開源音頻編輯器 Audacity 的 AI 工具來了

Audacity 現在配備了新的 AI 工具。
在過去的幾年中,我們已經看到了 AI 的顯著發展,包括將 AI 驅動的功能添加到各種流行的工具中。而且,我們在 2024 年 Linux 和開源預測 中已經提到了更多的人工智慧。
這次是 Audacity,Linux 的最佳音頻編輯之一,迎來了 AI。現在,用戶可以通過利用 AI 的力量來增強其音頻編輯體驗。
讓我們來看看這些迷人的功能都有哪些。
英特爾打造 AI 工具 ?️
英特爾公司推出了由 AI 驅動的處理語音音頻和音樂的新功能。
這些功能是 OpenVino 插件套件的一部分。對於那些不知道的人來說,英特爾的 OpenVino 是一個 AI 框架,有助於加速深度學習模型。
值得注意的一個很酷但也很重要的方面是,所有這些功能在本地的 PC 上運行! 更具體地說,PC 的 CPU 或 GPU 將用於處理部分。
播客編輯
曾經想快速轉錄甚至翻譯音頻嗎?
由 OpenAI 的 Whisper 支持的轉錄功能可以讓用戶做到這一點。
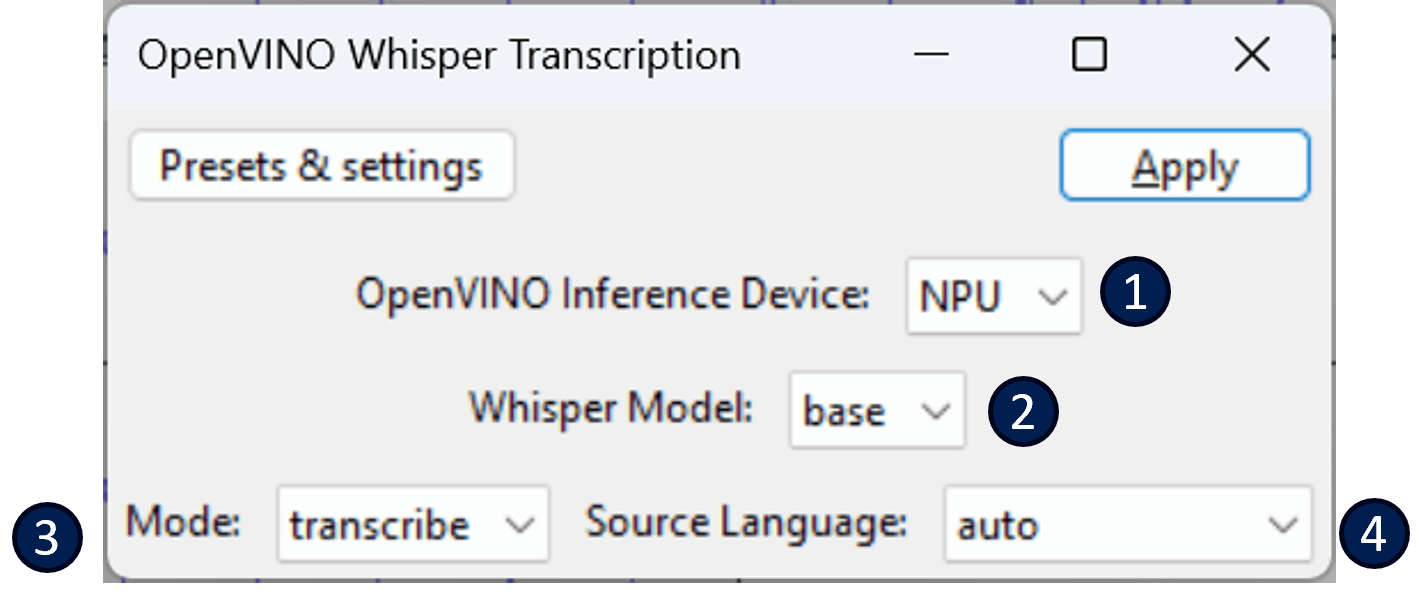
- 它能根據給定的音頻樣本生成包含轉錄/翻譯文本的新標籤音軌。
- 翻譯將始終以英語產生輸出,而轉錄將以與源音頻相同的語言產生輸出。
- 目前,默認情況下僅支持 Whisper Base 模型。稍後可能會支持更多模型。
與現有的 「噪音去除」效果類似,「噪音抑制」 可幫助去除口語音頻樣本中不需要的背景噪音。
- 由於它是由 AI 提供動力的,因此你可以期望此功能的效果優於噪音去除。
- 目前,默認情況下僅支持 denseunet 模型。稍後可能會支持更多模型。
音樂生成
是的,你沒看錯:現在,你可以在機器內生成新音樂!
音樂生成 允許用戶生成音樂片段。這要歸功於一個名為 Riffusion 的開源項目,這是一個基於 Stable Diffusion 的音樂生成模型(一種流行的開源模型,用於生成圖像。)
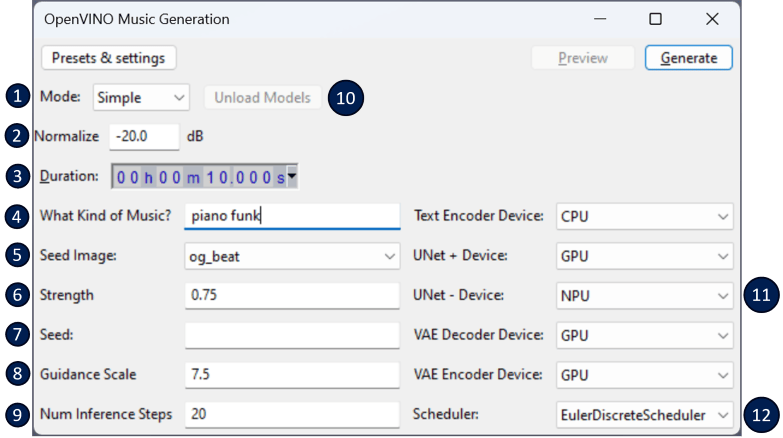
- 你通過給出文本提示並調整其他一些參數(例如持續時間)來生成音樂。
- 在文本提示符中,你指定要生成的音樂流派,AI 將儘力在生成音樂時保持這種類型。
- 你可以選擇在默認的簡單模式和可選的高級模式之間切換,以進行更多的控制,例如指定開始提示和結束提示。
此外,你甚至可以通過音樂風格混音,選擇音樂曲目的一部分,對音樂進行混音!
音樂分離
如果你想為自己喜歡的歌曲創建自己的器樂曲目,該怎麼辦?也許還能與朋友來一場有趣的卡拉 OK 呢?
音樂分離使你可以將歌曲分為聲音或樂器版本。提供了兩種分離模式:
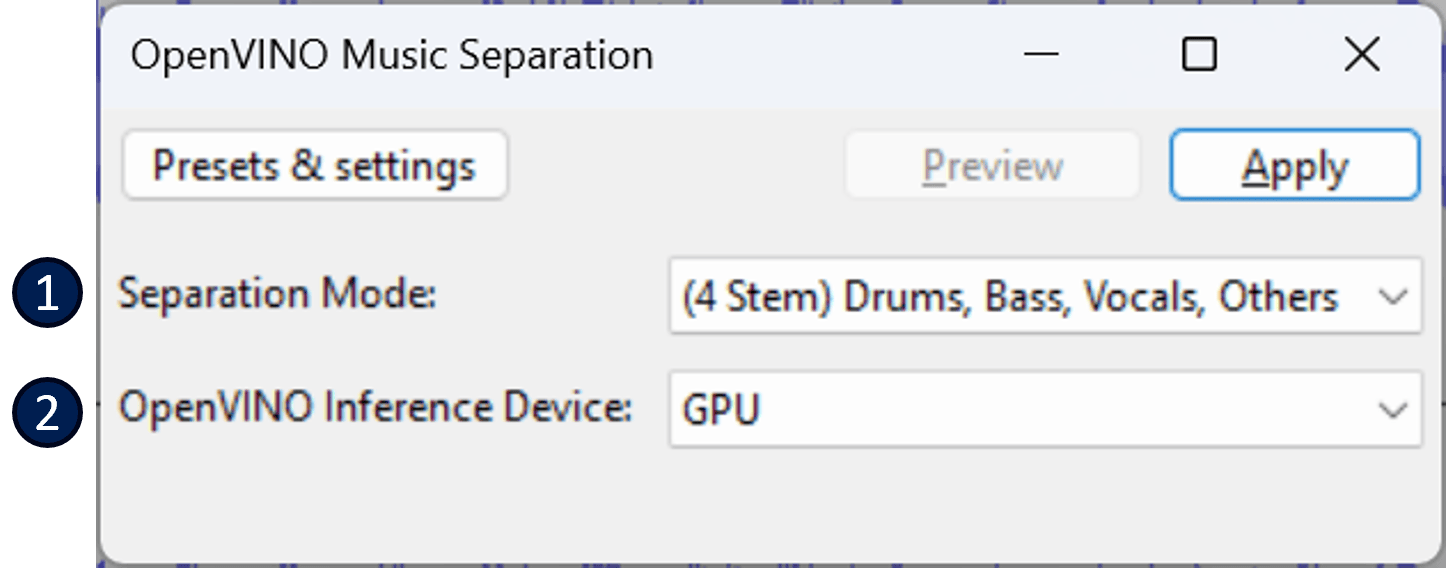
- 2-Stem 為人聲和器樂製作兩個新音軌。
- 4-Stem 可生成四條新音軌,包括人聲、鼓聲、貝司聲,最後一條是其他樂器聲。
如何使用 AI 工具? ?
如果你是 Linux 用戶,請等一等。
雖然該插件的 Windows 版本 可供下載,但其 Linux 對應版本暫時還不可用。
如果你仍然想嘗試一下,則需要自己編譯該項目。你可以參考此的官方說明。
希望 Linux 構建很快到來!?
? 你覺得 Audacity 的這些新人工智慧功能怎麼樣?請在評論中告訴我們你的想法!
via: https://news.itsfoss.com/audacity-ai-tools/
作者:Rishabh Moharir 選題:lujun9972 譯者:geekpi 校對:wxy
本文轉載來自 Linux 中國: https://github.com/Linux-CN/archive
對這篇文章感覺如何?
You may also like






More in:Linux中國

捐贈 Let's Encrypt,共建安全的互聯網

Let's Encrypt 正式發布,已經保護 380 萬個域名

關於Linux防火牆iptables的面試問答

Lets Encrypt 已被所有主流瀏覽器所信任









