連接被當成任務分發到池中。只要池中有空閑的線程,它就會去處理任務。如果當前池中所有線程都是繁忙狀態,那麼伺服器就會阻塞,直到線程池可以接受任務(某個繁忙狀態的線程處理完當前任務後,變回空閑的狀態)。
這裡有個 4 線程的線程池處理任務的圖。任務(這裡就是客戶端的連接)要等到線程池中的某個線程可以接受新任務。
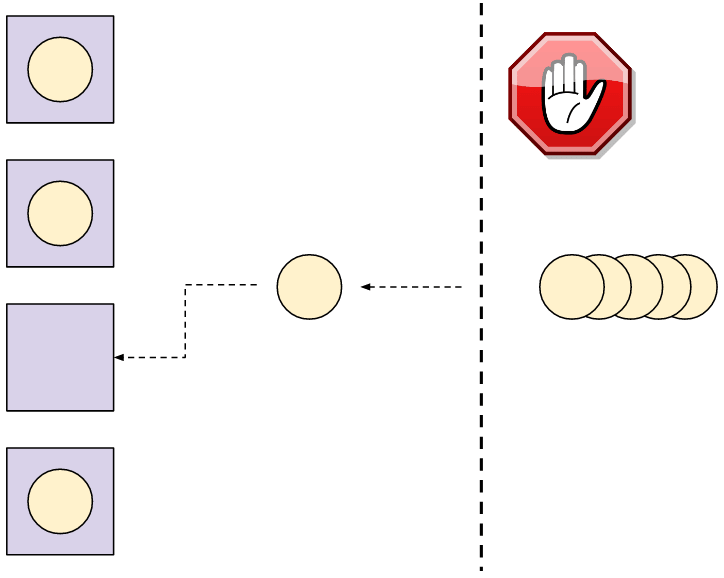
非常明顯,線程池的定義就是一種按比例限制的機制。我們可以提前設定伺服器所能擁有的線程數。那麼這就是並發連接的最多的客戶端數 —— 其它的客戶端就要等到線程空閑。如果我們的池中有 8 個線程,那麼 8 就是伺服器可以處理的最多的客戶端並發連接數,哪怕上千個客戶端想要同時連接。
那麼怎麼確定池中需要有多少個線程呢?通過對問題範疇進行細緻的分析、評估、實驗以及根據我們擁有的硬體配置。如果是單核的雲伺服器,答案只有一個;如果是 100 核心的多套接字的伺服器,那麼答案就有很多種。也可以在運行時根據負載動態選擇池的大小 —— 我會在這個系列之後的文章中談到這個東西。
使用線程池的伺服器在高負載情況下表現出 性能退化 —— 客戶端能夠以穩定的速率進行連接,可能會比其它時刻得到響應的用時稍微久一點;也就是說,無論多少個客戶端同時進行連接,伺服器總能保持響應,盡最大能力響應等待的客戶端。與之相反,每個客戶端一個線程的伺服器,會接收多個客戶端的連接直到過載,這時它更容易崩潰或者因為要處理所有客戶端而變得緩慢,因為資源都被耗盡了(比如虛擬內存的佔用)。
在伺服器上使用線程池
為了改變伺服器的實現,我用了 Python,在 Python 的標準庫中帶有一個已經實現好的穩定的線程池。(concurrent.futures 模塊里的 ThreadPoolExecutor) 注2 。
伺服器創建一個線程池,然後進入循環,監聽套接字接收客戶端的連接。用 submit 把每一個連接的客戶端分配到池中:
pool = ThreadPoolExecutor(args.n)
sockobj = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
sockobj.setsockopt(socket.SOL_SOCKET, socket.SO_REUSEADDR, 1)
sockobj.bind(('localhost', args.port))
sockobj.listen(15)
try:
while True:
client_socket, client_address = sockobj.accept()
pool.submit(serve_connection, client_socket, client_address)
except KeyboardInterrupt as e:
print(e)
sockobj.close()
serve_connection 函數和 C 的那部分很像,與一個客戶端交互,直到其斷開連接,並且遵循我們的協議:
ProcessingState = Enum('ProcessingState', 'WAIT_FOR_MSG IN_MSG')
def serve_connection(sockobj, client_address):
print('{0} connected'.format(client_address))
sockobj.sendall(b'*')
state = ProcessingState.WAIT_FOR_MSG
while True:
try:
buf = sockobj.recv(1024)
if not buf:
break
except IOError as e:
break
for b in buf:
if state == ProcessingState.WAIT_FOR_MSG:
if b == ord(b'^'):
state = ProcessingState.IN_MSG
elif state == ProcessingState.IN_MSG:
if b == ord(b'$'):
state = ProcessingState.WAIT_FOR_MSG
else:
sockobj.send(bytes([b + 1]))
else:
assert False
print('{0} done'.format(client_address))
sys.stdout.flush()
sockobj.close()
來看看線程池的大小對並行訪問的客戶端的阻塞行為有什麼樣的影響。為了演示,我會運行一個池大小為 2 的線程池伺服器(只生成兩個線程用於響應客戶端)。
$ python3.6 threadpool-server.py -n 2
在另外一個終端里,運行客戶端模擬器,產生 3 個並發訪問的客戶端:
$ python3.6 simple-client.py -n 3 localhost 9090
INFO:2017-09-22 05:58:52,815:conn1 connected...
INFO:2017-09-22 05:58:52,827:conn0 connected...
INFO:2017-09-22 05:58:52,828:conn1 sending b'^abc$de^abte$f'
INFO:2017-09-22 05:58:52,828:conn0 sending b'^abc$de^abte$f'
INFO:2017-09-22 05:58:52,828:conn1 received b'b'
INFO:2017-09-22 05:58:52,828:conn0 received b'b'
INFO:2017-09-22 05:58:52,867:conn1 received b'cdbcuf'
INFO:2017-09-22 05:58:52,867:conn0 received b'cdbcuf'
INFO:2017-09-22 05:58:53,829:conn1 sending b'xyz^123'
INFO:2017-09-22 05:58:53,829:conn0 sending b'xyz^123'
INFO:2017-09-22 05:58:53,830:conn1 received b'234'
INFO:2017-09-22 05:58:53,831:conn0 received b'2'
INFO:2017-09-22 05:58:53,831:conn0 received b'34'
INFO:2017-09-22 05:58:54,831:conn1 sending b'25$^ab0000$abab'
INFO:2017-09-22 05:58:54,832:conn1 received b'36bc1111'
INFO:2017-09-22 05:58:54,832:conn0 sending b'25$^ab0000$abab'
INFO:2017-09-22 05:58:54,833:conn0 received b'36bc1111'
INFO:2017-09-22 05:58:55,032:conn1 disconnecting
INFO:2017-09-22 05:58:55,032:conn2 connected...
INFO:2017-09-22 05:58:55,033:conn2 sending b'^abc$de^abte$f'
INFO:2017-09-22 05:58:55,033:conn0 disconnecting
INFO:2017-09-22 05:58:55,034:conn2 received b'b'
INFO:2017-09-22 05:58:55,071:conn2 received b'cdbcuf'
INFO:2017-09-22 05:58:56,036:conn2 sending b'xyz^123'
INFO:2017-09-22 05:58:56,036:conn2 received b'234'
INFO:2017-09-22 05:58:57,037:conn2 sending b'25$^ab0000$abab'
INFO:2017-09-22 05:58:57,038:conn2 received b'36bc1111'
INFO:2017-09-22 05:58:57,238:conn2 disconnecting
回顧之前討論的伺服器行為:
- 在順序伺服器中,所有的連接都是串列的。一個連接結束後,下一個連接才能開始。
- 前面講到的每個客戶端一個線程的伺服器中,所有連接都被同時接受並得到服務。
這裡可以看到一種可能的情況:兩個連接同時得到服務,只有其中一個結束連接後第三個才能連接上。這就是把線程池大小設置成 2 的結果。真實用例中我們會把線程池設置的更大些,取決於機器和實際的協議。線程池的緩衝機制就能很好理解了 —— 我 幾個月前 更詳細的介紹過這種機制,關於 Clojure 的 core.async 模塊。
總結與展望
這篇文章討論了在伺服器中,用多線程作並發的方法。每個客戶端一個線程的方法最早提出來,但是實際上卻不常用,因為它並不安全。
線程池就常見多了,最受歡迎的幾個編程語言有良好的實現(某些編程語言,像 Python,就是在標準庫中實現)。這裡說的使用線程池的伺服器,不會受到每個客戶端一個線程的弊端。
然而,線程不是處理多個客戶端並行訪問的唯一方法。下一節中我們會看看其它的解決方案,可以使用非同步處理,或者事件驅動的編程。
- 注1:老實說,現代 Linux 內核可以承受足夠多的並發線程 —— 只要這些線程主要在 I/O 上被阻塞。這裡有個示常式序,它產生可配置數量的線程,線程在循環體中是休眠的,每 50 ms 喚醒一次。我在 4 核的 Linux 機器上可以輕鬆的產生 10000 個線程;哪怕這些線程大多數時間都在睡眠,它們仍然消耗一到兩個核心,以便實現上下文切換。而且,它們佔用了 80 GB 的虛擬內存(Linux 上每個線程的棧大小默認是 8MB)。實際使用中,線程會使用內存並且不會在循環體中休眠,因此它可以非常快的佔用完一個機器的內存。
- 注2:自己動手實現一個線程池是個有意思的練習,但我現在還不想做。我曾寫過用來練手的 針對特殊任務的線程池。是用 Python 寫的;用 C 重寫的話有些難度,但對於經驗豐富的程序員,幾個小時就夠了。
via: https://eli.thegreenplace.net/2017/concurrent-servers-part-2-threads/
作者:Eli Bendersky 譯者:GitFuture 校對:wxy
本文轉載來自 Linux 中國: https://github.com/Linux-CN/archive
對這篇文章感覺如何?
You may also like






More in:Linux中國

捐贈 Let's Encrypt,共建安全的互聯網

Let's Encrypt 正式發布,已經保護 380 萬個域名

關於Linux防火牆iptables的面試問答

Lets Encrypt 已被所有主流瀏覽器所信任









